
Java での PDF 解析は、PDFを単に画面表示するだけでなく、内部に含まれる情報をプログラムで抽出・活用したい場合によく必要とされます。代表的なユースケースとしては、ドキュメントのインデックス化、自動レポート処理、請求書分析、データ取り込みパイプラインなどが挙げられます。
JSON や XML のような構造化データ形式とは異なり、PDF は見た目の正確な再現(ビジュアル忠実度)を目的として設計されています。そのため、テキスト・表・画像といった要素は、論理構造としてではなく、描画位置を指定する命令の集合として格納されています。
このような特性から、Java で PDF を解析する際には、PDF内部のコンテンツ表現を理解し、それを Java ライブラリがどのように API として提供しているかを把握することが重要になります。
本記事では、Spire.PDF for Java を使用し、実際の Java アプリケーションで役立つ PDF 解析処理を実践的に解説します。PDF 解析を一連の単一フローとして扱うのではなく、テキスト・表・画像・メタデータといった目的別の抽出タスクごとに説明していきます。
目次
- 実装視点で理解する PDF 解析
- Java における実践的な PDF 解析ワークフロー
- Java で PDF ドキュメントを読み込み・検証する
- Java で PDF ページからテキストを解析する
- Java で PDF ページから表を解析する
- Java で PDF ページから画像を解析する
- Java で PDF メタデータを解析する
- Java で PDF 解析を実装する際の考慮点
- JavaでのPDF解析に関するよくある質問
実装視点で理解する PDF 解析
実装の観点から見ると、Java での PDF 解析は単一の処理ではなく、同一ドキュメントに対して実行される複数の抽出タスクの集合です。アプリケーションが必要とするデータの種類に応じて、実行すべき解析処理が決まります。
実際のシステムにおいて、PDF 解析は主に以下の情報を取得する目的で使用されます。
- プレーンテキスト(検索、インデックス、分析用)
- 表などの構造化データ(後続処理やデータ保存用)
- 画像などの埋め込みリソース(アーカイブや後処理用)
- ドキュメントメタデータ(分類、監査、バージョン管理用)
PDF 解析が複雑になる最大の理由は、PDF が論理構造を保持しない形式であることにあります。段落、行、表といった構造は明示的には保存されず、主に以下の要素として表現されています。
- ページ単位のコンテンツストリーム
- 座標情報を持つ文字断片
- 罫線、余白、画像など、視覚的に構造を示すグラフィック要素
そのため、Java での PDF 解析は、あらかじめ定義されたデータ構造を読み取るのではなく、レイアウト情報から意味を再構築する処理になります。
このような理由から、実用的な Java 実装では、低レベルなページコンテンツへアクセスできるだけでなく、テキスト抽出や表検出といった高レベル機能も提供する専用 PDF 解析ライブラリを利用するのが一般的です。これにより、独自ロジックの実装量を大幅に削減できます。
Java における実践的な PDF 解析ワークフロー
本番環境では、PDF 解析を厳密なステップ型パイプラインとして設計するよりも、必要に応じて個別に適用可能な独立した解析処理の集合として設計する方が適しています。
この設計により、障害の切り分けが容易になり、アプリケーションは本当に必要な解析処理だけを選択的に実行できます。
ここでは、テキスト抽出、表検出、画像エクスポート、メタデータ取得などの API を提供する Java PDF ライブラリ Spire.PDF for Java を使用します。バックエンドサービス、バッチ処理、ドキュメント自動化システムなどに適しています。
Spire.PDF for Java のインストール
ライブラリは Spire.PDF for Java ダウンロードページ から取得し、手動でプロジェクトに追加できます。
Maven を使用している場合は、以下の依存関係を追加することで簡単に導入できます。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
インストール後は、外部ツールに依存せず、Java コードだけで PDF ドキュメントの読み込み・解析が可能になります。
Java で PDF ドキュメントを読み込み・検証する
解析処理を行う前に、まず PDF ドキュメントを読み込み、安全に処理できるかどうかを検証する必要があります。このステップは、後続の解析ロジックとは独立した処理として扱うのが望ましいです。
import com.spire.pdf.PdfDocument;
public class loadPDF {
public static void main(String[] args) {
// PdfDocument インスタンスを作成
PdfDocument pdf = new PdfDocument();
// PDF ファイルを読み込み
pdf.loadFromFile("sample.pdf");
// ページ数を取得
