チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

電子文書では透かしを使用して著作権を保護したり、状態を指定したりすることがよくあります。Microsoft Excel には Excel に透かしを追加するための機能はありませんが、ヘッダー画像やワードアートを挿入するなど、透かし効果を実現するための特別な方法を使用することができます。この記事では、Spire.XLS for .NET を使用して、C# および VB.NET でプログラムによって Excel に透かしを追加する方法を紹介します。
まず、Spire.XLS for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.XLSヘッダー画像を作成するために、DrawWatermarkImage() というカスタムの方法を定義しました。この方法では、文字列(機密、ドラフト、内部使用などの透かしとして表示するテキスト)に基づいてカスタムの画像を生成できます。画像を生成したら、Worksheet.PageSetup.LeftHeaderImage と Worksheet.PageSetup.LeftHeader プロパティを使用して、画像をワークシートのヘッダーのセクションに追加できます。詳細な手順は次のとおりです。
using Spire.Xls;
using System.Drawing;
namespace AddWatermark
{
class Program
{
static void Main(string[] args)
{
//Workbookクラスのインスタンスを初期化し、Excelファイルをロードする
Workbook workbook = new Workbook();
workbook.LoadFromFile(@"Sample.xlsx");
//フォントを作成する
Font font = new Font("Arial", 40);
//テキストを定義する
string watermark = "機密";
//ファイル内のすべてのシートをループする
foreach (Worksheet sheet in workbook.Worksheets)
{
//DrawWatermarkImage()メソッドを使用して、テキストに基づいて画像を作成する
Image imgWtrmrk = DrawWatermarkImage(watermark, font, Color.LightCoral, Color.White, sheet.PageSetup.PageHeight, sheet.PageSetup.PageWidth);
//各シートの左ヘッダーのセクションに画像を追加する
sheet.PageSetup.LeftHeaderImage = imgWtrmrk;
sheet.PageSetup.LeftHeader = "&G";
//シートのビューモードを透かしを見るためのページレイアウトに変更する
sheet.ViewMode = ViewMode.Layout;
}
///結果ファイルを保存する
workbook.SaveToFile("AddWatermark.xlsx", ExcelVersion.Version2013);
}
private static Image DrawWatermarkImage(string text, Font font, Color textColor, Color backColor, double height, double width)
{
//指定した幅と高さの画像を作成する
Image img = new Bitmap((int)width, (int)height);
//画像からグラフィックのオブジェクトを作成する
Graphics drawing = Graphics.FromImage(img);
//テキストのサイズを取得する
SizeF textSize = drawing.MeasureString(text, font);
//指定されたトランスレーションをグラフィックの変換マトリックスに前置きして座標系の原点を変更する
drawing.TranslateTransform(((int)width - textSize.Width) / 2, ((int)height - textSize.Height) / 2);
//ローテーションを適用する
drawing.RotateTransform(-45);
//指定されたトランスレーションをグラフィックの変換マトリックスに前置きして座標系の原点を変更する
drawing.TranslateTransform(-((int)width - textSize.Width) / 2, -((int)height - textSize.Height) / 2);
//背景をペイントする
drawing.Clear(backColor);
//テキストのブラシを作成する
Brush textBrush = new SolidBrush(textColor);
//グラフィックの中心にテキストを描画する
drawing.DrawString(text, font, textBrush, ((int)width - textSize.Width) / 2, ((int)height - textSize.Height) / 2);
drawing.Save();
return img;
}
}
}Imports Spire.Xls
Imports System.Drawing
Namespace AddWatermark
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Workbookクラスのインスタンスを初期化し、Excelファイルをロードする
Dim workbook As Workbook = New Workbook()
workbook.LoadFromFile("Sample.xlsx")
'フォントを作成する
Dim font As Font = New Font("Arial", 40)
'テキストを定義する
Dim watermark = "機密"
'ファイル内のすべてのシートをループする
For Each sheet As Worksheet In workbook.Worksheets
'DrawWatermarkImage()メソッドを呼び出してテキストに基づいて画像を作成する
Dim imgWtrmrk As Image = DrawWatermarkImage(watermark, font, Color.LightCoral, Color.White, sheet.PageSetup.PageHeight, sheet.PageSetup.PageWidth)
'各シートの左ヘッダーのセクションに画像を追加する
sheet.PageSetup.LeftHeaderImage = imgWtrmrk
sheet.PageSetup.LeftHeader = "&G"
'シートのビューモードを透かしを見るためのページレイアウトに変更する
sheet.ViewMode = ViewMode.Layout
Next
'結果ファイルを保存する
workbook.SaveToFile("AddWatermark.xlsx", ExcelVersion.Version2013)
End Sub
Private Shared Function DrawWatermarkImage(ByVal text As String, ByVal font As Font, ByVal textColor As Color, ByVal backColor As Color, ByVal height As Double, ByVal width As Double) As Image
'指定した幅と高さの画像を作成する
Dim img As Image = New Bitmap(width, height)
'画像からグラフィックのオブジェクトを作成する
Dim drawing As Graphics = Graphics.FromImage(img)
'テキストのサイズを取得する
Dim textSize As SizeF = drawing.MeasureString(text, font)
'指定されたトランスレーションをグラフィックの変換マトリックスに前置きして座標系の原点を変更する
drawing.TranslateTransform((CInt(width) - textSize.Width) / 2, (CInt(height) - textSize.Height) / 2)
'ローテーションを適用する
drawing.RotateTransform(-45)
'指定されたトランスレーションをグラフィックの変換マトリックスに前置きして座標系の原点を変更する
drawing.TranslateTransform(-(CInt(width) - textSize.Width) / 2, -(CInt(height) - textSize.Height) / 2)
'背景をペイントする
drawing.Clear(backColor)
'テキストのブラシを作成する
Dim textBrush As Brush = New SolidBrush(textColor)
'グラフィックの中心にテキストを描画する
drawing.DrawString(text, font, textBrush, (CInt(width) - textSize.Width) / 2, (CInt(height) - textSize.Height) / 2)
drawing.Save()
Return img
End Function
End Class
End Namespace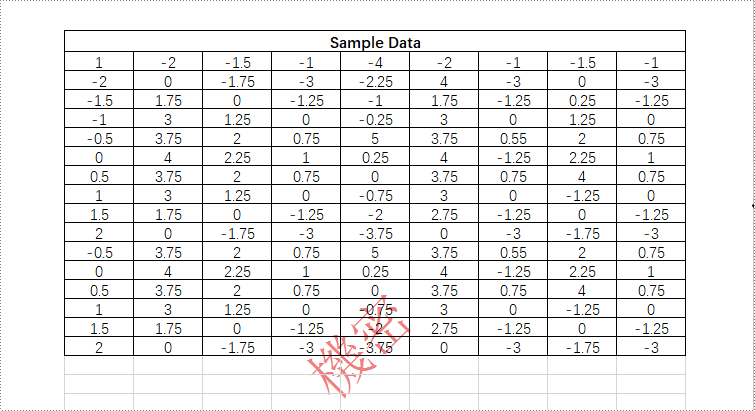
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
