チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

Python で Excel ファイルをインポートする場合、単にファイルを読み込むだけでは不十分なことがほとんどです。多くのケースでは、データをリストや辞書など、アプリケーションで直接利用できる Python のデータ構造へ変換する必要があります。
この変換ステップは非常に重要です。なぜなら、Excel のデータは通常表形式で保存されているのに対し、Python アプリケーションでは処理・統合・保存のために構造化されたデータが求められるからです。用途に応じて、データは順次処理用のリスト、フィールド単位でアクセスするための辞書、構造化モデルとしてのカスタムオブジェクト、あるいは永続化のためのデータベースとして表現されます。
本ガイドでは、Spire.XLS for Python を使用して、Excel ファイルを Python にインポートし、データを複数の構造に変換する方法を実用的な例とともに解説します。
目次
Python に Excel データをインポートする処理は、基本的に以下の 2 ステップで構成されます。
この分離は重要です。実際のアプリケーションでは、単に Excel を読み込むだけでは不十分であり、データを処理・保存・システム統合に適した形式へ変換する必要があるためです。
Spire.XLS for Python を使用して Excel データをインポートする場合、以下のコンポーネントが関与します。
一般的なワークフローは次のとおりです。
Excel ファイル → Workbook → Worksheet → CellRange → Python データ構造
このパイプラインを理解することで、さまざまなシナリオに対応できる柔軟なインポートロジックを設計できます。
以下の例を実行する前に、pip で Spire.XLS for Python をインストールします。
pip install spire.xls
必要に応じて、Spire.XLS for Python をダウンロード してプロジェクトに組み込むこともできます。
次の例は、Excel データを Python にインポートする最もシンプルな方法を示しています。
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
data = []
sheet = workbook.Worksheets[0]
# 使用されているセル範囲を取得
cellRange = sheet.AllocatedRange
# 1 行目のデータを取得
for col in range(cellRange.Columns.Count):
data.append(sheet.Range[1, col +1].Value)
print(data)
workbook.Dispose()
以下は、Excel ファイルからインポートされたデータのプレビューです。
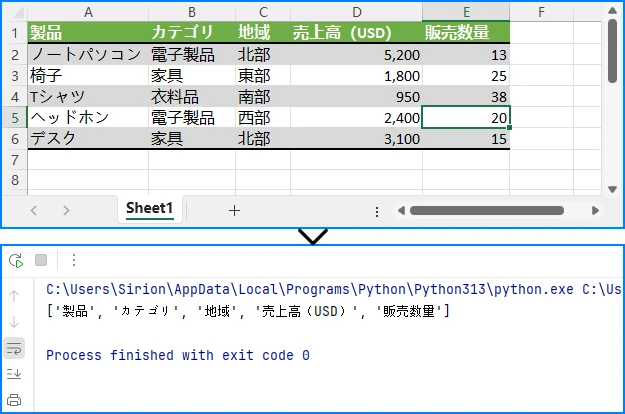
この最小限の例では、基本的なワークフローを示しています。すなわち、Workbook の初期化、Excel ファイルの読み込み、Worksheet およびセルデータへのアクセス、そしてリソース解放のための Dispose 処理です。
Python で Excel データをインポートする最もシンプルな方法の一つは、行単位のリストとして変換することです。この構造は、反復処理や基本的なデータ処理に適しています。
from spire.xls import *
# Workbook を読み込み
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
# 最初のワークシートの使用範囲を取得
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
# データ格納用リストを作成
data = []
for row_index in range(cellRange.RowCount):
row_data = []
for cell_index in range(cellRange.ColumnCount):
row_data.append(cellRange[row_index + 1, cell_index + 1].Value)
data.append(row_data)
workbook.Dispose()
リストとしてインポートする場合、ワークシートの各行が Python のリストとして扱われ、元の行順が保持されます。
コードの仕組み:
+1 のオフセットを適用しますこの設計の利点:
この構造は、順次処理や簡単な変換、または辞書やオブジェクトへの変換前の基盤データとして最適です。
Excel ファイルにヘッダー行が含まれている場合、辞書としてインポートすることで、より整理されたデータ管理と列名ベースのアクセスが可能になります。
from spire.xls import *
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
rows = list(cellRange.Rows)
headers = [cellRange[1, cell_index + 1].Value for cell_index in range(cellRange.ColumnCount)]
data_dict = []
for row in rows[1:]:
row_dict = {}
for i, cell in enumerate(row.Cells):
row_dict[headers[i]] = cell.Value
data_dict.append(row_dict)
workbook.Dispose()
辞書としてインポートする場合、各行は列ヘッダーをキーとするキー・バリュー構造に変換されます。
コードの仕組み:
この設計の利点:
この方法は、構造化データの処理や、JSON、API 連携、ラベル付きデータセットに適しています。
構造化されたアプリケーションでは、型安全性を維持しつつビジネスロジックをカプセル化するために、Excel データを Python オブジェクトとしてインポートする必要がある場合があります。
class Employee:
def __init__(self, name, age, department):
self.name = name
self.age = age
self.department = department
from spire.xls import *
from spire.xls.common import *
workbook = Workbook()
workbook.LoadFromFile("EmployeeData.xlsx")
sheet = workbook.Worksheets[0]
cellRange = sheet.AllocatedRange
employees = []
