チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

ワークシートの複製には、同一のワークブック内または異なるワークブック内で既存のワークシートを複製することが含まれます。この機能により、開発者は元のワークシートの構造、フォーマット、データ、数式、グラフ、およびその他のオブジェクトを含む正確なコピーを作成することができます。実際には、この機能は大規模なスプレッドシートを処理する際に特に有用であり、バックアップファイルの作成やテンプレートの作成にかかる時間と労力を大幅に削減することが証明されています。この記事では、Spire.XLS for Java を使用して Excel でワークシートを複製する方法を紹介します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.6.5</version>
</dependency>
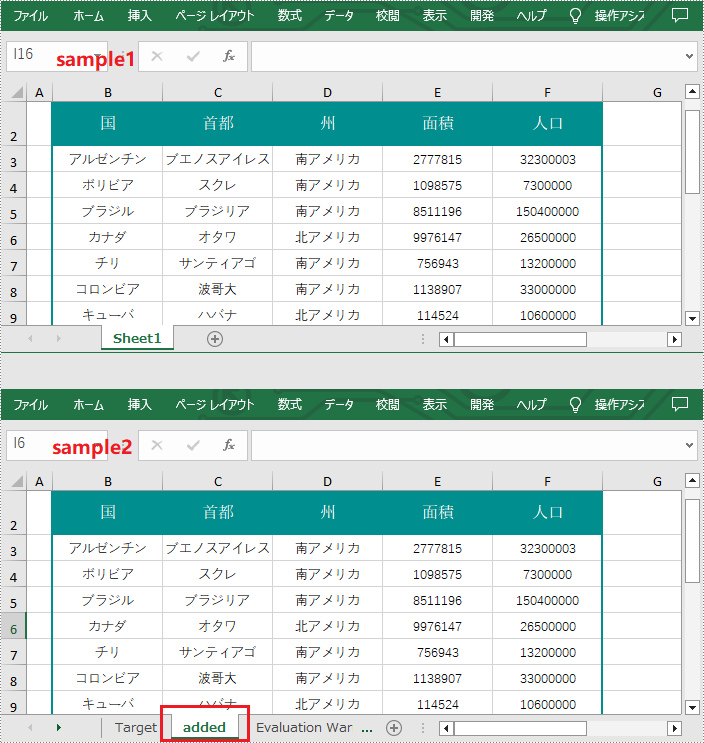
</dependencies>Spire.XLS for Java ライブラリを使用すると、Worksheet.copyFrom() メソッドを使用して、既存のワークブックから別のワークブックにを簡単に複製できます。以下は詳細な手順です。
import com.spire.xls.*;
public class copyWorksheet {
public static void main(String[] args) {
//Workbookオブジェクトを作成する
Workbook sourceWorkbook = new Workbook();
//ディスクから「sample1.xlsx」をロードする
sourceWorkbook.loadFromFile("sample1.xlsx");
//最初のシートを取得する
Worksheet srcWorksheet = sourceWorkbook.getWorksheets().get(0);
//別のWorkbookオブジェクトを作成する
Workbook targetWorkbook = new Workbook();
//ディスクから「sample2.xlsx」をロードする
targetWorkbook.loadFromFile("sample2.xlsx");
//新しいシートを追加する
Worksheet targetWorksheet = targetWorkbook.getWorksheets().add("added");
//sample1の最初のシートを、sample2の新しく追加されたシートに複製する
targetWorksheet.copyFrom(srcWorksheet);
//出力パスを指定する
String outputFile = "output/CopyWorksheet.xlsx";
//結果ファイルを保存する
targetWorkbook.saveToFile(outputFile, ExcelVersion.Version2013);
sourceWorkbook.dispose();
targetWorkbook.dispose();
}
}
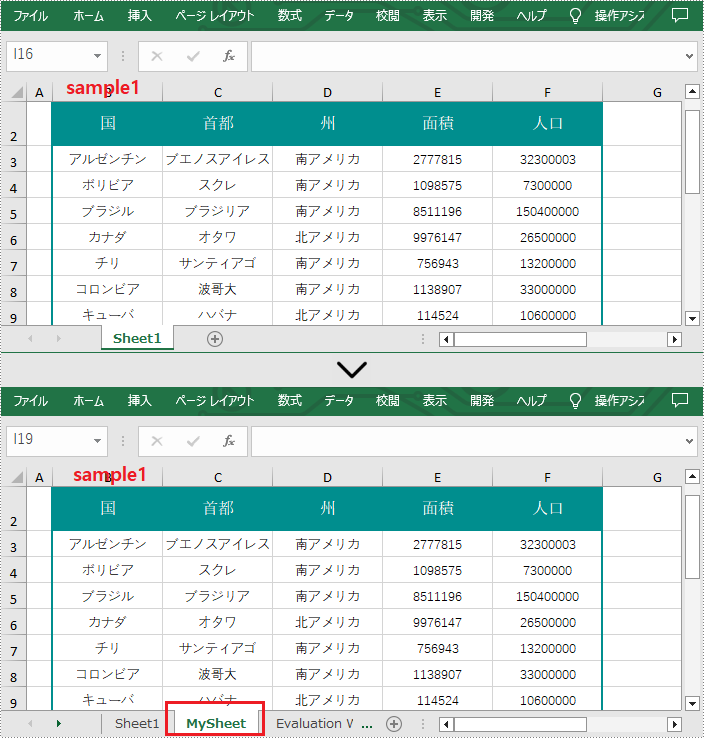
同じブック内でワークシートを複製することもできます。新しいワークシートをこのブックに追加し、その後、特定のシートを新しいワークシートに複製します。以下は Excel ブック内でワークシートを複製する手順です。
import com.spire.xls.*;
public class copySheetWithinWorkbook {
public static void main(String[] args) {
//Workbookオブジェクトを作成する
Workbook workbook = new Workbook();
//ディスクから「sample1.xlsx」をロードする
workbook.loadFromFile("sample1.xlsx");
//最初のシートを取得し、新しいシートを追加する
Worksheet sheet = workbook.getWorksheets().get(0);
Worksheet sheet1 = workbook.getWorksheets().add("MySheet");
//最初のシートを2番目のシートに複製する
sheet1.copyFrom(sheet);
//出力パスを指定する
String result = "output/CopySheetWithinWorkbook.xlsx";
//結果ファイルを保存する
workbook.saveToFile(result, ExcelVersion.Version2013);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Excel におけるコメントは、セルに追加できるテキストブロックであり、主にセルの内容に関する追加の説明や補足情報を提供するために使用されます。ユーザーは特定のセルにコメントを追加し、ワークシートのデータをより詳しく説明することができます。しかし、時にはコメントが多すぎて視覚的な混雑を引き起こしたり、他のコンテンツを妨げることがあります。この問題を回避するために、既存のコメントをプログラムで非表示にすることができ、ワークシートを整理して読みやすくすることができます。必要な場合には、非表示にされたコメントを簡単に表示することもできます。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET で Excel のコメントを表示または非表示にする方法を紹介します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSSpire.XLS for .NET は、Worksheet.Comments[].IsVisble プロパティを提供して、コメントの表示/非表示を制御します。このプロパティを 「false」に設定することで、既存のコメントを簡単に非表示にすることができます。以下は、Excel でコメントを非表示にするための詳細な手順です。
using Spire.Xls;
namespace ShowExcelComments
{
class Program
{
static void Main(string[] args)
{
{
//Workbookインスタンスを初期化し、サンプルファイルを読み込む
Workbook workbook = new Workbook();
workbook.LoadFromFile("Comments.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//ワークシート内の特定のコメントを非表示にする
sheet.Comments[0].IsVisible = false;
//結果ファイルを保存する
workbook.SaveToFile("HideComment.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}
}Imports Spire.Xls
Namespace ShowExcelComments
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookインスタンスを初期化し、サンプルファイルを読み込む
Dim workbook As Workbook = New Workbook
