チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

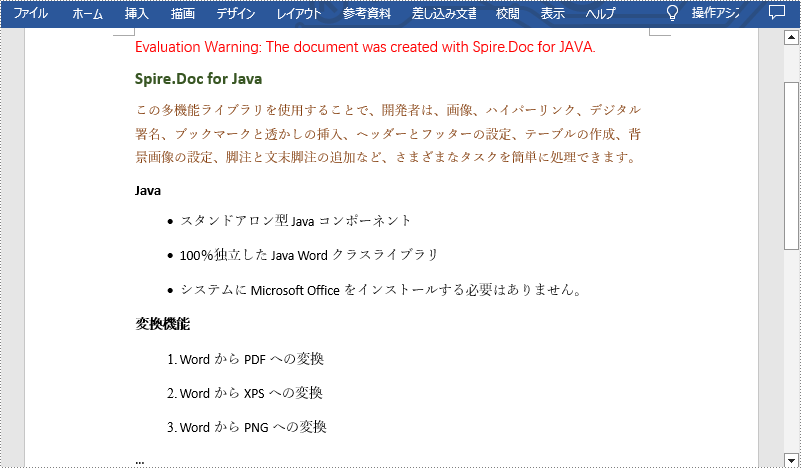
項目符号リストは、記号で始まるリストであり、各項目は同じインデントがあります。一方、番号付きリストは数字で始まります。これらのリストは、冗長なテキストに比べて情報をより良く整理し、読者が各項目の構造や要点を簡単に理解するのに役立ちます。この記事では、Spire.Doc for Java を使用して Word 文書で既存のテキストから箇条書きや番号付きリストを作成する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>Spire.Doc for Java には、箇条書きリストと番号付きリストを作成するための ListFormat.applyBulletStyle() と ListFormat.applyNumberedStyle() メソッドが用意されています。以下は詳細な手順です。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.formatting.ListFormat;
public class CreateLists {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Word 文書を読み込む
document.loadFromFile("Sample.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//4 番目から 6 番目の段落までをループする
for(int i = 3; i <= 5; i++){
Paragraph para = section.getParagraphs().get(i);
ListFormat listFormat = para.getListFormat();
//箇条書きスタイルを適用する
listFormat.applyBulletStyle();
//リストの位置を設定する
listFormat.getCurrentListLevel().setNumberPosition(-10);
}
//8 段落から 10 段落までをループする
for(int i = 7; i <= 9; i++){
Paragraph para = section.getParagraphs().get(i);
ListFormat listFormat = para.getListFormat();
//番号付きリストのスタイルを適用する
listFormat.applyNumberedStyle();
//リストの位置を設定する
listFormat.getCurrentListLevel().setNumberPosition(-10);
}
//結果文書を保存する
document.saveToFile("CreateLists.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
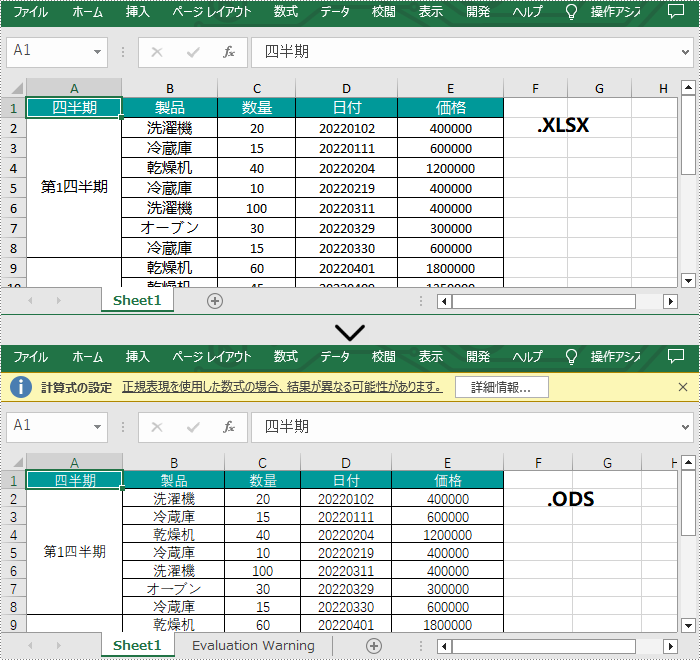
ODS(OpenDocument Spreadsheet)は、Calc プログラムによって作成された XML ベースのファイル形式です。MS Excel ファイルと同様に、ODS ファイルはデータをスプレッドシートに格納し、テキスト、数学関数、書式などを含むことができます。ODS ファイルは優れたクロスプラットフォーム互換性を持っており、異なるシステム上の複数の電子表計算アプリケーションで表示することができます。時には、ファイルをより便利に表示するために Excel を ODS に変換する必要があります。この記事では、Spire.XLS for Java を使用して、プログラムでこの変換を行う方法を示します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.11.0</version>
</dependency>
</dependencies>Spire.XLS for Java によって提供される Workbook.saveToFile() メソッドは、Excel ファイルの ODS 形式への変換をサポートしています。詳細な手順は次のとおりです。
import com.spire.xls.*;
public class toODS {
public static void main(String[] args) {
// Workbook インスタンスを作成する
Workbook workbook = new Workbook();
// サンプルExcelファイルをロードする
workbook.loadFromFile("Sample.xlsx");
// ExcelファイルをODSに変換する