for row in list(cellRange.Rows)[1:]:
name = row.Cells[0].Value
age = int(row.Cells[1].Value) if row.Cells[1].Value else None
department = row.Cells[2].Value
emp = Employee(name, age, department)
employees.append(emp)
workbook.Dispose()
オブジェクトとしてインポートする場合、各行は構造化されたクラスインスタンスへマッピングされます。
コードの仕組み:
この設計の利点:
この方法は、バックエンドシステムやビジネスロジック層など、明確なデータモデルを持つアプリケーションに適しています。
多くのアプリケーションでは、Excel データを永続的に保存し、クエリ可能にするためにデータベースへ格納する必要があります。
import sqlite3
from spire.xls import *
# SQLite データベースに接続
conn = sqlite3.connect("sales.db")
cursor = conn.cursor()
# Excel 構造に対応したテーブルを作成
cursor.execute("""
CREATE TABLE IF NOT EXISTS sales (
product TEXT,
category TEXT,
region TEXT,
sales REAL,
units_sold INTEGER
)
""")
# Excel ファイルを読み込み
workbook = Workbook()
workbook.LoadFromFile("Sales.xlsx")
# 最初のワークシートにアクセス
sheet = workbook.Worksheets[0]
rows = list(sheet.AllocatedRange.Rows)
# 各行を処理(ヘッダー行はスキップ)
for row in rows[1:]:
product = row.Cells[0].Value
category = row.Cells[1].Value
region = row.Cells[2].Value
# 桁区切りを削除して float に変換
sales_text = row.Cells[3].Value
sales = float(str(sales_text).replace(",", "")) if sales_text else 0
# 販売数を整数に変換
units_text = row.Cells[4].Value
units_sold = int(units_text) if units_text else 0
# データベースに挿入
cursor.execute(
"INSERT INTO sales VALUES (?, ?, ?, ?, ?)",
(product, category, region, sales, units_sold)
)
# 変更を確定して接続を閉じる
conn.commit()
conn.close()
# Excel リソースを解放
workbook.Dispose()
以下は、Excel データおよび SQLite データベース構造のプレビューです。
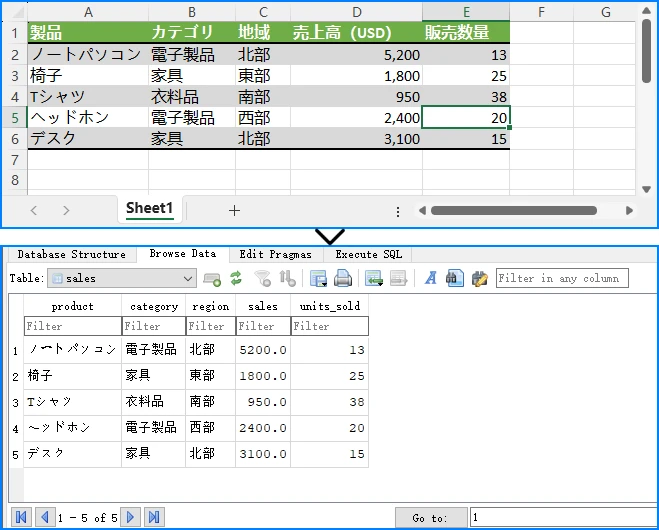
データベースへのインポートでは、各行が永続的なレコードとして保存されます。
コードの仕組み:
この設計の利点:
この方法が適しているケース:
データの保存、検索、大規模データパイプラインへの統合に適しています。
より詳細な手順については、Excel ファイルとデータベース間でデータを転送する方法 を参照してください。
本ガイドで Spire.XLS for Python を使用しているのは、Excel データへのアクセスと変換をシンプルかつ一貫した方法で実現できるためです。主な利点は以下のとおりです。
構造化されたオブジェクトモデル Workbook、Worksheet、CellRangeなど、Excel の構造に対応したコンポーネントを提供します。これにより、データフローの理解と実装が容易になります。 詳細は Spire.XLS for Python API Reference を参照してください。
データアクセスに特化したレイヤー 低レベルのファイル解析を意識する必要がなく、セル値や範囲に直接アクセスできます。そのため、ファイル構造ではなくデータ変換ロジックに集中できます。
フォーマット互換性 XLS や XLSX に加え、CSV、ODS、OOXML などのスプレッドシート形式をサポートしており、異なるファイル形式でも同じロジックを適用できます。
外部依存なし Microsoft Excel をインストールすることなく処理可能なため、バックエンドサービスや自動化環境に適しています。
Excel ファイルのパスが正しく、スクリプトからアクセス可能であることを確認してください。絶対パスの使用、または作業ディレクトリの確認が重要です。
import os
print(os.getcwd()) # 現在のディレクトリを確認
辞書としてインポートする場合、1 行目にヘッダーが存在することを確認してください。存在しない場合、キーが不正になります。
特に大規模ファイルを扱う場合、処理後は必ず Workbook を解放してください。
workbook.Dispose()
Excel セルの値は、期待する型と異なる場合があります。アプリケーションに応じて適切に検証・変換してください。
Python において、Excel ファイルの「読み込み(Read)」と「インポート(Import)」は関連していますが、異なる概念です。
読み込み(Read) は、ファイルから生データを取得することに焦点を当てます。セル値や行、特定範囲を取得しますが、データ構造自体は変更しません。
インポート(Import) は、読み込みに加えて変換も含みます。取得したデータを、リスト、辞書、オブジェクト、またはデータベースレコードなどに変換し、アプリケーションで直接利用できる形にします。
つまり、読み込みはインポートの一部であり、違いは目的にあります。読み込みはデータ取得、インポートは実用化のための準備です。
Python で Excel ファイルをインポートするとは、単にデータを読み込むことではなく、アプリケーションで活用できる構造へ変換することを意味します。本ガイドでは、Excel データをリストとして扱う方法、辞書へ変換する方法、オブジェクトへマッピングする方法、さらにデータベースへインポートする方法を解説しました。
Spire.XLS for Python を使用すれば、少ないコードで Excel データをさまざまな構造へ変換できます。一貫した API により、多様な Excel 形式や複雑なデータ処理にも対応可能です。
機能を評価するには、30 日間の試用ライセンスを申請 することができます。