セルの結合は、2つ以上のセルを1つの大きなセルに結合することです。セルの分割は、1つのセルを2つ以上の小さなセルに分割することです。Microsoft Word で表を作成または編集する際には、データをよりよく表示するために、表のセルを結合または分割する必要があることがよくあります。この記事では、Spire.Doc for .NET を使用して、C# および VB.NET でプログラムによって Word で表のセルを結合または分割する方法を示します。
まず、Spire.Doc for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
PM> Install-Package Spire.DocMicrosoft Word では、垂直または水平に隣接する2つ以上のセルを1つの大きなセルに結合できます。Spire.Doc では、Table.ApplyHorizontalMerge() と Table.ApplyVerticalMerge() メソッドを使用してセルを結合できます。詳細な手順は次のとおりです。
using Spire.Doc;
using Spire.Doc.Documents;
namespace MergeTableCells
{
class Program
{
static void Main(string[] args)
{
//Documentインスタンスを作成する
Document document = new Document();
//Wordドキュメントをロードする
document.LoadFromFile("sample.docx");
//最初のセクションを取得する
Section section = document.Sections[0];
//セクションに4 x 4の表を追加する
Table table = section.AddTable();
table.ResetCells(4, 4);
//最初の行のセル1、2、3、4を水平に結合する
table.ApplyHorizontalMerge(0, 0, 3);
//最初の列のセル3と4を垂直に結合する
table.ApplyVerticalMerge(0, 2, 3);
//表にデータを追加する
for (int row = 0; row < table.Rows.Count; row++)
{
for (int col = 0; col < table.Rows[row].Cells.Count; col++)
{
TableCell cell = table[row, col];
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle;
Paragraph paragraph = cell.AddParagraph();
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center;
paragraph.Text = "テキスト";
}
}
//表にスタイルを適用する
table.ApplyStyle(DefaultTableStyle.LightGridAccent1);
//結果ドキュメントを保存する
document.SaveToFile("MergeCells.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Namespace MergeTableCells
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Documentインスタンスを作成する
Dim document As Document = New Document()
'Wordドキュメントをロードする
document.LoadFromFile("sample.docx")
'最初のセクションを取得する
Dim section As Section = document.Sections(0)
'セクションに4 x 4の表を追加する
Dim table As Table = section.AddTable()
table.ResetCells(4, 4)
'最初の行のセル1、2、3、4を水平に結合する
table.ApplyHorizontalMerge(0, 0, 3)
'最初の列のセル3と4を垂直に結合する
table.ApplyVerticalMerge(0, 2, 3)
'表にデータを追加する
For row As Integer = 0 To table.Rows.Count - 1
For col As Integer = 0 To table.Rows(row).Cells.Count - 1
Dim cell As TableCell = table(row, col)
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
Dim paragraph As Paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.Text = "テキスト"
Next
Next
'表にスタイルを適用する
table.ApplyStyle(DefaultTableStyle.LightGridAccent1)
'結果ドキュメントを保存する
document.SaveToFile("MergeCells.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace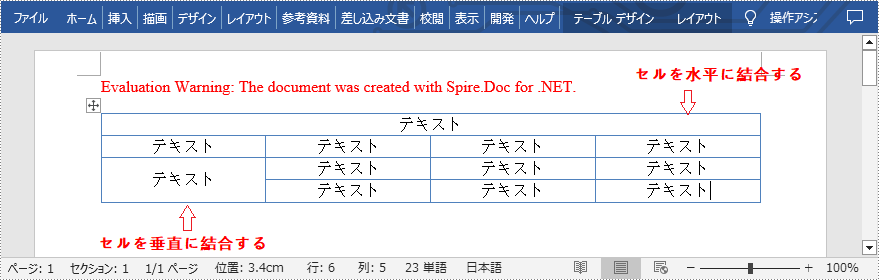
Spire.Doc for .NET が提供する TableCell.SplitCell() メソッドは、Word で表のセルを2つ以上のセルに分割することをサポートしています。詳細な手順は次のとおりです。
using Spire.Doc;
namespace SplitTableCells
{
class Program
{
static void Main(string[] args)
{
//Documentインスタンスを作成する
Document document = new Document();
//Wordドキュメントをロードする
document.LoadFromFile("MergeCells.docx");
//最初のセクションを取得する
Section section = document.Sections[0];
//セクションの最初の表を取得する
Table table = section.Tables[0] as Table;
//4行の4番目のセルを取得する
TableCell cell1 = table.Rows[3].Cells[3];
//セルを2列2行に分割する
cell1.SplitCell(2, 2);
//結果ドキュメントを保存する
document.SaveToFile("SplitCells.docx", FileFormat.Docx2013);
}
}
}Imports Spire.Doc
Namespace SplitTableCells
Friend Class Program
Private Shared Sub Main(ByVal args As String())
'Documentインスタンスを作成する
Dim document As Document = New Document()
'Wordドキュメントをロードする
document.LoadFromFile("MergeCells.docx")
'最初のセクションを取得する
Dim section As Section = document.Sections(0)
'セクションの最初の表を取得する
Dim table As Table = TryCast(section.Tables(0), Table)
'4行の4番目のセルを取得する
Dim cell1 As TableCell = table.Rows(3).Cells(3)
'セルを2列2行に分割する
cell1.SplitCell(2, 2)
'結果ドキュメントを保存する
document.SaveToFile("SplitCells.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Word と Excel は全く異なるファイルタイプです。Word ドキュメントは、論文、手紙、またはレポートを書くために使用されます。Excel ドキュメントは、データを表形式で保存したり、グラフを作成したり、データを計算したりするために使用されます。通常、Excel は Word の元のレイアウトを表示するのが難しいため、複雑な Word ドキュメントを Excel スプレッドシートに変換することはお勧めしません。
ただし、Word ドキュメントが主に表から構成されており、Excel で表データを分析したい場合は、Spire.Office for .NET を使用して Word を Excel に変換できます。この方法により、ドキュメントの可読性を維持することもできます。
まず、Spire.Office for .NET パッケージに含まれている DLL ファイルを .NET プロジェクトの参照として追加する必要があります。DLL ファイルは、このリンクからダウンロードするか、NuGet を介してインストールできます。
bPM> Install-Package Spire.Officeこのシーンでは、実際に Spire.Office パッケージの2つのライブラリが使用されています。Spire.Doc for .NET は、Word ドキュメントからコンテンツを読み取り、抽出するために使用されます。Spire.XLS for .NET は、Excel ドキュメントを作成し、特定のセルにデータを書き込むために使用されます。このコード例を理解しやすくするために、次の3つのカスタム方法を作成して変換機能を実現しました。
次の手順では、Spire.Office for .NET を使用して Word ドキュメント全体からワークシートにデータをエクスポートする方法を示します。
