チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Doc for Java 10.9.8 のリリースを発表できることを嬉しく思います。このバージョンは、Word level による Word ドキュメントの比較をサポートしました。このリリースでは、Word から PDF への変換機能も強化しました。詳細は以下の内容を読んでください。
| Category | ID | Description |
| New feature | SPIREDOC-7817 | Word levelによるWordドキュメントの比較をサポートしました。
Document doc1 = new Document(); doc1.loadFromFile(folder + "a.docx"); Document doc2 = new Document(); doc2.loadFromFile(folder + "b.docx"); CompareOptions options = new CompareOptions(); options.setLevel(ComparisonLevel.Word); doc1.compare(doc2, "E-iceblue",options); doc1.saveToFile(result, FileFormat.Docx); |
| Bug | SPIREDOC-7268 | 表の行の高さを自動タイプに設定するときに、DOC形式のドキュメントに保存しても機能しない問題が修正されました。 |
| Bug | SPIREDOC- 7835 | ディレクトリの更新時にディレクトリの内容が整列していなかった問題が修正されました。 |
| Bug | SPIREDOC-8018 | WordをPDFに変換する際に、テーブルレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8038 | WordをPDFに変換する際に、合計ページ数が正しく表示されなかった問題が修正されました。 |
| Bug | SPIREDOC-8092 | OleLinkType.Linkを使用してOLEオブジェクトを追加した後、OLEオブジェクトに表示される画像をクリックしたときに埋め込まれたドキュメントを開くことができなかった問題が修正されました。 |
| Bug | SPIREDOC-8095 | ディレクトリの更新時にページ番号が正しく表示されなかった問題が修正されました。 |
| Bug | SPIREDOC-8098 | regexでテキストを検索する際に設定した大文字と小文字を区別しないと機能しない問題が修正されました。 |
| Bug | SPIREDOC-8162 | ディレクトリの更新時にアプリケーションが「NullPointerException」をスローしする問題が修正されました。 |
| Bug | SPIREDOC-8190 | WordをPDFに変換する際に、テキスト改行が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8199 | WordをPDFに変換する際に、透かしの回転角度が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8200 | WordをPDFに変換する際に、アプリケーションが「Argument width[0]or height[0]cannot be less or equal to zero」をスローしする問題が修正されました。 |
| Bug | SPIREDOC-8231 | WordをPDFに変換する際に、表のスパン・ページが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8273 | ドキュメントをロードする際に、アプリケーションが「Error reading WMF metafile」をスローしする問題が修正されました。 |
| Bug | SPIREDOC-8282 | WordをPDFに変換する際に、コンテンツレイアウトが正しくない問題が修正されました。 |
| Bug | SPIREDOC-8285 | docmファイル形式がdocxと認識される問題が修正されました。 |
| Bug | SPIREDOC-8303 | docmファイルが暗号化されているかどうかを検出した結果が正しくない問題が修正されました。 |
| Bug | SPIREDOC-8369 | WordをPDFに変換する際に、アプリケーションが「GC overhead limit exceeded」をスローする問題が修正されました。 |
仕事上、2版の Word ドキュメントを受け取り、その違いを見つける必要に迫られることはよくあることです。特に、法令や教育などの分野では、文書の比較は重要であり、よく行われています。この記事では、Spire.Doc for .NET を使用して、C# と VB.NET で2つの Word ドキュメントを比較する方法について学びます。
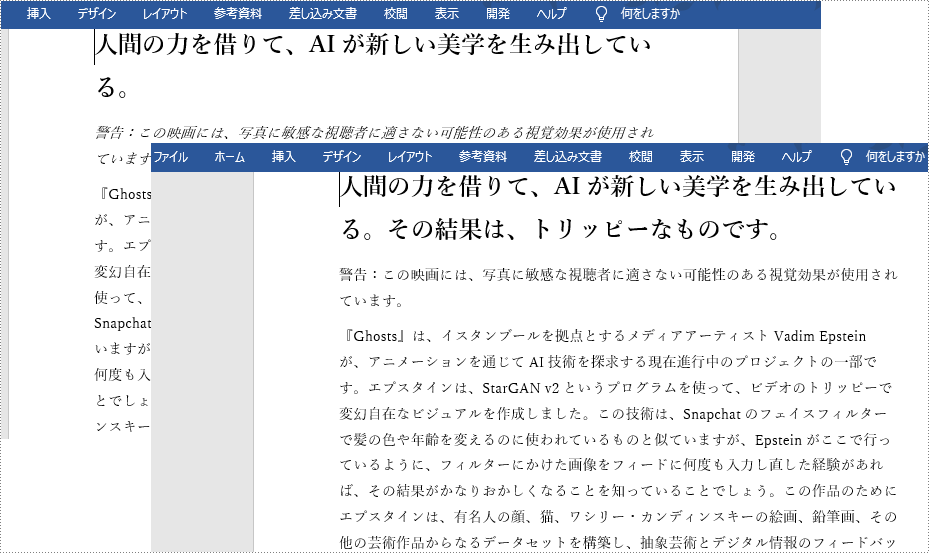
以下は、比較される2つの Word ドキュメントのスクリーンショットです。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.Doc比較結果を別の Word ドキュメントに保存すると、挿入、削除、書式の変更など、元のドキュメントに加えられたすべての変更を確認することができます。以下は、Spire.Doc for .NET を使用して、2つの Word ドキュメントを比較し、結果を別の Word ドキュメントに保存する手順です。
using Spire.Doc;
namespace CompareDocuments
{
class Program
{
static void Main(string[] args)
{
//Wordドキュメントを読み込む