Excel データをリスト、辞書、データベースなどの Python 構造に変換し、処理や統合に利用できるようにすることです。
Spire.XLS for Python などのライブラリを使用して、Workbook の読み込み、Worksheet へのアクセス、セルデータの取得を行い、必要な構造へ変換します。
はい。Excel データを読み取り、SQLite、MySQL、PostgreSQL などのデータベースへ挿入できます。データ移行やバックエンド連携でよく利用されます。
用途によって異なります。リストは単純処理、辞書は列名ベースのアクセス、オブジェクトは型安全性とロジック、データベースは永続化と検索に適しています。
不要です。Spire.XLS for Python のようなライブラリは、Excel をインストールせずに処理できます。

CSV(Comma-Separated Values)ファイルは、データ分析からバックエンドシステムまで、さまざまな業界におけるデータ交換の基盤となるファイル形式です。軽量で人が読みやすく、Excel、Google スプレッドシート、データベースなど、ほぼすべてのツールと互換性があります。Python で CSV ファイルを作成する方法 を探している開発者にとって、Spire.XLS for Python はその処理を大幅に簡素化できる強力なライブラリです。
本記事では、Spire.XLS を使用して Python で CSV ファイルを生成する方法 を詳しく解説します。基本的な CSV 作成から、リストや辞書データの変換、Excel から CSV への変換といった実践的なユースケースまで幅広くカバーします。
本記事で学べること
Spire.XLS for Python の導入は非常に簡単です。以下の手順で環境を準備します。
ステップ 1: Python 3.6 以上がインストールされていることを確認します。
ステップ 2: pip(Python の公式パッケージマネージャー)でライブラリをインストールします。
pip install Spire.XLS
ステップ 3(任意): すべての機能を制限なく試用するには、一時的な無料ライセンスを申請 します。
まずは、静的なデータ(例:売上レポート)から CSV ファイルを作成するシンプルな例を見ていきます。以下のコードでは、新しいワークブックを作成し、データを入力して CSV ファイルとして保存します。
from spire.xls import *
# 1. 新しいワークブックを作成
workbook = Workbook()
# 2. 先頭のワークシートを取得(既定のシート)
worksheet = workbook.Worksheets[0]
# 3. セルにデータを入力
# ヘッダー行
worksheet.Range["A1"].Text = "商品ID"
worksheet.Range["B1"].Text = "商品名"
worksheet.Range["C1"].Text = "単価"
worksheet.Range["D1"].Text = "販売数量"
worksheet.Range["A2"].NumberValue = 101
worksheet.Range["B2"].Text = "ワイヤレスイヤホン"
worksheet.Range["C2"].NumberValue = 7980
worksheet.Range["D2"].NumberValue = 250
worksheet.Range["A3"].NumberValue = 102
worksheet.Range["B3"].Text = "Bluetoothスピーカー"
worksheet.Range["C3"].NumberValue = 4980
worksheet.Range["D3"].NumberValue = 180
# CSV として保存
worksheet.SaveToFile("BasicSalesReport.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
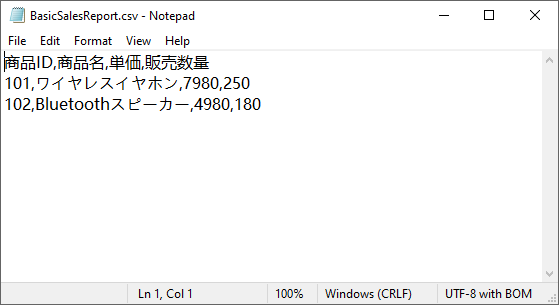
Workbook() で新しい Excel ワークブックを作成し、Worksheets[0] で対象のワークシートにアクセスします。.Text、数値には .NumberValue を使用し、適切なデータ型を保持します。SaveToFile() で CSV にエクスポートし、Dispose() でメモリリークを防止します。出力結果:
生成された BasicSalesReport.csv は次のようになります。
実際の業務では、データは API やデータベースから取得した辞書形式(JSON など)で扱われることが一般的です。以下の例では、辞書のリストを CSV に変換します。
from spire.xls import *
# サンプルデータ(データベースや API から取得した想定)
customer_data = [
{"顧客ID": 1, "氏名": "山田 太郎", "メールアドレス": "taro.yamada@ example.co.jp", "国名": "日本"},
{"顧客ID": 2, "氏名": "佐藤 花子", "メールアドレス": "hanako.sato@ example.co.jp", "国名": "日本"},
{"顧客ID": 3, "氏名": "鈴木 一郎", "メールアドレス": "ichiro.suzuki@ example.co.jp", "国名": "日本"}
]
# 1. ワークブックとワークシートを作成
workbook = Workbook()
worksheet = workbook.Worksheets[0]
# 2. ヘッダー行を書き込み(最初の辞書のキーを取得)
headers = list(customer_data[0].keys())
for col_idx, header in enumerate(headers, start=1):
worksheet.Range[1, col_idx].Text = header # 1 行目 = ヘッダー
# 3. データ行を書き込み
for row_idx, customer in enumerate(customer_data, start=2): # 2 行目から開始
for col_idx, key in enumerate(headers, start=1):
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row_idx, col_idx].NumberValue = value
else:
worksheet.Range[row_idx, col_idx].Text = value
# 4. CSV として保存
worksheet.SaveToFile("CustomerData.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