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using Spire.Xls;
using System;
using System.Drawing;
namespace ConvertWordToExcel
{
class Program
{
static void Main(string[] args)
{
//Documentオブジェクトを作成する
Document doc = new Document();
//Wordサンプル・ドキュメントをロードする
doc.LoadFromFile(@"sample.docx");
//Workbookオブジェクトを作成する
Workbook wb = new Workbook();
//デフォルト・ワークシートを削除する
wb.Worksheets.Clear();
//「WordToExcel」というワークシートを作成する
Worksheet worksheet = wb.CreateEmptySheet("WordToExcel");
int row = 1;
int column = 1;
//Wordドキュメントのセクションをループする
foreach (Section section in doc.Sections)
{
//セクション内のドキュメントオブジェクトをループする
foreach (DocumentObject documentObject in section.Body.ChildObjects)
{
//オブジェクトが段落かどうかを判断する
if (documentObject is Paragraph)
{
CellRange cell = worksheet.Range[row, column];
Paragraph paragraph = documentObject as Paragraph;
//Wordの段落を特定のセルにコピーする
CopyTextAndStyle(cell, paragraph);
row++;
}
//オブジェクトがテーブルかどうかを判断する
if (documentObject is Table)
{
Table table = documentObject as Table;
//テーブルのデータをWordからExcelにエクスポートする
int currentRow = ExportTableInExcel(worksheet, row, table);
row = currentRow;
}
}
}
//行の高さと列の幅を自動調整する
worksheet.AllocatedRange.AutoFitRows();
worksheet.AllocatedRange.AutoFitColumns();
//テキストをセルでラップする
worksheet.AllocatedRange.IsWrapText = true;
//ワークブックをExcelに保存する
wb.SaveToFile("WordToExcel.xlsx", ExcelVersion.Version2013);
}
//WordのテーブルからExcelセルにデータをエクスポートする
private static int ExportTableInExcel(Worksheet worksheet, int row, Table table)
{
CellRange cell;
int column;
foreach (TableRow tbRow in table.Rows)
{
column = 1;
foreach (TableCell tbCell in tbRow.Cells)
{
cell = worksheet.Range[row, column];
cell.BorderAround(LineStyleType.Thin, Color.Black);
CopyContentInTable(tbCell, cell);
column++;
}
row++;
}
return row;
}
//WordテーブルのセルからExcelのセルにコンテンツをコピーする
private static void CopyContentInTable(TableCell tbCell, CellRange cell)
{
Paragraph newPara = new Paragraph(tbCell.Document);
for (int i = 0; i < tbCell.ChildObjects.Count; i++)
{
DocumentObject documentObject = tbCell.ChildObjects[i];
if (documentObject is Paragraph)
{
Paragraph paragraph = documentObject as Paragraph;
foreach (DocumentObject cObj in paragraph.ChildObjects)
{
newPara.ChildObjects.Add(cObj.Clone());
}
if (i < tbCell.ChildObjects.Count - 1)
{
newPara.AppendText("\n");
}
}
}
CopyTextAndStyle(cell, newPara);
}
//段落のテキストとスタイルをセルにコピーする
private static void CopyTextAndStyle(CellRange cell, Paragraph paragraph)
{
RichText richText = cell.RichText;
richText.Text = paragraph.Text;
int startIndex = 0;
foreach (DocumentObject documentObject in paragraph.ChildObjects)
{
if (documentObject is TextRange)
{
TextRange textRange = documentObject as TextRange;
string fontName = textRange.CharacterFormat.FontName;
bool isBold = textRange.CharacterFormat.Bold;
Color textColor = textRange.CharacterFormat.TextColor;
float fontSize = textRange.CharacterFormat.FontSize;
string textRangeText = textRange.Text;
int strLength = textRangeText.Length;
ExcelFont font = cell.Worksheet.Workbook.CreateFont();
font.Color = textColor;
font.IsBold = isBold;
font.Size = fontSize;
font.FontName = fontName;
int endIndex = startIndex + strLength;
richText.SetFont(startIndex, endIndex, font);
startIndex += strLength;
}
if (documentObject is DocPicture)
{
DocPicture picture = documentObject as DocPicture;
cell.Worksheet.Pictures.Add(cell.Row, cell.Column, picture.Image);
cell.Worksheet.SetRowHeightInPixels(cell.Row, 1, picture.Image.Height);
}
}
switch (paragraph.Format.HorizontalAlignment)
{
case HorizontalAlignment.Left:
cell.Style.HorizontalAlignment = HorizontalAlignType.Left;
break;
case HorizontalAlignment.Center:
cell.Style.HorizontalAlignment = HorizontalAlignType.Center;
break;
case HorizontalAlignment.Right:
cell.Style.HorizontalAlignment = HorizontalAlignType.Right;
break;
}
}
}
}Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Imports Spire.Xls
Imports System
Imports System.Drawing
Namespace ConvertWordToExcel
Class Program
Shared Sub Main(ByVal args() As String)
'Documentオブジェクトを作成する
Document doc = New Document()
'Wordサンプル・ドキュメントをロードする
doc.LoadFromFile("sample.docx")
'Workbookオブジェクトを作成する
Dim wb As Workbook = New Workbook()
'デフォルト・ワークシートを削除する
wb.Worksheets.Clear()
'「WordToExcel」というワークシートを作成する
Dim worksheet As Worksheet = wb.CreateEmptySheet("WordToExcel")
Dim row As Integer = 1
Dim column As Integer = 1
'Wordドキュメントのセクションをループする
Dim section As Section
For Each section In doc.Sections
'セクション内のドキュメントオブジェクトをループする
