
HTMLの解析は、Java開発において非常に重要な処理のひとつです。構造化データの抽出、コンテンツ分析、Webベースの情報活用など、さまざまな場面で活用されます。Webスクレイパーの構築、HTMLコンテンツの検証、Webページからのテキストや属性の抽出など、用途は多岐にわたりますが、信頼性の高いツールを使うことで実装は大幅に簡素化できます。
本ガイドでは、Spire.Doc for Java を使用して JavaでHTMLを解析する方法 を解説します。Spire.Docは、HTML解析とドキュメント処理を統合的に扱える強力なライブラリで、実用的なHTMLデータ抽出を効率よく実装できます。
- HTML解析にSpire.Doc for Javaを使う理由
- 環境準備とインストール
- 基本編:JavaでHTMLを解析して要素を抽出する
- 応用編:HTMLファイル・URLを解析する
- HTML解析に関するFAQ
HTML解析にSpire.Doc for Javaを使う理由
JavaにはJsoupなど複数のHTML解析ライブラリがありますが、Spire.Docはドキュメント処理との親和性と低コードで実装できる点が大きな特長です。効率を重視する開発者にとって、以下の理由からHTML解析用途に適しています。
- 直感的なオブジェクトモデル
HTMLを Section、Paragraph、Table などの構造化されたオブジェクトに変換し、生のHTMLタグを直接処理する必要がありません。 - 幅広いデータ抽出機能
テキスト、属性、表データ(行・セル)、見出しなどのスタイル情報まで、追加ライブラリなしで取得できます。 - 低コードワークフロー
HTMLの読み込みから処理まで、最小限のコードで実装でき、開発時間を短縮できます。 - 軽量な導入
MavenやGradleで簡単にプロジェクトへ追加でき、依存関係も最小限です。
環境準備とインストール
JavaでHTMLを読み込む前に、以下の環境が整っていることを確認してください。
- Java Development Kit (JDK)
JDK 8以上(URL解析で HttpClient を使用する場合は JDK 11以上を推奨) - Spire.Doc for Java
最新バージョン(Maven または手動で導入) - HTMLソース
HTML文字列、ローカルHTMLファイル、またはURL(動作確認用)
Spire.Doc for Javaのインストール
Mavenを使用する場合
以下のリポジトリと依存関係を pom.xml に追加します。必要なライブラリは自動的にダウンロードされます。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.12.2</version>
</dependency>
手動で導入する場合は、公式サイト からJARファイルをダウンロードし、プロジェクトに追加してください。
一時ライセンスの取得
デフォルトでは、Spire.Docの出力結果に評価用ウォーターマークが付与されます。制限を解除するには、30日間の無料トライアルライセンス を申請できます。
基本編:JavaでHTMLを解析して要素を抽出する
Spire.Docは、HTMLを構造化されたドキュメントモデルに変換します。段落、表、フィールドなどの要素をJavaオブジェクトとして直接操作できるため、データ抽出が容易になります。ここでは代表的なケースを紹介します。
1. JavaでHTMLからテキストを抽出する
HTMLタグを除外した純粋なテキスト抽出は、全文検索やコンテンツ分析でよく使われます。以下の例では、HTML文字列を解析し、すべての段落テキストを取得します。
Javaコード:HTML文字列からテキストを抽出
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTextFromHtml {
public static void main(String[] args) {
// 解析するHTMLコンテンツを定義
String htmlContent = "<html>" +
"<body>" +
"<h1>HTML解析の概要</h1>" +
"<p>Spire.Doc for Java を使用すると、HTMLからのテキスト抽出を簡単に行えます。</p>" +
"<ul>" +
"<li>見出しを抽出</li>" +
"<li>段落を抽出</li>" +
"<li>リスト項目を抽出</li>" +
"</ul>" +
"</body>" +
"</html>";
// 解析したHTMLを格納するためのDocumentオブジェクトを作成
Document doc = new Document();
// HTML文字列をドキュメントに解析して追加
doc.addSection().addParagraph().appendHTML(htmlContent);
// すべての段落からテキストを抽出
StringBuilder extractedText = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph paragraph : (Iterable<Paragraph>) section.getParagraphs()) {
extractedText.append(paragraph.getText()).append("\n");
}
}
// 抽出したテキストを出力または後続処理
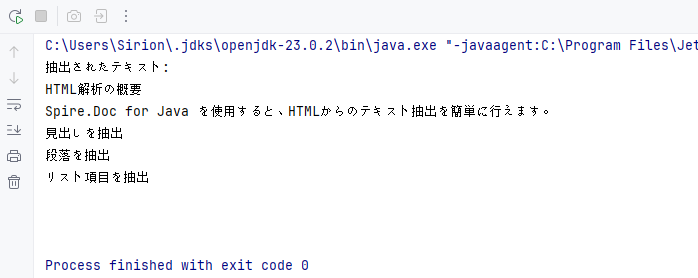
System.out.println("抽出されたテキスト:\n" + extractedText);