workbook.LoadFromFile("Comments.xlsx")
'最初のワークシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'ワークシート内の特定のコメントを非表示にする
sheet.Comments(0).IsVisible = false
'結果ファイルを保存する
workbook.SaveToFile("HideComment.xlsx", ExcelVersion.Version2013)
workbook.Dispose
End Sub
End Class
End Namespace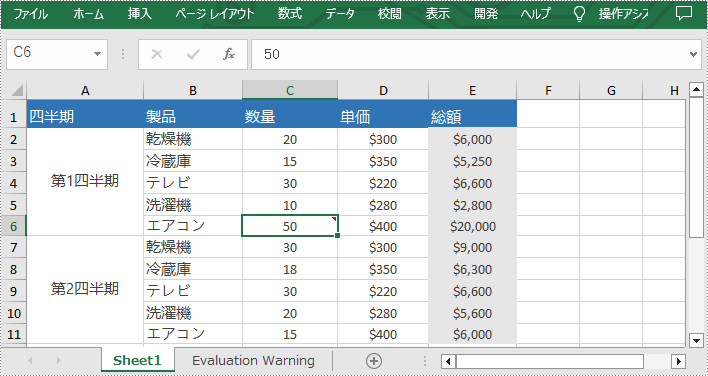
必要な場合には、非表示にされたコメントを簡単に表示することもできます。再び表示したい場合は、Worksheet.Comments[].IsVisble プロパティを「true」に設定してください。以下は、Excel でコメントを表示する手順です。
using Spire.Xls;
namespace ShowExcelComments
{
class Program
{
static void Main(string[] args)
{
{
//Workbookインスタンスを初期化し、サンプルファイルを読み込む
Workbook workbook = new Workbook();
workbook.LoadFromFile("HideComment.xlsx");
//最初のワークシートを取得する
Worksheet sheet = workbook.Worksheets[0];
//特定のコメントを表示する
sheet.Comments[0].IsVisible = true;
//結果ファイルを保存する
workbook.SaveToFile("ShowComment.xlsx", ExcelVersion.Version2013);
workbook.Dispose();
}
}
}
}Imports Spire.Xls
Namespace ShowExcelComments
Class Program
Private Shared Sub Main(ByVal args() As String)
'Workbookインスタンスを初期化し、サンプルファイルを読み込む
Dim workbook As Workbook = New Workbook
workbook.LoadFromFile("HideComment.xlsx")
'最初のワークシートを取得する
Dim sheet As Worksheet = workbook.Worksheets(0)
'特定のコメントを表示する
sheet.Comments(0).IsVisible = true
'結果ファイルを保存する
workbook.SaveToFile("ShowComment.xlsx", ExcelVersion.Version2013)
workbook.Dispose
End Sub
End Class
End Namespace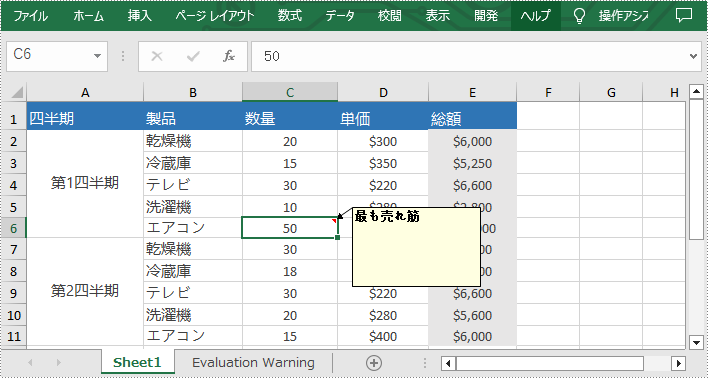
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
特定の領域内で差し込み印刷(メールマージ)を実行すると、領域内のすべての差し込みフィールドがデータソースの各レコードに対して繰り返されます。この記事では、Spire.Doc for Java を使用して領域での差し込み印刷を実行する方法について説明します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.6.0</version>
</dependency>
</dependencies>メールマージ領域を作成するには、領域の開始点と終了点を指定する必要があります。たとえば、次の Word ドキュメントのテンプレートには、"TableStart:Country" フィールドと "TableEnd:Country" フィールドでマークされた "Country" リージョンが含まれています。
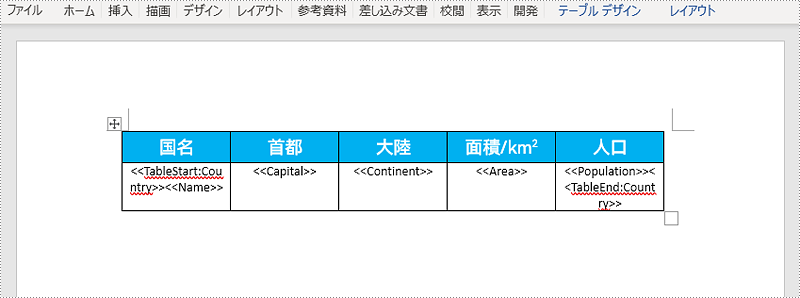
以下は、データのソースとして使用される XML ファイルのサンプルです。
<?xml version="1.0" encoding="UTF-8"?>
<Data>
<Country>
<Capital>Buenos Aires</Capital>
<Name>Argentina</Name>
<Continent>South America</Continent>
<Area>2777815</Area>
<Population>32300003</Population>
</Country>
<Country>
<Capital>La Paz</Capital>
<Name>Bolivia</Name>
<Continent>South America</Continent>
<Area>1098575</Area>
<Population>7300000</Population>
</Country>
<Country>
<Capital>Brasilia</Capital>
<Name>Brazil</Name>
<Continent>South America</Continent>
<Area>8511196</Area>
<Population>150400000</Population>
</Country>
<Country>
<Capital>Buenos Aires</Capital>
<Name>Argentina</Name>
<Continent>South America</Continent>
<Area>2777815</Area>
<Population>32300003</Population>
</Country>
<Country>
<Capital>La Paz</Capital>
<Name>Bolivia</Name>
<Continent>South America</Continent>
<Area>1098575</Area>
<Population>7300000</Population>
</Country>
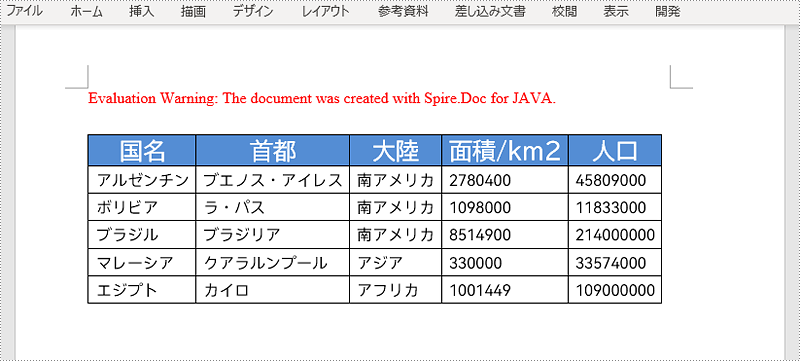
</Data>以下は、領域で差し込み印刷を実行する手順です。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class mailMergeWithRegion {
public static void main(String[] args) throws Exception {
//Documentのオブジェクトをします
Document doc = new Document();
//Wordドキュメントを
doc.loadFromFile("サンプル.docx");
//Execute mail merge with a region
doc.getMailMerge().executeWidthRegion("データ.xml");
//Save the changes to another fil
doc.saveToFile("領域でのメールマージ.docx", FileFormat.Docx_2013);