Document doc1 = new Document("C:\\Sample1.docx");
//もう一方のWordドキュメントを読み込む
Document doc2 = new Document("C:\\Sample2.docx");
//Compare two documents
doc1.Compare(doc2, "桜桃子");
//Save the differences in a third document
doc1.SaveToFile("違い.docx", FileFormat.Docx2013);
doc1.Dispose();
}
}
}Imports Spire.Doc
Namespace CompareDocuments
Class Program
Shared Sub Main(ByVal args() As String)
'Wordドキュメントを読み込む
Dim doc1 As Document = New Document("C:\\Sample1.docx")
'もう一方のWordドキュメントを読み込む
Dim doc2 As Document = New Document("C:\\Sample2.docx")
'Compare two documents
doc1.Compare(doc2, "桜桃子")
'Save the differences in a third document
doc1.SaveToFile("違い.docx", FileFormat.Docx2013)
doc1.Dispose()
End Sub
End Class
End Namespace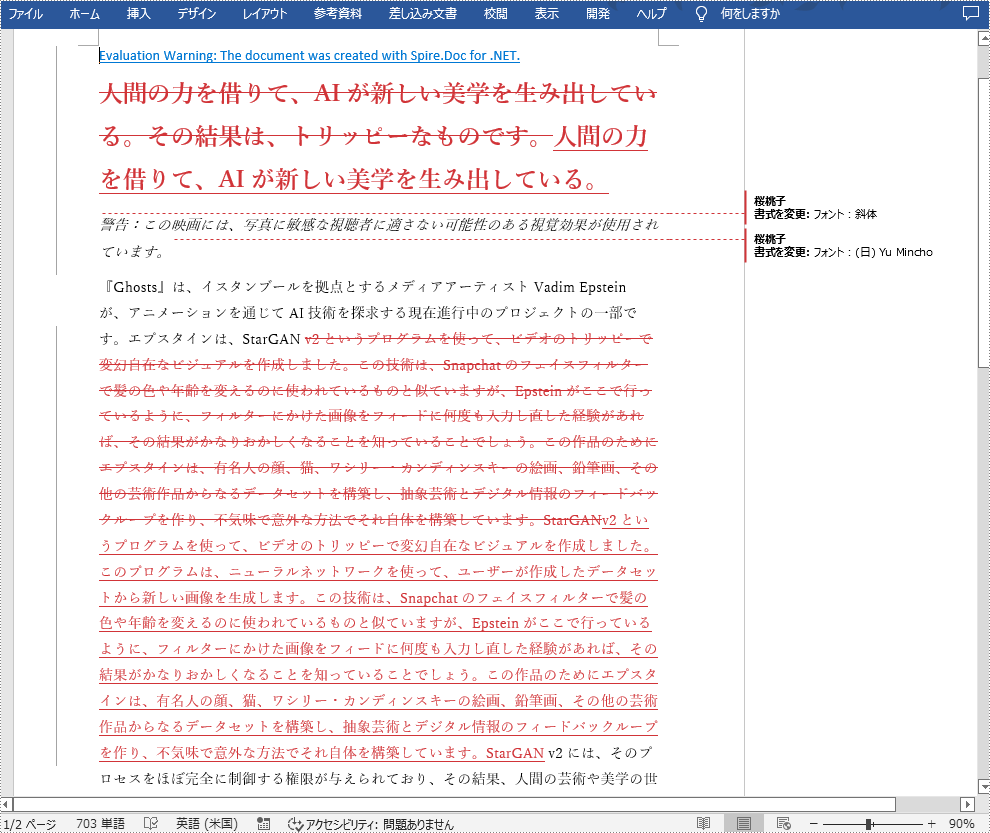
開発者は、すべての差分ではなく、挿入と削除の情報のみを取得したいと思うかもしれません。以下は、挿入と削除の情報を取得し、それらを2つの別々のリストに入れる手順です。
using Spire.Doc;
using Spire.Doc.Fields;
using System;
namespace GetDifferencesInList
{
class Program
{
static void Main(string[] args)
{
//Wordドキュメントを読み込む
Document doc1 = new Document("C:\\Sample1.docx");
//もう一方のWordドキュメントを読み込む
Document doc2 = new Document("C:\\Sample2.docx");
//2つのWordドキュメントを比較する
doc1.Compare(doc2, "桜桃子");
//改訂を取得する
DifferRevisions differRevisions = new DifferRevisions(doc1);
//挿入の改訂を返し、リストに入れる
var insetRevisionsList = differRevisions.InsertRevisions;
//削除の改訂を返し、リストに入れる
var deletRevisionsList = differRevisions.DeleteRevisions;
//2つのint型変数を作成する
int m = 0;
int n = 0;
//挿入改訂のリストをループする
for (int i = 0; i < insetRevisionsList.Count; i++)
{
if (insetRevisionsList[i] is TextRange)
{
m += 1;
//特定の改訂を取得し、その内容を取得する
TextRange textRange = insetRevisionsList[i] as TextRange;
Console.WriteLine("挿入 #" + m + ":" + textRange.Text);
}
}
Console.WriteLine("=====================");
//削除改訂のリストをループする
for (int i = 0; i < deletRevisionsList.Count; i++)
{
if (deletRevisionsList[i] is TextRange)
{
n += 1;
//特定の改訂を取得し、その内容を取得する
TextRange textRange = deletRevisionsList[i] as TextRange;
Console.WriteLine("削除 #" + n + ":" + textRange.Text);
}
}
Console.ReadKey();
}
}
}Imports Spire.Doc
Imports Spire.Doc.Fields
Imports System
Namespace GetDifferencesInList
Class Program
Shared Sub Main(ByVal args() As String)
'Wordドキュメントを読み込む
Dim doc1 As Document = New Document("C:\\Sample1.docx")
'もう一方のWordドキュメントを読み込む
Dim doc2 As Document = New Document("C:\\Sample2.docx")
'2つのWordドキュメントを比較する
doc1.Compare(doc2, "桜桃子")
'改訂を取得する
Dim differRevisions As DifferRevisions = New DifferRevisions(doc1)
'挿入の改訂を返し、リストに入れる
Dim insetRevisionsList As var = differRevisions.InsertRevisions
'削除の改訂を返し、リストに入れる
Dim deletRevisionsList As var = differRevisions.DeleteRevisions
'2つのint型変数を作成する
Dim m As Integer = 0