int pageCount = pdf.getPages().getCount();
System.out.println("総ページ数: " + pageCount);
}
}
コンソール出力例
実装上、この段階で以下の重要な点が確認できます。
- サポートされている PDF 形式であること
- ドキュメント構造が致命的なエラーなく解析できること
- ページツリーが正しく存在し、アクセス可能であること
本番システムでは、この検証処理がゲートキーパーとして機能し、読み込みに失敗した PDF は早期に除外されます。
ドキュメント検証と抽出ロジックを分離することで、特にバッチ処理や自動解析フローにおいて、障害の連鎖を防ぐことができます。
Java で PDF ページからテキストを解析する
テキスト解析は、Java における PDF 処理で最も一般的なタスクの一つです。PDF ページから可読なテキストを抽出・再構成する処理を指します。
Spire.PDF for Java では、単一の高レベル API に頼るのではなく、PdfTextExtractor クラスと PdfTextExtractOptions を組み合わせて実装することで、柔軟かつ制御しやすいテキスト抽出が可能です。
テキスト解析を独立した処理として設計することで、インデックス作成、分析、コンテンツ移行など、必要なタイミングで自由に利用できます。
Java におけるテキスト解析の仕組み
一般的な Java 実装では、テキスト解析は以下の明確なステップで構成されます。
- PdfDocument に PDF を読み込む
- PdfTextExtractOptions で抽出挙動を設定する
- 各ページに対して PdfTextExtractor を作成する
- ページ単位でテキストを解析・収集する
このページ単位の設計は、PDF の内部構造と自然に対応しており、複数ページの処理でも高い制御性を提供します。
Java サンプル:PDF からテキストを抽出する
以下は、Spire.PDF for Java の PdfTextExtractor と PdfTextExtractOptions を使用して、PDF ファイルからテキストを抽出する例です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
public class extractPdfText {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// 抽出結果を効率的に保持するため StringBuilder を使用
StringBuilder extractedText = new StringBuilder();
// テキスト抽出オプションを設定
PdfTextExtractOptions options = new PdfTextExtractOptions();
// シンプル抽出モードを有効化(可読性向上)
options.setSimpleExtraction(true);
// 各ページを順に処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// ページごとに PdfTextExtractor を作成
PdfTextExtractor extractor =
new PdfTextExtractor(pdf.getPages().get(i));
// オプションを指定してテキストを抽出
String pageText = extractor.extract(options);
extractedText.append(pageText).append("\n");
}
System.out.println(extractedText.toString());
}
}
コンソール出力例
テキスト解析における重要ポイント
PdfTextExtractor ページ単位で動作し、テキスト再構成を細かく制御できます。
PdfTextExtractOptions 抽出挙動を調整可能です。setSimpleExtraction(true) を有効にすると、レイアウト処理を簡略化し、読みやすいテキストが得られます。
ページ単位処理 大容量 PDF への対応や、問題のあるページの切り分けが容易になります。
技術的な注意点
- テキストは段落ではなく、座標付きグリフから再構成されます
- 抽出挙動は PdfTextExtractOptions で調整可能です
- ページ単位の解析は耐障害性と柔軟性を向上させます
- 抽出後のテキストは、後続システム向けに正規化が必要な場合があります
この方法は、レポート、契約書など、比較的レイアウトが安定したテキスト中心の PDF に適しており、Spire.PDF for Java を使用した Java での PDF テキスト解析として推奨されるアプローチです。 その他のテキスト抽出の例については、「Javaを使用してPDFページからテキストを抽出する方法」を参照してください。
Java で PDF ページから表を解析する