この方法は、JSON から CSV への変換、データベースのダンプ、REST API データのエクスポートなどに最適です。主な利点は以下のとおりです。
生成された CSV ファイル:
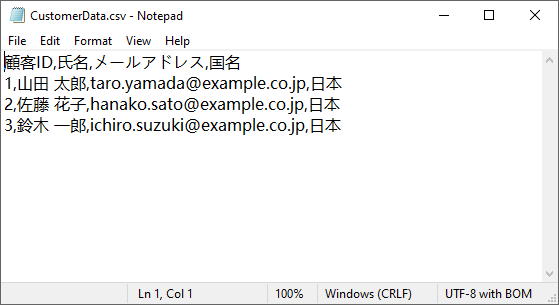
Spire.XLS は、Python で Excel(XLS/XLSX)を CSV に変換する処理にも優れています。Excel レポートをデータパイプラインや外部ツール向けに CSV として出力する場合に便利です。
from spire.xls import *
# 1. ワークブックを初期化
workbook = Workbook()
# 2. xlsx ファイルを読み込み
workbook.LoadFromFile("Sample.xlsx")
# 3. Excel を CSV として保存
workbook.SaveToFile("XLSXToCSV.csv", FileFormat.CSV)
workbook.Dispose()
変換結果:
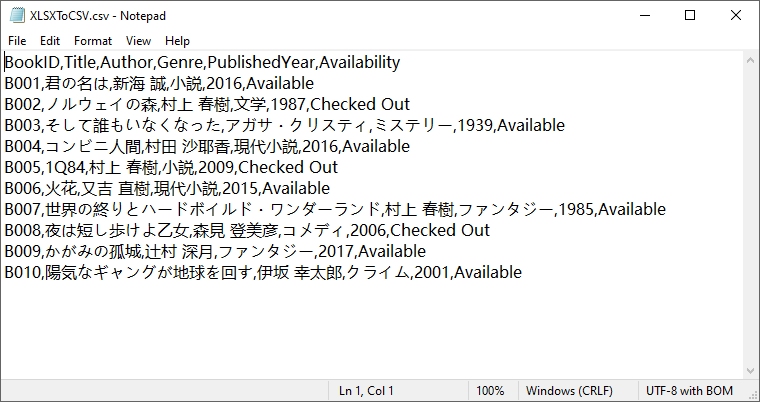
注意: SaveToFile() は既定では最初のワークシートのみを変換します。
堅牢で実務に耐える CSV を生成するために、以下のポイントを意識してください。
Encoding.get_UTF8() を明示的に指定し、多言語文字に対応します。Dispose() を呼び出してワークブック/ワークシートのリソースを解放し、メモリリークを防ぎます。Spire.XLS を活用すれば、Python での CSV ファイル生成を効率的かつ柔軟に実装できます。ゼロからのレポート作成、Excel ブックの変換、API やデータベースから取得した動的データの処理まで、幅広いシナリオに対応可能です。
本ガイドで紹介した方法を応用すれば、区切り文字やエンコーディング(UTF-8 など)の指定、データ型の適切な管理を行いながら、正確で互換性の高い CSV ファイルを作成できます。さらに高度な機能については、Spire.XLS for Python チュートリアル を参照してください。
A: Python 標準の csv モジュールは基本的な読み書きには適していますが、Spire.XLS には以下の利点があります。
A: はい。Spire.XLS は CSV ファイルの解析とデータ抽出をサポートしています。
A: はい。Spire.XLS は双方向変換をサポートしています。簡単な例は以下のとおりです。
from spire.xls import *
# ワークブックを作成
workbook = Workbook()
# CSV ファイルを読み込み
workbook.LoadFromFile("sample.csv", ",", 1, 1)
# Excel 形式で保存
workbook.SaveToFile("CSVToExcel.xlsx", ExcelVersion.Version2016)
A: SaveToFile() メソッドの第 2 引数で区切り文字を指定します。
# セミコロン(ヨーロッパ地域向け)
worksheet.SaveToFile("EU.csv", ";", Encoding.get_UTF8())
# タブ区切り(TSV)
worksheet.SaveToFile("TSV_File.csv", "\t", Encoding.get_UTF8())

Python で Excel ファイルを作成することは、データドリブンなアプリケーションにおいて非常に一般的な要件です。
業務ユーザーが内容を確認・共有しやすい形式でアプリケーションデータを提供する必要がある場合、Excel は現在でも最も実用的で広く受け入れられている選択肢の一つです。
実際のプロジェクトでは、Python を使って Excel ファイルを生成する処理は、自動化フローの出発点になることがよくあります。
データはデータベース、API、内部サービスなどから取得され、Python がそれらを一定のレイアウトや命名規則に従った構造化された Excel ファイルへ変換します。
本記事では、Spire.XLS for Python を使用した Python による Excel ファイル作成について、ワークブックを一から生成する方法をはじめ、データの書き込み、基本的な書式設定、既存ファイルの更新までを段階的に解説します。 すべてのサンプルは、実際の自動化シナリオを想定した実用的な視点で紹介します。
目次
Python による Excel ファイル作成は、単独の処理としてではなく、より大きなシステムの一部として利用されることがほとんどです。代表的な例は次のとおりです。
これらの場面では、Python を用いて Excel ファイルを自動生成することで、手作業を削減し、データの一貫性と再現性を確保できます。
本チュートリアルでは、Excel 操作の例として Spire.XLS for Python を使用します。
Excel ファイルを生成する前に、開発環境を整えておきましょう。
Excel 自動化には、Python 3.x のいずれの最新版でも問題ありません。
Spire.XLS for Python は pip から簡単にインストールできます。
pip install Spire.XLS
または、Spire.XLS for Python をダウンロード して、プロジェクトに手動で組み込むことも可能です。
本ライブラリは Microsoft Excel に依存せず動作するため、サーバー環境、定期実行ジョブ、Excel がインストールされていない自動化環境にも適しています。
このセクションでは、Python を使用して Excel ファイルを一から作成する方法を紹介します。 データを書き込む前に、ワークブックやワークシート、ヘッダー行などの基本構造を定義することが目的です。
初期レイアウトをコードで生成することで、すべての出力ファイルが同じ構造を持ち、後続のデータ処理に適した状態になります。
from spire.xls import Workbook, FileFormat
# 新しいワークブックを作成
workbook = Workbook()
# 既定のワークシートを取得
sheet = workbook.Worksheets[0]
sheet.Name = "テンプレート"
# タイトル用のプレースホルダーを追加
sheet.Range["B2"].Text = "月次レポート(テンプレート)"
# Excelファイルとして保存
workbook.SaveToFile("template.xlsx", FileFormat.Version2016)
workbook.Dispose()
テンプレートファイルのプレビュー:

この例では次の処理を行っています。
Python による Excel 自動生成では、1 つのワークブック内に複数のワークシートを配置し、関連データを論理的に整理することが一般的です。 各ワークシートには、異なるデータセット、集計結果、処理結果を格納できます。