Dim n As Integer = 0
'挿入改訂のリストをループする
Dim i As Integer
For i = 0 To insetRevisionsList.Count - 1 Step i + 1
If TypeOf insetRevisionsList(i) Is TextRange Then
m += 1
'特定の改訂を取得し、その内容を取得する
Dim textRange As TextRange = insetRevisionsList(i) As TextRange
Console.WriteLine("挿入 #" + m + ":" + textRange.Text)
End If
Next
Console.WriteLine("=====================")
'削除改訂のリストをループする
Dim i As Integer
For i = 0 To deletRevisionsList.Count - 1 Step i + 1
If TypeOf deletRevisionsList(i) Is TextRange Then
n += 1
'特定の改訂を取得し、その内容を取得する
Dim textRange As TextRange = deletRevisionsList(i) As TextRange
Console.WriteLine("削除 #" + n + ":" + textRange.Text)
End If
Next
Console.ReadKey()
End Sub
End Class
End Namespace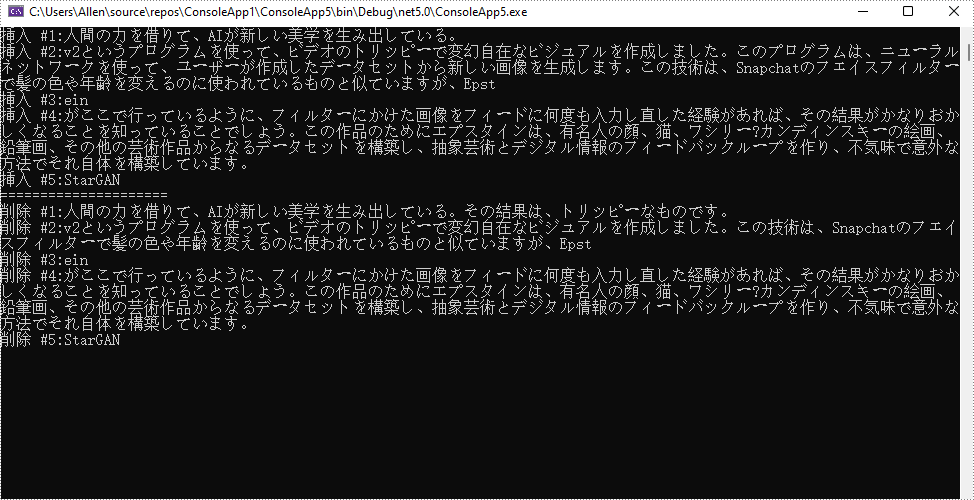
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
コンピュータに MS Word をインストールする必要がないため、Word 文書形式よりも、イメージ書式をプラットフォーム間で共有したりプレビューしたりするのが便利です。また、Word をイメージに変換することで、文書のオリジナルの外観を維持でき、他の人がそれをさらに修正するのを防ぐことができます。この記事では、Spire.Doc for .NET を使用して、C# および VB.NET でプログラムによって Word をイメージに変換する方法を示します。
まず、Spire.Doc for.NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocSpire.Doc for .NET が提供する Document.SaveToImages() メソッドは、Word 文書のページを Bitmap または Metafile に変換します。その後、Bitmap または Metafile は、BMP、EMF、JPEG、PNG、GIF または WMF 書式のイメージとして保存することができます。以下は Word を JPG に変換するための詳細な手順です。
using Spire.Doc;
using Spire.Doc.Documents;
using System;
using System.Drawing;
using System.Drawing.Imaging;
namespace ConvertWordToJPG
{
class Program
{
static void Main(string[] args)
{
//Documentオブジェクトを作成する
Document doc = new Document();
//Wordをロードする
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Template.docx");
//文書全体のページをイメージに変換する
Image[] images = doc.SaveToImages(ImageType.Bitmap);
//イメージコレクションをループする
for (int i = 0; i < images.Length; i++)
{
//イメージをJPGとして保存する
string outputfile = String.Format("Image-{0}.jpg", i);
images[i].Save("C:\\Users\\Administrator\\Desktop\\Images\\" + outputfile, ImageFormat.Jpeg);
}
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System
Imports System.Drawing
Imports System.Drawing.Imaging
Namespace ConvertWordToJPG
Class Program
Shared Sub Main(ByVal args() As String)
'Documentオブジェクトを作成する
Document doc = New Document()
'Wordをロードする
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Template.docx")
'文書全体のページをイメージに変換する
Dim images() As Image = doc.SaveToImages(ImageType.Bitmap)
'イメージコレクションをループする
Dim i As Integer
For i = 0 To images.Length- 1 Step i + 1
'イメージをJPGとして保存する
Dim outputfile As String = String.Format("Image-{0}.jpg",i)
images(i).Save("C:\\Users\\Administrator\\Desktop\\Images\\" + outputfile, ImageFormat.Jpeg)
Next
End Sub
End Class