workbook.saveToFile("ExcelToODS.ods", FileFormat.ODS);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
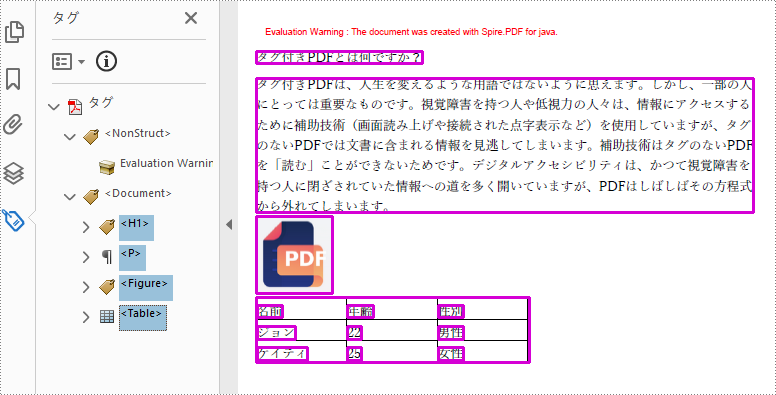
タグ付き PDF は、HTML コードによく似たタグを含む PDF ドキュメントです。タグは、PDF のコンテンツが支援技術によってどのように表示されるかを管理する論理構造を提供します。各タグは、見出しレベル1 <H1>、段落 <P>、画像 <Figure>、表 <Table> など、関連するコンテンツ要素を識別します。この記事では、Spire.PDF for Java を使って Java プログラムでタグ付き PDF ドキュメントを作成する方法を説明します。
まず、Spire.PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>9.9.6</version>
</dependency>
</dependencies>タグ付き PDF 文書に構造要素を追加するには、まず PdfTaggedContent クラスのオブジェクトを作成する必要があります。次に、PdfTaggedContent.getStructureTreeRoot().appendChildElement() メソッドを使用して、要素をルートに追加します。以下は、Spire.PDF for Java を使ってタグ付き PDF に「見出し」要素を追加する詳細な手順です。
次のコード例は、Java でタグ付き PDF ドキュメントのドキュメント、見出し、段落、図、表などのさまざまな要素を作成する方法を示しています。
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import com.spire.pdf.interchange.taggedpdf.PdfStandardStructTypes;
import com.spire.pdf.interchange.taggedpdf.PdfStructureElement;
import com.spire.pdf.interchange.taggedpdf.PdfTaggedContent;
import com.spire.pdf.tables.PdfTable;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
public class createTaggedPDF {
public static void main(String[] args) throws Exception {
//PdfDocumentオブジェクトを作成します
PdfDocument doc = new PdfDocument();
//ページを追加します
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(20));
//タブの順序を設定します
page.setTabOrder(TabOrder.Structure);
//PdfTaggedContentクラスのオブジェクトを作成します
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
//ドキュメントの言語とタイトルを設定します
taggedContent.setLanguage("ja-JP");
taggedContent.setTitle("Javaによるタグ付きPDFドキュメントの作成");
//PDF/UA1の識別情報を設定します
taggedContent.setPdfUA1Identification();
//フォントとブラシを作成します
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Yu Mincho",Font.PLAIN,14), true);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//"ドキュメント"要素を追加します
PdfStructureElement document = taggedContent.getStructureTreeRoot().appendChildElement(PdfStandardStructTypes.Document);
// "見出し"要素を追加します
PdfStructureElement heading1 = document.appendChildElement(PdfStandardStructTypes.HeadingLevel1);
heading1.beginMarkedContent(page);
String headingText = "タグ付きPDFとは何ですか?";
page.getCanvas().drawString(headingText, font, brush, new Point2D.Float(0, 30));
