チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Doc 11.7.0のリリースを発表できることを嬉しく思います。このバージョンでは、先頭行インデントの文字数の設定がサポートされています。テキストボックスと画像のアスペクト比のロック機能が追加されました。また、WordからPDFへの変換機能も強化されました。さらに、取得された段落の前後の値が正しくない問題など、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREDOC-3548 | 先頭行インデントの文字数の設定がサポートされています。
paragraph.ParagraphFormat.FirstLineIndentChars = value; 注記: valueが正数の場合:先頭行インデントが設定されます。 valueが負数の場合:ハングインデントが設定されます。 valueが0の場合、paragraph.Format.SetFirstLineIndentChars(0)メソッドを使用して設定します。 |
| New feature | SPIREDOC-4467 | テキストボックスのアスペクト比のロック機能がされています。
textBox.AspectRatioLocked = true; //テキストボックスを追加する場合、デフォルトではアスペクト比はロックされません |
| New feature | SPIREDOC-7850/td> | 画像のアスペクト比のロック機能がされています。
picture.AspectRatioLocked = true; //画像を追加する場合、デフォルトではアスペクト比がロックされます |
| New feature | SPIREDOC-9137 | OfficeMathには、EQFieldをOfficeMathに変換するためのFromEqField()という静的メソッドが追加されました。 |
| Bug | SPIREDOC-3366 | 自動的に縦横比をロックする画像の幅を設定する際、高さが適切に調整されない問題が修正されました。 |
| Bug | SPIREDOC-7839 | WordをPDFに変換する際に、アプリケーションが「Object reference not set to an instance of an object」をスローする問題が修正されました。 |
| Bug | SPIREDOC-8340 | WordをPDFに変換する際に、アプリケーションが「System.ArgumentOutOfRangeException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9341 | メールマージフィールドの値が正しく更新されない問題が修正されました。 |
| Bug | SPIREDOC-9371 | 文書を比較する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREDOC-9450 | 取得された段落の前後の値が正しくない問題が修正されました。 |
| Bug | SPIREDOC-9525 | Dotm文書とDocx文書を比較する際に、アプリケーションが「System.InvalidOperationException」をスローする問題が修正されました。 |
Spire.XLS 13.7.0のリリースを発表できることを嬉しく思います。このバージョンでは、NETWORKDAYS.INTL関数をサポートする機能が追加されました。また、グラフを画像に変換した後に内容が正しくない問題など、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4712 | NETWORKDAYS.INTL関数をサポートする機能が追加されました。 |
| Bug | SPIREXLS-411 | 追加された数値が日付形式で表示される問題が修正されました。 |
| Bug | SPIREXLS-698 | グラフを画像に変換した後に、内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-883 | 分割ページでセルの上枠が印刷されない問題が修正されました。 |
| Bug | SPIREXLS-891 | シェイプを削除するときに、プログラムが「ArgumentOutOfRangeException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-1158 | ピボットテーブルの特定行のフォント色が変更しても効果がない問題が修正されました。 |
| Bug | SPIREXLS-2286 | ピボットテーブルのフォントが変更しても効果がない問題が修正されました。 |
| Bug | SPIREXLS-4711 | ExcelをHTMLに変換した後に破線が失われる問題が修正されました。 |
| Bug | SPIREXLS-4722 | CalculateAllValue()メソッドを使用する際にプログラムが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4728 | 結合セルにフィルタを追加した後、フィルタボタンが機能しなくなる問題が修正されました。 |
| Bug | SPIREXLS-4738 | 行を削除した後に残りの行数が正しくならない問題が修正されました。 |
| Bug | SPIREXLS-4748 | worksheet.ExportDataTable()メソッドを使用してデータをエクスポートする際に、形式が正しくならない問題が修正されました。 |