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc for Java 11.7.0のリリースを発表できることを嬉しく思います。このバージョンで、PrivateFontPathオブジェクトをストリーム形式で作成する機能がサポートされています。WordをPDFに変換した後、ユーザ情報の注釈表示を一貫して維持する機能をサポートしています。さらに、WordからPDFへの変換機能も強化されました。また、文書をロードした後に保存された新しい文書の透かしが失われるなど、既知の問題も修正されました。詳細については、以下の内容をご覧ください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-9004 | PrivateFontPathオブジェクトをストリーム形式で作成する機能がサポートされています。
//Constructor PrivateFontPath(String fontName,InputStream fontStream); PrivateFontPath(String fontName,int fontStyle,InputStream fontStream); //getter setter setFontStream(InputStream value); getFontStream(); |
| New feature | SPIREDOC-9423 | WordをPDFに変換した後、ユーザ情報の注釈表示を一貫して維持する機能をサポートしています。
ToPdfParameterList parms = new ToPdfParameterList(); parms.useAuthorNameToDisplayCommentLabel(true); |
| Bug | SPIREDOC-9044 | WordをPDFに変換した後、結果文書のページ分割が一致しない問題が修正されました。 |
| Bug | SPIREDOC-9053 | Wordの目次を更新した後、PDFに保存しても機能しない問題が修正されました。 |
| Bug | SPIREDOC-9129 | 文書をロードした後、保存された新しい文書の透かしが失われる問題が修正されました。 |
| Bug | SPIREDOC-9323 | WordをPDFに変換した後、1レベル見出しが消える問題が修正されました。 |
| Bug | SPIREDOC-9346 | Word文書を比較する際に、「Index is less than 0 or more than or equal to the list count」というエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-9347 | WordをHTMLに変換した後、再びWordに戻すとブックマークが消える問題が修正されました。 |
| Bug | SPIREDOC-9382 | 文書をクローンする際に、「An element with the same key already exists in the dictionary.」というエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-9386 | HTMLをWordに変換した後、段落に余分なインデントが発生する問題が修正されました。 |
| Bug | SPIREDOC-9431 | 文書を結合した後に、目次の更新が失敗する問題が修正されました。 |
| Bug | SPIREDOC-9435 | WordをPDFに変換した後、コンテンツが消失する問題が修正されました。 |
| Bug | SPIREDOC-9457 | WordをPDFに変換した後、レイアウトが一致しない問題が修正されました。 |
| Bug | SPIREDOC-9462 | 修正されたWord文書で変更を受け入れた後、余分な空白の段落が発生する問題が修正されました。 |
| Bug | SPIREDOC-9500 | Doc形式の文書をロードする際に、「No have this value 110」というエラーが発生する問題が修正されました。 |
| Bug | SPIREDOC-9509 SPIREDOC-9527 |
WordをPDFに変換した後、コンテンツが一致しない問題が修正されました。 |
| Bug | SPIREDOC-9520 | WordをPDFに変換した後、フォントが変更される問題が修正されました。 |
| Bug | SPIREDOC-9529 | WPSルールでWordをPDFに変換した後、ページ数が正しくない問題が修正されました。 |
PDF ドキュメント内のハイパーリンクを使用することで、ユーザーはページにジャンプしたりドキュメントを開いたりすることができ、PDF ファイルはよりインタラクティブで使いやすくなります。しかし、リンクの対象サイトが変更された場合や、リンクが誤ったページを指している場合は、ドキュメントのユーザーにトラブルや誤解を招く可能性があります。そのため、PDF ドキュメント内の誤ったまたは無効なハイパーリンクを変更または削除することは、ハイパーリンクの正確性と使いやすさを確保するために非常に重要であり、ユーザーにとってより良い読書体験を提供することができます。この記事では、Spire.PDF for .NET を使用して、.NET プログラムを介して PDF ドキュメント内のハイパーリンクを変更または削除する方法を紹介します。
まず、Spire.PDF for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFPDF ページ上のハイパーリンクの URL を変更するには、ハイパーリンク注釈ウィジェットを取得し、PdfUriAnnotationWidget.Uri プロパティを使用して URL を再設定する必要があります。詳しい手順は以下の通りです。
using Spire.Pdf;
using Spire.Pdf.Annotations;
using System;
namespace ChangeHyperlink
{
internal class Program
{
static void Main(string[] args)
{
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.LoadFromFile("サンプル.pdf");
//最初のページを取得する
PdfPageBase page = pdf.Pages[0];
//最初のハイパーリンクを取得する
PdfUriAnnotationWidget url = (PdfUriAnnotationWidget)page.AnnotationsWidget[0];
//このハイパーリンクのURLを再設定する
url.Uri = "https://www.jma.go.jp/jma/kishou/know/whitep/3-1.html";
//PDFファイルを保存する
pdf.SaveToFile("ハイパーリンクの変更.pdf");
pdf.Dispose();
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Annotations
Imports System
Namespace ChangeHyperlink
Friend Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'PDFファイルを読み込む
pdf.LoadFromFile("サンプル.pdf")
'最初のページを取得する
Dim page As PdfPageBase = pdf.Pages(0)
'最初のハイパーリンクを取得する