heading1.endMarkedContent(page);
// "段落"要素を追加します
PdfStructureElement paragraph = document.appendChildElement(PdfStandardStructTypes.Paragraph);
paragraph.beginMarkedContent(page);
String paragraphText = "タグ付きPDFは、人生を変えるような用語ではないように思えます。しかし、一部の人にとっては重要なものです。視覚障害を持つ人や低視力の人々は、情報にアクセスするために補助技術(画面読み上げや接続された点字表示など)を使用していますが、タグのないPDFでは文書に含まれる情報を見逃してしまいます。補助技術はタグのないPDFを「読む」ことができないためです。デジタルアクセシビリティは、かつて視覚障害を持つ人に閉ざされていた情報への道を多く開いていますが、PDFはしばしばその方程式から外れてしまいます。";
Rectangle2D.Float rect = new Rectangle2D.Float(0, 60, (float) page.getCanvas().getClientSize().getWidth(), (float) page.getCanvas().getClientSize().getHeight());
page.getCanvas().drawString(paragraphText, font, brush, rect);
paragraph.endMarkedContent(page);
// "図"要素を追加します
PdfStructureElement figure = document.appendChildElement(PdfStandardStructTypes.Figure);
figure.beginMarkedContent(page);
PdfImage image = PdfImage.fromFile("PDF.png");
page.getCanvas().drawImage(image, new Point2D.Float(0, 220));
figure.endMarkedContent(page);
// "表"要素を追加します
PdfStructureElement table = document.appendChildElement(PdfStandardStructTypes.Table);
table.beginMarkedContent(page);
PdfTable pdfTable = new PdfTable();
pdfTable.getStyle().getDefaultStyle().setFont(font);
String[] data = {"名前;年齢;性別",
"ジョン;22;男性",
"ケイティ;25;女性"
};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
pdfTable.setDataSource(dataSource);
pdfTable.getStyle().setShowHeader(true);
pdfTable.draw(page.getCanvas(), new Point2D.Float(0, 310), 300f);
table.endMarkedContent(page);
// ドキュメントをファイルに保存します
doc.saveToFile("PDFUAの作成.pdf");
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation for Java 8.11.1を発表できることをうれしく思います。このバージョンでは、スライドからSVGへの変換機能が強化されています。 また、挿入されたHTMLテキストの下線が欠落する問題など、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPPT-2114 | スライドをSVGに変換した後、内容が正しくない問題が修正されました。 |
| Bug | SPIREPPT-2140 SPIREPPT-2373 |
スライドを SVG に変換した後、グラデーションの背景色が正しくなくなる問題が修正されました。 |
| Bug | SPIREPPT-2380 | スライドを SVG に変換した後、内容が不鮮明になる問題が修正されました。 |
| Bug | SPIREPPT-2381 | 「Indent Text When Overflow」の設定が無効になる問題が修正されました。 |
| Bug | SPIREPPT-2383 | 挿入されたHTMLテキストの下線が欠落する問題が修正されました。 |
| Bug | SPIREPPT-2386 | 「Resize Shape to Fit Text」の設定が無効になる問題が修正されました。 |