End NamespaceSpire.Doc for .NET を使用して Word 文書を一連のバイト配列として保存し、SVG 文書にそれぞれ書き込むことができます。Word を SVG に変換するための詳細な手順は次のとおりです。
using Spire.Doc;
using System;
using System.Collections.Generic;
using System.IO;
namespace CovnertWordToSVG
{
class Program
{
static void Main(string[] args)
{
//Documentオブジェクトを作成する
Document doc = new Document();
//Wordをロードする
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Template.docx");
//文書をバイト配列キューとして保存する
Queue<byte[]> svgBytes = doc.SaveToSVG();
//すべてのバイト配列をループする
for (int i = 0; i < svgBytes.Count; i++)
{
//キューを配列に変換する
byte[][] bytes = svgBytes.ToArray();
//出力文書名を指定する
string outputfile = String.Format("Image-{0}.svg", i);
//SVG文書にバイト配列を書き込む
FileStream fs = new FileStream("C:\\Users\\Administrator\\Desktop\\Images\\" + outputfile, FileMode.Create);
fs.Write(bytes[i], 0, bytes[i].Length);
fs.Close();
}
}
}
}Imports Spire.Doc
Imports System
Imports System.Collections.Generic
Imports System.IO
Namespace CovnertWordToSVG
Class Program
Shared Sub Main(ByVal args() As String)
'Documentオブジェクトを作成する
Document doc = New Document()
'Wordをロードする
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Template.docx")
'文書をバイト配列キューとして保存する
Dim svgBytes()> As Queue<byte = doc.SaveToSVG()
'すべてのバイト配列をループする
Dim i As Integer
For i = 0 To svgBytes.Count- 1 Step i + 1
'キューを配列に変換する
Dim bytes()() As Byte = svgBytes.ToArray()
'出力文書名を指定する
Dim outputfile As String = String.Format("Image-{0}.svg",i)
' SVG文書にバイト配列を書き込む
Dim fs As FileStream = New FileStream("C:\\Users\\Administrator\\Desktop\\Images\\" + outputfile,FileMode.Create)
fs.Write(bytes(i), 0, bytes(i).Length)
fs.Close()
Next
End Sub
End Class
End Namespaceより解像度の高いイメージはコンテンツをより明確に表示することができます。以下の手順に従って、Word を PNG に変換するときに、イメージ解像度を設定することができます。
using Spire.Doc;
using System;
using System.Drawing;
using System.Drawing.Imaging;
using Spire.Doc.Documents;
namespace ConvertWordToPng
{
class Program
{
static void Main(string[] args)
{
//Documentオブジェクトを作成する
Document doc = new Document();
//Word文書をロードする
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Template.docx ");
//文書全体のページをイメージに変換する
Image[] images = doc.SaveToImages(ImageType.Metafile);
//イメージコレクションをループする
for (int i = 0; i < images.Length; i++)
{
//イメージの解像度を設定する
Image newimage = ResetResolution(images[i] as Metafile, 150);
//イメージをPNGとして保存する
string outputfile = String.Format("image-{0}.png", i);
newimage.Save(outputfile, ImageFormat.Png);
}
}
//ResetResolution()を使用しでイメージの解像度を設定する
public static Image ResetResolution(Metafile mf, float resolution)
{
int width = (int)(mf.Width * resolution / mf.HorizontalResolution);
int height = (int)(mf.Height * resolution / mf.VerticalResolution);
Bitmap bmp = new Bitmap(width, height);