from spire.xls import Workbook, FileFormat
workbook = Workbook()
# 最初のワークシートを取得して名前を設定
sales_sheet = workbook.Worksheets[0]
sales_sheet.Name = "売上データ"
# 不要な2番目のワークシートを削除
workbook.Worksheets.RemoveAt(1)
# 集計用の新しいワークシートを追加
report_sheet = workbook.Worksheets.Add("集計")
report_sheet.Range["A1"].Text = "月次売上レポート"
# ファイルを保存
workbook.SaveToFile("sales_report.xlsx", FileFormat.Version2016)
workbook.Dispose()
この構成は、1 つのシートに元データを読み込み、別のシートに処理結果を書き出すといった読み書きワークフローでよく利用されます。
Python で Excel ファイルを生成する場合、XLSX は最も一般的な形式で、最新の Microsoft Excel で完全にサポートされています。 複数シート、数式、書式設定にも対応しており、ほとんどの自動化シナリオに適しています。
Spire.XLS for Python では、以下の形式も生成可能です。
本記事では、レポート生成やテンプレート用途に適した XLSX 形式を使用します。対応形式の一覧は FileFormat 列挙型 を参照してください。
実際のアプリケーションでは、Excel に書き込まれるデータがコード内にハードコードされることはほとんどありません。
多くの場合、データはデータベースのクエリ結果、API レスポンス、または中間処理の結果として生成されます。
一般的なパターンとして、すでに構造化されたデータの最終出力先として Excel を使用するケースが挙げられます。
ここでは、アプリケーション側ですでに売上データが生成されていると仮定します。
各レコードには、商品情報と計算済みの数値が含まれており、Python ではそれを 辞書のリスト として扱います。
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "売上レポート"
# ヘッダー行の設定
headers = ["商品名", "数量", "単価", "合計金額"]
for col, header in enumerate(headers, start=1):
sheet.Range[1, col].Text = header
# 通常、データはデータベースやサービス層から取得される
sales_data = [
{"product": "ノートパソコン", "qty": 15, "price": 1200},
{"product": "モニター", "qty": 30, "price": 250},
{"product": "キーボード", "qty": 50, "price": 40},
{"product": "マウス", "qty": 80, "price": 20},
{"product": "ヘッドセット", "qty": 100, "price": 10}
]
# データ行の入力
row = 2
for item in sales_data:
sheet.Range[row, 1].Text = item["product"]
sheet.Range[row, 2].NumberValue = item["qty"]
sheet.Range[row, 3].NumberValue = item["price"]
sheet.Range[row, 4].NumberValue = item["qty"] * item["price"]
row += 1
# Excelファイルの保存
workbook.SaveToFile("monthly_sales_report.xlsx")
workbook.Dispose()
月次売上レポートのプレビュー:
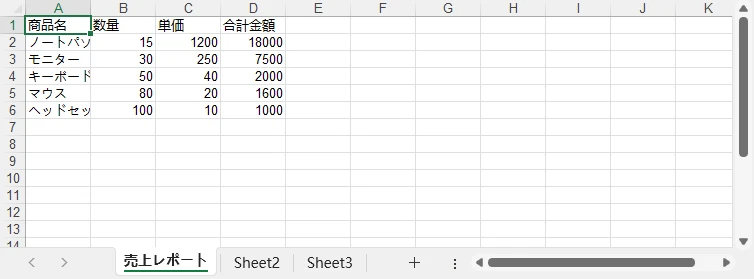
この例では、商品名などの文字列は CellRange.Text、数量や金額などの数値は CellRange.NumberValue を使用して書き込んでいます。 これにより、Excel 上で正しく計算・並び替え・書式設定を行うことができます。
この方法はデータ量が増えても自然にスケールし、ビジネスロジックと Excel 出力処理を分離できる点が特長です。 さらに詳しい書き込み例については、PythonでExcel書き込みを自動化する方法 を参照してください。
実際の業務では、Excel ファイルはそのまま関係者へ共有されることが多く、 書式設定のない生データは可読性や理解性に欠ける場合があります。
よく行われる書式設定には、次のようなものがあります。
以下の例では、これらの基本的な書式設定を組み合わせて、レポートの視認性を向上させています。
from spire.xls import Workbook, Color, LineStyleType
# 作成済みのExcelファイルを読み込む
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# 使用されているセルのフォント名を設定する
sheet.Range.Style.Font.FontName = "Yu Gothic UI"
# ヘッダー行の書式設定
header_range = sheet.Range.Rows[0]
header_range.Style.Font.IsBold = True
header_range.Style.Font.Size = 12
header_range.Style.Color = Color.get_LightBlue()
# 通貨形式を適用
sheet.Range["C2:D6"].NumberFormat = "$#,##0.00"
# データ行の背景色を交互に設定
for i in range(1, sheet.Range.Rows.Count):
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
if i % 2 == 0:
row_range.Style.Color = Color.get_LightGreen()
else:
row_range.Style.Color = Color.get_LightYellow()
# データ範囲に罫線を追加
sheet.Range["A2:D6"].BorderAround(LineStyleType.Medium, Color.get_LightBlue())
# 列幅を自動調整
sheet.AllocatedRange.AutoFitColumns()