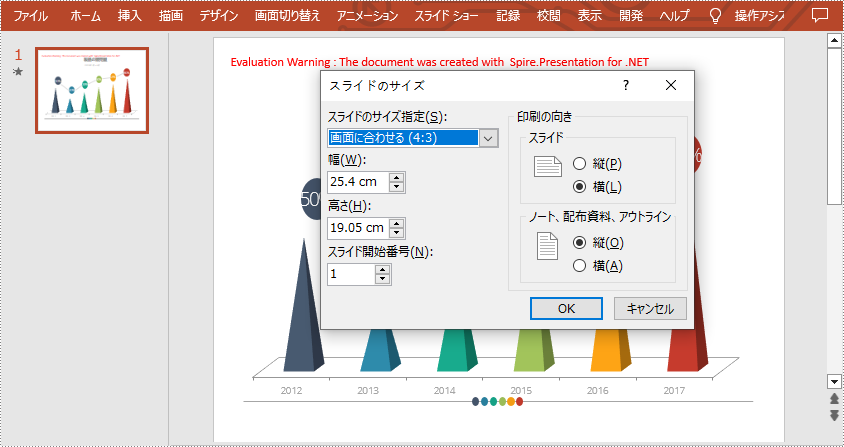
スライドサイズの変更は、PowerPoint プレゼンテーションの視覚的な整合性を維持するための方法です。ターゲットとするスクリーンや投影デバイスの特定の縦横比と寸法に合わせてスライドのサイズを調整することで、コンテンツが切り取られたり、引き伸ばされたり、歪んだりするなどの問題を回避できます。この記事では、C# で Spire.Presentation for .NET を使用して PowerPoint プレゼンテーションのスライドサイズを変更する方法について説明します。
まず、Spire.Presentation for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PresentationSpire.Presentation for .NET では、Presentation.SlideSize.Type プロパティを使用して、スライドサイズをプリセットサイズに設定または変更できます。以下に詳細な手順を示します。
using Spire.Presentation;
namespace ChangeSlideSize
{
class Program
{
static void Main(string[] args)
{
//Presentationインスタンスを作成する
Presentation ppt = new Presentation();
//プレゼンテーションをロードする
ppt.LoadFromFile("sample.pptx");
//スライド サイズを変更する
ppt.SlideSize.Type = SlideSizeType.Screen4x3;
//結果文書を保存する
ppt.SaveToFile("SlideSize.pptx", FileFormat.Pptx2013);
ppt.Dispose();
}
}
}
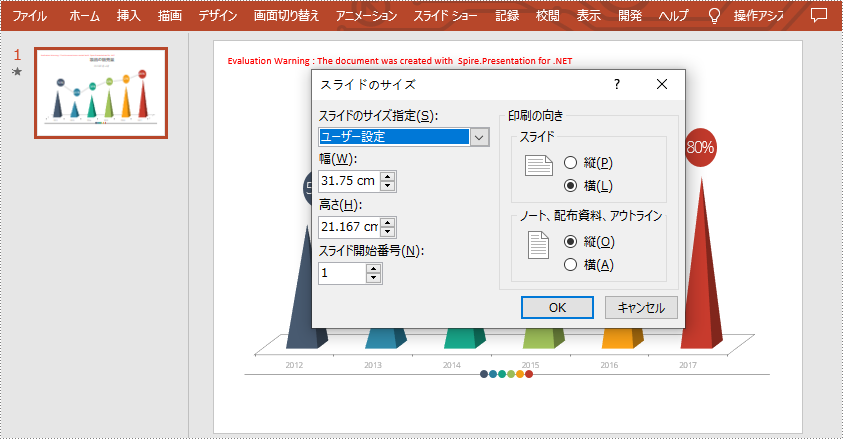
スライドのサイズをカスタマイズするには、まずスライドのサイズタイプをカスタムに変更し、Presentation.SlideSize.Size プロパティで希望のサイズを設定します。以下はその詳細な手順です。
using Spire.Presentation;
using System.Drawing;
namespace ChangeSlideSize
{
class Program
{
static void Main(string[] args)
{
//Presentationインスタンスを作成する
Presentation ppt = new Presentation();
//プレゼンテーションをロードする
ppt.LoadFromFile("sample.pptx");
//スライド サイズのタイプをカスタムに変更する
ppt.SlideSize.Type = SlideSizeType.Custom;
//スライドのサイズを設定する
ppt.SlideSize.Size = new SizeF(900, 600);
//結果文書を保存する
ppt.SaveToFile("CustomSize.pptx", FileFormat.Pptx2013);
ppt.Dispose();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
スタンプは文書の真正性と有効性を保証し、文書をよりプロフェッショナルに見せることができます。Microsoft Word には組み込みのスタンプ機能がないため、スタンプの効果を模倣するためにWord文書に画像を追加することができます。これは、文書を印刷したり PDF に変換する際に非常に便利です。この記事では、Spire.Doc for Java を使用して Word 文書に画像スタンプを追加する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>Spire.Doc for Java を使用すると、開発者は以下の表のコアクラスとメソッドを使用して、画像を追加および書式設定し、Word 文書のスタンプのように見せることができます。
| メソッドとクラス | 説明 |
| DocPicture クラス | Word 文書内の画像です |
| Paragraph.appendPicture() メソッド | 段落の末尾に画像を追加します |
| DocPicture.setHorizontalPosition() メソッド | 画像の水平位置の絶対値を設定します |
| DocPicture.setVerticalPosition() メソッド | 画像の垂直位置の絶対値を設定します |
| DocPicture.setWidth() メソッド | 画像の幅を設定します |
| DocPicture.setHeight メソッド | 画像の高さを設定します |