bmp.SetResolution(resolution, resolution);
using (Graphics g = Graphics.FromImage(bmp))
{
g.DrawImage(mf, Point.Empty);
}
return bmp;
}
}
}Imports Spire.Doc
Imports System
Imports System.Drawing
Imports System.Drawing.Imaging
Imports Spire.Doc.Documents
Namespace ConvertWordToPng
Class Program
Shared Sub Main(ByVal args() As String)
'Documentオブジェクトを作成する
Dim doc As Document = New Document()
'Word文書をロードする
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Template.docx")
'文書全体のページをイメージに変換する
Dim images() As Image = doc.SaveToImages(ImageType.Metafile)
'イメージコレクションをループする
Dim i As Integer
For i = 0 To images.Length - 1 Step i + 1
'イメージの解像度を設定する
Dim Newimage As Image = ResetResolution(images(i) As Metafile, 150)
'イメージをPNGとして保存する
Dim outputfile As String = String.Format("image-{0}.png", i)
Newimage.Save(outputfile, ImageFormat.Png)
Next
End Sub
'ResetResolution()を使用しでイメージの解像度を設定する
Public Shared Function ResetResolution(ByVal mf As Metafile, ByVal resolution As Single) As Image
Dim width As Integer = CType((mf.Width * resolution / mf.HorizontalResolution), Integer)
Dim height As Integer = CType((mf.Height * resolution / mf.VerticalResolution), Integer)
Dim bmp As Bitmap = New Bitmap(width, height)
bmp.SetResolution(resolution, resolution)
Imports (Graphics g = Graphics.FromImage(bmp))
{
g.DrawImage(mf, PoInteger.Empty)
}
Return bmp
End Function
End Class
End Namespace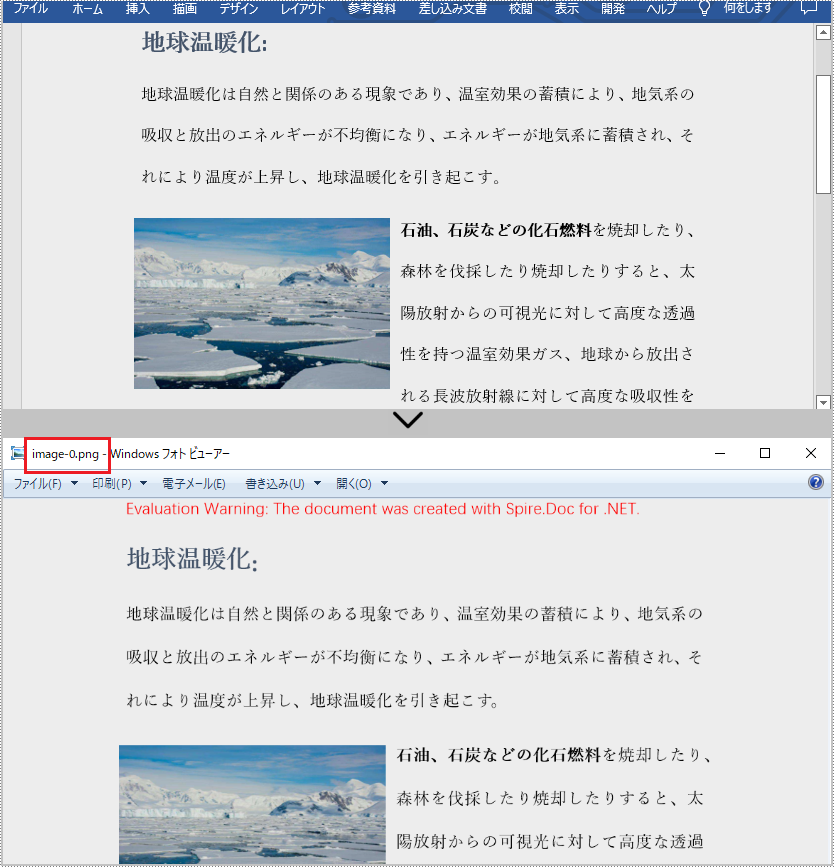
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
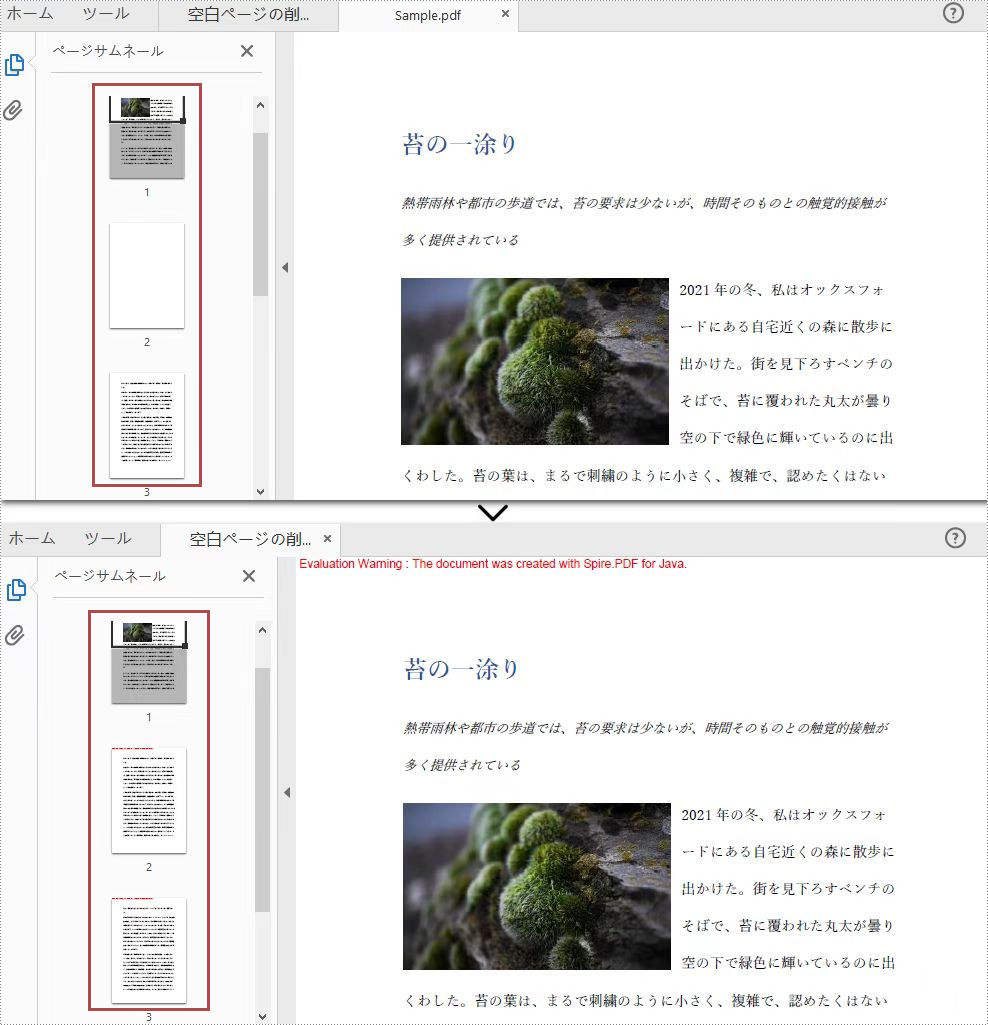
PDF ドキュメントを印刷または共有する場合、ドキュメント内に白紙ページがあるかどうかを確認した方がよいでしょう。なぜなら、白紙ページは紙の無駄遣いにつながり、ドキュメントの専門的な外観が損なわれてしまうからです。しかし、すべてのページに目を通して空白のページを見つけ、それを削除するには、多くの時間がかかるでしょう。この問題に対処するためのより良い方法は、Spire.PDF for Java を使用することです。この記事では、プログラミングによって簡単に PDF ドキュメントから空白ページを見つけ、削除するために Spire.PDF for Java を使用する方法を示しています。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.9.1</version>
</dependency>
</dependencies>Spire.PDF for Java は、PDF ページが完全に白紙であるかどうかを検出するメソッド PdfPageBase.isBlank() を提供しています。しかし、空白に見えるいくつかのページが実際に白い画像を含んでいる、これらのページは PdfPageBase.isBlank() メソッドを使用して空白とみなされないでしょう。したがって、白紙ページと白い画像を含むページを検出するために、 PdfPageBase.isBlank() メソッドと組み合わせて使用するカスタムメソッド isBlankImage() を作成する必要があります。
注意:この解決策は、PDF ページを画像に変換し、画像が空白であるかどうかを検出します。変換された画像の評価メッセージを削除するには、ライセンスを適用する必要があります。そうでなければ、この方法は正しく動作しません。もしライセンスをお持ちでない場合は、このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。でご連絡いただき、評価用の一時的なライセンスをお受け取りください。
詳細な手順は以下の通りです。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImageType;
import java.awt.*;
import java.awt.image.BufferedImage;
public class removeBlankPages {
public static void main(String []args){
