CSV(Comma-Separated Values)は表形式データの保存に広く利用される汎用フォーマットです。一方、リストは Python における基本データ構造で、データ処理に柔軟に対応できます。Python で CSV をリストへ変換する ことで、データ分析や他の処理フローとの統合をスムーズに行えます。
Python 標準の csv モジュールでも基本的な読み込みは可能ですが、Spire.XLS for Python を使用すると、スプレッドシートのような直感的な操作で構造的な CSV データを扱うことができます。
本記事では、Python で CSV をリスト(および辞書のリスト)に読み込む方法 を、基礎から応用までコード例付きで分かりやすく解説します。
目次:
Spire.XLS を CSV → リスト変換に使用する理由
Spire.XLS はスプレッドシート処理用の強力なライブラリで、CSV 取り扱いにおいて次のような利点があります。
- 直感的なインデックス操作:Excel と同様の 1 ベース行列インデックスで扱える
- 柔軟な区切り文字設定:カンマ・タブ・セミコロンなど任意の区切り文字を指定可能
- 構造的アクセス:CSV をワークシートとして読み込むため、行列 traversal が容易
- 強力なデータパース機能:数値・日付・文字列を自動で解析
インストール方法
以下の pip コマンドで Spire.XLS for Python をインストールできます:
pip install Spire.XLS
インストール後、すぐにプロジェクトで使用できます。
基本:CSV を Python リストへ変換する
CSV にヘッダーがない場合(データ行のみの場合)、Spire.XLS を使うと、行ごとにリストへ変換し、最終的に「リストのリスト」として取得できます。
手順:
- Spire.XLS モジュールをインポート
- Workbook オブジェクトを生成し CSV を読み込む
- 1 番目のワークシートを取得
- 行とセルを順に読み込み Python リストとして格納
CSV → リスト変換コード例:
from spire.xls import *
from spire.xls.common import *
# Workbook を初期化し、CSV を読み込む
workbook = Workbook()
workbook.LoadFromFile("Employee.csv",",")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# シートのデータを二次元リストへ変換
data_list = []
for i in range(sheet.Rows.Length):
row = []
for j in range(sheet.Columns.Length):
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
# 結果を表示
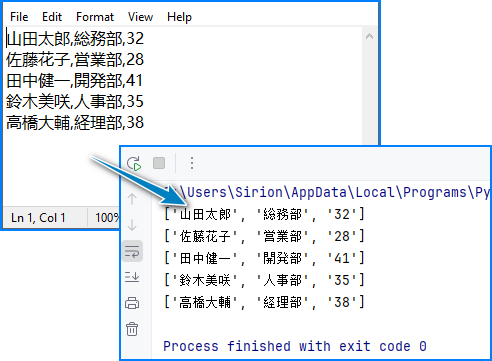
for row in data_list:
print(row)
# リソースを解放
workbook.Dispose()
出力例:
応用:CSV を辞書のリストへ変換する
ヘッダー(例:name,age,city)がある CSV の場合、辞書のリストへ変換すると、列名をキーとして扱えるためデータ操作がより直感的になります。
CSV → 辞書リスト変換コード例:
from spire.xls import *
# Workbook を初期化し、CSV を読み込む
workbook = Workbook()
workbook.LoadFromFile("Customer_Data.csv", ",")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# ヘッダー(1 行目)を取得
headers = []
for j in range(sheet.Columns.Length):