| DocPicture.setTextWrappingStyle() メソッド | 画像のテキストの折り返しスタイルを設定します |
詳細な手順は次のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.TextWrappingStyle;
import com.spire.doc.fields.DocPicture;
public class AddStamp {
public static void main(String[] args) {
//Documentインスタンスを作成する
Document doc = new Document();
//Word文書を読み込む
doc.loadFromFile("test.docx");
//特定の段落を取得する
Section section = doc.getSections().get(0);
Paragraph paragraph = section.getParagraphs().get(4);
//画像を追加する
DocPicture picture = paragraph.appendPicture("cert.png");
//画像の位置を設定する
picture.setHorizontalPosition(240f);
picture.setVerticalPosition(120f);
//画像の幅と高さを設定する
picture.setWidth(150);
picture.setHeight(150);
//画像のテキストの折り返しスタイルを「 In_Front_Of_Text」 に設定する
picture.setTextWrappingStyle(TextWrappingStyle.In_Front_Of_Text);
//結果文書を保存する
doc.saveToFile("AddStamp.docx", FileFormat.Docx);
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word 文書における変数は、テキストの置換や削除など、便利で正確なテキスト管理ができることを特徴とするフィールドの一種です。検索・置換機能に比べ、変数に値を代入してテキストを置換する方が、高速でエラーも少ない。この記事では、Spire.Doc for Java を使用して Word 文書で変数を追加または変更する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>変数は Word のフィールドの一種であるため、Paragraph.appendField(String fieldName, FieldType.Field_Doc_Variable) メソッドを使用して変数をWord文書に挿入し、VariableCollection.add() メソッドを使用して変数に値を割り当てることができます。なお、変数に値を割り当てた後は、文書のフィールドを更新して割り当てられた値を表示する必要があります。詳細な手順は以下の通りです。
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.formatting.CharacterFormat;
public class AddVariables {
public static void main(String[] args) {
//Documentのオブジェクトを作成する
Document document = new Document();
//セクションを追加する
Section section = document.addSection();
//段落を追加する
Paragraph paragraph = section.addParagraph();
//テキスト形式を設定する
CharacterFormat characterFormat = paragraph.getStyle().getCharacterFormat();
characterFormat.setFontName("Yu Mincho");
characterFormat.setFontSize(12);
//ページ余白を設定する
section.getPageSetup().getMargins().setTop(80f);
//変数フィールドを段落に追加する
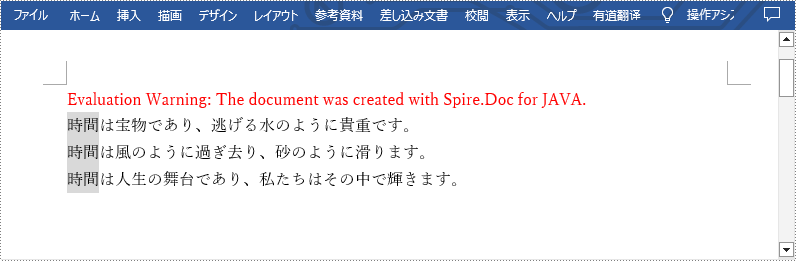
paragraph.appendField("Time", FieldType.Field_Doc_Variable);
paragraph.appendText("は宝物であり、逃げる水のように貴重です。\r\n");
paragraph.appendField("Time", FieldType.Field_Doc_Variable);
paragraph.appendText("は風のように過ぎ去り、砂のように滑ります。\r\n");
