PythonでPDFから表を抽出するには、通常、行と列で構成された視覚的レイアウトを理解する必要があります。多くのPDF表はセル境界を使用して定義されており、プログラム的に検出しやすくなっています。そのような場合、単にテキストを読み取るのではなく、レイアウト情報を解析できるライブラリを使うことが、正確なPDF表の抽出には不可欠です。
このチュートリアルでは、OCRや機械学習を使用せずにPythonでPDFから表を抽出する信頼性の高い方法を解説します。PDFに格子状の表がある場合でも複雑なレイアウトでも、表データをExcelやpandas DataFrameなどの構造化形式に変換する手順を学べます。
目次
PythonでPDFから表を抽出する準備
ExcelやCSVファイルとは異なり、PDFは表を構造化データとして保持していません。PythonでPDFから表を抽出するには、レイアウトを解析して表構造を検出できるライブラリが必要です。
Spire.PDF for Pythonは、ページごとに表を抽出するための組み込みメソッドを提供しており、明確にフォーマットされた表との相性が良く、PDFの内容をExcelやCSVなどの扱いやすいデータ形式に変換できます。
ライブラリのインストール方法:
pip install Spire.PDF
小規模なPDF表抽出には無料版も利用可能です:
pip install spire.pdf.free
PDFから表を抽出する手順
PythonでPDFから表を抽出するには、まず文書を読み込み、各ページを個別に解析します。Spire.PDF for Pythonを使えば、レイアウト構造に基づいて表を検出し、プログラムで抽出できます。複数ページのPDFにも対応可能です。
PDFを読み込み表を抽出する
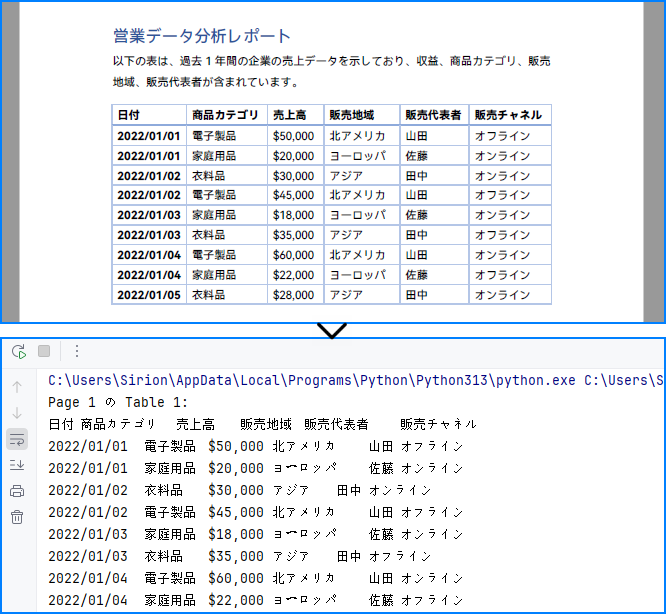
以下は、PythonでPDFから表を読み取る基本例です。Spire.PDFを使い、文書の各ページから表を抽出します。プログラムで表データを扱いたい開発者に最適です。
from spire.pdf import PdfDocument, PdfTableExtractor
# PDF文書を読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# PdfTableExtractorオブジェクトを作成
table_extractor = PdfTableExtractor(pdf)
# 各ページの表を抽出
for i in range(pdf.Pages.Count):
tables = table_extractor.ExtractTable(i)
for table_index, table in enumerate(tables):
print(f"Page {i + 1} の Table {table_index + 1}:")
for row in range(table.GetRowCount()):
row_data = []
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ")
row_data.append(text.strip())
print("\t".join(row_data))
この方法は、境界線のある表に対して信頼性があります。ただし、境界線のない表や複数行セル、未マークのヘッダーを含む表では、抽出が正確に行えない場合があります。
抽出結果の例:
表をExcelやCSVにエクスポート
抽出したPDF表を分析や保存したい場合、PythonでExcelやCSVに変換できます。この例ではSpire.XLS for Pythonを使い、各表をスプレッドシートに出力します。
pipでのインストール:
pip install spire.xls
PDF表をExcel/CSVに出力するコード例
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.xls import Workbook, FileFormat
# PDF文書を読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 抽出器とExcelワークブックを設定
extractor = PdfTableExtractor(pdf)
workbook = Workbook()
workbook.Worksheets.Clear()
# ページごとに表を抽出
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
for t_index, table in enumerate(tables):
sheet = workbook.Worksheets.Add(f"Page{page_index+1}_Table{t_index+1}")
for row in range(table.GetRowCount()):
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ").strip()
sheet.Range.get_Item(row + 1, col + 1).Value = text
sheet.AutoFitColumn(col + 1)