繰り返し透かしは、複数行の透かしとも呼ばれ、Word ドキュメントのページ上に一定の間隔で複数回表示される透かしの一種です。通常の透かしに比べ、繰り返し透かしは削除や隠蔽が難しいため、不正コピーや不正配布の防止に効果的です。この記事では、Spire.Doc for Java を使用して、プログラムによって Word ドキュメントに繰り返しテキストと画像の透かしを挿入する方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.6.0</version>
</dependency>
</dependencies>Word ドキュメントのヘッダーに指定した間隔で繰り返しワードアートを追加することで、Word ドキュメントに繰り返しテキスト透かしを挿入することができます。詳しい手順は次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.HeaderFooter;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.ShapeLineStyle;
import com.spire.doc.documents.ShapeType;
import com.spire.doc.fields.ShapeObject;
import java.awt.*;
public class insertRepeatingTextWatermark {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//ShapeObjectクラスのオブジェクトを作成し、アートフォントのテキストを設定する
ShapeObject shape = new ShapeObject(doc, ShapeType.Text_Plain_Text);
shape.getWordArt().setText("オリジナル");
//テキスト透かしの回転角度と、垂直方向と水平方向の繰り返し回数を設定する
double rotation = 315;
int ver = 5;
int hor = 3;
//ワードアートの書式を設定する
shape.setWidth(60);
shape.setHeight(20);
shape.setVerticalPosition(30);
shape.setHorizontalPosition(20);
shape.setRotation(rotation);
shape.getWordArt().setFontFamily("HarmonyOS Sans SC");
shape.setFillColor(Color.BLUE);
shape.setLineStyle(ShapeLineStyle.Single);
shape.setStrokeColor(Color.CYAN);
shape.setStrokeWeight(1);
//ドキュメントのセクションをループする
for (Section section : (Iterable) doc.getSections()
) {
//セクションのヘッダーを取得する
HeaderFooter header = section.getHeadersFooters().getHeader();
//ヘッダーに段落を追加する
Paragraph paragraph = header.addParagraph();
for (int i = 0; i < ver; i++) {
for (int j = 0; j < hor; j++) {
//ヘッダーに段落を追加する
shape = (ShapeObject) shape.deepClone();
shape.setVerticalPosition((float) (section.getPageSetup().getPageSize().getHeight()/ver * i + Math.sin(rotation) * shape.getWidth()/2));
shape.setHorizontalPosition((float) ((section.getPageSetup().getPageSize().getWidth()/hor - shape.getWidth()/2) * j));
paragraph.getChildObjects().add(shape);
}
}
}
//ドキュメントを保存する
doc.saveToFile("繰り返しテキスト透かし.docx", FileFormat.Auto);
doc.dispose();
}
}
同様に、ヘッダーに一定の間隔で繰り返し画像を追加することで、Wordドキュメントに繰り返し画像透かしを挿入することができます。詳しい手順は次のとおりです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.HeaderFooter;
import com.spire.doc.Section;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.TextWrappingStyle;
import com.spire.doc.fields.DocPicture;
public class insertRepeatingPictureWatermark {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document doc = new Document();
//Wordドキュメントを読み込む
doc.loadFromFile("サンプル.docx");