paragraph.appendField("Time", FieldType.Field_Doc_Variable);
paragraph.appendText("は人生の舞台であり、私たちはその中で輝きます。");
//変数コレクションを取得する
VariableCollection variableCollection = document.getVariables();
//変数に値を代入する
variableCollection.add("Time", "時間");
//文書内のフィールドを更新する
document.isUpdateFields(true);
//結果文書を保存する
document.saveToFile("AddVariables.docx", FileFormat.Auto);
document.dispose();
}
}
Spire.Doc for Java では、VariableCollection.set() メソッドを使用して変数の値を変更することができます。また、文書内のフィールドを更新した後、変数のすべての出現箇所には新しく割り当てられた値が表示されるため、高速かつ正確なテキストの置換が実現されます。詳細な手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.VariableCollection;
public class ChangeVariableValue {
public static void main(String[] args) {
//Documentのオブジェクトを作成する
Document document = new Document();
//Word文書をロードする
document.loadFromFile("AddVariables.docx");
//変数コレクションを取得する
VariableCollection variableCollection = document.getVariables();
//変数に値を代入する
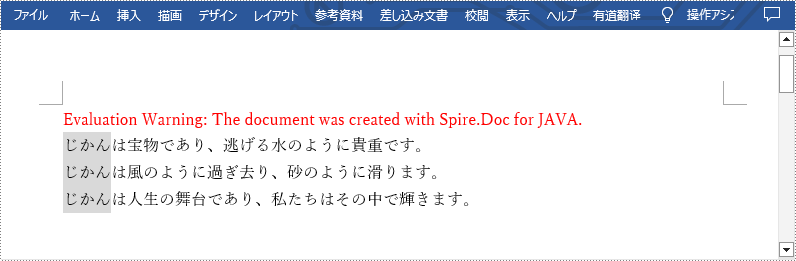
variableCollection.set("Time", "じかん");
//文書内のフィールドを更新する
document.isUpdateFields(true);
//結果文書を保存する
document.saveToFile("ChangeVariable.docx", FileFormat.Auto);
document.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
数式は、物理学、工学、コンピュータ科学、経済学の分野で一般的に使用される数式です。専門的な Word ドキュメントを作成する際、複雑な概念を説明したり、問題を解決したり、特定の議論をサポートしたりするために、数式を含める必要がある場合があります。この記事では、Spire.Doc for Java を使用して、Java プログラムで Word ドキュメントに数式を挿入する方法について説明します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.6.0</version>
</dependency>
</dependencies>Spire.Doc for Java では、OfficeMath.fromLatexMathCode(String latexMathCode) メソッドと OfficeMath.fromMathMLCode(String mathMLCode) メソッドを使用して、LaTeX コードと MathML コードから数式を生成できます。以下に詳細な手順を示します。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.omath.*;
public class AddMathEquations {
public static void main(String[] args){
//LaTeXコードから文字列配列を作成する
String[] latexMathCode = {
"x^{2}+\\sqrt{x^{2}+1}=2",
"\\cos (2\\theta) = \\cos^2 \\theta - \\sin^2 \\theta",
"k_{n+1} = n^2 + k_n^2 - k_{n-1}",
"\\frac {\\frac {1}{x}+ \\frac {1}{y}}{y-z}",
"\\int_0^ \\infty \\mathrm {e}^{-x} \\, \\mathrm {d}x",
"\\forall x \\in X, \\quad \\exists y \\leq \\epsilon",
"\\alpha, \\beta, \\gamma, \\Gamma, \\pi, \\Pi, \\phi, \\varphi, \\mu, \\Phi",