# 書式設定済みファイルを保存
workbook.SaveToFile("monthly_sales_report_formatted.xlsx")
workbook.Dispose()
書式設定後の月次売上レポート:

書式設定はデータの正確性そのものには影響しませんが、 共有・保存される業務レポートでは、事実上必須とされることが多いです。 より高度な書式設定については、PythonでExcelワークシートの書式設定を行う方法 を参照してください。
既存の Excel ファイルを更新する場合、特定のセルを固定位置で更新するのではなく、 条件に一致する行を検索して更新するケースが一般的です。
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
sheet = workbook.Worksheets[0]
# 商品名で対象行を検索し、ステータスを設定
sheet.Range["E1"].Text = "ステータス" # ヘッダーを設定
for row in range(2, sheet.LastRow + 1):
product_name = sheet.Range[row, 1].Text
if product_name == "ノートパソコン": # 日語商品名に合わせる
sheet.Range[row, 5].Text = "確認済み"
break
# 更新されたファイルを保存
workbook.SaveToFile("monthly_sales_report_updated.xlsx")
workbook.Dispose()
更新後の月次売上レポート:
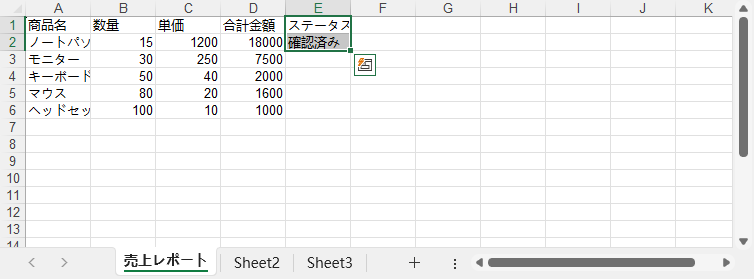
外部から取り込んだ Excel ファイルのデータは、そのままでは分析やレポートに適さないことがあります。 重複行、不整合な値、不完全なデータなどが含まれている場合が少なくありません。
実際の自動化システムでは、Excel ファイルは最終成果物ではなく中間データとして使われることも多く、 次のような課題が頻繁に発生します。
こうした場合、Excel を読み込み、Python 側で正規化・集計処理を行い、結果を新しいシートに書き出すことが一般的です。
以下の例では、商品ごとに複数行存在する売上データを読み込み、 商品ごとの合計売上金額を計算した サマリーシート を生成します。
from spire.xls import Workbook, Color
workbook = Workbook()
workbook.LoadFromFile("raw_sales_data.xlsx")
source = workbook.Worksheets[0]
summary = workbook.Worksheets.Add("集計") # 日語名に変更
# 出力用ヘッダーを定義
summary.Range["A1"].Text = "注文ID"
summary.Range["B1"].Text = "売上合計"
product_totals = {}
# 元データを読み込み、商品ごとに売上を集計
for row in range(2, source.LastRow + 1):
product = source.Range[row, 1].Text
value = source.Range[row, 4].Value
# 不完全・無効な行をスキップ
if not product or value is None:
continue
try:
amount = float(value)
except ValueError:
continue
if product not in product_totals:
product_totals[product] = 0
product_totals[product] += amount
# 集計結果を書き込み
target_row = 2
for product, total in product_totals.items():
summary.Range[target_row, 1].Text = product
summary.Range[target_row, 2].NumberValue = total
target_row += 1
# 合計行を追加
summary.Range[summary.LastRow, 1].Text = "合計"
summary.Range[summary.LastRow, 2].Formula = "=SUM(B2:B" + str(summary.LastRow - 1) + ")"
# 書式設定
summary.Range.Style.Font.FontName = "Yu Gothic UI"
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.Size = 12
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.IsBold = True
for row in range(2, summary.LastRow + 1):
for column in range(1, summary.LastColumn + 1):
summary.Range[row, column].Style.Font.Size = 10
summary.Range[
summary.LastRow, 1, summary.LastRow, summary.LastColumn
].Style.Color = Color.get_LightGray()
summary.Range.AutoFitColumns()
workbook.SaveToFile("normalized_sales_summary.xlsx")
workbook.Dispose()
正規化・集計後のサマリー:

データ検証や集計、正規化といった処理は Python が担い、Excel は業務ユーザー向けの最終出力形式として利用されます。これにより、手作業による修正や複雑な数式に頼る必要がなくなります。
Python には Excel ファイルを作成する方法が複数存在しますが、 最適な選択は Excel をワークフローの中でどのように使うかによって異なります。
Spire.XLS for Python は、次のようなシナリオに特に適しています。
データ分析や統計処理は別のライブラリで行い、 最終段階で Free Spire.XLS を使って Excel ファイルを生成するという構成も一般的です。
このように処理と表示を分離することで、保守性と信頼性を高めることができます。 詳細なガイドについては、Spire.XLS for Python チュートリアル を参照してください。
Excel 自動化では、次のような実務的な問題に遭遇することがあります。
ファイルパスや権限エラー 保存先ディレクトリの存在と書き込み権限を事前に確認してください。
想定外のデータ型 文字列と数値を明示的に使い分け、Excel 上での計算エラーを防ぎます。