Dim url As PdfUriAnnotationWidget = CType(page.AnnotationsWidget(0), PdfUriAnnotationWidget)
'このハイパーリンクのURLを再設定する
url.Uri = "https://www.jma.go.jp/jma/kishou/know/whitep/3-1.html"
'PDFファイルを保存する
pdf.SaveToFile("ハイパーリンクの変更.pdf")
pdf.Dispose()
End Sub
End Class
End Namespace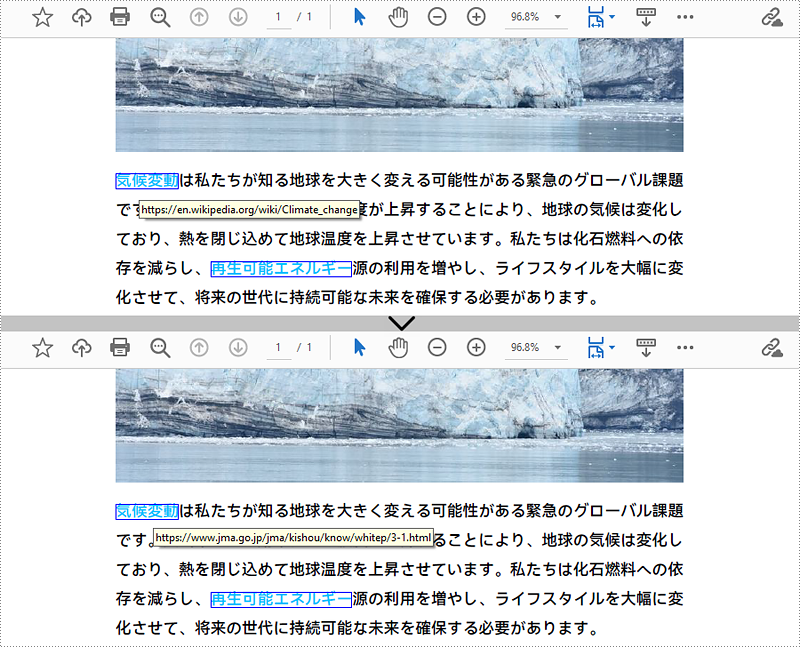
Spire.PDF for .NET は、PdfPageBase.AnnotationsWidget.RemoveAt() メソッドを提供し、インデックスによって PDF ページ上のハイパーリンクを削除します。PDF ドキュメントからすべてのハイパーリンクを削除するには、ページを繰り返し、各ページの注釈ウィジェットを取得し、注釈が PdfUriAnnotationWidget クラスのインスタンスであるかどうかを確認し、もしそうであれば注釈を削除する必要があります。以下に詳細な手順を示します。
using Spire.Pdf;
using Spire.Pdf.Annotations;
using System;
using System.Dynamic;
namespace DeleteHyperlink
{
internal class Program
{
static void Main(string[] args)
{
//PdfDocumentのオブジェクトを作成する
PdfDocument pdf = new PdfDocument();
//PDFファイルを読み込む
pdf.LoadFromFile("サンプル.pdf");
//最初のページの2番目のハイパーリンクを削除する
//PdfPageBase page = pdf.Pages[0];
//page.AnnotationsWidget.RemoveAt(1);
//ドキュメント内のすべてのハイパーリンクを削除する
//ドキュメント内のページをループする
foreach (PdfPageBase page in pdf.Pages)
{
//ページ内の注釈のコレクションを取得する
PdfAnnotationCollection collection = page.AnnotationsWidget;
for (int i = collection.Count - 1; i >= 0; i--)
{
PdfAnnotation annotation = collection[i];
//注釈がPdfUriAnnotationWidgetのインスタンスであるかどうかを判定する
if (annotation is PdfUriAnnotationWidget)
{
PdfUriAnnotationWidget url = (PdfUriAnnotationWidget)annotation;
//ハイパーリンクを削除する
collection.Remove(url);
}
}
}
//ドキュメントを保存する
pdf.SaveToFile("ハイパーリンクの削除.pdf");
pdf.Dispose();
}
}
}Imports Spire.Pdf
Imports Spire.Pdf.Annotations
Imports System
Imports System.Dynamic
Namespace DeleteHyperlink
Friend Class Program
Shared Sub Main(ByVal args() As String)
'PdfDocumentのオブジェクトを作成する
Dim pdf As PdfDocument = New PdfDocument()
'PDFファイルを読み込む
pdf.LoadFromFile("サンプル.pdf")
'最初のページの2番目のハイパーリンクを削除する
'PdfPageBase page = pdf.Pages[0];
'page.AnnotationsWidget.RemoveAt(1);
'ドキュメント内のすべてのハイパーリンクを削除する
'ドキュメント内のページをループする
Dim page As PdfPageBase
For Each page In pdf.Pages
'ページ内の注釈のコレクションを取得する
Dim collection As PdfAnnotationCollection = page.AnnotationsWidget
Dim i As Integer
For i = collection.Count - 1 To 0 Step i - 1
Dim annotation As PdfAnnotation = collection(i)
'注釈がPdfUriAnnotationWidgetのインスタンスであるかどうかを判定する
If TypeOf annotation Is PdfUriAnnotationWidget Then
Dim url As PdfUriAnnotationWidget = CType(annotation, PdfUriAnnotationWidget)
'ハイパーリンクを削除する
collection.Remove(url)
End If
Next
Next
'ドキュメントを保存する
pdf.SaveToFile("ハイパーリンクの削除.pdf")
pdf.Dispose()
End Sub
End Class
End Namespace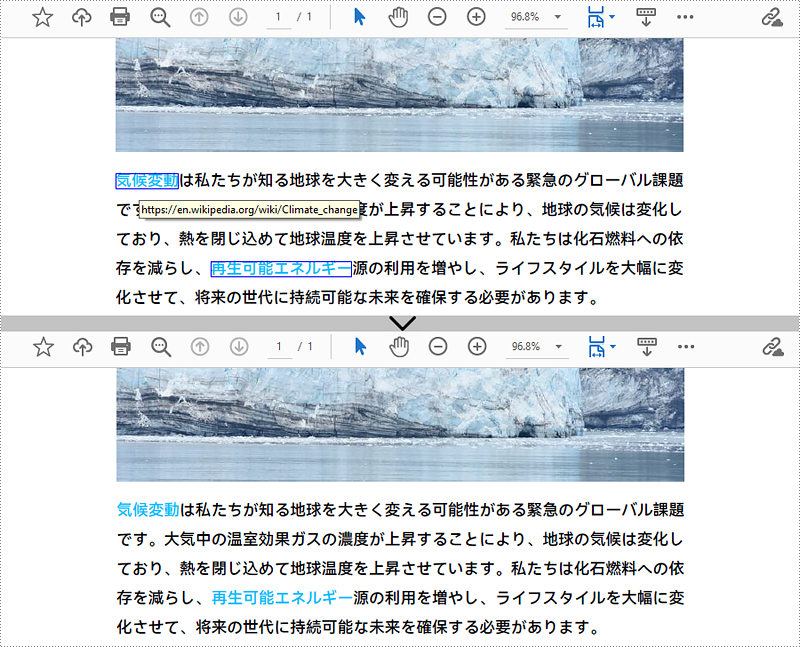
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office 8.7.0のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.Docでは先頭行インデントの文字数の設定がサポートされています。Spire.PDFでは構造化された表を含むラベル付きPDFファイルの作成もサポートされています。Spire.XLS ではNETWORKDAYS.INTL関数をサポートする機能が追加されました。Spire.Presentationでは、 PPTX 2016およびPPTX 2019がサポートされています。さらに、多くの既知の問題も修正しました。詳細は以下の内容を読んでください。
このバージョンでは、Spire.Doc,Spire.PDF,Spire.XLS,Spire.Email,Spire.DocViewer, Spire.PDFViewer,Spire.Presentation,Spire.Spreadsheet, Spire.OfficeViewer, Spire.Barcode, Spire.DataExportの最新バージョンが含まれています。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-3548 | 先頭行インデントの文字数の設定がサポートされています。
paragraph.ParagraphFormat.FirstLineIndentChars = value; 注記: valueが正数の場合:先頭行インデントが設定されます。 valueが負数の場合:ハングインデントが設定されます。 valueが0の場合、paragraph.Format.SetFirstLineIndentChars(0)メソッドを使用して設定します。 |