"A_{m,n} = \\begin{pmatrix} a_{1,1} & a_{1,2} & \\cdots & a_{1,n} \\\\ a_{2,1} & a_{2,2} & \\cdots & a_{2,n} \\\\ \\vdots & \\vdots & \\ddots & \\vdots \\\\ a_{m,1} & a_{m,2} & \\cdots & a_{m,n} \\end{pmatrix}",
};
//MathMLコードから文字列配列を作成する
String[] mathMLCode = {
"<math xmlns=\"http://www.w3.org/1998/Math/MathML\"><mi>a</mi><mo>≠</mo><mn>0</mn></math>",
"<math xmlns=\"http://www.w3.org/1998/Math/MathML\"><mi>a</mi><msup><mi>x</mi><mn>2</mn></msup><mo>+</mo><mi>b</mi><mi>x</mi><mo>+</mo><mi>c</mi><mo>=</mo><mn>0</mn></math>",
"<math xmlns=\"http://www.w3.org/1998/Math/MathML\"><mi>x</mi><mo>=</mo><mrow><mfrac><mrow><mo>−</mo><mi>b</mi><mo>±</mo><msqrt><msup><mi>b</mi><mn>2</mn></msup><mo>−</mo><mn>4</mn><mi>a</mi><mi>c</mi></msqrt></mrow><mrow><mn>2</mn><mi>a</mi></mrow></mfrac></mrow></math>",
};
//ドキュメントのインスタンスを作成する
Document doc = new Document();
//セクションを追加する
Section section = doc.addSection();
//セクションに段落を追加する
Paragraph textPara = section.addParagraph();
textPara.appendText("LaTeXコードから方程式を作成する");
textPara.applyStyle(BuiltinStyle.Heading_1);
textPara.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//文字列配列内の各LaTeXコードに対して繰り返す
for (int i = 0; i < latexMathCode.length; i++)
{
//LaTeXコードから数式を作成する
OfficeMath officeMath = new OfficeMath(doc);
officeMath.fromLatexMathCode(latexMathCode[i]);
//数式をセクションに追加する
Paragraph paragraph = section.addParagraph();
paragraph.getItems().add(officeMath);
section.addParagraph();
}
//セクションに段落を追加する
textPara = section.addParagraph();
textPara.appendText("MathMLコードから方程式を作成する");
textPara.applyStyle(BuiltinStyle.Heading_1);
textPara.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//文字列配列内の各MathMLコードに対して繰り返す
for (int j = 0; j < mathMLCode.length; j++)
{
//MathMLコードから数式を作成する
OfficeMath officeMath = new OfficeMath(doc);
officeMath.fromMathMLCode(mathMLCode[j]);
//数式をセクションに追加する
Paragraph paragraph = section.addParagraph();
paragraph.getItems().add(officeMath);
section.addParagraph();
}
//結果のドキュメントを保存する
doc.saveToFile("数式の追加.docx", FileFormat.Docx_2016);
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF 9.11.4のリリースをお知らせいたします。このバージョンは、PdfImageHelperインターフェイスで画像の抽出、削除、置換、圧縮をサポートしています。 PDFからXPS、XPSからPDFへの変換機能も強化されました。 さらに、抽出されたPDFテーブルで2つの列が一緒にマージされる問題など、いくつかの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | PdfImageHelperインターフェイスで画像の抽出、削除、置換、圧縮をサポートしています。