**表解析(テーブル抽出)**は、PDF 内の表構造を検出し、行と列を持つ構造化データとして再構築する高度な解析処理です。単純なテキスト抽出と異なり、セル間の意味的な関係を保持できるため、請求書、財務諸表、業務レポートなどで広く利用されます。
Java で PDF を解析する際、表解析を行うことで、視覚的に整列された情報をプログラムで扱いやすい構造化データへ変換できます。
Java における表解析の実装イメージ
表解析では、単純なテキスト抽出から、視覚的な配置とレイアウトの一貫性に基づく構造推定へと処理の焦点が移ります。
- PdfDocument に PDF を読み込む
- ドキュメントに紐づく PdfTableExtractor を作成
- 特定ページから表構造を解析
- 行・列を再構築
- 抽出されたセルデータを検証・正規化
表解析は、テキストの位置関係をもとに構造を推定するため、行・列インデックスを用いたセル単位のアクセスが可能になります。
Java サンプル:PDF ページから表を抽出する
以下は、Spire.PDF for Java の PdfTableExtractor を使用して PDF ページから表を解析する例です。抽出された表は、行と列を持つ構造化データとして扱えます。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
public class extractPdfTable {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 表抽出器を作成
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// 1 ページ目から表を解析(インデックスは 0 から)
PdfTable[] tables = extractor.extractTable(0);
if (tables != null) {
for (PdfTable table : tables) {
int rowCount = table.getRowCount();
int columnCount = table.getColumnCount();
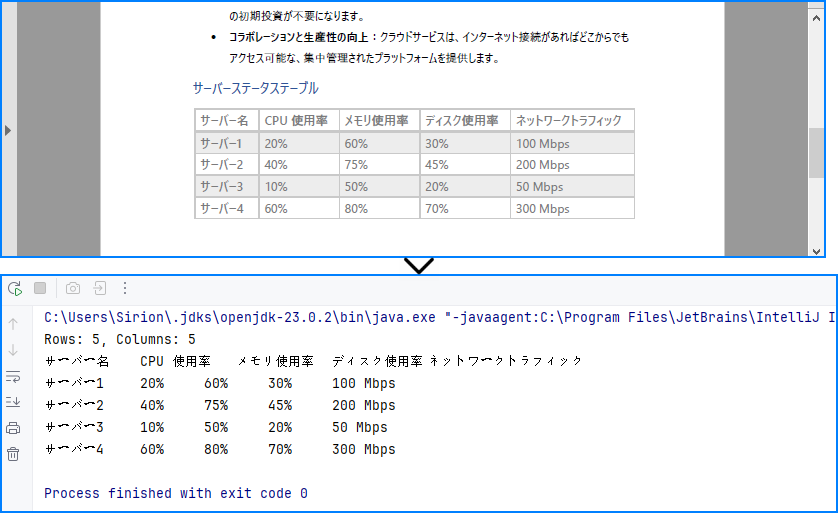
System.out.println("Rows: " + rowCount +
", Columns: " + columnCount);
StringBuilder tableData = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
tableData.append(table.getText(i, j));
if (j < columnCount - 1) {
tableData.append("\t");
}
}
if (i < rowCount - 1) {
tableData.append("\n");
}
}
System.out.println(tableData.toString());
}
}
}
}
コンソール出力例
表解析における実装上のポイント
PdfTableExtractor ページコンテンツを解析し、視覚的な配置情報から表領域を検出します。
構造の再構築 テキスト要素の相対位置に基づいて行・列を推定し、セル単位でのアクセスを可能にします。
ページ単位解析 ページごとのレイアウト差異に対応しやすく、精度向上につながります。
PDF 表解析時の注意点
- 表の境界は視覚的レイアウトから推定されます
- 見出し行は追加処理が必要な場合があります
- セル内容は保存・出力前に正規化が必要なことがあります
- 複雑または不統一なレイアウトでは精度が低下する可能性があります
制約はあるものの、表解析は Java における PDF 解析機能の中でも特に価値が高く、業務文書からのデータ自動抽出において重要な役割を果たします。
PDFページから表構造を解析した後、抽出されたデータは「JavaでPDF表をCSVに変換する」で示されているように、さらなる利用のためにCSVなどの構造化形式へエクスポートされることが多い。
Java で PDF ページから画像を解析する
画像解析(画像抽出)は、PDF ページ内に埋め込まれている画像リソースを抽出することに特化した PDF 解析機能です。テキストや表の解析がコンテンツストリームやレイアウト推定に基づくのに対し、画像解析はページレベルのリソース情報を解析し、画像オブジェクトを直接取得します。
Java ベースの PDF 処理システムでは、画像解析は以下のような用途でよく利用されます。
- 視覚コンテンツのアーカイブ
- ドキュメント構成の監査
- 画像データを後続の処理パイプラインへ連携
Java における画像解析の仕組み
実装レベルでは、画像解析はテキスト解析とは異なり、ページのリソース情報を対象として処理が行われます。
- PdfDocument に PDF を読み込む
- PdfImageHelper ユーティリティを初期化する
- 各ページを走査し、画像リソース情報を取得する
- 埋め込まれた画像を解析し、標準的な画像形式として保存する
画像はページの独立したリソースとして管理されているため、この処理はテキストフローやレイアウト再構築、表検出のロジックに依存しません。
Java サンプル:PDF ページから画像を抽出する