Dim documentObject As DocumentObject
For Each documentObject In section.Body.ChildObjects
'オブジェクトが段落かどうかを判断する
If TypeOf documentObject Is Paragraph Then
Dim cell As CellRange = worksheet.Range(row,column)
Dim paragraph As Paragraph = documentObject as Paragraph
'Wordの段落を特定のセルにコピーする
CopyTextAndStyle(cell, paragraph)
row = row + 1
End If
'オブジェクトがテーブルかどうかを判断する
If TypeOf documentObject Is Table Then
Dim table As Table = documentObject as Table
'テーブルのデータをWordからExcelにエクスポートする
Dim currentRow As Integer = ExportTableInExcel(worksheet,row,table)
row = currentRow
End If
Next
Next
'行の高さと列の幅を自動調整する
worksheet.AllocatedRange.AutoFitRows()
worksheet.AllocatedRange.AutoFitColumns()
'テキストをセルでラップする
worksheet.AllocatedRange.IsWrapText = True
'ワークブックをExcelに保存する
wb.SaveToFile("WordToExcel.xlsx", ExcelVersion.Version2013)
End Sub
'WordのテーブルからExcelセルにデータをエクスポートする
Private Shared Function ExportTableInExcel(ByVal worksheet As Worksheet, ByVal row As Integer, ByVal table As Table) As Integer
Dim cell As CellRange
Dim column As Integer
Dim tbRow As TableRow
For Each tbRow In table.Rows
column = 1
Dim tbCell As TableCell
For Each tbCell In tbRow.Cells
cell = worksheet.Range(row, column)
cell.BorderAround(LineStyleType.Thin, Color.Black)
CopyContentInTable(tbCell, cell)
column = column + 1
Next
row = row + 1
Next
Return row
End Function
'WordテーブルのセルからExcelのセルにコンテンツをコピーする
Private Shared Sub CopyContentInTable(ByVal tbCell As TableCell, ByVal cell As CellRange)
Dim NewPara As Paragraph = New Paragraph(tbCell.Document)
Dim i As Integer
For i = 0 To tbCell.ChildObjects.Count- 1 Step i + 1
Dim documentObject As DocumentObject = tbCell.ChildObjects(i)
If TypeOf documentObject Is Paragraph Then
Dim paragraph As Paragraph = documentObject as Paragraph
Dim cObj As DocumentObject
For Each cObj In paragraph.ChildObjects
NewPara.ChildObjects.Add(cObj.Clone())
Next
If i < tbCell.ChildObjects.Count - 1 Then
NewPara.AppendText("\n")
End If
End If
Next
CopyTextAndStyle(cell, NewPara)
End Sub
'段落のテキストとスタイルをセルにコピーする
Private Shared Sub CopyTextAndStyle(ByVal cell As CellRange, ByVal paragraph As Paragraph)
Dim richText As RichText = cell.RichText
richText.Text = paragraph.Text
Dim startIndex As Integer = 0
Dim documentObject As DocumentObject
For Each documentObject In paragraph.ChildObjects
If TypeOf documentObject Is TextRange Then
Dim textRange As TextRange = documentObject as TextRange
Dim fontName As String = textRange.CharacterFormat.FontName
Dim isBold As Boolean = textRange.CharacterFormat.Bold
Dim textColor As Color = textRange.CharacterFormat.TextColor
Dim fontSize As single = textRange.CharacterFormat.FontSize
Dim textRangeText As String = textRange.Text
Dim strLength As Integer = textRangeText.Length
Dim font As ExcelFont = cell.Worksheet.Workbook.CreateFont()
font.Color = textColor
font.IsBold = isBold
font.Size = fontSize
font.FontName = fontName
Dim endIndex As Integer = startIndex + strLength
richText.SetFont(startIndex, endIndex, font)
startIndex += strLength
End If
If TypeOf documentObject Is DocPicture Then
Dim picture As DocPicture = documentObject as DocPicture
cell.Worksheet.Pictures.Add(cell.Row, cell.Column, picture.Image)
cell.Worksheet.SetRowHeightInPixels(cell.Row, 1, picture.Image.Height)
End If
Next
Select Case paragraph.Format.HorizontalAlignment
Case HorizontalAlignment.Left
cell.Style.HorizontalAlignment = HorizontalAlignType.Left
Exit For
Case HorizontalAlignment.Center
cell.Style.HorizontalAlignment = HorizontalAlignType.Center
Exit For
Case HorizontalAlignment.Right
cell.Style.HorizontalAlignment = HorizontalAlignType.Right
Exit For
End Select
End Sub
End Class
End Namespace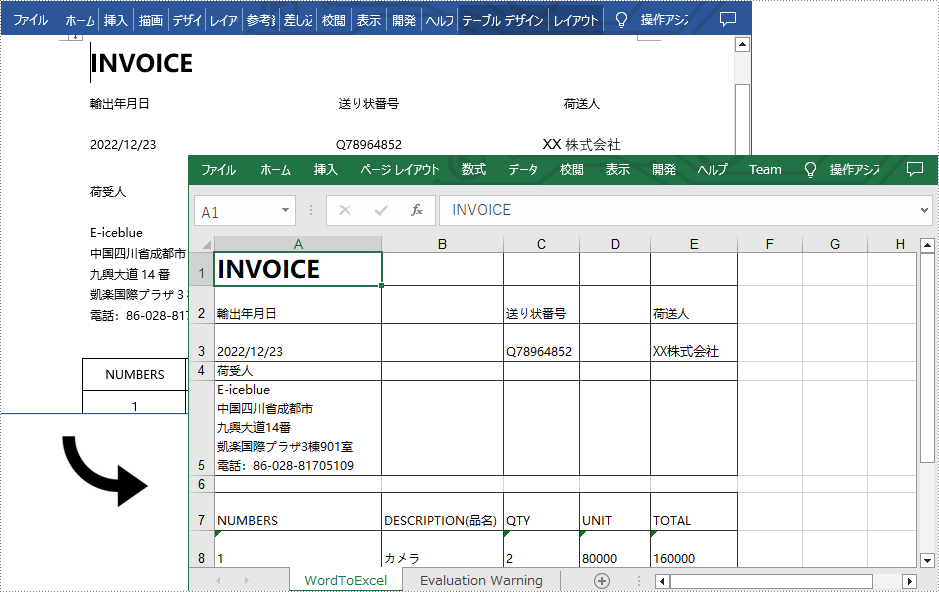
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
SVG は、XML ベースのスケーラブルなベクター グラフィック形式であり、グラフィックを記述するためのオープン スタンダードの構成言語です。 SVG は、CSS、DOM、JavaScript などの他の Web 標準とうまく連携するため、現在 Web ページ作成で非常に一般的です。 Excel ワークシートなどのオフィス ドキュメントを Web ページに追加して直接表示するのは非常に困難です。しかし、しかし、これらのドキュメントをSVG画像に変換することで、この難題を解決することができます。この記事では、Spire.XLS for Java を使用して Excel を SVG に変換する方法を紹介します。
まず、Spire. XLS for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>12.11.8</version>
</dependency>
</dependencies>Spire.XLS for Java が提供する Worksheet.toSVGStream() メソッドは、特定のワークシートを SVG に変換することをサポートします。以下に詳細な操作手順を示します。
import com.spire.xls.*;
import java.io.FileOutputStream;
import java.io.IOException;
public class ExcelToSVG {
public static void main(String[] args) throws IOException {