//画像を読み込む
DocPicture pic = new DocPicture(doc);
pic.loadImage("透かし.png");
//画像のテキストの折り返しを背面に設定する
pic.setTextWrappingStyle(TextWrappingStyle.Behind);
//垂直方向と水平方向の繰り返し回数を設定する
int ver = 4;
int hor = 3;
//ドキュメントのセクションをループする
for (Section section : (Iterable) doc.getSections()
) {
//セクションのヘッダーを取得する
HeaderFooter header = section.getHeadersFooters().getHeader();
//ヘッダーに段落を追加する
Paragraph paragraph = header.addParagraph();
for (int i = 0; i < ver; i++) {
for (int j = 0; j < hor; j++) {
//ヘッダーに画像を追加する
pic = (DocPicture) pic.deepClone();
pic.setVerticalPosition((float) ((section.getPageSetup().getPageSize().getHeight()/ver) * i));
pic.setHorizontalPosition((float) (section.getPageSetup().getPageSize().getWidth()/hor - pic.getWidth()/2) * j);
paragraph.getChildObjects().add(pic);
}
}
}
//ドキュメントを保存する
doc.saveToFile("繰り返し画像透かし.docx", FileFormat.Auto);
doc.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation 8.7.0のリリースを発表できることをうれしく思います。このバージョンでは、PPTX 2016およびPPTX 2019がサポートされています。また、グラフの横軸から軸線までの距離の設定にもサポートされています。さらに、PPTファイルを分割した後に生成されたファイルを開くことができなかった問題など、既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2244 | PPTX 2016およびPPTX 2019がサポートされています。
Spire.Presentation.FileFormat.Pptx2016 Spire.Presentation.FileFormat.Pptx2019 |
| New feature | SPIREPPT-2266 | グラフの横軸から軸線までの距離の設定にがサポートされています。
Presentation ppt = new Presentation(); IChart chart = ppt.Slides[0].Shapes.AppendChart(ChartType.ColumnClustered, new RectangleF(50, 50, 400, 400)); //PrimaryCategory軸を取得する IChartAxis chartAxis = chart.PrimaryCategoryAxis; //「軸からの距離」を設定する chartAxis.LabelsDistance = 200; //ファイルに保存する ppt.SaveToFile(outputFile, FileFormat.Pptx2013); |
| Bug | SPIREPPT-2279 | PPTファイルを分割した後に生成されたファイルを開くことができなかった問題が修正されました。 |
| Bug | SPIREPPT-2280 | PPTファイルを読み込む際に、プログラムがヌルポインタエラーを報告する問題が修正されました。 |
| Bug | SPIREPPT-2285 | 棒グラフが列に切り替わるかどうかを判断する際に、プログラムがエラーを報告する問題が修正されました。 |
Spire.PDF 9.7.0のリリースを発表できることを嬉しく思います。このバージョンでは、高さに合わせたズームレベルのサポートが追加されました。また、構造化された表を含むラベル付きPDFファイルの作成もサポートされています。PDFからPDF/A3AおよびPDF/A1Bへの変換機能も強化されました。さらに、PDFを印刷する際に印章の回転が歪む問題など、いくつかの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5964 | 構造化された表を含むラベル付きPDFファイルの作成がサポートされています。
PdfDocument doc = new PdfDocument();
PdfPageBase page = doc.Pages.Add(PdfPageSize.A4, new PdfMargins(20));
page.SetTabOrder(TabOrder.Structure);
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
taggedContent.SetLanguage("en-US");
taggedContent.SetTitle("test");
taggedContent.SetPdfUA1Identification();
