
レポートや請求書、PDF形式で保存されたデータセットを扱う際、開発者はしばしばその表データをスプレッドシートやデータベース、分析ツールで再利用する必要があります。一般的な解決策は JavaでPDFをCSVに変換すること です。CSVは軽量で構造化され、ほぼすべてのプラットフォームで扱えるため非常に便利です。
テキストや画像の書き出しと異なり、PDFからCSVへの変換の本質は PDFから表を抽出しCSVとして保存すること です。Spire.PDF for Java を使えば、PDF内の表構造を検出して数行のコードでプログラム的にCSVとして出力できます。
この記事では、環境構築から表抽出、さらに複数ページや1ページ内の複数表など複雑なケースへの対応まで、JavaでのPDFからCSVへの変換手順 をステップごとに解説します。
本チュートリアルの内容
JavaでPDFをCSVに変換するための環境構築
JavaでPDFをCSVに変換する前に、開発環境を整える必要があります。適切なライブラリを選び、プロジェクトに追加しましょう。
Spire.PDF for Javaを選ぶ理由
PDFファイルにはCSV形式でのエクスポート機能が備わっていないため、プログラムによる表抽出が現実的なアプローチです。Spire.PDF for Java は、PDF内の表構造を検出し、直接CSVに保存できるAPIを提供しており、シンプルかつ効率的に変換を行えます。
Spire.PDF for Javaのインストール
Mavenを利用する場合は以下を追加します。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.8.3</version>
</dependency>
Mavenを使わない場合は、Spire.PDF for Javaパッケージをダウンロードし、JARファイルをプロジェクトのクラスパスに追加してください。
PDFから表を抽出してCSVに保存する
PDFをCSVに変換する最も実用的な方法は表の抽出です。Spire.PDF for Javaを使えば以下のステップで実現できます。
- PDFを読み込む
- PdfTableExtractor で各ページから表を検出
- 行ごとにセルの値を取得
- CSVファイルに出力
以下にJavaコードのサンプルを示します。
Javaコード例:PDFからCSVへの変換
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;
import java.io.*;
public class PdfToCsvExample {
public static void main(String[] args) throws Exception {
// PDFドキュメントを読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("Sample.pdf");
// 抽出したテキストを格納するStringBuilder
StringBuilder sb = new StringBuilder();
// ページごとに処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (PdfTable table : tableLists) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
// CSVフィールドを安全にエスケープ
String cellText = escapeCsvField(table.getText(row, col));
sb.append(cellText);
if (col < table.getColumnCount() - 1) {
sb.append(",");
}
}
sb.append("\n");
}
}
}
}
// CSVファイルに出力
FileWriter writer = new FileWriter("output/PDFTable.csv");
writer.write(sb.toString());
writer.close();
pdf.close();
System.out.println("PDF内の表をCSVに正常にエクスポートしました。");
}
// CSVフィールドをエスケープするユーティリティメソッド
private static String escapeCsvField(String text) {
if (text == null) return "";
// 改行を削除
text = text.replaceAll("[\\n\\r]", "");
// 特殊文字を含む場合はエスケープ
if (text.contains(",") || text.contains(";") || text.contains("\"") || text.contains("\n")) {
text = text.replace("\"", "\"\""); // ダブルクォートをエスケープ
text = "\"" + text + "\""; // クォートで囲む
}
return text;
}
}
コード解説
- PdfDocument:PDFファイルをメモリに読み込む
- PdfTableExtractor:ページごとの表を検出
- PdfTable:行・列にアクセス可能
- escapeCsvField():改行を削除し、特殊文字をエスケープ
- StringBuilder:セルテキストをカンマ区切りで格納