//Workbook クラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//ディスクからExcelドキュメントをロードする
workbook.loadFromFile("sample.xlsx");
//2つ目のワークシートを取得する
Worksheet sheet = workbook.getWorksheets().get(1);
//ワークシートをSVGに変換する
FileOutputStream stream = new FileOutputStream("sheet.svg");
sheet.toSVGStream(stream, sheet.getFirstRow(), sheet.getFirstColumn(), sheet.getLastRow(), sheet.getLastColumn());
stream.flush();
stream.close();
}
}
Spire.XLS for Java が提供する Worksheet.toSVGStream() メソッドは、すべてのワークシートを SVG に変換することをサポートします。以下に詳細な操作手順を示します。
import com.spire.xls.*;
import java.io.FileOutputStream;
import java.io.IOException;
public class ExcelToSVG {
public static void main(String[] args) throws IOException {
//Workbook クラスのオブジェクトを作成する
Workbook workbook = new Workbook();
//ディスクからExcelドキュメントをロードする
workbook.loadFromFile("sample.xlsx");
//ドキュメントをルーペして、ワークシートを取得する
for (int i = 0; i < workbook.getWorksheets().size(); i++)
{
FileOutputStream stream = new FileOutputStream("sheet"+i+".svg");
//ワークシートをSVGに変換する
Worksheet sheet = workbook.getWorksheets().get(i);
sheet.toSVGStream(stream, sheet.getFirstRow(), sheet.getFirstColumn(), sheet.getLastRow(), sheet.getLastColumn());
stream.flush();
stream.close();
}
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Office 7.12のリリースを発表できることを嬉しく思います。このバージョンでは、Spire.PDFはフォームドメインの可視と非表示プロパティの設定、カスタムメタデータの追加、PDFドキュメントのメタデータに新しい名前空間の追加をサポートしました。Spire.XLSは.NET 7.0をサポートしました。Spire.PresentationはPPTスライドを画像として保存した後にコンテンツが失われていた問題が修正されました。さらに、このバージョンでは、多くの既知の問題も修正しました。詳細は以下の内容を読んでください。
このバージョンでは、Spire.Doc,Spire.PDF,Spire.XLS,Spire.Email,Spire.DocViewer, Spire.PDFViewer,Spire.Presentation,Spire.Spreadsheet, Spire.OfficeViewer, Spire.DocViewer, Spire.Barcode, Spire.DataExportの最新バージョンが含まれています。
| カテゴリー | ID | 説明 |
| New feature | SPIREPDF-2352 | フォームドメインの可視と非表示プロパティの設定をサポートします。
Spire.Pdf.Fields.PdfField field = formWidget.FieldsWidget.List[0] as Spire.Pdf.Fields.PdfField; //field.AnnotationFlags = Spire.Pdf.Annotations.PdfAnnotationFlags.Default; // Setting visibility field.AnnotationFlags = Spire.Pdf.Annotations.PdfAnnotationFlags.Hidden; // Setting hidden |
| New feature | SPIREPDF-5495 | カスタムメタデータの追加をサポートします。
using(PdfDocument doc = new PdfDocument("1.pdf"))
{
using(Stream stream = new FileStream('1.xml',FileMode.Open))
{
doc.Metadata = PdfXmlMetadata.Parse(stream);
}
doc.SaveToFile('result.pdf');
} |
| New feature | SPIREPDF-5506 | PDFドキュメントのメタデータに新しい名前空間の追加をサポートします。
SPIREPDF-5506 PDFドキュメントのメタデータに新しい名前空間の追加をサポートします。
PdfXmlMetadata.RegisterNamespace("http://myRandomNamespace", "zf");
using(PdfDocument doc = new PdfDocument("1.pdf"))
{
doc.Metadata.SetPropertyString("http://myRandomNamespace", "test1","my test");
doc.SaveToFile('result.pdf');
}
PdfXmlMetadata.ResetNamespaces(); |
| Bug | SPIREPDF-5479 | プロパティoptions.IsShowHiddenText = falseを設定して隠しテキストを抽出しない問題が機能しなかった問題を修正します。 |
| Bug | SPIREPDF-5523 | PDFをdocxに変換した後の表の背景色が正しくない問題が修正されました。 |
| Bug | SPIREPDF-5597 | 特殊文字の置換に失敗した問題が修正されました。 |
| Bug | SPIREPDF-5615 | PDF-Xchangerエディタに選択したボタンが表示されない問題が修正されました。 |
| Bug | SPIREPDF-5623 | 透かしを描画した後にテキストを検索できなかった問題が修正されました。 |
| Bug | SPIREPDF-5644 | PDFを画像に変換する際にアプリケーションが「Object reference not set to an instance of an object.」をスローする問題が修正されました。 |
| カテゴリー | ID | 説明 |
| Bug | SPIREPPT-2109 | PPTスライドを画像として保存した後にコンテンツが失われていた問題が修正されました。 |
Spire.XLS 12.12.3のリリースを発表できることを嬉しく思います。このリリースは.NET 7.0をサポートしました。同時に、今回の更新では、ExcelからPDFとCSV、HTMLからExcelへの変換機能も強化されました。また、このリリースでは、Save()関数を呼び出して.et形式の文書を保存する場合のデータ保存に失敗するなど、既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREXLS-783 | ExcelをPDFに変換した後の枠線が正しくない問題が修正されました。 |
| Bug | SPIREXLS-4288 | Save()関数を呼び出して.et形式の文書を保存する場合のデータ保存に失敗する問題を修正しました。 |
| Bug | SPIREXLS-4297 | ExcelをCSVに変換した後、数式が計算されなかった問題が修正されました。 |
| Bug | SPIREXLS-4317 | SetActiveCell()関数を呼び出したときに選択されていたセルがアクティブになっていた問題が修正されました。 |
| Bug | SPIREXLS-4325 | ExcelをPDFに変換した後にA列のデータが失われていた問題が修正されました。 |
| Bug | SPIREXLS-4328 | CSVファイル内のデータをデータテーブルに変換する際のデータフォーマットが正しくない問題が修正されました。 |
| Bug | SPIREXLS-4330 | HTMLをExcelに変換した後に結果ファイルの中国語文字化けが修正されました。 |
| Bug | SPIREXLS-4332 | 指定したセル範囲を画像に連続的に変換する際に、アプリケーションが「System.NullReferenceException」をスローする問題が修正されました。 |
Word 文書におけるヘッダーとは、ページの上部に位置するテキストや画像のコンテンツのことで、フッターはページの下部に位置するものであるということです。 ヘッダーとフッターは、著作権、著者情報、ページ番号など、文書に関する重要な情報を表示するためによく使われます。また、文書をより専門的で美しいものにするために、文書を装飾するためにも使用されます。 ヘッダーとフッターは、文書の各ページまたは最初のページに挿入することができ、文書の奇数ページと偶数ページに異なるヘッダーとフッターを挿入することができます。 この記事では、Spire.Doc for Java を使用してプログラム的に Word 文書にヘッダーとフッターを挿入する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.12.4</version>
