チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Spire.Presentation 8.11.1のリリースをお知らせいたします。このバージョンでは、図形内のテキスト領域の高さと幅の取得や、図形内の複数行のテキストの取得など、いくつかの新機能をサポートしています。 また、shape.TextFrame.GetTextLocation() メソッドの実行時に、アプリケーションが「System.InvalidCastException」をスローする問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPPT-2378 | 図形を SVG に変換するときに、スライドに図形の位置情報の維持をサポートします。
byte[] svgByte = shape.SaveAsSvgInSlide();
FileStream fs = new FileStream("shapePath_" + num + ".svg", FileMode.Create);
fs.Write(svgByte, 0, svgByte.Length);
fs.Close(); |
| New feature | SPIREPPT-2379 | 図形内のテキスト領域の高さと幅の取得をサポートします。
IAutoShape autoShape = shape as IAutoShape; SizeF size = autoShape.TextFrame.GetTextSize(); |
| New feature | SPIREPPT-2384 | 図形内の複数行のテキストの取得をサポートします。
Presentation ppt = new Presentation();
ppt.LoadFromFile(inputFile);
ISlide slide = ppt.Slides[0];
for (int i = 0; i < slide.Shapes.Count; i++)
{
IAutoShape shape = (IAutoShape)slide.Shapes[i];
File.AppendAllText(outputFile, "shape" + i + ":" + "\r\n");
IList<LineText> lines = shape.TextFrame.GetLayoutLines();
for (int j = 0; j < lines.Count; j++)
{
File.AppendAllText(outputFile,"line[" + j + "]:" + lines[j].Text + "\r\n");
}
} |
| New feature | SPIREPPT-2390 | OleObject オブジェクトの ShapeID プロパティの取得をサポートします。
Presentation ppt = new Presentation();
ppt.LoadFromFile(inputFile);
OleObjectCollection oles = ppt.Slides[0].OleObjects;
OleObject oleObject = oles[0];
StringBuilder sb = new StringBuilder();
sb.AppendLine("ShapeID=" + oleObject.ShapeID);
foreach (DictionaryEntry entry in oleObject.Properties)
{
sb.AppendLine(entry.Key + ":" + entry.Value);
}
File.AppendAllText(outputFile, sb.ToString()); |
| Bug | SPIREPPT-2391 | shape.TextFrame.GetTextLocation() メソッドの実行時に、アプリケーションが「System.InvalidCastException」をスローする問題が修正されました。 |
Spire.Office 8.11.0のリリースを発表できることを嬉しく思います。このバージョンでは Linux プラットフォームがサポートされています。 Spire.PDF for C++ は PdfMarker タイプをサポートします。 さらに、いくつかの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5945 | PdfMarkerタイプがサポートされています。
intrusive_ptr<PdfDocument> doc = new PdfDocument(); intrusive_ptr<PdfNewPage> page = Object::Dynamic_cast<PdfNewPage>(doc->GetPages()->Add()); intrusive_ptr<PdfMarker> marker = new PdfMarker(PdfUnorderedMarkerStyle::CustomImage); marker->SetImage(PdfImage::FromFile(inputFile_Img.c_str())); std::wstring listContent = L"Data Structure\n"; listContent += L"Algorithm\n"; listContent += L"Computer Newworks\n"; listContent += L"Operating System\n"; listContent += L"C Programming\n"; listContent += L"Computer Organization and Architecture"; intrusive_ptr<PdfList> list = new PdfList(listContent.c_str()); list->SetIndent(2); list->SetTextIndent(4); list->SetMarker(marker); ((intrusive_ptr<PdfLayoutWidget>)list)->Draw(page, 100, 100); doc->SaveToFile(outputFile.c_str(), FileFormat::PDF); doc->Close(); |
| Bug | SPIREPDF-6052 | PDF文書のリニアライズ変換時に、一次ブックマークナビゲーション機能が機能しない問題が修正されました。 |
| Bug | SPIREPDF-6173 | 署名の検証が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6191 | doc->GetXmpMetaData()メソッドが削除されました。 |
| Bug | SPIREPDF-6242 | PDF文書のプロパティの読み取りに失敗する問題が修正されました。 |
| Bug | SPIREPDF-6257 | PDFをXPSに変換するとき、「System.InvalidCastException」が何度か発生する問題が修正されました。 |
| Bug | SPIREPDF-6270 | PDF文書の圧縮に失敗する問題が修正されました。 |
| Bug | SPIREPDF-6344 | PDFをPPTXに変換するとき、プログラムが 「System.TypeInitialisationException」をスローする問題が修正されました。 |
Spire.PDF for C++ 9.11.0を発表できることを嬉しく思います。このバージョンでは、PdfMarkerタイプがサポートされています。また、PDFからXPSやPowerPointファイルへの変換機能が強化されました。さらに、PDF文書の圧縮が失敗するなど、いくつかの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-5945 | PdfMarkerタイプがサポートされています。
intrusive_ptr<PdfDocument> doc = new PdfDocument(); intrusive_ptr<PdfNewPage> page = Object::Dynamic_cast<PdfNewPage>(doc->GetPages()->Add()); intrusive_ptr<PdfMarker> marker = new PdfMarker(PdfUnorderedMarkerStyle::CustomImage); marker->SetImage(PdfImage::FromFile(inputFile_Img.c_str())); std::wstring listContent = L"Data Structure\n"; listContent += L"Algorithm\n"; listContent += L"Computer Newworks\n"; listContent += L"Operating System\n"; listContent += L"C Programming\n"; listContent += L"Computer Organization and Architecture"; intrusive_ptr<PdfList> list = new PdfList(listContent.c_str()); list->SetIndent(2); list->SetTextIndent(4); list->SetMarker(marker); ((intrusive_ptr<PdfLayoutWidget>)list)->Draw(page, 100, 100); doc->SaveToFile(outputFile.c_str(), FileFormat::PDF); doc->Close(); |
| Bug | SPIREPDF-6052 | PDF文書のリニアライズ変換時に、一次ブックマークナビゲーション機能が機能しない問題が修正されました。 |
| Bug | SPIREPDF-6173 | 署名の検証が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6191 | doc->GetXmpMetaData()メソッドが削除されました。 |
| Bug | SPIREPDF-6242 | PDF文書のプロパティの読み取りに失敗する問題が修正されました。 |
| Bug | SPIREPDF-6257 | PDFをXPSに変換するとき、「System.InvalidCastException」が何度か発生する問題が修正されました。 |