- 出力結果は「Output.csv」として保存され、Excelや任意のエディタで開けます
PDFから抽出した表をCSVに変換した例:
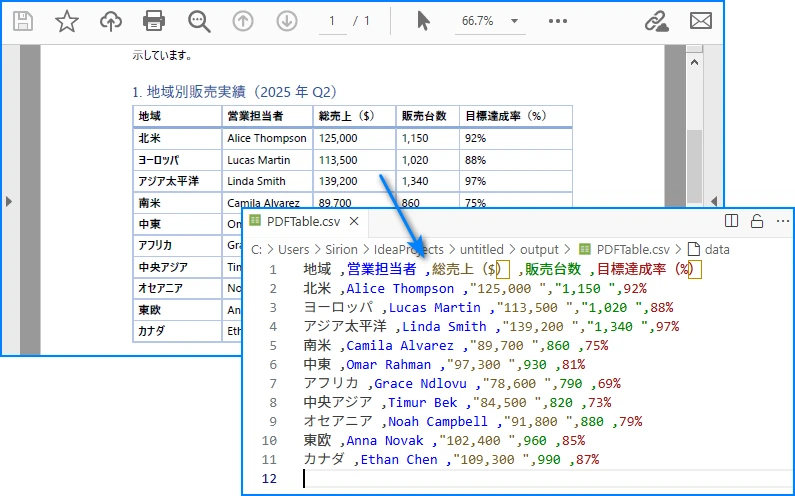
複雑なPDFからCSV変換のケースを処理する
実際のPDFには複数表、複数ページ、または不規則な表構造が含まれることが多いです。ここではそれらへの対応方法を紹介します。
1. 1ページに複数の表がある場合
extractTable(i) が返す PdfTable[] にはそのページで検出されたすべての表が含まれます。各表を個別のCSVに保存することも可能です。
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (int t = 0; t < tableLists.length; t++) {
PdfTable table = tableLists[t];
StringBuilder tableContent = new StringBuilder();
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
tableContent.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) {
tableContent.append(",");
}
}
tableContent.append("\n");
}
FileWriter writer = new FileWriter("Table_Page" + i + "_Index" + t + ".csv");
writer.write(tableContent.toString());
writer.close();
}
}
}
1ページ内の複数表を個別CSVに保存した例:
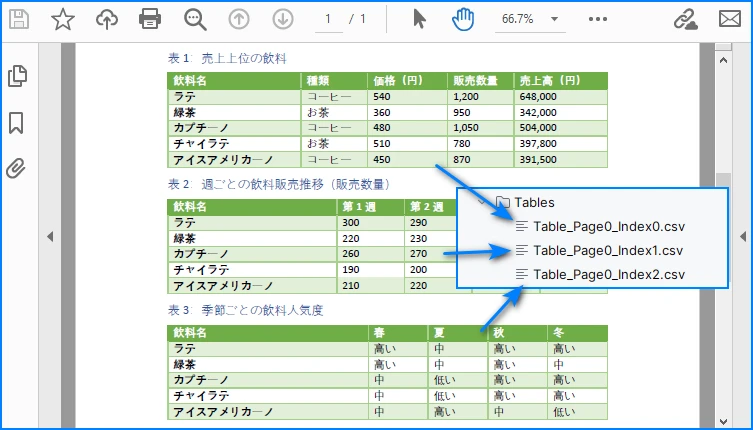
2. 複数ページや大きな表の場合
表が複数ページにまたがる場合はページごとに繰り返し処理し、追記していくのがポイント です。
StringBuilder sb = new StringBuilder();
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(i);
if (tables != null) {
for (PdfTable table : tables) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
sb.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) sb.append(",");
}
sb.append("\n");
}
}
}
}
FileWriter writer = new FileWriter("MergedTables.csv");
writer.write(sb.toString());
writer.close();
複数ページにまたがる大きな表を1つのCSVに統合した例:
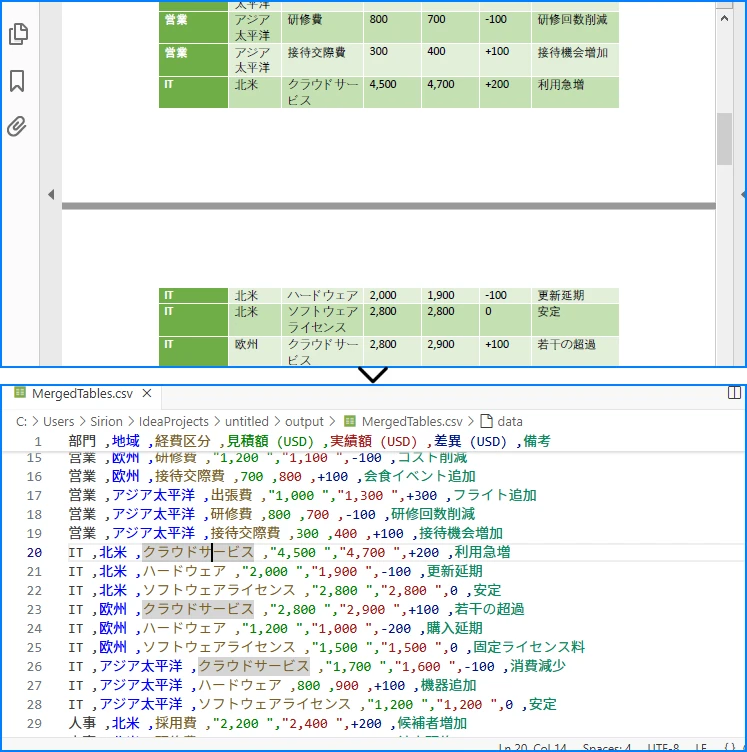
3. フォーマットに関する制限
CSVはテキストデータのみを保持するため、結合セル・フォント・画像などの情報は失われます。書式を保持したい場合はExcel(.xlsx)にエクスポートする方法が適しています。詳細は JavaでPDF表をExcelにエクスポートする方法 を参照してください。
4. CSVの特殊文字処理
CSVではカンマ、セミコロン、ダブルクォート、改行などの特殊文字がファイル構造を壊す可能性があります。 上記のJava例では escapeCsvField メソッドで改行除去と適切なエスケープ処理を行っています。
さらに高度な処理が必要な場合は Spire.XLS for Java を利用して Excelワークシートにデータを書き込み、その後 CSVとして保存 すれば、特殊文字も自動処理され正しいCSVが得られます。
オープンソースの OpenCSV や Apache Commons CSV なども同様に特殊文字処理を自動で行える選択肢です。
まとめ
JavaでPDFをCSVに変換するとは、基本的に 表を抽出して構造化データとして保存すること を意味します。CSVは軽量で広くサポートされており、表形式データの保存や分析に最適です。Spire.PDF for Javaを導入し、この記事のコード例に従うことで、このプロセスを自動化でき、時間を節約し手作業を減らせます。
さらに高度な機能を試したい方は、無料評価ライセンスの申請 を行うか、小規模プロジェクトには Free Spire.PDF for Java を利用できます。
FAQ
Q: PDFをCSVファイルに変換できますか? A: はい。画像や装飾されたテキストは変換できませんが、表を抽出してCSVに保存することは可能です。
Q: JavaでPDFからデータを抽出する方法は? A: Spire.PDF for JavaのようなPDFライブラリを使えば、ドキュメント解析や表検出、CSVやExcelへのエクスポートが可能です。
Q: 最適なPDF to CSV変換方法は? A: Java開発者には、Spire.PDF for Javaのようなプログラム的な解決策が、手動ツールより柔軟で効率的です。
Q: JavaコードでPDFをExcelに変換する方法は? A: CSV出力と手順はほぼ同じで、カンマ区切りのテキストではなくExcel形式に保存することで、より多機能な利用が可能です。