</dependency>
</dependencies>Word 文書にヘッダーとフッターを挿入するには、まず Section.getHeadersFooters().getHeader() と Section.getHeadersFooters().getFooter() メソッドを使用してヘッダーとフッターを取得しておく必要があります。 そして、それらに段落を追加します。 最後に段落に画像、テキスト、ページ番号などを追加します。
以下に、ヘッダーとフッターの挿入方法の詳細を示します。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.TextRange;
public class insertHeaderAndFooter1 {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("私たちは織り成す存在である.docx");
//ドキュメントの最初のセクションを取得する
Section section = document.getSections().get(0);
//カスタムのメソッドinsertHeaderAndFooter()を呼び出し、ヘッダーとフッターを挿入する
insertHeaderAndFooter(section);
//ドキュメントを保存する
document.saveToFile("ヘッダーとフッター.docx", FileFormat.Docx);
}
private static void insertHeaderAndFooter(Section section) {
//セクションからヘッダーとフッターを取得する
HeaderFooter header = section.getHeadersFooters().getHeader();
HeaderFooter footer = section.getHeadersFooters().getFooter();
//ヘッダーに段落を追加する
Paragraph headerParagraph = header.addParagraph();
//ヘッダーの段落にテキストを追加する
TextRange text = headerParagraph.appendText("哲学\r私たちは織り成す存在である");
text.getCharacterFormat().setFontName("Yu Gothic UI");
text.getCharacterFormat().setFontSize(10);
text.getCharacterFormat().setItalic(true);
headerParagraph.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//ヘッダー段落の下部線のスタイルを設定する
headerParagraph.getFormat().getBorders().getBottom().setBorderType(BorderStyle.Single);
headerParagraph.getFormat().getBorders().getBottom().setLineWidth(1f);
//フッターに段落を追加する
Paragraph footerParagraph = footer.addParagraph();
//フッター段落にField_PageとField_Num_Pagesフィールドを追加する
footerParagraph.appendField("ページ番号", FieldType.Field_Page);
footerParagraph.appendText(" / ");
footerParagraph.appendField("ページ数", FieldType.Field_Num_Pages);
footerParagraph.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//フッター段落の上部線のスタイルを設定する
footerParagraph.getFormat().getBorders().getTop().setBorderType(BorderStyle.Single);
footerParagraph.getFormat().getBorders().getTop().setLineWidth(1f);
}
}
最初のページにヘッダーとフッターを挿入するだけでよい場合もありますが、これも Spire.Doc for Java を使って行うことができます。 Section.getPageSetup().setDifferentFirstPageHeaderFooter() メソッドを使用して、最初のページのヘッダーとフッターを他のページと異なるものにし、最初のページにヘッダーとフッターを挿入することができます。
最初のページのみにヘッダーとフッターを挿入する詳しい手順は、以下の通りです。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextRange;
import java.awt.*;
public class insertHeaderAndFooter {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("私たちは織り成す存在である.docx");
//ドキュメントの最初のセクションを取得する
Section section = document.getSections().get(0);
//ドキュメントの最初のページのヘッダーとフッターを他のページと異なるように設定する
section.getPageSetup().setDifferentFirstPageHeaderFooter(true);
//カスタム insertHeaderAndFooterFirst() メソッドを呼び出して、最初のページにヘッダとフッタを挿入する
insertHeaderAndFooterFirst(section);
//ドキュメントを保存する
document.saveToFile("最初のページのヘッダーとフッター.docx", FileFormat.Docx);
}
private static void insertHeaderAndFooterFirst(Section section) {
//ドキュメントの最初のページのヘッダーとフッターを取得する
HeaderFooter header = section.getHeadersFooters().getFirstPageHeader();
HeaderFooter footer = section.getHeadersFooters().getFirstPageFooter();
//ヘッダーに段落を追加する
Paragraph headerParagraph = header.addParagraph();
//ヘッダーの段落にテキストを追加する
TextRange text = headerParagraph.appendText("哲学");
text.getCharacterFormat().setFontName("Yu Gothic UI");
text.getCharacterFormat().setFontSize(14);
text.getCharacterFormat().setTextColor(Color.blue);
text.getCharacterFormat().setItalic(true);
headerParagraph.getFormat().setHorizontalAlignment(HorizontalAlignment.Right);
//ヘッダー段落に画像を挿入し、その位置を設定する
DocPicture headerPicture = headerParagraph.appendPicture("ヘッダー.png");
headerPicture.setHorizontalAlignment(ShapeHorizontalAlignment.Left);
headerPicture.setVerticalAlignment(ShapeVerticalAlignment.Top);
//ヘッダー段落の下部線のスタイルを設定する
headerParagraph.getFormat().getBorders().getBottom().setBorderType(BorderStyle.Single);
headerParagraph.getFormat().getBorders().getBottom().setLineWidth(1f);
//画像の文字列の折り返しスタイルを背面に設定する
headerPicture.setTextWrappingStyle(TextWrappingStyle.Behind);
//フッターに段落を追加する
Paragraph footerParagraph = footer.addParagraph();
//フッター段落にテキストを追加する
TextRange text1 = footerParagraph.appendText("私たちは織り成す存在である");
text1.getCharacterFormat().setFontName("Yu Gothic UI");
text1.getCharacterFormat().setFontSize(14);
text1.getCharacterFormat().setTextColor(Color.blue);
text1.getCharacterFormat().setItalic(true);
footerParagraph.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
//フッター段落の上部線のスタイルを設定する