| New feature | SPIREDOC-4467 | テキストボックスのアスペクト比のロック機能がされています。
textBox.AspectRatioLocked = true; //テキストボックスを追加する場合、デフォルトではアスペクト比はロックされません |
| New feature | SPIREDOC-7850/td> | 画像のアスペクト比のロック機能がされています。
picture.AspectRatioLocked = true; //画像を追加する場合、デフォルトではアスペクト比がロックされます |
| New feature | SPIREDOC-9137 | OfficeMathには、EQFieldをOfficeMathに変換するためのFromEqField()という静的メソッドが追加されました。 |
| Bug | SPIREDOC-3366 | 自動的に縦横比をロックする画像の幅を設定する際、高さが適切に調整されない問題が修正されました。 |
| Bug | SPIREDOC-7839 | WordをPDFに変換する際に、アプリケーションが「Object reference not set to an instance of an object」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8340 | WordをPDFに変換する際に、アプリケーションが「System.ArgumentOutOfRangeException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9341 | メールマージフィールドの値が正しく更新されない問題が修正されました。 |
| Bug | SPIREDOC-9371 | 文書を比較する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9450 | 取得された段落の前後の値が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9525 | Dotm文書とDocx文書を比較する際に、アプリケーションが「System.InvalidOperationException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9031 | 改行を含むテキストフィールドの値が誤って取得される問題が修正されました。 |
| Bug | SPIREDOC-9285 | 文書の比較時に、アプリケーションが「System.ArgumentException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9339 | Word を HTML に変換する際に、アプリケーションが「System.ArgumentException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9365 | メールマージフィールドの更新に失敗する問題が修正されました。 |
| Bug | SPIREDOC-9379 | 数字で終わるテキストを置換する際に、wholeWord パラメータが true に設定されても効果がない問題を修正しました。 |
| Bug | SPIREDOC-9396 | Word を PDF に変換した後、一部のテキストの整列が不一致になる問題を修正しました。 |
| Bug | SPIREDOC-9430 | Word を PDF に変換した後、記号の位置が上に移動する問題を修正しました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4712 | NETWORKDAYS.INTL関数をサポートする機能が追加されました。 |
| Bug | SPIREXLS-411 | 追加された数値が日付形式で表示される問題が修正されました。 |
| Bug | SPIREXLS-698 | グラフを画像に変換した後に、内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-883 | 分割ページでセルの上枠が印刷されない問題が修正されました。 |
| Bug | SPIREXLS-891 | シェイプを削除するときに、プログラムが「ArgumentOutOfRangeException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-1158 | ピボットテーブルの特定行のフォント色が変更しても効果がない問題が修正されました。 |
| Bug | SPIREXLS-2286 | ピボットテーブルのフォントが変更しても効果がない問題が修正されました。 |
| Bug | SPIREXLS-4711 | ExcelをHTMLに変換した後に破線が失われる問題が修正されました。 |
| Bug | SPIREXLS-4722 | CalculateAllValue()メソッドを使用する際にプログラムが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4728 | 結合セルにフィルタを追加した後、フィルタボタンが機能しなくなる問題が修正されました。 |
| Bug | SPIREXLS-4738 | 行を削除した後に残りの行数が正しくならない問題が修正されました。 |
| Bug | SPIREXLS-4748 | worksheet.ExportDataTable()メソッドを使用してデータをエクスポートする際に、形式が正しくならない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2244 | PPTX 2016およびPPTX 2019がサポートされています。
Spire.Presentation.FileFormat.Pptx2016 Spire.Presentation.FileFormat.Pptx2019 |
| New feature | SPIREPPT-2266 | グラフの横軸から軸線までの距離の設定にがサポートされています。
Presentation ppt = new Presentation(); IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.ColumnClustered, new RectangleF(50, 50, 400, 400)); //PrimaryCategory軸を取得する IChartAxis chartAxis = chart.PrimaryCategoryAxis; //「軸からの距離」を設定する chartAxis.LabelsDistance = 200; //ファイルに保存する ppt.SaveToFile(outputFile, FileFormat.Pptx2013); |
| Bug | SPIREPPT-2279 | PPTファイルを分割した後に生成されたファイルを開くことができなかった問題が修正されました。 |
| Bug | SPIREPPT-2280 | PPTファイルを読み込む際に、プログラムがヌルポインタエラーを報告する問題が修正されました。 |
| Bug | SPIREPPT-2285 | 棒グラフが列に切り替わるかどうかを判断する際に、プログラムがエラーを報告する問題が修正されました。 |
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5964 | 構造化された表を含むラベル付きPDFファイルの作成がサポートされています。