ファイルの上書き タイムスタンプ付きのファイル名や専用出力フォルダを利用しましょう。
大規模データの処理 行単位で順次書き込み、ループ内での不要な書式設定を避けることが重要です。
これらを早期に考慮することで、データ量や処理の複雑さが増しても安定した自動化が可能になります。
PythonでExcelファイルを作成することは、レポート作成、データエクスポート、ドキュメント更新を自動化するための実用的な手段です。 ファイル生成、構造化データの書き込み、書式設定、更新処理を組み合わせることで、 単発のスクリプトを超えた安定した自動化システムを構築できます。
Spire.XLS for Python は、自動化・一貫性・保守性が求められる環境において、 Excel 処理を確実に実装するための有効な選択肢です。 一時ライセンスを申請 することで、Excel 自動化の可能性を最大限に活用できます。
はい。 Spire.XLS for Python のようなライブラリは Microsoft Excel に依存せず動作するため、 サーバー環境やクラウド、自動化ワークフローに適しています。
適切に実装すれば可能です。 行を順次書き込み、ループ内で不要な書式設定を避けることで、大量データにも対応できます。
タイムスタンプ付きのファイル名を使用する、 または出力専用ディレクトリを用意する方法が一般的です。
はい。 対応しているファイル形式であれば、Python で読み取り・修正・拡張が可能です。

Excel は、データの整理・分析・可視化において最も広く利用されているツールのひとつです。財務報告書から業務ダッシュボードに至るまで、多くのワークフローで Excel へのデータ出力が必要とされます。手動で情報を入力する代わりに、Python で Excel ファイルを書き込む処理を自動化すれば、処理がより迅速で、信頼性が高く、スケーラブルになります。
本チュートリアルでは、Python を使って Excel ファイルにデータを書き込む方法を解説します。構造化データの挿入、書式設定、エクスポートまでをカバーしており、例ではプログラムからワークブックを生成・カスタマイズできる Python の Excel ライブラリを使用しています。
本チュートリアルの内容:
Python で Excel ファイルを書き込むには、ワークブックの作成・読み込み・保存をプログラム的に行えるライブラリが必要です。Spire.XLS for Python はこれらの操作に対応した完全な API を提供し、レポート作成やデータ処理を自動化できます。
pip を使ってインストールします:
pip install spire.xls
インストール後は、次の 3 つの基本操作が可能になります:
これらの操作が、Python におけるデータ書き込み、書式設定、複数シート管理の基礎となります。
実際のビジネスシーンでは、新しい Excel ファイルの作成、既存レポートの更新、テキスト・数値・日付・数式などさまざまな種類のデータ書き込みが必要です。このセクションでは、これらのケースにおける効率的な Python での Excel データ操作を紹介します。
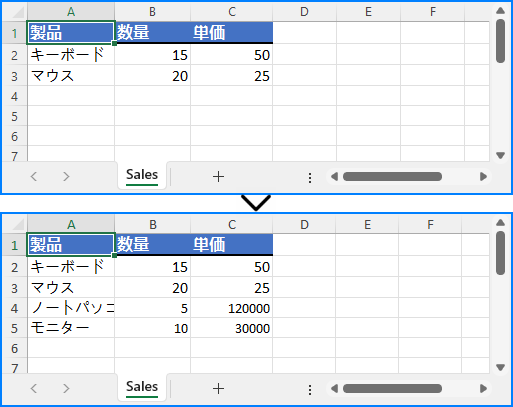
最新の売上データや在庫情報などを既存の Excel ワークブックに追記したい場合、ファイルを開いてプログラムで新しいデータ行を追加し、既存の内容を保持したまま保存できます。
from spire.xls import Workbook, ExcelVersion
workbook = Workbook()
workbook.LoadFromFile("Sample.xlsx")
sheet = workbook.Worksheets[0]
# 新しい行を追加
sheet.Range["A4"].Value = "ノートパソコン"
sheet.Range["B4"].NumberValue = 5
sheet.Range["C4"].NumberValue = 120000
sheet.Range["A5"].Value = "モニター"
sheet.Range["B5"].NumberValue = 10
sheet.Range["C5"].NumberValue = 30000
workbook.SaveToFile("output/updated_excel.xlsx", ExcelVersion.Version2016)
ポイントとなる要素:
この方法により、既存のレポートを保持したまま継続的にデータを更新できます。
大規模なデータセットを扱う場合、セル単位で更新するよりも複数行・列を一括で書き込む方が効率的です。この方法は処理速度の向上だけでなく、ワークシート全体のデータ整合性を確保できます。
from spire.xls import Workbook, ExcelVersion
# 新しい Excel ワークブックを作成
workbook = Workbook()
sheet = workbook.Worksheets[0]
orders = [
["注文ID", "顧客名", "商品名", "数量", "単価", "ステータス"],
[1001, "佐藤", "ノートパソコン", 2, 120000, "発送済み"],
[1002, "鈴木", "モニター", 1, 30000, "保留中"],
[1003, "高橋", "キーボード", 5, 4500, "配達済み"],
[1004, "田中", "マウス", 3, 2500, "発送済み"],
[1005, "伊藤", "タブレット", 1, 45000, "保留中"]
]
for row_index, row_data in enumerate(orders, start=1):
for col_index, value in enumerate(row_data, start=1):
if isinstance(value, (int, float)):
sheet.Range[row_index, col_index].NumberValue = value
else:
sheet.Range[row_index, col_index].Value = value
workbook.SaveToFile("output/orders.xlsx", ExcelVersion.Version2016)
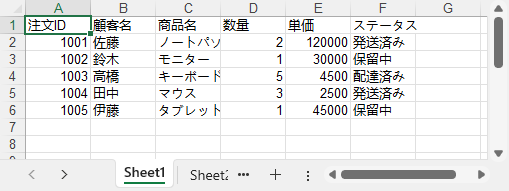
注目すべき要素:
バッチ書き込みは、データベースのクエリ結果や業務レポートのエクスポートに特に有効です。
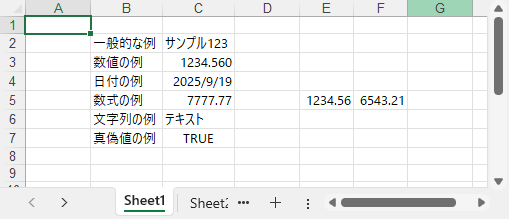
Excel のセルは、テキスト・数値・日付・数式など多様なデータ型を扱えます。正しいプロパティを使うことで、各データ型が適切に保存・表示され、計算や書式設定が正確に行われます。
from spire.xls import Workbook, ExcelVersion, DateTime, TimeSpan