footerParagraph.getFormat().getBorders().getTop().setBorderType(BorderStyle.Single);
footerParagraph.getFormat().getBorders().getTop().setLineWidth(1f);
}
}
また、奇数ページと偶数ページで異なるヘッダーとフッターを挿入する必要がある状況に遭遇することがあります。Spire.Doc for Java では、これらのニーズに対応するために、奇数ページと偶数ページで異なるヘッダーとフッターを作成するメソッド、Section.getPageSetup().setDifferentOddAndEvenPagesHeaderFooter() が用意されています。
奇数ページと偶数ページで異なるヘッダーとフッターを挿入する詳しい手順は、以下のとおりです。
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.TextRange;
import java.awt.*;
public class insertHeaderAndFooter {
public static void main(String[] args) {
//Documentクラスのオブジェクトを作成する
Document document = new Document();
//Wordドキュメントを読み込む
document.loadFromFile("私たちは織り成す存在である.docx");
//ドキュメントの最初のセクションを取得する
Section section = document.getSections().get(0);
//奇数ページと偶数ページのヘッダーとフッターを異なるものに設定する
section.getPageSetup().setDifferentOddAndEvenPagesHeaderFooter(true);
//カスタム insertHeaderAndFooterOddEven() メソッドを呼び出し、奇数ページと偶数ページに異なるヘッダーとフッターを挿入する
insertHeaderAndFooterOddEven(section);
//ドキュメントを保存する
document.saveToFile("奇数ページと偶数ページのヘッダーとフッター.docx", FileFormat.Docx);
}
private static void insertHeaderAndFooterOddEven(Section section) {
//奇数ページにヘッダーを挿入する
Paragraph P1 = section.getHeadersFooters().getOddHeader().addParagraph();
TextRange OH = P1.appendText("奇数ページのヘッダー");
P1.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
OH.getCharacterFormat().setFontName("Yu Gothic UI");
OH.getCharacterFormat().setFontSize(16);
OH.getCharacterFormat().setTextColor(Color.BLUE);
P1.getFormat().getBorders().getBottom().setBorderType(BorderStyle.Single);
P1.getFormat().getBorders().getBottom().setLineWidth(1f);
//偶数ページにヘッダーを挿入
Paragraph P2 = section.getHeadersFooters().getEvenHeader().addParagraph();
TextRange EH = P2.appendText("偶数ページのヘッダー");
P2.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
EH.getCharacterFormat().setFontName("Yu Gothic UI");
EH.getCharacterFormat().setFontSize(16);
EH.getCharacterFormat().setTextColor(Color.BLUE);
P2.getFormat().getBorders().getBottom().setBorderType(BorderStyle.Single);
P2.getFormat().getBorders().getBottom().setLineWidth(1f);
//奇数ページにフッターを挿入
Paragraph P3 = section.getHeadersFooters().getOddFooter().addParagraph();
TextRange OF = P3.appendText("奇数ページのフッター");
P3.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
OF.getCharacterFormat().setFontName("Yu Gothic UI");
OF.getCharacterFormat().setFontSize(16);
OF.getCharacterFormat().setTextColor(Color.BLUE);
P3.getFormat().getBorders().getTop().setBorderType(BorderStyle.Single);
P3.getFormat().getBorders().getTop().setLineWidth(1f);
//偶数ページにフッターを挿入する
Paragraph P4 = section.getHeadersFooters().getEvenFooter().addParagraph();
TextRange EF = P4.appendText("偶数ページのフッター");
EF.getCharacterFormat().setFontName("Yu Gothic UI");
EF.getCharacterFormat().setFontSize(16);
P4.getFormat().setHorizontalAlignment(HorizontalAlignment.Center);
EF.getCharacterFormat().setTextColor(Color.BLUE);
P4.getFormat().getBorders().getTop().setBorderType(BorderStyle.Single);
P4.getFormat().getBorders().getTop().setLineWidth(1f);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
下付き文字と上付き文字は、どちらも文字列の中で他の文字の後に表示される記号です。上付き文字は通常の文字の基線より上に表示され、下付き文字は文字の基線より下に表示されます。Microsoft Word で上付き文字や下付き文字を挿入する必要がある場合があります。例えば、科学的な数式を含む学術的な文書を作成する場合などです。この記事では、Spire.Doc for Java ライブラリを使用して、Java で Word 文書に上付き文字と下付き文字を挿入する方法について説明します。
まず、Spire. Doc for Java を Java プロジェクトに追加する必要があります。JAR ファイルは、このリンクからダウンロードできます。Maven を使用する場合は、次のコードをプロジェクトの pom.xml ファイルに追加する必要があります。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url> https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>10.12.4</version>
</dependency>
</dependencies>Spire.Doc for Java では、テキストに上付き文字や下付き文字を適用するための TextRange.getCharacterFormat().setSubSuperScript() メソッドを用意しています。
上付き文字と下付き文字の挿入の詳細な手順は以下の通りです。
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.Section;
import com.spire.doc.documents.BreakType;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.documents.SubSuperScript;
import com.spire.doc.fields.TextRange;
public class insertSuperscriptAndSubscript {
public static void main(String[] args){
//Documentクラスのインスタンスを作成する
Document document = new Document();
//Word文書の読み込み
document.loadFromFile("サンプル.docx");
//1つ目のセクションを取得する
Section section = document.getSections().get(0);
//セクションに段落を追加する
Paragraph paragraph = section.addParagraph();
//段落に通常のテキストを追加する
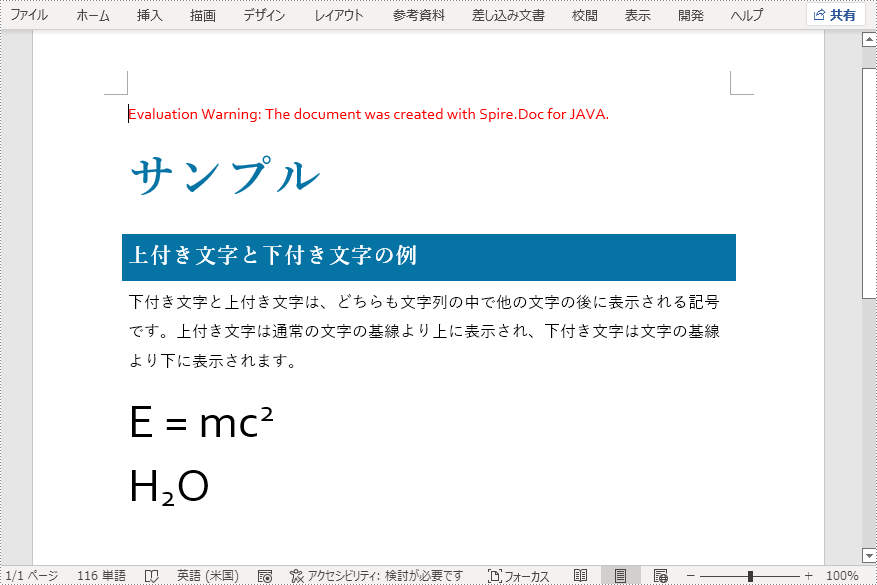
paragraph.appendText("E = mc");
//上付き文字を適用するテキストを段落に追加する
TextRange superscriptText = paragraph.appendText("2");