//PdfDocument クラスのインスタンスを作成する
PdfDocument pdf = new PdfDocument();
//PDFドキュメントを読み込む
pdf.loadFromFile("C:/Sample.pdf");
BufferedImage image;
//PDF内のページをループする
for(int i = pdf.getPages().getCount()-1; i>=0; i--)
{
//ページを取得する
PdfPageBase page = pdf.getPages().get(i);
//ページが空白かどうかを検出する
if(page.isBlank())
{
//白紙ページを削除する
pdf.getPages().remove(page);
}
else
{
//PDFのページを画像として保存する
image = pdf.saveAsImage(i, PdfImageType.Bitmap);
//変換後の画像が空白かどうかを検出する
if (isBlankImage(image))
{
//白紙画像に対応するページを削除する
pdf.getPages().remove(page);
}
}
}
//結果のドキュメントを保存する
pdf.saveToFile("空白ページの削除.pdf");
}
//画像が空白かどうかを検出する
public static boolean isBlankImage(BufferedImage image)
{
BufferedImage bufferedImage = image;
Color pixel;
for (int i = 0; i < bufferedImage.getWidth(); i++)
{
for (int j = 0; j < bufferedImage.getHeight(); j++)
{
pixel = new Color(bufferedImage.getRGB(i, j));
if (pixel.getRed() < 240 || pixel.getGreen() < 240 || pixel.getBlue() < 240)
{
return false;
}
}
}
return true;
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation 7.9.2 のリリースを発表できることをうれしく思います。このバージョンでは、PPTをPDFに変換する際に隠されたスライドを変換しないように設定する機能と、スライドに最初に表示される一致するテキストを検索してスタイルを変更する機能をサポートしました。また、今回のアップデートでは、PPTからイメージへの変換機能も強化しました。また、多くの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2037 | スライドに最初に表示される一致するテキストを検索してスタイルを変更する機能をサポートしました。
Presentation ppt = new Presentation();
ppt.LoadFromFile(inputFile);
string text = "create";
TextRange textRange = ppt.Slides[0].FindFirstTextAsRange(text);
textRange.Fill.FillType = FillFormatType.Solid;
textRange.Fill.SolidColor.Color = Color.Red;
textRange.FontHeight = 28;
textRange.LatinFont = new TextFont("Times New Roman");
textRange.IsBold = TriState.True;
textRange.IsItalic = TriState.True;
textRange.TextUnderlineType = TextUnderlineType.Double;
textRange.TextStrikethroughType = TextStrikethroughType.Single; |
| New feature | SPIREPPT-2065 | PPTをPDFに変換する際に隠されたスライドを変換しないように設定する機能をサポートしました。
Presentation presentation = new Presentation();
presentation.LoadFromFile(input);
presentation.SaveToPdfOption.ContainHiddenSlides = false;
presentation.SaveToFile(output, FileFormat.PDF); |
| Bug | SPIREPPT-2034 | データラベルのフォントサイズと色の設定が機能しない問題が修正されました。 |
| Bug | SPIREPPT-2051 | PPTをイメージに変換する際にコンテンツが失われていた問題が修正されました。 |
| Bug | SPIREPPT-2067 | PPTをロードする際に、アプリケーションが「System.ArgumentOutOfRangeException」をスローする問題が修正されました。 |
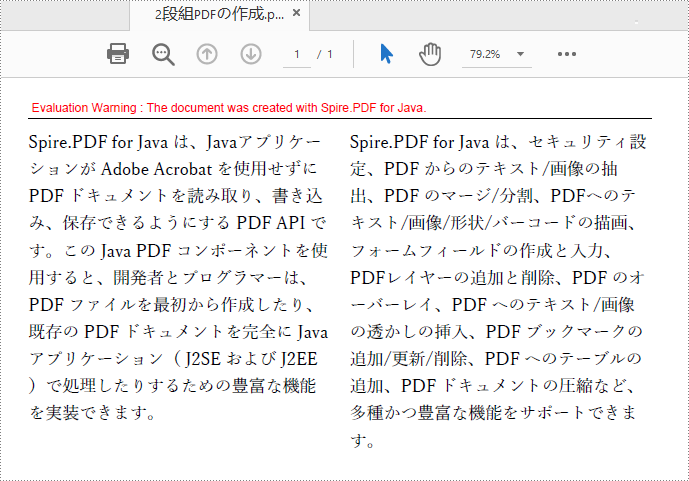
雑誌、新聞、研究論文などでは、多段組の PDF がよく使われます。Spire.PDF for Java を使えば、コードから簡単に多段組の PDF を作成することができます。この記事では、Java アプリケーションにおいて 2段組の PDF を作成する方法を紹介します。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>詳しい手順は以下の通りです。
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Rectangle2D;