| Bug | SPIREPDF-6270 | PDF文書の圧縮に失敗する問題が修正されました。 |
| Bug | SPIREPDF-6344 | PDFをPPTXに変換するとき、プログラムが 「System.TypeInitialisationException」をスローする問題が修正されました。 |
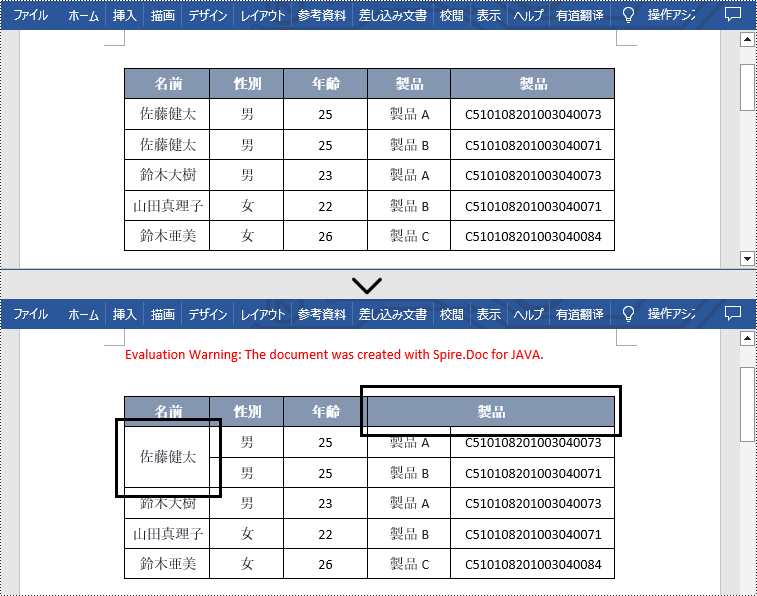
Spire.Doc for Java で提供される Table.applyVerticalMerge() メソッドと Table.applyHorizontalMerge() メソッドは、それぞれ表のセルを垂直に結合するときと水平に結合するときに使用されます。デフォルトでは、結合するセルに同じ値が複数含まれている場合、結合後のセルにもこれらの重複した値が含まれます。表をより明瞭にするために、重複した値を削除することができます。この記事では、Spire.Doc for Java を使用して Word でセルを結合する際に重複した値を削除する方法を示します。
まず、Spire.Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>セルを結合するときに重複した値を削除するには、mergeCell(Table table, boolean isHorizontalMerge, int index, int start, int end) のカスタムメソッドを作成します。このメソッドでは、結合された範囲内の最初のセルの値が範囲内の他のセルの値と同じかどうかを判断します。それらが同じである場合は、他のセルの値を削除してからセルを結合します。詳細な手順は次のとおりです。
import com.spire.doc.*;
public class MergeCells {
public static void main(String[] args) throws Exception {
//Documentクラスのオブジェクトを作成し、サンプルドキュメントを読み込む
Document document = new Document();
document.loadFromFile("Sample.docx");
//最初のセクションを取得する
Section section = document.getSections().get(0);
//最初のテーブルを取得する
Table table = section.getTables().get(0);
//セルを垂直方向に結合する
mergeCell(table, false, 0, 1, 2);
//セルを水平方向に結合する
mergeCell(table, true, 0, 3, 4);
//結果ファイルを保存する
document.saveToFile("MergeTable.docx",FileFormat.Docx_2013);
document.dispose(); }
//セルを結合する際に重複した値を削除する
public static void mergeCell(Table table, boolean isHorizontalMerge, int index, int start, int end) {
if (isHorizontalMerge) {
//テーブルから特定のセルを取得する
TableCell firstCell = table.get(index, start);
//セルからテキストを取得する
String firstCellText = getCellText(firstCell);
for (int i = start + 1; i <= end; i++) {
TableCell cell1 = table.get(index, i);
//テキストが最初のセルと同じかどうかを確認する
if (firstCellText.equals(getCellText(cell1))) {
//「はい」の場合、セル内のすべての段落をクリアする
cell1.getParagraphs().clear(); }
}
//セルを水平方向に結合する
table.applyHorizontalMerge(index, start, end); }
else {
TableCell firstCell = table.get(start, index);
String firstCellText = getCellText(firstCell);
for (int i = start + 1; i <= end; i++) {
TableCell cell1 = table.get(i, index);
if (firstCellText.equals(getCellText(cell1))) {
cell1.getParagraphs().clear();
}
}
//セルを垂直方向に結合する
table.applyVerticalMerge(index, start, end);
}
}
public static String getCellText(TableCell cell) {
StringBuilder text = new StringBuilder();
//セルのすべての段落をループする
for (int i = 0; i < cell.getParagraphs().getCount(); i++) {