headers.append(sheet.Range[1, j + 1].Value)
# データ行をディクショナリのリストへ変換
dict_list = []
for i in range(1, sheet.Rows.Length): # ヘッダー行をスキップ
row_dict = {}
for j in range(sheet.Columns.Length):
key = headers[j]
value = sheet.Range[i + 1, j + 1].Value
row_dict[key] = value
dict_list.append(row_dict)
# 結果を出力
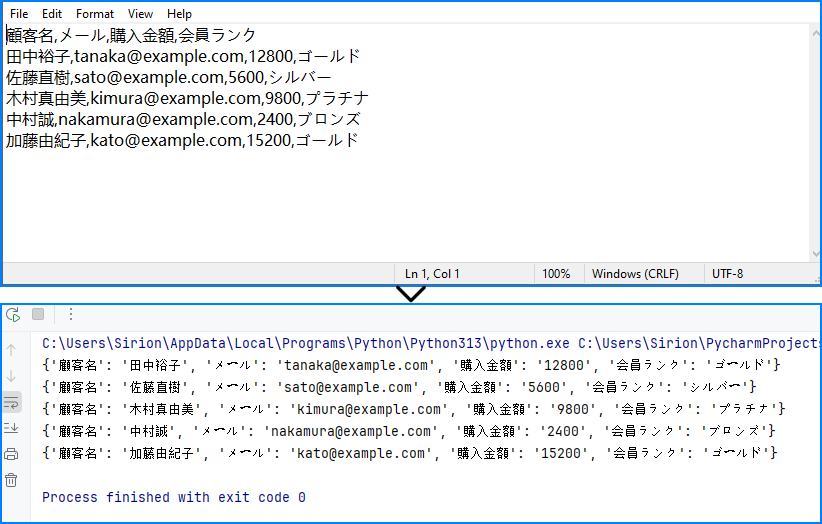
for record in dict_list:
print(record)
# リソースを解放
workbook.Dispose()
説明
- CSV を読み込む:Workbook クラスの LoadFromFile() を使用
- ヘッダー行の取得:1 行目を辞書キーとして利用
- 辞書化処理:各行のセル内容を、対応するヘッダー名をキーとしてマッピング
出力例:
特定ケースの処理方法
カスタム区切り文字の CSV(タブ・セミコロンなど)
カンマ以外の区切り文字(TSV など)を使う場合は、LoadFromFile の第 2 引数で区切り文字を指定します:
# タブ区切りファイル
workbook.LoadFromFile("data.tsv", "\t")
# セミコロン区切りファイル
workbook.LoadFromFile("data_eu.csv", ";")
空値を整形する
CSV に空セルがある場合、リストでは空文字 ('') として保持されます。空文字を "N/A" などに置き換える場合は以下のようにします:
cell_value = sheet.Range[i + 1, j + 1].Value or "N/A"
まとめ
Python で CSV をリストへ変換する方法 は、Spire.XLS を使うことで効率的かつ柔軟になります。 生データ用にリストのリストを使う場合も、構造化された分析のために辞書リストを使う場合も、Spire.XLS はパース処理・インデックス管理・リソース解放を自動的に行ってくれます。
この記事のコード例を活用すれば、データパイプライン、分析スクリプト、アプリケーションへ簡単に組み込むことができます。
より高度な機能については、Spire.XLS for Python ドキュメント を参照してください。
よくある質問(FAQ)
Q1: Spire.XLS は大規模 CSV にも対応できますか?
A: はい。一般的な業務データであれば問題なく処理できます。ただし、数百万行規模など極端に大きいデータについては、分割処理やビッグデータ専用のツールの利用を検討してください。
Q2: pandas を使う方法と比べてどうですか?
A: Spire.XLS はパース処理を細かく制御でき、追加のデータサイエンス系依存パッケージも不要です。 分析中心なら pandas が便利ですが、CSV の解析を正確に行いたい場合 や pandas が使えない環境 では Spire.XLS が適しています。
Q3: ヘッダー付きの CSV をリストへ変換するには?
A: 辞書のリストへ変換する方法がおすすめです。1 行目をヘッダーとして読み取り、各行のデータとマッピングすることで、列名でデータへアクセスできます。
Q4: CSV の特定列だけをリスト化したい場合は?
A: 内側のループで対象列のみを読み込むよう変更してください。
# 1 列目と 3 列目のみを抽出(インデックス 0 と 2)
target_columns = [0, 2]
for i in range(sheet.Rows.Length):
row = []
for j in target_columns:
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)