以下の例では、Spire.PDF for Java の PdfImageHelper と PdfImageInfo を使用して、PDF ページに埋め込まれた画像を抽出し、PNG ファイルとして保存します。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class extractPdfImages {
public static void main(String[] args) throws IOException {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// PdfImageHelper を作成
PdfImageHelper imageHelper = new PdfImageHelper();
// 各ページを順に処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 現在のページに含まれる画像情報を取得
PdfImageInfo[] imageInfos =
imageHelper.getImagesInfo(pdf.getPages().get(i));
if (imageInfos != null) {
for (int j = 0; j < imageInfos.length; j++) {
// BufferedImage として画像を取得
BufferedImage image = imageInfos[j].getImage();
// 画像を PNG ファイルとして保存
File output = new File(
"output/images/page_" + i + "_image_" + j + ".png"
);
ImageIO.write(image, "PNG", output);
}
}
}
}
}
抽出された画像の例
画像解析における重要ポイント
PdfImageHelper / PdfImageInfo ページレベルのリソースを解析し、埋め込まれた画像を BufferedImage として取得できます。
ページ単位の解析 複数ページ PDF や、同一画像が再利用されている場合でも正確に抽出できます。
レイアウト非依存 テキスト配置や表構造に依存しないため、あらゆるビジュアル要素の抽出に適しています。
PDF 画像解析時の注意点
- 装飾用や背景用の画像も抽出される場合があります
- 解像度・カラースペース・画像形式は PDF ごとに異なります
- 大規模 PDF では画像数が多くなるため、メモリ・保存容量管理が必要です
- 画像解析は、テキスト・表・メタデータ解析を補完する役割を果たします
個別画像の抽出だけでなく、PDF ページ全体を画像として変換することも可能です。詳細は Java で PDF ページを画像に変換する方法 を参照してください。
Java で PDF メタデータを解析する
メタデータ解析は、PDF の視覚コンテンツとは独立して保存されているドキュメントレベル情報を取得する基本的な PDF 解析機能です。ページレイアウトに依存しないため、ほぼすべての PDF に対して安定して適用できます。
Java ベースの PDF 処理システムでは、メタデータ解析は以下の目的で利用されることが多くあります。
- ドキュメントの分類
- 処理フローの振り分け
- インデックス作成
Java におけるメタデータ解析の仕組み
メタデータ解析は、ページ単位の解析とは異なり、ドキュメント全体に対する処理として実装されます。
- PdfDocument に PDF を読み込む
- ドキュメント情報ディクショナリへアクセスする
- 利用可能なメタデータ項目を取得する
- 分類・ルーティング・インデックス処理に活用する
メタデータはレンダリング内容とは独立して保存されているため、高速かつ一貫性のある解析処理が可能です。
Java サンプル:PDF ドキュメントのメタデータを取得する
以下の例では、Spire.PDF for Java を使用して、一般的な PDF メタデータ項目を取得します。これらの情報は、検索・分類・ワークフロー制御などに利用できます。
import com.spire.pdf.PdfDocument;
public class ParsePdfMetadata {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// ドキュメントメタデータを取得
String title = pdf.getDocumentInformation().getTitle();
String author = pdf.getDocumentInformation().getAuthor();
String subject = pdf.getDocumentInformation().getSubject();
String keywords = pdf.getDocumentInformation().getKeywords();
String creator = pdf.getDocumentInformation().getCreator();