//すべての段落のテキストを取得し、StringBuilder に追加する
text.append(cell.getParagraphs().get(i).getText().trim()); }
return text.toString();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
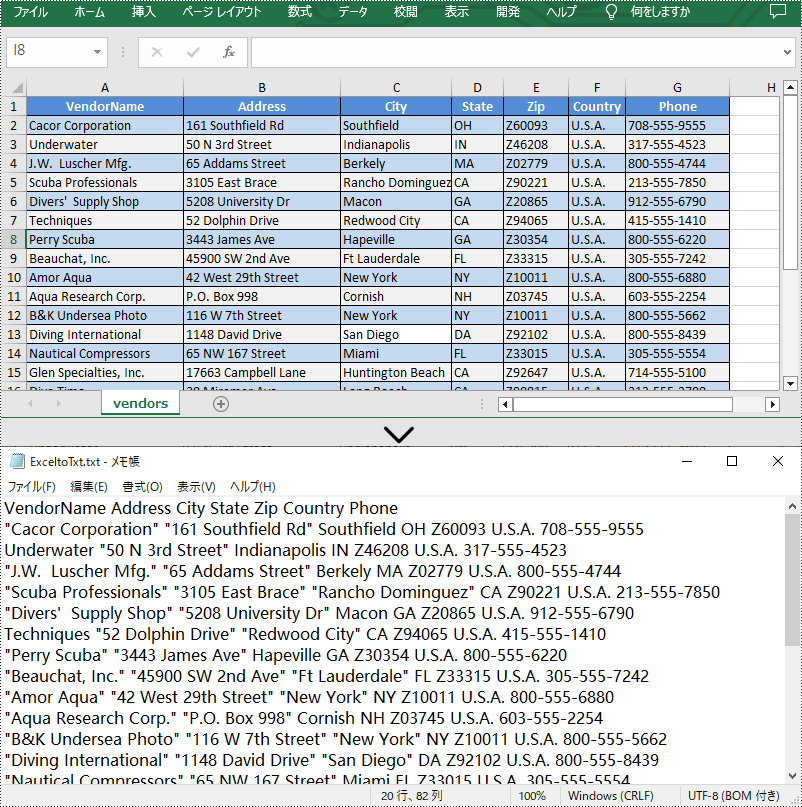
Excel ファイルをテキストファイルに変換すると、ファイルサイズが小さくなり、データの保存が容易になります。 また、TXT ファイルは専用のリーダーを必要としないため、ほとんどのデバイスで開いて編集することができ、他の人とファイルを共有することも容易になります。さらに、TXT ファイルは構造が単純なため、Excel を TXT に変換することで文書処理が簡単になることもあります。この記事では、Spire.XLS for Java を使用して、Excel をテキスト (TXT) に変換する方法を示します。
まず、Spire.XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.11.6</version>
</dependency>
</dependencies>Spire.XLS for Java は、指定されたワークシートを TXT ファイルに変換するための Worksheet.saveToFile(String fileName, String separator, java.nio.charset.Charset encoding) メソッドを提供します。以下は詳細な手順です。
import com.spire.xls.*;
import java.nio.charset.Charset;
public class toText {
public static void main(String[] args) {
//Workbook インスタンスを作成する
Workbook workbook = new Workbook();
//サンプルExcelファイルをロードする
workbook.loadFromFile("sample.xlsx");
//最初のワークシートを取得する
Worksheet worksheet = workbook.getWorksheets().get(0);
//ワークシート を TXT ファイルに変換する
Charset charset = Charset.forName("utf8");
worksheet.saveToFile("ExceltoTxt.txt", " ", charset);
workbook.dispose();
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.XLS 13.11.4のリリースをお知らせできることをうれしく思います。このバージョンでは、ExcelからHTMLやPDFへの変換機能が強化されました。また、SHEET(A3)関数が自動計算されなかったり、ワークシートをコピーした後に透かしが正しく表示されなかったりといった既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4876 | ExcelをHTMLに変換した後、セルが欠落する問題が修正されました。 |
| Bug | SPIREXLS-4880 | ExcelをPDFに変換した後、フォントディレクトリの設定が有効にならない問題が修正されました。 |
| Bug | SPIREXLS-4904 | SHEET(A3)関数が自動計算されない問題が修正されました。 |
| Bug | SPIREXLS-4922 | ワークシート暗号化の判定結果が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4925 | ワークシートをコピーすると透かしが不正になる問題が修正されました。 |
| Bug | SPIREXLS-4931 | ExcelをPDFに変換した後、ページングが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4933 | Excelの読み込み時に、プログラムが 「System.FormatException 」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4942 | Excelを画像に変換する際に、括弧が認識されない問題が修正されました。 |
| Bug | SPIREXLS-4963 | Excel 365で作成したカスタム図形を別のワークシートにコピーすると、一部の内容が失われる問題が修正されました。 |
Spire.Office for Java 8.11.3を発表できることをうれしく思います。このリリースでは、Spire.XLS for Javaは「Name Manager」からの注釈の取得をサポートしています。Spire.PDF for JavaではPDFからWordやPPTXへの変換機能が強化されました。Spire.Presentation for JavaではスライドからSVGへの変換機能が強化されました。さらに、多くの既知のバグも修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | SPIREXLS-4919 | 「Name Manager」からの注釈の取得をサポートしています。