PdfTrueTypeFont font = new PdfTrueTypeFont(new System.Drawing.Font("Times New Roman", 14), true);
PdfSolidBrush brush = new PdfSolidBrush(Color.Black);
PdfStructureElement document = taggedContent.StructureTreeRoot.AppendChildElement(PdfStandardStructTypes.Document);
PdfStructureElement heading1 = document.AppendChildElement(PdfStandardStructTypes.HeadingLevel1);
heading1.BeginMarkedContent(page);
string headingText = "What is a Tagged PDF?";
page.Canvas.DrawString(headingText, font, brush, new PointF(0, 0));
heading1.EndMarkedContent(page);
PdfStructureElement paragraph = document.AppendChildElement(PdfStandardStructTypes.Paragraph);
paragraph.BeginMarkedContent(page);
string paragraphText = ""Tagged PDF" doesn’t seem like a life-changing term. But for some, it is. For people who are " +
"blind or have low vision and use assistive technology (such as screen readers and connected Braille displays) to " +
"access information, an untagged PDF means they are missing out on information contained in the document because assistive " +
"technology cannot "read" untagged PDFs. Digital accessibility has opened up so many avenues to information that were once " +
"closed to people with visual disabilities, but PDFs often get left out of the equation.";
RectangleF rect = new RectangleF(0, 30, page.Canvas.ClientSize.Width, page.Canvas.ClientSize.Height);
page.Canvas.DrawString(paragraphText, font, brush, rect);
paragraph.EndMarkedContent(page);
PdfStructureElement figure = document.AppendChildElement(PdfStandardStructTypes.Figure);
figure.BeginMarkedContent(page);
PdfImage image = PdfImage.FromFile(TestUtil.DataPath + "ImgFiles/Bug_3938.png");
page.Canvas.DrawImage(image, new PointF(0, 150));
figure.EndMarkedContent(page);
PdfStructureElement table = document.AppendChildElement(PdfStandardStructTypes.Table);
PdfTable pdfTable = new PdfTable();
pdfTable.Style.DefaultStyle.Font = font;
System.Data.DataTable dataTable = new System.Data.DataTable();
dataTable.Columns.Add("Name");
dataTable.Columns.Add("Age");
dataTable.Columns.Add("Sex");
dataTable.Rows.Add(new string[] { "John", "22", "Male" });
dataTable.Rows.Add(new string[] { "Katty", "25", "Female" });
pdfTable.DataSource = dataTable;
pdfTable.Style.ShowHeader = true;
pdfTable.StructureElement = table;
pdfTable.Draw(page.Canvas, new PointF(0, 280), 300f);
doc.SaveToFile("1.pdf");
doc.Dispose(); |
| New feature | SPIREPDF-6038 | 高さに合わせたズームレベルのサポートが追加されました。
PdfDocument myPdf = new PdfDocument("test.pdf");
PdfPageBase page = myPdf .Pages[0];