# すべての表を1つのExcelファイルに保存
workbook.SaveToFile("output/Sample.xlsx", FileFormat.Version2016)
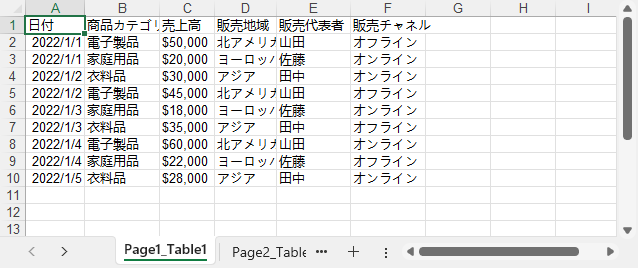
下記のように、抽出したPDFの表はSpire.XLS for Pythonを使用してExcelやCSVに変換されます。
PDF表抽出精度向上のヒント
複雑なレイアウトや改ページ、フォーマットの不一致により、PDFからの表抽出は完全でない場合があります。Pythonでより正確な結果を得るための実用的な方法を紹介します。
1. 複数ページにまたがる表の結合
Spire.PDFはページ単位で表を抽出します。表が複数ページにまたがる場合、行を結合して対応できます。
# 表を抽出して結合
combined_rows = []
for i in range(start_page, end_page + 1):
tables = table_extractor.ExtractTable(i)
if tables:
table = tables[0] # ページごとに1つの表を想定
for row in range(table.GetRowCount()):
cells = [table.GetText(row, col).strip().replace("\n", " ") for col in range(table.GetColumnCount())]
combined_rows.append(cells)
結合後、ExcelやCSVに変換して分析できます。
2. 空行・無効行の除外
表には空行や空列が含まれることがあります。抽出前にフィルタリングすると精度が向上します。
# 空行を除外
filtered_rows = []
for row in range(table.GetRowCount()):
row_data = [table.GetText(row, col).strip().replace("\n", " ") for col in range(table.GetColumnCount())]
if any(cell for cell in row_data):
filtered_rows.append(row_data)
# 空列を除外
transposed = list(zip(*filtered_rows))
filtered_columns = [col for col in transposed if any(cell.strip() for cell in col)]
filtered_data = list(zip(*filtered_columns))
これにより、雑多なレイアウトでもより正確な表抽出が可能です。
よくある質問 (FAQ)
Q: PDFからテキストと表の両方を抽出できますか?
はい、PdfTextExtractorでページ全体のテキストを取得し、PdfTableExtractorで構造化された表を抽出できます。
Q: 表が検出されません
PDFがテキストベース(スキャン画像ではない)であり、行列形式のレイアウトになっていることを確認してください。Spire.PDF for Pythonは境界線付き表のみを検出します。境界線のない表は認識されない場合があります。
画像ベースPDFの場合、Spire.OCR for Pythonを使用して表データを抽出できます。詳細は「Pythonで画像からテキストを抽出する方法」を参照してください。
Q: 境界線のない表を抽出するには?
Spire.PDFでは境界線のない表の抽出は難しい場合があります。以下の方法を検討してください:
PdfTextExtractorでテキストを抽出し、行列を特定するカスタムロジックを作成- 大規模言語モデルAPI(例: GPT)で抽出したテキストから構造を解析し、表データを取得
- 元PDFに表の境界線を追加してから生成することで抽出しやすくする
Q: 抽出した表をpandas DataFrameに変換するには?
Spire.PDFには直接DataFrame出力はありませんが、セル値をリストのリストに格納してから変換可能です。
import pandas as pd
df = pd.DataFrame(table_data)
これにより、PythonでPDF表をDataFrameに変換して分析できます。
Q: Spire.PDF for Pythonは無料で使えますか?
はい、以下の2つのオプションがあります:
- Free Spire.PDF for Python – 機能制限ありの永続無料版(ページ数制限など)。pipでインストール可能。公式ページ
- 一時的無料ライセンス – 商用版の全機能を評価や社内利用で試せます。申請ページ
まとめ
構造化されたレポートや財務データ、標準フォームなど、PythonでPDF表を抽出すると作業効率が大幅に向上します。Spire.PDF for Pythonのようなレイアウト認識型パーサを使えば、OCRや手動調整なしで表を正確に検出・抽出可能です。Excel、CSV、DataFrameに変換すれば、自動化やデータ分析にすぐ活用できます。
総じて、Spire.PDFを使ったPythonによるPDF表抽出は、ExcelやCSVなどの構造化形式への変換を通じて、分析や自動処理に非常に便利です。