Workbook workbook = new Workbook();
workbook.loadFromFile(inputFile);
INameRanges nameManager = workbook.getNameRanges();
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < nameManager.getCount(); i++) {
XlsName name = (XlsName) nameManager.get(i);
stringBuilder.append("Name: " + name.getName() + ", Comment: " + name.getCommentValue() + "\r\n");
}
workbook.dispose(); |
| Bug | SPIREXLS-4911 | LinuxでExcelからPDFへの変換速度を改善しました。 |
| Bug | SPIREXLS-4860 | ExcelからPDFに変換するとき、setSheetFitToPageメソッドを設定するとページサイズの設定に失敗する問題を修正しました。 |
| Bug | SPIREXLS-4894 | ピボットテーブルの枠線の削除に失敗する問題を修正しました。 |
| Bug | SPIREXLS-4906 | ExcelをPDFに変換した後、テキストが反転して切り取られる問題を修復しました。 |
| Bug | SPIREXLS-4923 | Excel文書読み込み時に、プログラムが「Invalid ValidationAlertType」をスローする問題を修正しました。 |
| Bug | SPIREXLS-4924 | Excel文書読み込み時に、プログラムが「Input string was not in the correct format」をスローする問題を修正しました。 |
| Bug | SPIREXLS-4966 | Excel ワークシートを HTML に変換するときに、プログラムが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4967 | ExcelをHTMLに変換した後、テキストコンテンツに多くの余分な「0」が表示される問題が修正されました。 |
| Bug | SPIREXLS-4968 | 行の高さが自動調整される Excel を PDF に変換した後、セルの内容が部分的に失われる問題が修正されました。 |
| Bug | SPIREXLS-4970 | 結合されたセルの取得内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4975 | 文字列を検索すると間違った結果が返される問題が修正されました。 |
| Bug | SPIREXLS-4977 | ワークシートをコピーするときに、チャート参照が誤って更新される問題が修正されました。 |
| Bug | SPIREXLS-4990 | DisplayedText 値の取得が正しくない問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5830 | PDF文書の表の内容を抽出できない問題が修正されました。 |
| Bug | SPIREPDF-6315 | UbuntuシステムでPDFをPPTXに変換する際に、コンテンツが繰り返し描画される問題が修正されました。 |
| Bug | SPIREPDF-6323 | LinuxシステムでPDFをWordに変換する際に、プログラムが 「No 'DCWGQU+CambriaMath' font found!」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6359 | 小冊子を作成する際に、表紙の綴じ方向が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6364 | PDF をロードする際に、プログラムが「PDF file structure is not valid」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6389 | appendPage() メソッドを使用して PDF 文書を結合する際に、プログラムが「NullPointerException」をスローする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPPT-2114 | スライドをSVGに変換した後、内容が正しくない問題が修正されました。 |
| Bug | SPIREPPT-2140 SPIREPPT-2373 |
スライドを SVG に変換した後、グラデーションの背景色が正しくなくなる問題が修正されました。 |
| Bug | SPIREPPT-2380 | スライドを SVG に変換した後、内容が不鮮明になる問題が修正されました。 |
| Bug | SPIREPPT-2381 | 「Indent Text When Overflow」の設定が無効になる問題が修正されました。 |