//テキストに上付き文字書式を適用する
superscriptText.getCharacterFormat().setSubSuperScript(SubSuperScript.Super_Script);
//新しい行を開始する
paragraph.appendBreak(BreakType.Line_Break);
//段落に通常のテキストを追加する
paragraph.appendText("H");
//下付き文字を適用するテキストを段落に追加する
TextRange subscriptText = paragraph.appendText("2");
//テキストに下付き文字書式を適用する
subscriptText.getCharacterFormat().setSubSuperScript(SubSuperScript.Sub_Script);
//段落に通常のテキストを追加する
paragraph.appendText("O");
//段落内のテキストの文字サイズを設定する
for(Object item : paragraph.getItems())
{
if (item instanceof TextRange)
{
TextRange textRange = (TextRange)item ;
textRange.getCharacterFormat().setFontSize(36f);
}
}
//結果文書を保存する
document.saveToFile("上付き文字と下付き文字.docx", FileFormat.Docx_2013);
}
}
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。
Spire.Presentation 7.12.1 のリリースを発表できることをうれしく思います。このリリースでは、PPTスライドを画像として保存した後にコンテンツが失われていた問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| Bug | SPIREPPT-2109 | PPTスライドを画像として保存した後にコンテンツが失われていた問題が修正されました。 |
Spire.PDF for Java 8.12.6のリリースを発表できることをうれしく思います。このバージョンでは、ラベルPDFファイルの作成がサポートされました。この更新には、パフォーマンスの最適化も含まれています。例えば、画像の抽出にかかる時間と、ドキュメント画像を圧縮する際のメモリ消費の問題を最適化しました。また、このバージョンでは多くの既知の問題が修正されました。詳細は以下の内容を読んでください。
| カテゴリー | ID | 説明 |
| New feature | - | ラベルPDFファイルの作成がサポートされました。
//Create a pdf document
PdfDocument doc = new PdfDocument();
//Add page
doc.getPages().add();
//Set tab order
doc.getPages().get(0).setTabOrder(TabOrder.Structure);
//Create PdfTaggedContent
PdfTaggedContent taggedContent = new PdfTaggedContent(doc);
taggedContent.setLanguage("en-US");
taggedContent.setTitle("test");
//Set font
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Times New Roman",Font.PLAIN,12), true);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.black));
//Append elements
PdfStructureElement article = taggedContent.getStructureTreeRoot().appendChildElement(PdfStandardStructTypes.Document);
PdfStructureElement paragraph1 = article.appendChildElement(PdfStandardStructTypes.Paragraph);
PdfStructureElement span1 = paragraph1.appendChildElement(PdfStandardStructTypes.Span);
span1.beginMarkedContent(doc.getPages().get(0));
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Justify);
doc.getPages().get(0).getCanvas().drawString("Spire.PDF for .NET is a professional PDF API applied to creating, writing, editing, handling and reading PDF files.",
font, brush, new Rectangle(40, 0, 480, 80), format);
span1.endMarkedContent(doc.getPages().get(0));
PdfStructureElement paragraph2 = article.appendChildElement(PdfStandardStructTypes.Paragraph);
paragraph2.beginMarkedContent(doc.getPages().get(0));
doc.getPages().get(0).getCanvas().drawString("Spire.PDF for .NET can be applied to easily convert Text, Image, SVG, HTML to PDF and convert PDF to Excel with C#/VB.NET in high quality.",
font, brush, new Rectangle(40, 80, 480, 60), format);
paragraph2.endMarkedContent(doc.getPages().get(0));
PdfStructureElement figure1 = article.appendChildElement(PdfStandardStructTypes.Figure);
//Set Alternate text
figure1.setAlt("replacement text1");
figure1.beginMarkedContent(doc.getPages().get(0), null);
PdfImage image = PdfImage.fromFile("E-logo.png");
Dimension2D dimension2D = new Dimension();
dimension2D.setSize( 100,100);
doc.getPages().get(0).getCanvas().drawImage(image, new Point2D.Float(40, 200),dimension2D);
figure1.endMarkedContent(doc.getPages().get(0));
PdfStructureElement figure2 = article.appendChildElement(PdfStandardStructTypes.Figure);
//Set Alternate text
figure2.setAlt( "replacement text2");
figure2.beginMarkedContent(doc.getPages().get(0), null);
doc.getPages().get(0).getCanvas().drawRectangle(PdfPens.getBlack(), new Rectangle(300, 200, 100, 100));
figure2.endMarkedContent(doc.getPages().get(0));
//Save to file
String result = "CreateTaggedFile_result.pdf";
doc.saveToFile(result);
doc.close(); |
| Bug | SPIREPDF-4806 | 抽出画像の時間がかかる問題を最適化しました。 |
| Bug | SPIREPDF-4856 | ドキュメント画像を圧縮する際のメモリ消費の問題を最適化しました。 |
| Bug | SPIREPDF-4860 SPIREPDF-5583 |
PDFのロード時にアプリケーションが長時間ハングアップしていた問題が修正されました。 |
| Bug | SPIREPDF-4955 | PDF文書の圧縮に時間がかかる問題を最適化しました。 |
| Bug | SPIREPDF-5496 | PDFをExcelに変換するためにCustomFontsFoldersを定義する際に、アプリケーションが「TimesNewRomanのフォントが見つかりません」をスローする問題が修正されました。 |
| Bug | SPIREPDF-5622 | PdfGridを使用して表を描画する際に、枠線の太さが異なる問題が修正されました。 |
| Bug | SPIREPDF-5641 | 異なる場所で描画すると、グリッドセルの内容が正しく表示されない問題を修正しました。 |
| Bug | SPIREPDF-5646 | PDFをマージすると、アプリケーションが「Unexpected token Unknown before 105」をスローする問題が修正されました。 |