PdfDocument doc = new PdfDocument();
PdfPageBase page = doc.Pages.Add(PdfPageSize.A4, new PdfMargins(20));
page.SetTabOrder(TabOrder.Structure);
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
taggedContent.SetLanguage("en-US");
taggedContent.SetTitle("test");
taggedContent.SetPdfUA1Identification();
PdfTrueTypeFont font = new PdfTrueTypeFont(new System.Drawing.Font("Times New Roman", 14), true);
PdfSolidBrush brush = new PdfSolidBrush(Color.Black);
PdfStructureElement document = taggedContent.StructureTreeRoot.AppendChildElement(PdfStandardStructTypes.Document);
PdfStructureElement heading1 = document.AppendChildElement(PdfStandardStructTypes.HeadingLevel1);
heading1.BeginMarkedContent(page);
string headingText = "What is a Tagged PDF?";
page.Canvas.DrawString(headingText, font, brush, new PointF(0, 0));
heading1.EndMarkedContent(page);
PdfStructureElement paragraph = document.AppendChildElement(PdfStandardStructTypes.Paragraph);
paragraph.BeginMarkedContent(page);
string paragraphText = ""Tagged PDF" doesn’t seem like a life-changing term. But for some, it is. For people who are " +
"blind or have low vision and use assistive technology (such as screen readers and connected Braille displays) to " +
"access information, an untagged PDF means they are missing out on information contained in the document because assistive " +
"technology cannot "read" untagged PDFs. Digital accessibility has opened up so many avenues to information that were once " +
"closed to people with visual disabilities, but PDFs often get left out of the equation.";
RectangleF rect = new RectangleF(0, 30, page.Canvas.ClientSize.Width, page.Canvas.ClientSize.Height);
page.Canvas.DrawString(paragraphText, font, brush, rect);
paragraph.EndMarkedContent(page);
PdfStructureElement figure = document.AppendChildElement(PdfStandardStructTypes.Figure);
figure.BeginMarkedContent(page);
PdfImage image = PdfImage.FromFile(TestUtil.DataPath + "ImgFiles/Bug_3938.png");
page.Canvas.DrawImage(image, new PointF(0, 150));
figure.EndMarkedContent(page);
PdfStructureElement table = document.AppendChildElement(PdfStandardStructTypes.Table);
PdfTable pdfTable = new PdfTable();
pdfTable.Style.DefaultStyle.Font = font;
System.Data.DataTable dataTable = new System.Data.DataTable();
dataTable.Columns.Add("Name");
dataTable.Columns.Add("Age");
dataTable.Columns.Add("Sex");
dataTable.Rows.Add(new string[] { "John", "22", "Male" });
dataTable.Rows.Add(new string[] { "Katty", "25", "Female" });
pdfTable.DataSource = dataTable;
pdfTable.Style.ShowHeader = true;
pdfTable.StructureElement = table;
pdfTable.Draw(page.Canvas, new PointF(0, 280), 300f);
doc.SaveToFile("1.pdf");
doc.Dispose(); |
| New feature | SPIREPDF-6038 | 高さに合わせたズームレベルのサポートが追加されました。
PdfDocument myPdf = new PdfDocument("test.pdf");
PdfPageBase page = myPdf .Pages[0];
PdfDestination dest = new PdfDestination(page, new PointF(-40f, -40f));
dest.Mode = PdfDestinationMode.FitV;
PdfGoToAction gotoaction = new PdfGoToAction(dest);
myPdf.AfterOpenAction = gotoaction;
myPdf.ViewerPreferences.PageMode = PdfPageMode.UseOutlines;
myPdf.SaveToFile("FitBH.pdf");
myPdf.Close(); |
| Bug | SPIREPDF-6011 | PDFをPDF/A3Aに変換する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6032 | PDFをPDF/A1Bに変換した後の内容が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6047 | PDFを画像に変換したり、PDFを印刷する際にフォントが変更される問題が修正されました。 |
