データ主導の業務が一般化している現在、Python 開発者にとって「リスト(Python の基本データ構造)を Excel へ変換する」作業は非常に一般的です。Excel は多くの業界で、データの可視化・共有・レポート作成の標準ツールとして広く利用されています。
レポート生成、分析前の前処理、非エンジニアへのデータ共有など、Python のリストを Excel に出力するスキルは欠かせません。
pandas のような軽量ライブラリでも基本的な出力は可能ですが、Spire.XLS for Python は Excel の書式設定、スタイル、ファイル生成を細かく制御でき、Microsoft Excel のインストールも不要です。このガイドでは、さまざまなリスト構造を Excel へ変換する方法を、実例とベストプラクティスとともに解説します。
- なぜ Python のリストを Excel に変換するのか
- インストール手順
- 基本:一次元リストを Excel に書き込む
- 二次元リスト(ネストされたリスト)を Excel に変換する
- 辞書型(dict)のリストを Excel に変換する
- Excel 出力を最適化する 4 つのポイント
- まとめ
- FAQ
なぜ Python のリストを Excel に変換するのか
Python のリストは柔軟にデータを保持できますが、Excel には次のような利点があります:
- 共同作業:Excel は広く利用されており、Python を知らなくても並べ替え・フィルター・編集が可能。
- レポート作成:書き出した後にグラフやピボットテーブルを追加できる。
- コンプライアンス:多くの業界で Excel 形式が監査や保存の基準とされている。
- 可視化:色・枠線・ヘッダーなどの Excel の書式設定により、リストより読みやすい。
売上データ、ユーザー情報、アンケート結果など、Excel に書き出すことでデータの共有性と実用性が大幅に向上します。
インストール手順
Spire.XLS for Python を使用するには、pip でインストールします:
pip install Spire.XLS
Excel(.xls/.xlsx)形式の読み書きに対応し、太字、列幅、色などの書式設定が自由に行えます。 本番レベルの Excel 出力に最適なライブラリです。
さらに多くの機能を試すには、30日間の無料評価ライセンスを取得できます。
基本:一次元の Python リストを Excel に変換する
一次元リストを Excel に書き込む場合、リストをループし、1 列に順番に挿入します。
以下のコード例では、文字列のリストを 1 列に書き込みます。 数値リストの場合は、保存前に数値書式を設定できます。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("シンプルなリスト")
# サンプルデータ(文字列のリスト)
data_list = ["佐藤", "鈴木", "高橋", "田中", "伊藤"]
# リストの内容を Excel セルに書き込みます(1行目・1列目から開始)
for index, value in enumerate(data_list):
worksheet.Range[index + 1, 1].Value = value
# 表示を見やすくするため、列幅を設定します
worksheet.Range[1, 1].ColumnWidth = 15
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("SimpleListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
1 行に並べたい場合は以下のようにします:
for index, value in enumerate(data_list):
worksheet.Range[1, index + 1].Value = value
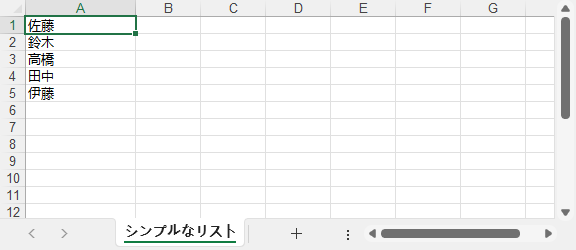
出力結果: きれいに整った 1 列の Excel になります。
二次元リスト(ネストされたリスト)を Excel に変換する
ネストされたリスト(2D リスト)は、行列形式のデータで、Excel シートに直接マッピングできます。 以下は、従業員データ(名前・年齢・部署)を Excel テーブルへ変換する例です。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("社員データ")
# ネストされたリスト(各行:[氏名、年齢、部署])
employee_data = [
["氏名", "年齢", "部署"], # ヘッダー行
["佐藤 太郎", 30, "人事部"],
["鈴木 一郎", 28, "開発部"],
["高橋 花子", 35, "マーケティング部"],
["田中 美咲", 29, "経理部"]
]
# ネストされたリストの内容を Excel に書き込みます
for row_idx, row_data in enumerate(employee_data):
for col_idx, value in enumerate(row_data):
if isinstance(value, int):
worksheet.Range[row_idx + 1, col_idx + 1].NumberValue = value
else:
worksheet.Range[row_idx + 1, col_idx + 1].Value = value
# ヘッダー行の書式を設定します
worksheet.Range["A1:C1"].Style.Font.IsBold = True
worksheet.Range["A1:C1"].Style.Color = Color.get_Yellow()
# 列幅を設定します
worksheet.Range[1, 1].ColumnWidth = 10
worksheet.Range[1, 2].ColumnWidth = 6
worksheet.Range[1, 3].ColumnWidth = 15