PdfDestination dest = new PdfDestination(page, new PointF(-40f, -40f));
dest.Mode = PdfDestinationMode.FitV;
PdfGoToAction gotoaction = new PdfGoToAction(dest);
myPdf.AfterOpenAction = gotoaction;
myPdf.ViewerPreferences.PageMode = PdfPageMode.UseOutlines;
myPdf.SaveToFile("FitBH.pdf");
myPdf.Close(); |
| Bug | SPIREPDF-6011 | PDFをPDF/A3Aに変換する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6032 | PDFをPDF/A1Bに変換した後の内容が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6047 | PDFを画像に変換したり、PDFを印刷する際にフォントが変更される問題が修正されました。 |
| Bug | SPIREPDF-6051 | ページからテキストを抽出する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6076 | PDFを印刷する際に印章の回転が歪む問題が修正されました。 |
チーム作業が必要なかなり長い Word ドキュメントがある場合、作業を効率化するためにドキュメントをいくつかの短いファイルに分割し、それぞれの担当者に割り当てる必要があるかもしれません。この記事では、手作業でカット&ペーストする代わりに、Spire.Doc for Java を使ってプログラムで Word ドキュメントを分割する方法を紹介します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.6.0</version>
</dependency>
</dependencies>Word ドキュメントには、改ページで区切られた複数のページを含めることができます。Word ドキュメントを改ページで分割するには、以下の手順とコードを参照してください。
import com.spire.doc.*;
import com.spire.doc.documents.BreakType;
import com.spire.doc.documents.Paragraph;
public class splitByPageBreak {
public static void main(String[] args) {
//Documentのインスタンスを作成する
Document original = new Document();
//Wordドキュメントを読み込む
original.loadFromFile("サンプル.docx");
//新しいWordドキュメントを作成し、そこにセクションを追加する
Document newWord = new Document();
Section section = newWord.addSection();
int index = 0;
//原文のすべてのセクションをループする
for (int s = 0; s < original.getSections().getCount(); s++) {
Section sec = original.getSections().get(s);
//各セクションに含まれるボディーの子オブジェクトをすべてループする
for (int c = 0; c < sec.getBody().getChildObjects().getCount(); c++) {
DocumentObject obj = sec.getBody().getChildObjects().get(c);
if (obj instanceof Paragraph) {
Paragraph para = (Paragraph) obj;
sec.cloneSectionPropertiesTo(section);
//元のセクションの段落オブジェクトを新しいドキュメントのセクションに追加する
section.getBody().getChildObjects().add(para.deepClone());
for (int i = 0; i < para.getChildObjects().getCount(); i++) {
DocumentObject parobj = para.getChildObjects().get(i);
if (parobj instanceof Break) {
Break break1 = (Break) parobj;
if (break1.getBreakType().equals(BreakType.Page_Break)) {
//段落内の改ページのインデックスを取得する
int indexId = para.getChildObjects().indexOf(parobj);
//段落から改ページを削除する
Paragraph newPara = (Paragraph) section.getBody().getLastParagraph();
newPara.getChildObjects().removeAt(indexId);
//新しいWordドキュメントを保存する
newWord.saveToFile("Output/ドキュメント/ドキュメント"+index+".docx", FileFormat.Docx);
index++;
