
PDF ファイルには、グラフ、図、スキャン画像などの重要なビジュアル情報が含まれていることが多くあります。
開発者にとって、PythonでPDFから画像を抽出する方法を知っておくことは、レポートの自動生成や画像解析、OCR などの機械学習タスクにおいて非常に有用です。
この記事では、Spire.PDF for Python を利用して、Python で PDF から画像を抽出する方法を次の観点から詳しく紹介します。
インストールと環境設定
Python で Spire.PDF を使用して PDF から画像を抽出する前に、以下の準備を行ってください。
Python 環境:システムに Python がインストールされていることを確認します。
最新の安定版を使用することで、より良い互換性とパフォーマンスが得られます。
Python公式サイト からダウンロード可能です。Spire.PDF for Python ライブラリ:
Python 用の PDF SDK をインストールします。pip を使うのが最も簡単です。
コマンドプロンプトまたはターミナルで以下を実行します:
pip install Spire.PDF
PythonでPDFから画像を抽出する方法
Spire.PDF をインストールしたら、すぐに PDF ドキュメントから画像を抽出できるようになります。 以下の例では、ページ単位および全ページから画像を抽出する方法を順に紹介します。
例1:PDFの特定ページから画像を抽出する
次のコードは、PDF の特定ページに含まれるすべての画像を抽出して保存する完全なスクリプトです。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
pdf = PdfDocument()
# PDFファイルを読み込む
pdf.LoadFromFile("template1.pdf")
# 最初のページを取得
page = pdf.Pages[0]
# PdfImageHelper インスタンスを作成
imageHelper = PdfImageHelper()
# ページ上の画像情報を取得
imageInfo = imageHelper.GetImagesInfo(page)
# 取得した画像情報をループ処理して保存
for i in range(0, len(imageInfo)):
imageInfo[i].Image.Save("Images/Image" + str(i) + ".png")
# リソースを解放
pdf.Dispose()
ポイント解説:
- PDFを読み込む:LoadFromFile() メソッドを使ってファイルをロードします。
- ページを取得:インデックスを指定して特定ページを取得します。
- 画像情報を抽出: PdfImageHelper を使い、GetImagesInfo() メソッドでページ内の画像情報(PdfImageInfo オブジェクト)をリストとして取得します。
- 画像を保存:ループ処理で各画像を順に保存します。
出力例プレビュー:
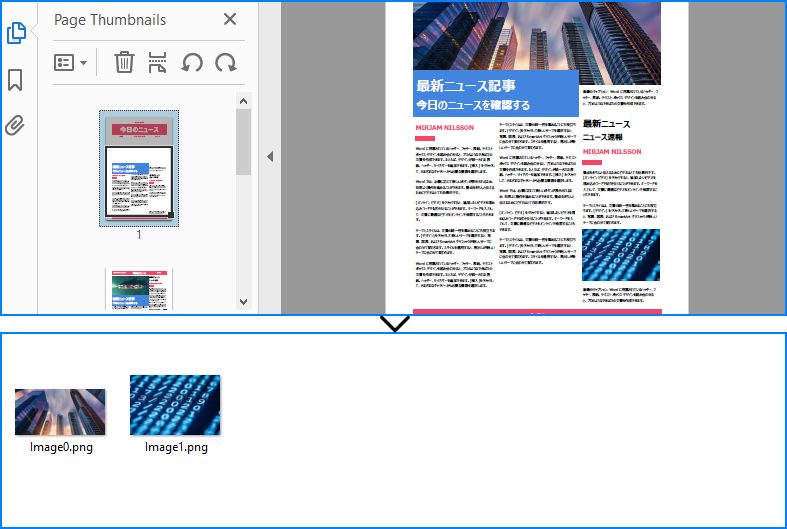
例2:PDF全体からすべての画像を抽出する
単一ページからの抽出を拡張し、すべてのページをループして全画像を抽出することも可能です。 以下のスクリプトでは、PDF 全体からすべての埋め込み画像を取得します。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
pdf = PdfDocument()