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("NestedListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
ポイント
- 最初のサブリストはヘッダーとして扱う
- 二重ループで行列を Excel セルにマッピング
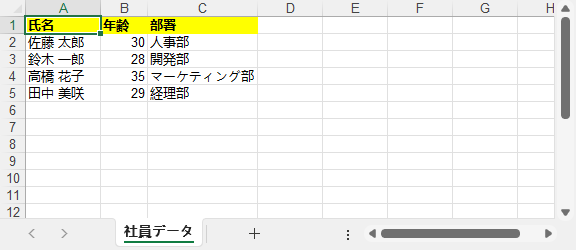
出力結果: ヘッダーが太字・黄色で、型が正しく保持された Excel テーブル。
Excel ファイルをよりプロフェッショナルな仕上がりにするために、Spire.XLS for Python を使用して、セルの罫線を追加したり、条件付き書式を設定したり、その他の書式設定オプションを適用したりできます。
辞書型(dict)のリストを Excel に変換する
辞書型のリストは、フィールド名付きのデータ構造を扱う際に一般的です。 以下の例では、顧客情報のリストを Excel に書き出します。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("顧客データ")
# 辞書のリスト
customers = [
{"ID": 101, "氏名": "山田 太郎", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"},
{"ID": 102, "氏名": "佐藤 花子", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"},
{"ID": 103, "氏名": "鈴木 一郎", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"}
]
# 辞書のキーからヘッダーを取得します
headers = list(customers[0].keys())
# ヘッダーを 1 行目に書き込みます
for col, header in enumerate(headers):
worksheet.Range[1, col + 1].Value = header
worksheet.Range[1, col + 1].Style.Font.IsBold = True # ヘッダーを太字に設定します
# データ行を書き込みます
for row, customer in enumerate(customers, start=2): # 2 行目から開始します
for col, key in enumerate(headers):
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row, col + 1].NumberValue = value
else:
worksheet.Range[row, col + 1].Value = value
# 列幅を自動調整します
worksheet.AutoFitColumn(2)
worksheet.AutoFitColumn(3)
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("CustomerDataToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
メリット
- ヘッダーを自動抽出:手動で列名を定義する必要なし
- 列幅自動調整:内容に合わせて最適化
- 大規模データでも対応可能
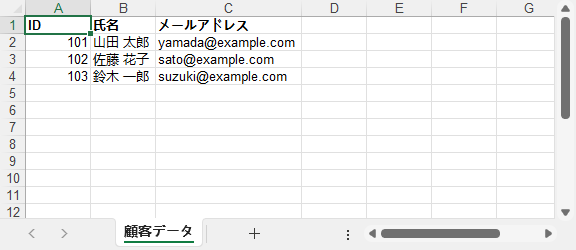
出力結果:ヘッダーが自動生成され、データ型が保持され、列幅が自動調整された Excel ファイル。
Excel 出力を最適化する 4 つのポイント
- データ型を保持する:数値には NumberValue を使用(Excel 内で計算が正しく機能)
- 列幅を自動調整する:AutoFitColumn() で手動設定の手間を軽減
- シート名を分かりやすくする:"Sheet1" ではなく "Q3 Sales" などに変更
- Workbook を破棄する:大量データでは Dispose() によるメモリ解放が重要
まとめ
Python のリストを Excel に変換する作業はデータ処理の基本スキルです。 Spire.XLS を利用することで、簡単なリストから複雑な入れ子構造、辞書型データまで、きれいで実用的な Excel ファイルを簡単に生成できます。
より高度な操作(グラフ、数式追加など)については、公式ドキュメントをご覧ください。
FAQs:リストから Excel への変換
Q1: pandas と Spire.XLS の違いは?
A: pandas は素早い基本出力に適していますが、書式設定の自由度は低めです。 Spire.XLS は以下の用途に向いています:
- 色・フォント・罫線などの高度な書式設定
- ウィンドウ枠の固定、条件付き書式、グラフなどの Excel 機能を利用
- Excel のインストール不要で 単独動作
Q2: Excel ファイルを別形式で保存する方法は?
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016)
workbook.SaveToFile("output.xls", ExcelVersion.Version97to2003)
Q3: Spire.XLS はデータ型をどのように扱う?
- .Text:文字列
- .NumberValue:数値
- .DateTimeValue:日付
- .BooleanValue:True/False
Q4: なぜデフォルトのワークシートを削除するのですか?
A: Workbook を作成すると空のシートが自動生成されるため、
Workbook.Worksheets.Clear() を呼ばないと不要なシートが残ります。
Q5: Excel に正しく表示されない場合の原因は?
A: 主な原因は次の通りです:
- Excel のセルは 1 から始まるインデックスを使用している
- データ型が適切に設定されていない
- 保存前に Workbook.Dispose() を呼んでいない