//新しいWordドキュメントを作成し、そこにセクションを追加する
newWord = new Document();
section = newWord.addSection();
//元のセクションの段落オブジェクトを新しいドキュメントのセクションに追加する
section.getBody().getChildObjects().add(para.deepClone());
if (section.getParagraphs().get(0).getChildObjects().getCount() == 0) {
//最初の空白段落を削除する
section.getBody().getChildObjects().removeAt(0);
} else {
//改ページの前に子オブジェクトを削除する
while (indexId >= 0) {
section.getParagraphs().get(0).getChildObjects().removeAt(indexId);
indexId--;
}
}
}
}
}
}
if (obj instanceof Table) {
//元のセクションの表のオブジェクトを新しいドキュメントのセクションに追加する
section.getBody().getChildObjects().add(obj.deepClone());
}
}
}
//ドキュメントを保存する
newWord.saveToFile("Output/ドキュメント/ドキュメント"+index+".docx", FileFormat.Docx);
}
}
Word ドキュメントでは、セクションは独自のページ書式を含むドキュメントの一部です。複数のセクションを含むドキュメントについては、Spire.Doc for Java はセクション区切りによるドキュメントの分割もサポートしています。詳しい手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.Section;
public class splitBySectionBreak {
public static void main(String[] args) {
//Documentのインスタンスを作成する
Document document = new Document();
//Word ドキュメントを読み込む
document.loadFromFile("サンプル.docx");
//新しいWordドキュメントのオブジェクトを定義する
Document newWord;
//元のWordドキュメントのすべてのセクションをループする
for (int i = 0; i < document.getSections().getCount(); i++) {
newWord = new Document();
//元の文書の各セクションをコピーし、新しいセクションとして新しい文書に追加する
newWord.getSections().add(document.getSections().get(i).deepClone());
//結果ドキュメントを保存する
newWord.saveToFile("ドキュメント1/ドキュメント" + i + ".docx");
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word ドキュメントに改ページを挿入することで、Enter キーを連打することなく、好きな場所でページを終了し、新しいページを一度に開始することができます。今回は、Spire.Doc for Java ライブラリを使用して、Java で Word ドキュメントに改ページを挿入する方法を説明します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.12.2</version>
</dependency>
</dependencies>特定の段落後に改ページを挿入する手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.Section;
import com.spire.doc.documents.BreakType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.FileFormat;
public class InsertPageBreakAfterParagraph {
public static void main(String[] args){
//Documentのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
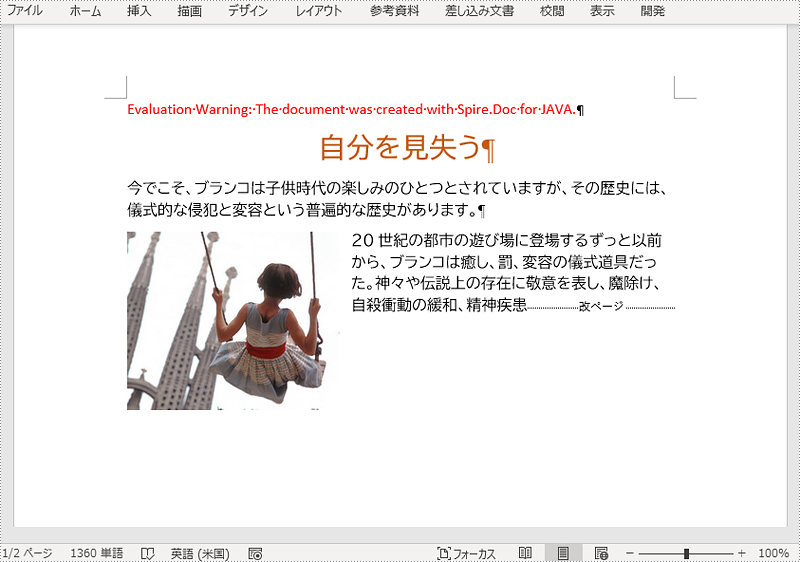
document.loadFromFile("C:/自分を見失う.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//セクションの3段落目を取得する
Paragraph paragraph = section.getParagraphs().get(2);
//段落に改ページを付加する
paragraph.appendBreak(BreakType.Page_Break);
//結果ドキュメントを保存する
document.saveToFile("改ページの挿入.docx", FileFormat.Docx_2013);
}
}
特定のテキストの後に改ページを挿入する手順は次のとおりです。
import com.spire.doc.Break;