public class createTwoColumnPDF {
public static void main(String[] args) throws Exception {
//PdfDocument クラスのオブジェクトを作成します
PdfDocument doc = new PdfDocument();
//新しいページを追加する
PdfPageBase page = doc.getPages().add();
//位置と幅を設定する
float x = 0;
float y = 15;
float width = 600;
//PdfPen クラスのオブジェクトを作成する
PdfPen pen = new PdfPen(new PdfRGBColor(Color.black), 1f);
//PDFページ上に線を描画する
page.getCanvas().drawLine(pen, x, y, x + width, y);
//段落テキストを定義する
String s1 = "Spire.PDF for Java は、Javaアプリケーションが Adobe Acrobat を使用せずに PDF ドキュメントを読み取り、"
+ "書き込み、保存できるようにする PDF API です。この Java PDF コンポーネントを使用すると、"
+ "開発者とプログラマーは、PDF ファイルを最初から作成したり、既存の PDF ドキュメント"
+ "を完全に Java アプリケーション( J2SE および J2EE )で処理したりするための豊富な機能を実装できます。";
String s2 = "Spire.PDF for Java は、セキュリティ設定、PDF からのテキスト/画像の抽出、PDF のマージ/分割、"
+ "PDFへのテキスト/画像/形状/バーコードの描画、フォームフィールドの作成と入力、"
+ "PDFレイヤーの追加と削除、PDF のオーバーレイ、PDF へのテキスト/画像の透かしの挿入、"
+ "PDF ブックマークの追加/更新/削除、PDF へのテーブルの追加、"
+ "PDF ドキュメントの圧縮など、多種かつ豊富な機能をサポートできます。";
//ページの幅と高さを取得する
double pageWidth = page.getClientSize().getWidth();
double pageHeight = page.getClientSize().getHeight();
//PdfSolidBrush クラスのオブジェクトを作成する
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
//PdfTrueTypeFont クラスのオブジェクトを作成する
PdfTrueTypeFont font= new PdfTrueTypeFont(new Font("Yu Mincho",Font.PLAIN,14));
//PdfStringFormat クラスによるテキスト配置を設定する
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Left);
//テキストを描画する
page.getCanvas().drawString(s1, font, brush, new Rectangle2D.Double(0, 20, pageWidth / 2 - 8f, pageHeight), format);
page.getCanvas().drawString(s2, font, brush, new Rectangle2D.Double(pageWidth / 2 + 8f, 20, pageWidth / 2 - 8f, pageHeight), format);
//ドキュメントを保存する
String output = "2段組PDFの作成.pdf";
doc.saveToFile(output, FileFormat.PDF);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS 12.9.2 のリリースを発表できることを嬉しく思います。このバージョンでは、条件付き書式の色の取得をサポートしました。Excel から PDF への変換機能を強化しました。また、Linux システムで RichText を取得する際に、アプリケーションが「System.ArgumentException」をスローするなどの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4084 | 条件付き書式の色の取得をサポートしました。
Color color = cRange.GetConditionFormatsStyle().Color; |
| Bug | SPIREXLS-718 SPIREXLS-4066 |
XLS を PDF に変換した後、コンテンツの書式が正しくない問題を修正しました。 |
| Bug | SPIREXLS-2073 | Linux システムで RichText を取得する際に、アプリケーションが「System.ArgumentException」をスローする問題を修正しました。 |
| Bug | SPIREXLS-2308 | システム DPI が125%に設定されている場合、グラフをイメージに保存した後に内容が切り取られる問題が修正されました。 |
| Bug | SPIREXLS-3036 | Excel を PDF に変換した後、改ページが正しくない問題が修正されました。 |
| Bug | SPIREXLS-3278 | システム DPI が125%に設定されている場合、Excel をイメージに保存した後に内容が不完全になっていた問題が修正されました。 |
| Bug | SPIREXLS-4038 | グラフをイメージに変換した後、内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4047 | Pdf OLE オブジェクトをExcelに挿入できなかった問題が修正されました。 |