| Bug | SPIREPDF-6051 | ページからテキストを抽出する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6076 | PDFを印刷する際に印章の回転が歪む問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDFVIEWER-561 | スクロール時に文書のコンテンツがスムーズに読み込まれない問題が修正されました。 |
| Bug | SPIREPDFVIEWER-564 | 文書のコンテンツが完全に表示されない問題が修正されました。 |
Word ドキュメントの透かしは、半透明のテキストまたは画像の背景です。透かしは、そのドキュメントが機密文書であること、または単なる草稿であることを読者に思い出させるためにテキストの透かしを使用したり、会社の写真で著作権を宣言したりするなど、ドキュメントに関する重要な何かを強調するために使用されます。時には透かしがドキュメントの読みやすさに影響することもあり、透かしを除去したい場合、Spire.Doc for Java が大いに役立ちます。この記事では、Spire.Doc for Java を使用して Word ドキュメントから透かしを削除する詳細な手順を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.9.8</version>
</dependency>
</dependencies>Spire.Doc for Java が提供する Document.setWatermark() メソッドを使用して透かしを null に設定することで、Word ドキュメントから透かしを削除することができます。 テキスト透かしも画像透かしもこの方法で削除できます。詳しい手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class removeWordWatermark {
public static void main(String[] args) {
//Documentのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//透かしをnullに設定する
doc.setWatermark(null);
//ドキュメントを保存する
doc.saveToFile("透かしの削除.docx", FileFormat.Auto);
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.PDF for Java 9.7.0のリリースを発表できることをうれしく思います。このバージョンでは、PDFをWordに変換するための新しいインタフェースと、PDFをHTMLに変換するための新しい方法が追加されました。また、PDFからPPTX、HTML、および画像への変換機能も強化されました。また、クロップボックスの設定が機能しないなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | PDFをWordに変換するための新しいインタフェースが追加されました。
PdfToWordConverter converter(inputPath); converter.saveToDocx(OutputPath); converter.dispose(); |
| New feature | - | PDFをHTMLに変換するための新しい方法が追加されました。
pdfDocument.getConvertOptions().setPdfToHtmlOptions(bool useEmbeddedSvg, bool useEmbeddedImg) pdfDocument.getConvertOptions().setPdfToHtmlOptions(bool useEmbeddedSvg, bool useEmbeddedImg, int maxPageOneFile) |
| Bug | SPIREPDF-6008 | PDFをPPTXに変換した後に、フォントサイズが変更される問題が修正されました。 |
| Bug | SPIREPDF-6035 | クロップボックスの設定が機能しない問題が修正されました。 |
| Bug | SPIREPDF-6046 | キーワードの検索に失敗する問題が修正されました。 |
| Bug | SPIREPDF-6049 | キーワードを検索する際に、アプリケーションが「Parameter 'emSize' 0.0 is invalid」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6050 | PDFをHTMLに変換した後に、コンテンツが重なる問題が修正されました。 |
| Bug | SPIREPDF-6061 | 画像を追加する際に、アプリケーションが「No have this JpegTablesMode」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6073 | PDFを画像に変換した後に、画像の内容が切り取られる問題が修正されました。 |
| Bug | SPIREPDF-6083 | グリッドのテキストの垂直方向の揃えや下揃えが正しくない問題が修正されました。 |
XPS は、PDF に似た形式であり、ファイルのレイアウト、外観、印刷情報に XML 形式を使用しています。XPS は Microsoft によって開発され、Windows オペレーティングシステムでサポートされるファイル形式です。他のソフトウェアをインストールせずに Windows コンピュータで PDF ファイルを使用したい場合は、XPS 形式に変換することができます。同様に、Mac ユーザーと XPS ファイルを共有したり、他のデバイスで表示する必要がある場合は、PDF に変換することをおすすめします。この記事では、Spire.PDF for .NET を使用して XPS と PDF 間の相互変換方法を紹介します。
まず、Spire.PDF for .NET パッケージに含まれている DLL ファイルを.NETプロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.PDFSpire.PDF for .NET は、PDF をさまざまなファイル形式に変換する機能をサポートしています。PDF から XPS への変換は、わずか3行のコアコードで実現できます。以下に詳細な手順を示します。
using Spire.Pdf;
namespace ConvertPdfToXps
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//サンプルPDFドキュメントをロードする
pdf.LoadFromFile("sample.pdf");
//XPS形式で保存する
pdf.SaveToFile("ToXPS.xps", FileFormat.XPS);
pdf.Close();
}
}
}Imports Spire.PDF
Namespace ConvertPdfToXps
Class Program
Private Shared Sub Main(ByVal args() As String)
'PdfDocumentインスタンスを作成する