String producer = pdf.getDocumentInformation().getProducer();
String creationDate = pdf.getDocumentInformation()
.getCreationDate().toString();
String modificationDate = pdf.getDocumentInformation()
.getModificationDate().toString();
System.out.println(
"Title: " + title +
"\nAuthor: " + author +
"\nSubject: " + subject +
"\nKeywords: " + keywords +
"\nCreator: " + creator +
"\nProducer: " + producer +
"\nCreation Date: " + creationDate +
"\nModification Date: " + modificationDate
);
}
}
コンソール出力例
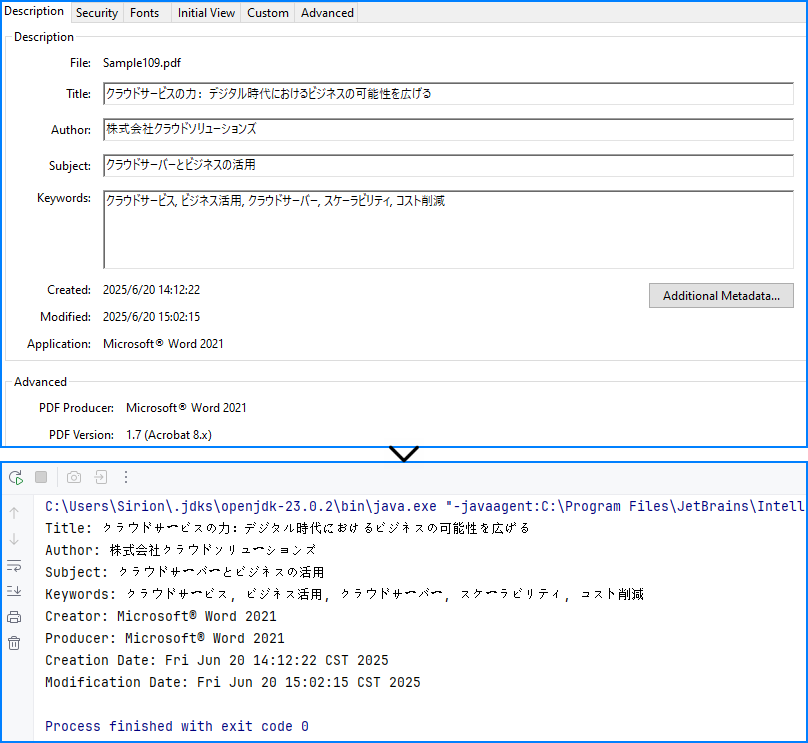
メタデータ解析の実装ポイント
ドキュメント情報ディクショナリ メタデータは専用の構造に保存されており、ページ描画内容とは独立しています。
項目の有無に注意 すべての PDF に完全なメタデータが含まれているとは限らず、null や空文字になる場合があります。
低い処理コスト ページ走査が不要なため、高速な前処理として適しています。
メタデータ解析の主な用途
- ドキュメントの分類・タグ付け
- 検索インデックス・フィルタリング
- ワークフロー制御・アクセス管理
- バージョン管理・監査ログ
メタデータ解析は、視覚レイアウトに依存しないため、複雑な PDF においても比較的安定した結果が得られます。
Java で PDF 解析を実装する際の考慮点
個々の解析処理は独立して実装できますが、実際の Java アプリケーションでは、複数の PDF 解析機能を組み合わせて同一パイプライン内で使用するケースが一般的です。
複数解析処理の組み合わせ
代表的な実装パターンには以下があります。
- テキスト解析で検索用インデックスを作成し、表解析で構造化データを保存
- メタデータ解析の結果を用いて処理フローを分岐
- 非同期処理やバッチジョブとして解析を実行
テキスト・表・画像・メタデータ解析を独立かつ組み合わせ可能な処理として設計することで、拡張性・テスト容易性・保守性が向上します。
実用上の制約と注意点
高機能な Java PDF パーサーを使用しても、以下の制約は避けられません。
- スキャン PDF は OCR 処理が必要
- 極端に複雑、または不統一なレイアウトは精度低下の原因となる
- カスタムフォントや特殊エンコーディングはテキスト再構成に影響する
これらの制約を理解したうえで解析戦略を設計することで、本番環境での例外処理やエラー対応を簡素化できます。
まとめ
Java での PDF 解析は、単一の線形処理としてではなく、目的別に分離された抽出処理の集合として設計することで、最も効果を発揮します。テキスト抽出、表解析、画像取得、メタデータアクセスをそれぞれ独立した関心事として扱うことで、PDF ドキュメントを安定して実用データへ変換できます。
Spire.PDF for Java のような専用 PDF 解析ライブラリを活用することで、実運用に耐える、拡張性の高い Java ベースの PDF 処理システムを構築できます。
Spire.PDF for Java を使用した PDF 解析の可能性を最大限に引き出すには、無料トライアルライセンスの申請 をご利用ください。
JavaでのPDF解析に関するよくある質問
Q1:JavaでPDFページからテキストを解析するには?
A1: Spire.PDF for Java の PdfTextExtractor と PdfTextExtractOptions を使用することで、ページ単位のテキストを効率的に抽出できます。検索、分析、データ移行など、柔軟な用途に対応できます。
Q2:JavaでPDF内の表を抽出する方法は?
A2: PdfTableExtractor を使用すると、表領域を検出し、行・列構造を再構築できます。抽出結果は構造化データとして保存・変換・エクスポート可能です。
Q3:JavaでPDFから画像を抽出できますか?
A3: はい。PdfImageHelper と PdfImageInfo を使用することで、各ページに埋め込まれた画像を抽出し、ファイルとして保存できます。PDFページ全体を画像に変換することも可能です。
Q4:JavaでPDFメタデータを読み取る方法は?
A4: PDFドキュメントから PdfDocumentInformation を取得することで、タイトル、作成者、作成日時、キーワードなどの標準メタデータを高速に取得できます。
Q5:JavaでのPDF解析には制限がありますか?
A5: あります。複雑なレイアウト、スキャンPDF、カスタムフォントは解析精度に影響します。スキャンPDFの場合は、OCR処理を先に行う必要があります。