| Bug | SPIREXLS-4051 | Excel を PDF に変換する際に、アプリケーションが「Shape failing to render」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4069 | Excel をロード時に、アプリケーションがハングアップしていた問題が修正されました。 |
| Bug | SPIREXLS-4087 | 新しいバージョンでセルが sheet.Range[0,1].Text="=SUM(18,29)" に対して生成した数値書式が、テキストではなく式の計算値である問題が修正されました。 |
| Bug | SPIREXLS-4099 | Excel をロードする際にアプリケーションが「Element is an invalid XmlNodeType」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4100 | Excel をイメージに変換した後、コンテンツが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4104 | 日付をセルに挿入すると日付の書式が失われる問題が修正されました。 |
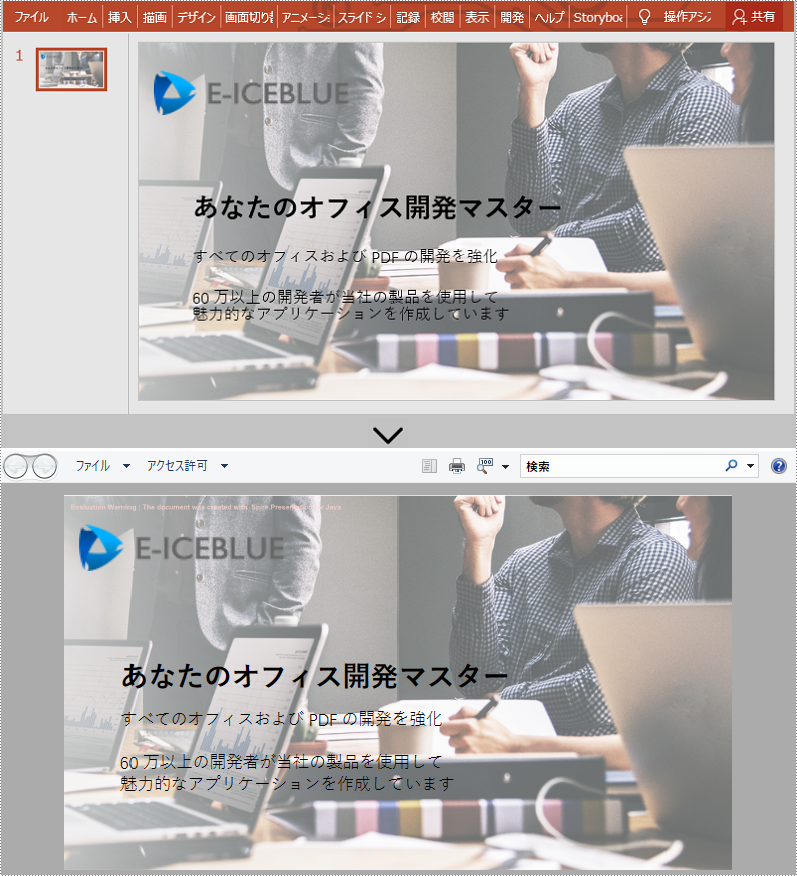
XPS は固定ページレイアウトを持つファイル書式です。この書式は、ドキュメントの忠実度を維持し、デバイスに依存しないドキュメントの外観を提供することができます。PowerPoint ファイルを既存の形式で印刷したり、他の人に送信したりするには、XPS に変換することができます。この記事では、Spire.Presentation for Java を使用して PowerPoint を XPS に変換する方法を示します。以下に具体的な手順と方法を示します。
まず、Spire.Presentation for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.presentation</artifactId>
<version>7.8.2</version>
</dependency>
</dependencies>Spire.Presentation for Java が提供する Presentation.saveToFile(java.lang.String file, FileFormat fileFormat) メソッドは、スライドを XPS ファイル書式として保存します。具体的な手順は次のとおりです。
import com.spire.presentation.*;
public class PPTtoXPS {
public static void main(String[] args) throws Exception{
// Presentationクラスのオブジェクトを作成する
Presentation ppt = new Presentation();
// PowerPointプレゼンテーションをロードする
ppt.loadFromFile("input.pptx");
//ファイルをXPSとして保存する
ppt.saveToFile("ToXPS.xps",FileFormat.XPS);
ppt.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Doc 10.9.6 のリリースを発表できることを嬉しく思います。このバージョンでは、Word から PDF への変換機能を強化しました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREDOC-8386 | Word を PDF に変換した後、灰色の長方形の左枠が切り取られていた問題が修正されました。 |
| Bug | SPIREDOC-8390 | Word を PDF に変換した後、一部のコンテンツが失われていた問題が修正されました。 |
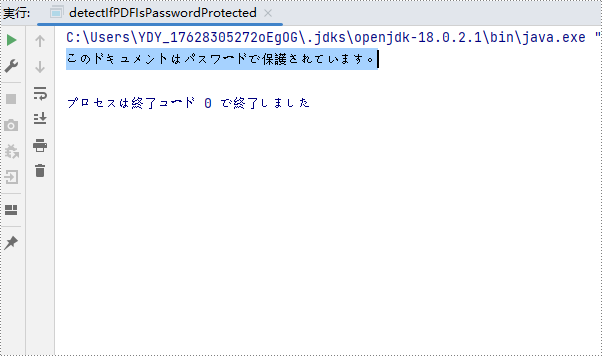
パスワードで保護された PDF を開くとき、それはパスワードを入力する必要があります。しかし、時には、PDF を開く前に、PDF がパスワードで保護されているかどうかを知る必要があります。Spire.PDF for Java は、PDF ドキュメントがパスワードで保護されているかどうかを判断するためのメソッド PdfDocument.isPasswordProtected() を提供しています。
まず、Spire. PDF for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>8.8.3</version>
</dependency>
</dependencies>詳しい手順は以下の通りです。
import com.spire.pdf.PdfDocument;
public class detectIfPDFIsPasswordProtected {
public static void main(String[] args) throws Exception {
//ファイルパスを定義する
String filePath ="Sample.pdf";
//PDFドキュメントがパスワードで保護されているかどうかを検出する
boolean isProtected = PdfDocument.isPasswordProtected(filePath);
//結果を印刷する
if(isProtected)
{
System.out.println("このドキュメントはパスワードで保護されています。");
}
else
{
System.out.println("このドキュメントはパスワードで保護されていません。");
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