Dim pdf As PdfDocument = New PdfDocument
'サンプルPDFドキュメントをロードする
pdf.LoadFromFile("sample.pdf")
' XPS形式で保存する
pdf.SaveToFile("ToXPS.xps", FileFormat.XPS)
pdf.Close()
End Sub
End Class
End Namespace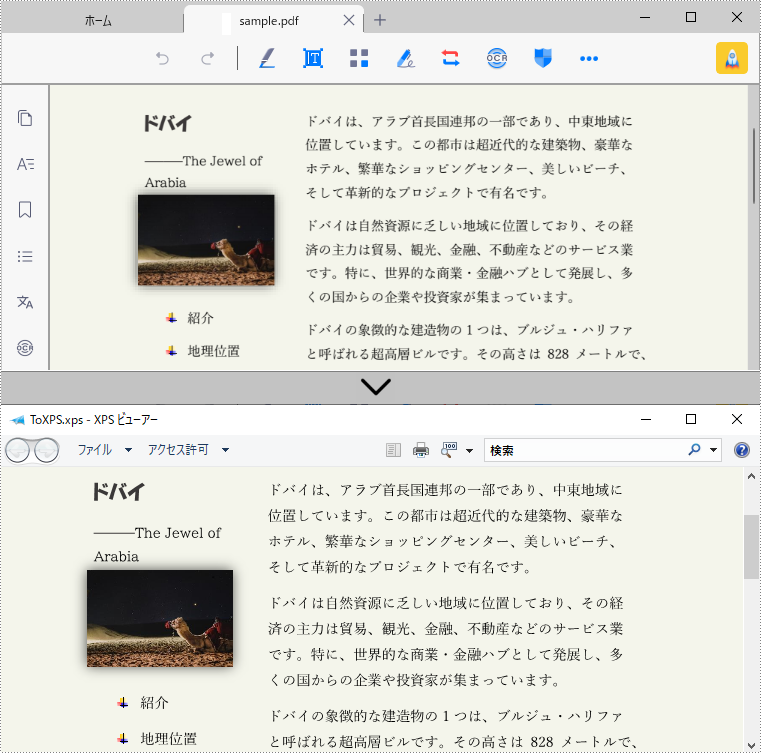
Spire.PDF for .NET は、XPS から PDF への変換もサポートしています。変換時には、PdfDocument.ConvertOptions.SetXpsToPdfOptions() メソッドを使用して生成される PDF ファイルで高品質な画像を維持するオプションを設定できます。以下に詳細な手順を示します。
using Spire.Pdf;
namespace ConvertXPStoPDF
{
class Program
{
static void Main(string[] args)
{
//PdfDocumentインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//サンプルXPSファイルをロードする
pdf.LoadFromFile("sample.xps", FileFormat.XPS);
//pdf.LoadFromXPS("sample.xps");
//XPSをPDFに変換したときの高品質な画像を維持する
pdf.ConvertOptions.SetXpsToPdfOptions(true);
//XPSファイルをPDFファイルに変換する
pdf.SaveToFile("XPStoPDF.pdf", FileFormat.PDF);
}
}
}Imports Spire.PDF
Namespace ConvertXPStoPDF
Class Program
Private Shared Sub Main(ByVal args() As String)
'PdfDocumentインスタンスを作成する
Dim pdf As PdfDocument = New PdfDocument
'サンプルXPSファイルをロードする
pdf.LoadFromFile("sample.xps", FileFormat.XPS)
'pdf.LoadFromXPS("sample.xps");
'XPSをPDFに変換したときの高品質な画像を維持する
pdf.ConvertOptions.SetXpsToPdfOptions(True)
'XPSファイルをPDFファイルに変換する
pdf.SaveToFile("XPStoPDF.pdf", FileFormat.PDF)
End Sub
End Class
End Namespace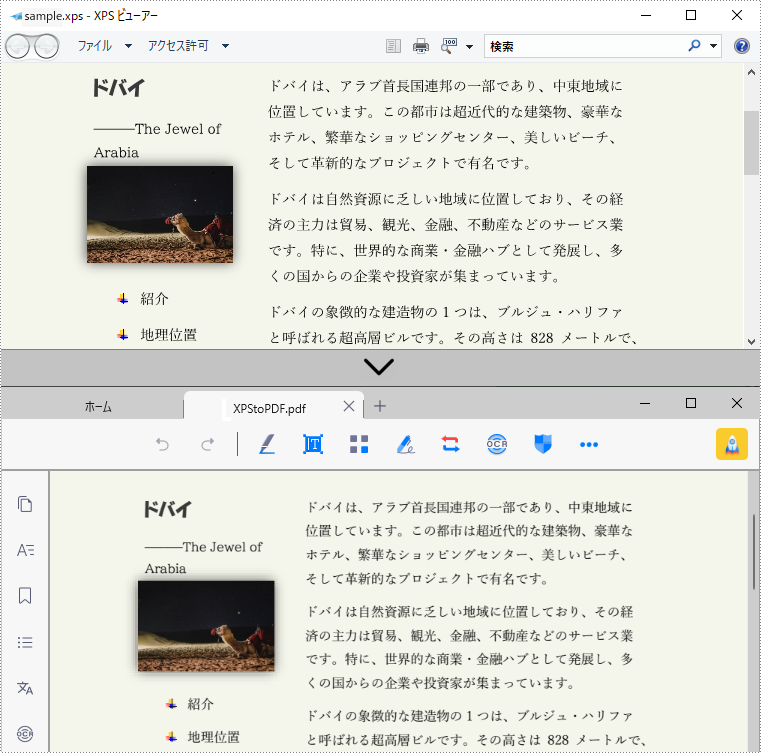
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
ハイパーリンクは Excel ドキュメントの便利な機能であり、Web サイト、電子メール アドレス、同じワークブック内の特定のセルなどの他の関連リソースにすばやくアクセスできます。ただし、さまざまな理由で既存のハイパーリンクを変更または削除する必要がある場合があります。例えば、切断されたリンクを更新したり、スペルミスを修正したり、古い情報を削除したりします。この記事では、Spire.XLS for Java を使用して Excel でハイパーリンクを変更または削除する方法を紹介します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.6.5</version>
</dependency>
</dependencies>ハイパーリンクがスペルミスやその他の理由により無効になった場合、修正する必要があります。以下の手順では、Excelファイル内の既存のハイパーリンクを変更する方法を示しています。
import com.spire.xls.*;
import com.spire.xls.collections.HyperLinksCollection;
public class ModifyHyperlink {
public static void main(String[] args) {
//Workbookクラスのインスタンスを作成する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.loadFromFile("sample.xlsx");
//最初のシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
//シート内のすべてのハイパーリンクのコレクションを取得する
HyperLinksCollection links = sheet.getHyperLinks();
//TextToDisplayとAddressプロパティの値を変更する
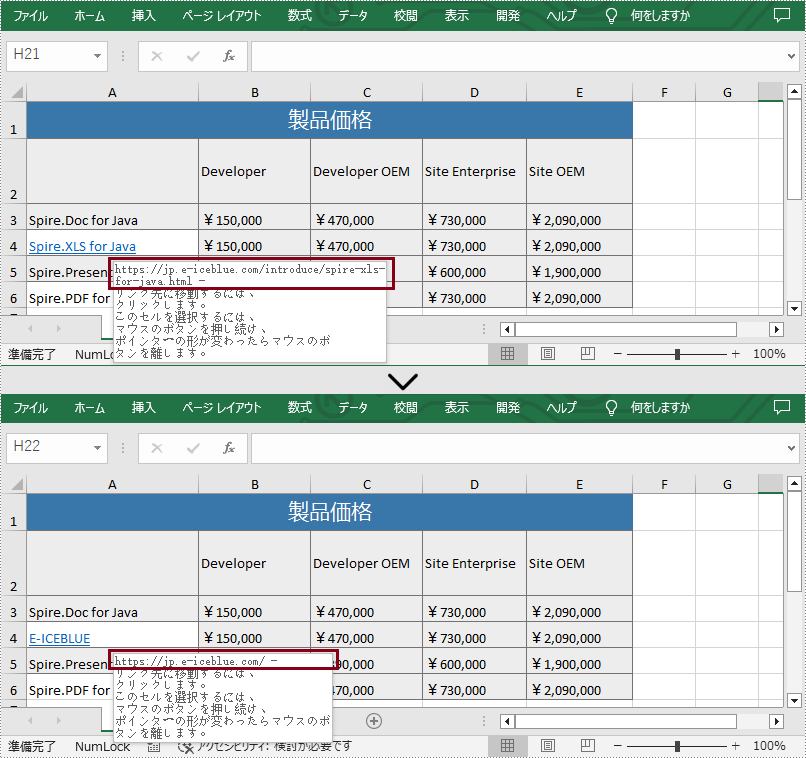
links.get(0).setTextToDisplay("E-ICEBLUE");
links.get(0).setAddress("https://jp.e-iceblue.com");
//結果ファイルを保存保存
workbook.saveToFile("ModifyHyperlink.xlsx", ExcelVersion.Version2013);
workbook.dispose();
}
}
Spire.XLS for Java には、ハイパーリンクを削除するための Worksheet.getHyperLinks().removeAt() メソッドも用意されています。以下は Java で Excel からハイパーリンクを削除する手順です。
import com.spire.xls.*;
import com.spire.xls.collections.HyperLinksCollection;
public class RemoveHyperlink {
public static void main(String[] args) {
//Workbookクラスのインスタンスを作成する
Workbook workbook = new Workbook();
//Excelファイルをロードする
workbook.loadFromFile("sample.xlsx");
//最初のシートを取得する
Worksheet sheet = workbook.getWorksheets().get(0);
//シート内のすべてのハイパーリンクのコレクションを取得する
HyperLinksCollection links = sheet.getHyperLinks();
//最初のハイパーリンクを削除し、リンクテキストを保持する
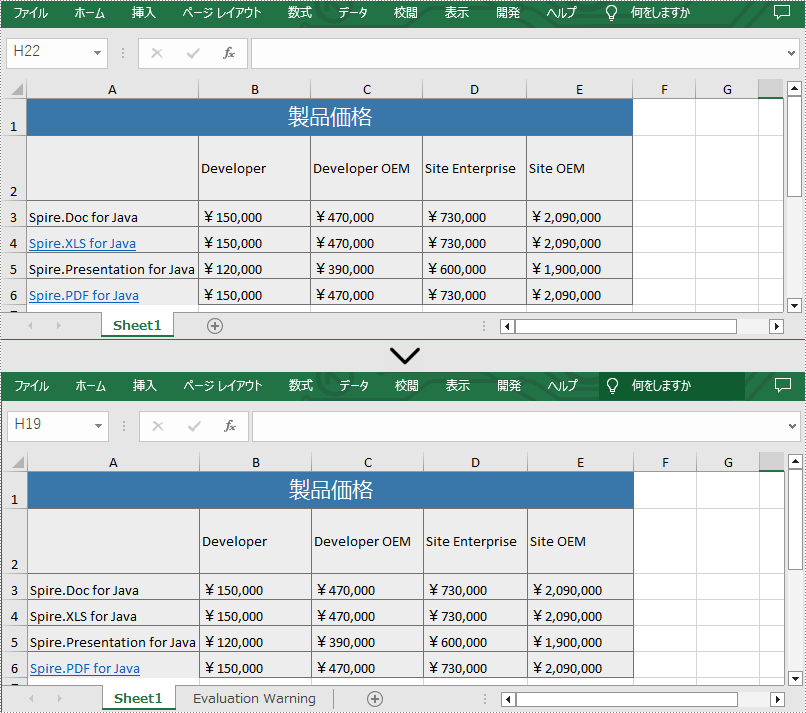
sheet.getHyperLinks().removeAt(0);
//セル内のすべてのコンテンツを削除する
//sheet.getCellRange("A6").clearAll();
//結果ファイルを保存する
String output = "RemoveHyperlink.xlsx";
workbook.saveToFile(output, ExcelVersion.Version2013);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