}
}
出力例:
2. JavaでHTMLテーブルのデータを抽出する
HTMLの <table> 要素は、商品一覧やレポートなどの構造化データを含むことが多くあります。Spire.Docでは、HTMLテーブルを Table オブジェクトとして扱えるため、行やセル単位で簡単にアクセスできます。
Javaコード:HTMLテーブルの行・セルを抽出
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTableFromHtml {
public static void main(String[] args) {
// テーブルを含むHTMLコンテンツ
String htmlWithTable = "<html>" +
"<body>" +
"<table border='1'>" +
"<tr><th>ID</th><th>商品名</th><th>価格</th></tr>" +
"<tr><td>001</td><td>ノートパソコン</td><td>$999</td></tr>" +
"<tr><td>002</td><td>スマートフォン</td><td>$699</td></tr>" +
"</table>" +
"</body>" +
"</html>";
// HTMLをDocumentオブジェクトに解析して読み込む
Document doc = new Document();
doc.addSection().addParagraph().appendHTML(htmlWithTable);
// テーブルデータを抽出
for (Section section : (Iterable<Section>) doc.getSections()) {
// セクション本文内のすべてのオブジェクトを走査
for (Object obj : section.getBody().getChildObjects()) {
if (obj instanceof Table) { // オブジェクトがテーブルかどうかを判定
Table table = (Table) obj;
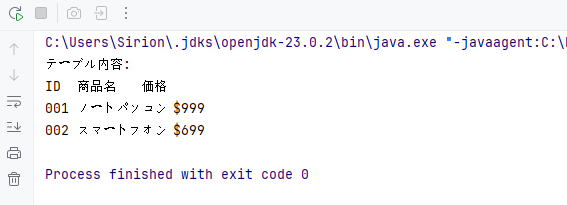
System.out.println("テーブル内容:");
// 行を順に処理
for (TableRow row : (Iterable<TableRow>) table.getRows()) {
// 行内のセルを順に処理
for (TableCell cell : (Iterable<TableCell>) row.getCells()) {
// 各セル内の段落からテキストを抽出
for (Paragraph para : (Iterable<Paragraph>) cell.getParagraphs()) {
System.out.print(para.getText() + "\t");
}
}
System.out.println(); // 各行の後で改行
}
}
}
}
}
}
出力例:
appendHTML() メソッドでHTMLをWordドキュメントとして解析した後、Spire.DocのAPIを使って ハイパーリンクを抽出 することも可能です。
応用編:HTMLファイル・URLを解析する
Spire.Doc for Javaは、ローカルHTMLファイルやWeb上のURLからHTMLを解析することもでき、実運用に適した柔軟性を備えています。
1. JavaでHTMLファイルを読み込む
ローカルのHTMLファイルは、loadFromFile(String, FileFormat.Html) メソッドを使用して読み込みます。
Javaコード:ローカルHTMLファイルを解析
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ParseHtmlFile {
public static void main(String[] args) {
// Documentオブジェクトを作成
Document doc = new Document();
// HTMLファイルを読み込む
doc.loadFromFile("input.html", FileFormat.Html);
// テキストを抽出して出力
StringBuilder text = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
text.append(para.getText()).append("\n");
}
}
System.out.println("HTMLファイルから抽出したテキスト:\n" + text);
}
}
この例ではHTMLファイル内のテキストを抽出しています。段落のスタイル(例:「Heading1」「Normal」)も同時に取得したい場合は、Paragraph.getStyleName() メソッドを使用します。
出力例:
関連情報:JavaでWordをHTMLに変換
2. JavaでURLを解析する
実際のWebスクレイピングでは、URLからHTMLを取得して解析する必要があります。Spire.Docは、JDK 11以降で利用可能な HttpClient と組み合わせて使用できます。
Javaコード:URLからHTMLを取得して解析
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class ParseHtmlFromUrl {
// 再利用可能な HttpClient(タイムアウトを設定してハングアップを防ぐ)