//画像を削除する
imageHelper.DeleteImage(imageInfos[0]);
//画像を抽出する
int index = 0;
foreach (PdfImageInfo info in imageInfos)
{
info.Image.Save(outputFile_I + string.Format("Image-{0}.png", index));
index++;
}
//画像を置き換える
PdfImage image = PdfImage.FromFile(TestUtil.DataPath + "ImgFiles/E-iceblue logo.png");
imageHelper.ReplaceImage(imageInfos[0], image);
//画像を圧縮する
foreach (PdfPageBase page in doc.Pages)
{
foreach (PdfImageInfo info in imageHelper.GetImagesInfo(page))
{
bool success = info.TryCompressImage();
}
} |
| Bug | SPIREPDF-5781 | 抽出されたPDFの表で、2つの列が一緒にマージされる問題が修正されました。 |
| Bug | SPIREPDF-6225 | XPSをPDFに変換した後、結果文書が空白になる問題が修正されました。 |
| Bug | SPIREPDF-6232 | XPSから変換したPDFドキュメントをAdobeツールで開くとページエラーが発生する問題が修正されました。 |
| Bug | SPIREPDF-6355 | PDFをXPSに変換した後、コンテンツに余分な文字が含まれる問題が修正されました。 |
| Bug | SPIREPDF-6361 | PDFドキュメントを読み込むとき、プログラムが "System.NullReferenceException "をスローする問題が修正されました。 |
Spire.XLS for Java 13.11.0のリリースをお知らせいたします。このバージョンでは、「Name Manager」からの注釈の取得をサポートしています。 同時に、ExcelからPDFへの変換機能も強化されました。 さらに、Excel文書を読み込む際にプログラムが「Invalid ValidationAlertType 」をスローするなど、既知の問題も修正されました。詳細については、以下の内容をご覧ください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4919 | 「Name Manager」からの注釈の取得をサポートしています。
Workbook workbook = new Workbook();
workbook.loadFromFile(inputFile);
INameRanges nameManager = workbook.getNameRanges();
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < nameManager.getCount(); i++) {
XlsName name = (XlsName) nameManager.get(i);
stringBuilder.append("Name: " + name.getName() + ", Comment: " + name.getCommentValue() + "\r\n");
}
workbook.dispose(); |
| Bug | SPIREXLS-4911 | LinuxでExcelからPDFへの変換速度を改善しました。 |
| Bug | SPIREXLS-4860 | ExcelからPDFに変換するとき、setSheetFitToPageメソッドを設定するとページサイズの設定に失敗する問題を修正しました。 |
| Bug | SPIREXLS-4894 | ピボットテーブルの枠線の削除に失敗する問題を修正しました。 |
| Bug | SPIREXLS-4906 | ExcelをPDFに変換した後、テキストが反転して切り取られる問題を修復しました。 |
| Bug | SPIREXLS-4923 | Excel文書読み込み時に、プログラムが「Invalid ValidationAlertType」をスローする問題を修正しました。 |
| Bug | SPIREXLS-4924 | Excel文書読み込み時に、プログラムが「Input string was not in the correct format」をスローする問題を修正しました。 |