| Bug | SPIREPPT-2383 | 挿入されたHTMLテキストの下線が欠落する問題が修正されました。 |
| Bug | SPIREPPT-2386 | 「Resize Shape to Fit Text」の設定が無効になる問題が修正されました。 |
Spire.XLS for Java 13.11.6のリリースをお知らせいたします。このバージョンでは、ExcelからHTMLやPDF への変換機能が強化されました。また、DisplayedText 値の取得が正しくないなど、既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-4966 | Excel ワークシートを HTML に変換するときに、プログラムが「java.lang.NullPointerException」をスローする問題が修正されました。 |
| Bug | SPIREXLS-4967 | ExcelをHTMLに変換した後、テキストコンテンツに多くの余分な「0」が表示される問題が修正されました。 |
| Bug | SPIREXLS-4968 | 行の高さが自動調整される Excel を PDF に変換した後、セルの内容が部分的に失われる問題が修正されました。 |
| Bug | SPIREXLS-4970 | 結合されたセルの取得内容が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4975 | 文字列を検索すると間違った結果が返される問題が修正されました。 |
| Bug | SPIREXLS-4977 | ワークシートをコピーするときに、チャート参照が誤って更新される問題が修正されました。 |
| Bug | SPIREXLS-4990 | DisplayedText 値の取得が正しくない問題が修正されました。 |
Spire.PDF for Java 9.11.3を発表できることをうれしく思います。このバージョンでは、PDFからWordやPPTXへの変換機能が強化されました。また、PDF文書の表の内容を抽出できない問題など、いくつかの既知の問題も修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPDF-5830 | PDF文書の表の内容を抽出できない問題が修正されました。 |
| Bug | SPIREPDF-6315 | UbuntuシステムでPDFをPPTXに変換する際に、コンテンツが繰り返し描画される問題が修正されました。 |
| Bug | SPIREPDF-6323 | LinuxシステムでPDFをWordに変換する際に、プログラムが 「No 'DCWGQU+CambriaMath' font found!」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6359 | 小冊子を作成する際に、表紙の綴じ方向が正しくない問題が修正されました。 |
| Bug | SPIREPDF-6364 | PDF をロードする際に、プログラムが「PDF file structure is not valid」をスローする問題が修正されました。 |
| Bug | SPIREPDF-6389 | appendPage() メソッドを使用して PDF 文書を結合する際に、プログラムが「NullPointerException」をスローする問題が修正されました。 |
Spire.Doc 11.11.8のリリースをお知らせいたします。このバージョンでは、列挙「Spire.Doc.Publics.Drawing.FontStyle」が公開されました。また、「PrivateFontPath」構造体の「FontStyle」の名前空間を「Spire.Doc.Publics.Drawing」に変更されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | 列挙「Spire.Doc.Publics.Drawing.FontStyle」が公開されました。 |
| New feature | - | 「PrivateFontPath」構造体の「FontStyle」の名前空間を「Spire.Doc.Publics.Drawing」に変更されました。 説明:
メソッド public PrivateFontPath(string fontName, System.Drawing.FontStyle fontStyle, string fontPath) は public PrivateFontPath(string fontName, Spire.Doc.Publics.Drawing.FontStyle fontStyle, string fontPath) に変更されました。 メソッドpublic PrivateFontPath(string fontName, System.Drawing.FontStyle fontStyle, string fontPath, bool useArabicConcatenationRules)はpublic PrivateFontPath(string fontName, Spire.Doc.Publics.Drawing.FontStyle fontStyle, string fontPath, bool useArabicConcatenationRules)に変更されました。 |