private static final HttpClient httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
public static void main(String[] args) {
String url = "https://jp.e-iceblue.com/misc/privacy-policy.html";
try {
// URLからHTMLコンテンツを取得
System.out.println("Fetching from: " + url);
String html = fetchHtml(url);
// Spire.DocでHTMLを解析
Document doc = new Document();
Section section = doc.addSection();
section.addParagraph().appendHTML(html);
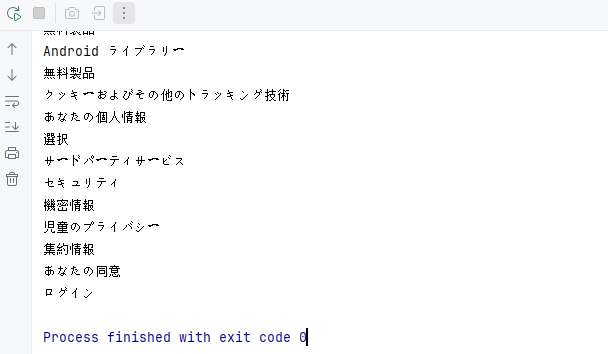
System.out.println("--- 見出し ---");
// 見出しを抽出
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
// 段落スタイルが見出しかどうかを確認(例:"Heading1", "Heading2")
if (para.getStyleName() != null && para.getStyleName().startsWith("Heading")) {
System.out.println(para.getText());
}
}
} catch (Exception e) {
System.err.println("エラー: " + e.getMessage());
}
}
// ヘルパーメソッド: 指定したURLからHTMLコンテンツを取得
private static String fetchHtml(String url) throws Exception {
// User-Agentヘッダー付きでHTTPリクエストを作成(ブロック回避のため)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("User-Agent", "Mozilla/5.0")
.timeout(Duration.ofSeconds(10))
.GET()
.build();
// リクエストを送信してレスポンスを取得
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
// リクエストが成功したか確認(HTTP 200 = OK)
if (response.statusCode() != 200) {
throw new Exception("HTTPエラー: " + response.statusCode());
}
return response.body(); // 生のHTMLコンテンツを返す
}
}
処理のポイント:
- HTTP取得 HttpClientでHTMLを取得し、User-Agentを設定してアクセスブロックを回避します。
- HTML解析 DocumentにSectionとParagraphを追加し、appendHTML()でHTMLを読み込みます。
- データ抽出 段落スタイルが「Heading」で始まるかを判定し、見出しを抽出します。
出力例:
まとめ
JavaでのHTML解析は、Spire.Doc for Javaを使うことで大幅に簡素化できます。HTML文字列、ローカルファイル、URLのいずれからでも、テキストや表データを最小限のコードで抽出可能です。生のHTMLタグを直接扱ったり、重い依存関係を管理したりする必要はありません。
Webスクレイピング、コンテンツ分析、HTML変換(例:HTMLをPDFに変換)など、さまざまな用途で活用できます。本ガイドの手順に沿って実装すれば、Javaプロジェクトに実用的なHTML解析機能をスムーズに組み込めるでしょう。
HTML解析に関するFAQ
Q1:JavaでHTMLを解析するには、どのライブラリが最適ですか?
A:用途によって異なります。
- Spire.Doc:HTMLからテキストや表を抽出しつつ、PDF変換などのドキュメント処理も行いたい場合に適しています。
- Jsoup:シンプルなHTML解析のみで十分な場合に向いていますが、表や構造化データの処理には追加実装が必要です。
Q2:不完全なHTMLでも解析できますか?
A:はい。Spire.Doc for Javaでは、XHTMLValidationType.None を指定して厳密な検証を無効化することで、不完全なHTML構造にも対応できます。
doc.loadFromFile("input.html", FileFormat.Html, XHTMLValidationType.None);
ただし、構造が大きく崩れているHTMLでは、解析に失敗する場合があります。
Q3:解析後のHTMLを編集して再保存できますか?
A:可能です。段落テキストの編集、表の行削除、新しい要素の追加などを行った後、HTMLとして保存できます。
doc.saveToFile("modified.html", FileFormat.Html);
Q4:HTML解析にインターネット接続は必要ですか?
A:ローカルファイルやHTML文字列を解析する場合、インターネット接続は不要です。URLからHTMLを取得する場合のみ、事前にネットワーク接続が必要になります。