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.documents.BreakType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.TextSelection;
import com.spire.doc.fields.TextRange;
public class InsertPageBreakAfterText {
public static void main(String[] args){
//Documentのインスタンスを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("C:/自分を見失う.docx");
//特定のテキストを検索する
TextSelection selection = document.findString("精神疾患", true, true);
//検索されたテキストのテキスト範囲を取得する
TextRange range = selection.getAsOneRange();
//テキスト範囲がある段落を取得する
Paragraph paragraph = range.getOwnerParagraph();
//段落内のテキスト範囲の位置インデックスを取得する
int index = paragraph.getChildObjects().indexOf(range);
//改ページを作成する
Break pageBreak = new Break(document, BreakType.Page_Break);
//検索されたテキストの後に改ページを挿入する
paragraph.getChildObjects().insert(index + 1, pageBreak);
//結果ドキュメントを保存する
document.saveToFile("テキストの後に改ページを挿入.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc for C++ 11.6.3を発表できることを嬉しく思います。このバージョンでは、アプリケーションがスローする例外を Try Catch でキャッチできない問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-9518 | アプリケーションがスローする例外を Try Catch でキャッチできない問題が修正されました。 |
Excel ファイルに文書プロパティを追加することは、ファイルに関する追加のコンテキストと情報を提供する簡単で便利な機能です。 文書プロパティには、標準的なものとカスタマイズされたものがあります。 標準の文書プロパティは、著者、タイトル、件名など、文書に関する基本的な情報で、文書の検索や特定を容易にするのに役立ちます。 カスタム文書プロパティは、プロジェクト名、クライアント名、部門長など、文書に関する特定の詳細を追加することができます。 この機能により、文書のデータに関連する情報やコンテキストを提供することもできます。この記事では、Spire.XLS for Java を使用して標準の文書プロパティとカスタム文書プロパティを Excel への追加する方法を紹介します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.6.5</version>
</dependency>
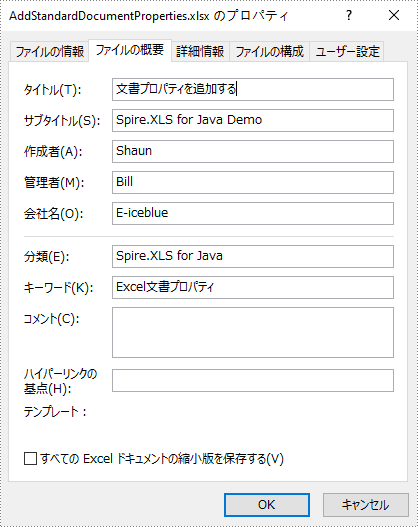
</dependencies>標準の文書プロパティは Microsoft Excel によって事前に定義されており、タイトル、件名、作成者、キーワード、コメントなどのフィールドが含まれています。次の手順は、Spire.XLS for Java を使用して Java で Excel への標準文書プロパティを追加する方法を示しています。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
public class AddStandardDocumentProperties {
public static void main(String[] args) {
//Workbook クラスのインスタンスを初期化する
Workbook workbook = new Workbook();
//Excel ファイルを読み込む
workbook.loadFromFile("sample.xlsx");
//ファイルに標準的な文書プロパティを追加する
workbook.getDocumentProperties().setTitle("文書プロパティを追加する");
workbook.getDocumentProperties().setSubject("Spire.XLS for Java Demo");
workbook.getDocumentProperties().setAuthor("Shaun");
workbook.getDocumentProperties().setManager("Bill");
workbook.getDocumentProperties().setCompany("E-iceblue");
workbook.getDocumentProperties().setCategory("Spire.XLS for Java");
workbook.getDocumentProperties().setKeywords("Excel文書プロパティ");
//結果ファイルを保存する
workbook.saveToFile("AddStandardDocumentProperties.xlsx", ExcelVersion.Version2016);