# PDFファイルを読み込む
pdf.LoadFromFile("template1.pdf")
# PdfImageHelper インスタンスを作成
imageHelper = PdfImageHelper()
# すべてのページをループ
for i in range(0, pdf.Pages.Count):
page = pdf.Pages[i]
imageInfo = imageHelper.GetImagesInfo(page)
for j in range(0, len(imageInfo)):
imageInfo[j].Image.Save(f"Images\\Page{i + 1}_Image{j + 1}.png")
# PDFを閉じる
pdf.Close()
出力例プレビュー:
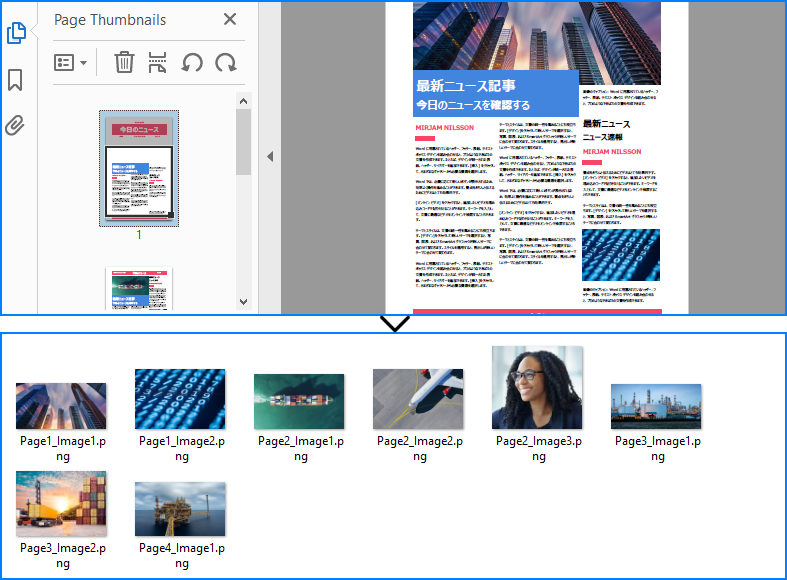
PDF内の画像をさらに操作したい場合は、PythonでPDFに画像を追加・置換・削除する方法の記事も参考にしてください。
抽出時に異なる画像形式を扱う方法
Spire.PDF for Python は、PNG、JPG/JPEG、BMP などさまざまな画像形式の抽出をサポートしています。 抽出した画像を保存する際、用途に合わせて最適なフォーマットを選択することができます。
主な画像形式と特徴:
| 形式 | 主な用途 | 備考 |
|---|---|---|
| JPG/JPEG | 写真・スキャン画像 | 圧縮で若干の劣化あり。PDFで最も一般的。 |
| PNG | 図表・スクリーンショット | 透過保持。ファイルサイズはやや大きめ。 |
| BMP | 一時保存やWindowsアプリ用 | 現在のPDFではまれ。Web用途には不向き。 |
| TIFF | 保存・印刷・OCR入力 | アーカイブや文書保存向け。複数ページ対応。 |
| EMF | ベクター画像編集 | IllustratorやInkscapeで編集可能。 |
よくある質問(FAQ)
Q1:Spire.PDF for Python は無料ですか?
Spire.PDF for Python には無料版と商用版があります。 Free Spire.PDF for Python は、1ファイルあたり最大10ページなどの制限があります。 制限のない試用版ライセンスを希望する場合は、こちらから申請してください。
Q2:特定のページ範囲だけから画像を抽出できますか?
可能です。全ページをループする代わりに、抽出したいページのインデックスを指定します。 例えば 2~5 ページの画像を抽出するには次のように書きます。
# ページ2~5の画像を抽出(ページは0始まり)
for i in range(1, 4):
page = pdf.Pages[i]
# 上記と同じ処理を実行
Q3:抽出した画像からテキストを取り出すことはできますか?
はい。スキャンPDFのように画像内に文字が含まれている場合は、Spire.OCR for Python を組み合わせることで、抽出画像から文字認識を行うことができます。
まとめ
PythonでPDFから画像を抽出する作業は、Spire.PDF for Python を使うことで簡単かつ効率的に実現できます。 この記事で紹介したサンプルコードを活用すれば、特定ページや全ページから画像を抽出し、任意の形式で保存することが可能です。 さらに、OCRツールと組み合わせることで、画像からテキストを自動的に抽出することもできます。
この機能を活用すれば、レポート作成や画像解析などの業務効率を大幅に向上させ、PDFに埋め込まれたビジュアルデータを柔軟に再利用できます。