workbook.dispose();
}
}
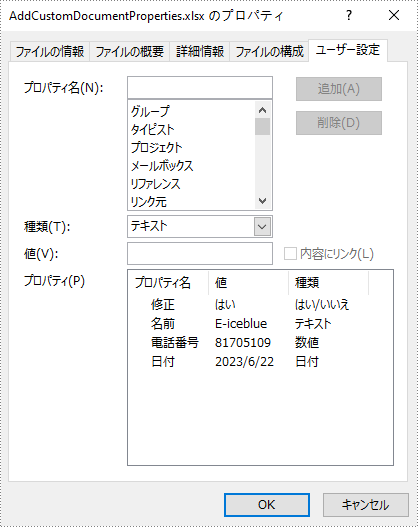
カスタム文書プロパティはユーザー定義であり、特定のニーズや要件に合わせて調整できます。カスタム文書プロパティのデータ型は、「はい/いいえ」、「テキスト」、「数値」、および「日付」です。次の手順は、Spire.XLS for Java を使用して、Java で Excel へのカスタム文書プロパティを追加する方法を示しています。
import com.spire.xls.ExcelVersion;
import com.spire.xls.Workbook;
import java.util.Date;
public class AddCustomDocumentProperties {
public static void main(String[] args) {
//Workbook クラスのインスタンスを初期化する
Workbook workbook = new Workbook();
//Excel ファイルを読み込む
workbook.loadFromFile("sample.xlsx");
//「はい/いいえ」カスタム文書プロパティを追加する
workbook.getCustomDocumentProperties().add("修正", true);
//「テキスト」カスタム文書プロパティを追加する
workbook.getCustomDocumentProperties().add("名前", "E-iceblue");
//「数値」カスタム文書プロパティを追加する
workbook.getCustomDocumentProperties().add("電話番号", 81705109);
//「日付」カスタム文書プロパティを追加する
workbook.getCustomDocumentProperties().add("日付", new Date());
//結果ファイルを保存する
workbook.saveToFile("AddCustomDocumentProperties.xlsx", ExcelVersion.Version2013);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
XPS は、XML Paper Specification の略称であり、Microsoft が開発した固定レイアウトファイル形式です。一部の動的なコンテンツやレイアウト変更を許容する形式とは異なり、XPS は文書のレイアウトを保持し、視覚的外観を維持しています。XPS ファイルは、Microsoft XPS Viewerで簡単に閲覧することができます。
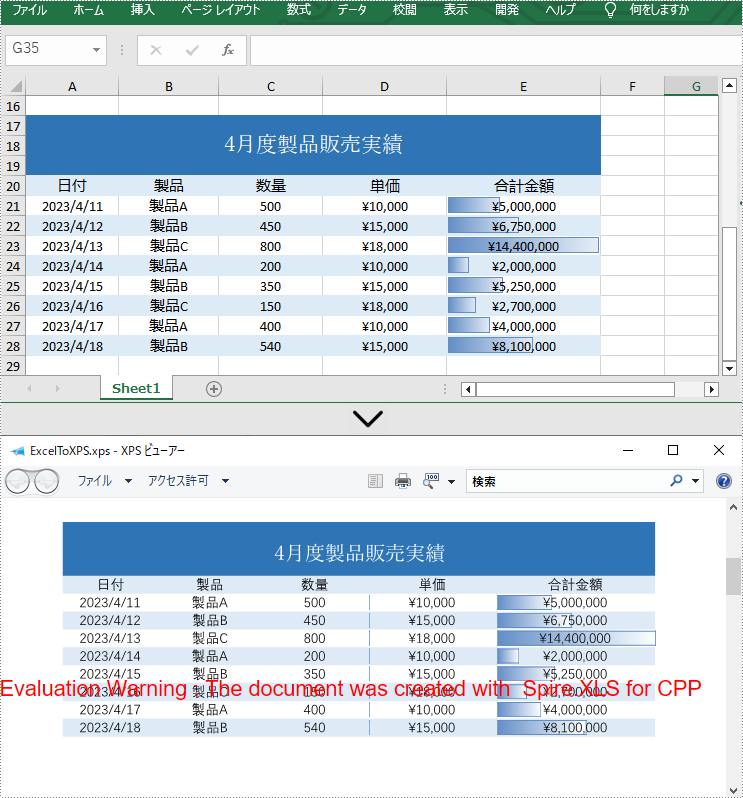
Excel ファイルを XPS 形式に変換することにはいくつかの利点があります。例えば、Microsoft Excel や他の電子スプレッドシートにアクセスできないユーザーと Excel データを共有するために、XPS 形式を使用することができます。さらに、変換により、元の Excel ファイルのフォーマットを維持し、読みやすくすることができます。また、XPS ファイルはアクセシビリティに配慮されており、スクリーンリーダーや支援技術によって読み込むことができます。この記事では、Spire.XLS for C++ を使用して C++ で Excel を XPS に変換する方法について説明します。
Spire.XLS for C++ をアプリケーションに組み込むには、2つの方法があります。一つは NuGet 経由でインストールする方法、もう一つは当社のウェブサイトからパッケージをダウンロードし、ライブラリをプログラムにコピーする方法です。NuGet 経由のインストールの方が便利で、より推奨されます。詳しくは、以下のリンクからご覧いただけます。
Spire.XLS for C++ を C++ アプリケーションに統合する方法
Excel ファイルを XPS 形式に変換することは、Spire.XLS for C++ を使用することで簡単に行えます。まず、Workbook->LoadFromFile(LPCWSTR_S fileName) メソッドを使って Excel ファイルを読み込みます。次に、Workbook->SaveToFile(LPCWSTR_S fileName, FileFormat::XPS) メソッドを呼び出して、XPS形式で保存します。詳細な手順は次のとおりです。
#include "Spire.Xls.o.h";
using namespace Spire::Xls;
using namespace std;
int main()
{
//入力ファイルと出力ファイルのパスを指定する
wstring inputFile = L"sample.xlsx";
wstring outputFile = L"ExcelToXPS.xps";
//Workbookクラスのインスタンスを初期化する
Workbook* workbook = new Workbook();
//Excelファイルを読み込む
workbook->LoadFromFile(inputFile.c_str());
//ExcelをXPSファイルに保存する
workbook->SaveToFile(outputFile.c_str(), Spire::Xls::FileFormat::XPS);
workbook->Dispose();
delete workbook;
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