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 一般的な値
sheet.Range[2, 2].Text = "一般的な例"
sheet.Range[2, 3].Value = "サンプル123"
# 数値
sheet.Range[3, 2].Text = "数値の例"
sheet.Range[3, 3].NumberValue = 1234.56
sheet.Range[3, 3].NumberFormat = "0.000"
# 日付
sheet.Range[4, 2].Text = "日付の例"
sheet.Range[4, 3].DateTimeValue = DateTime.get_UtcNow()
# 数式
sheet.Range[5, 2].Text = "数式の例"
sheet.Range[5, 5].NumberValue = 1234.56
sheet.Range[5, 6].NumberValue = 6543.21
sheet.Range[5, 3].Formula = "=SUM(E5:F5)"
# テキスト
sheet.Range[6, 2].Text = "文字列の例"
sheet.Range[6, 3].Text = "テキスト"
# 真偽値
sheet.Range[7, 2].Text = "真偽値の例"
sheet.Range[7, 3].BooleanValue = True
sheet.AllocatedRange.Style.Font.FontName = "Yu Gothic UI"
sheet.AllocatedRange.AutoFitColumns()
workbook.SaveToFile("output/value_types.xlsx", ExcelVersion.Version2016)
主な関数・プロパティ:
異なるデータ型を正しく扱うことは、ビジネス計算やレポートの精度を維持するために不可欠です。対応するデータ型の詳細は XlsRange API リファレンス を参照してください。
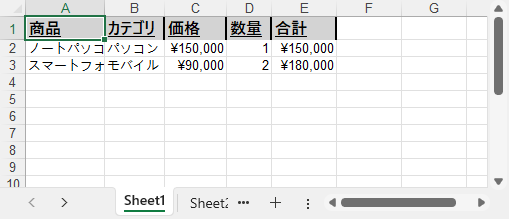
Excel レポートをわかりやすく、プロフェッショナルに仕上げるには、データ入力や更新と同時に書式を適用することが重要です。このセクションでは、セルのスタイル、数値フォーマット、列幅・行高の調整方法を解説します。
フォント・罫線・背景色などのスタイルを適用することで、シートの可読性と視覚的な訴求力を高められます。
from spire.xls import Workbook, Color, FontUnderlineType, ExcelVersion, BordersLineType, LineStyleType
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 見出し
sheet.Range["A1"].Value = "商品"
sheet.Range["B1"].Value = "カテゴリ"
sheet.Range["C1"].Value = "価格"
sheet.Range["D1"].Value = "数量"
sheet.Range["E1"].Value = "合計"
# データ行
sheet.Range["A2"].Value = "ノートパソコン"
sheet.Range["B2"].Value = "パソコン"
sheet.Range["C2"].NumberValue = 150000
sheet.Range["D2"].NumberValue = 1
sheet.Range["E2"].Formula = "=C2*D2"
sheet.Range["A3"].Value = "スマートフォン"
sheet.Range["B3"].Value = "モバイル"
sheet.Range["C3"].NumberValue = 90000
sheet.Range["D3"].NumberValue = 2
sheet.Range["E3"].Formula = "=C3*D3"
# ヘッダーのスタイル
header = sheet.Range["A1:E1"]
header.Style.Font.FontName = "Yu Gothic UI"
header.Style.Font.Size = 12.0
header.Style.Font.IsBold = True
header.Style.Font.Underline = FontUnderlineType.Single
header.Style.Interior.Color = Color.get_LightGray()
header.Style.Borders[BordersLineType.EdgeRight].LineStyle = LineStyleType.Medium
主な構成要素:
スタイルを使うことで、重要な部分を強調し、レポート全体の見栄えを向上させられます。
数値はフォーマットを適切に指定することで、通貨・パーセンテージ・整数など読みやすい形で表示できます。CellRange.NumberFormat を利用して、値の見せ方を制御します。
# 数値のフォーマット(円表示)
sheet.Range["C2:C3"].NumberFormat = "¥#,##0" # 通貨
sheet.Range["D2:D3"].NumberFormat = "0" # 整数
sheet.Range["E2:E3"].NumberFormat = "¥#,##0"
ポイント:
適切な数値フォーマットにより、財務データが理解しやすく、よりプロフェッショナルに見えます。詳細は Python で Excel セルの数値フォーマットを設定する方法 を参照してください。
列幅や行高を適切に設定することで、内容を見やすく表示できます。自動調整や固定値の指定が可能です。
# 列幅と行の高さを自動調整
for col in range(1, 5):
sheet.AutoFitColumn(col)
for row in range(1, 3):
sheet.AutoFitRow(row)
#sheet.Range["A1:E3"].AutoFitColumns()
#sheet.Range["A1:E3"].AutoFitRows()
# 固定の列幅と行の高さを設定
sheet.Columns[1].Width = 150
sheet.Rows[1].Height = 30
workbook.SaveToFile("output/formatted_excel.xlsx", ExcelVersion.Version2016)
ポイント:
動的データには自動調整、定型レイアウトには固定値を用いることで、見やすさと一貫性を両立できます。
より高度な Excel 書式設定(フォント・色・罫線・条件付き書式など)については、Python で Excel を書式設定する方法 を参照してください。
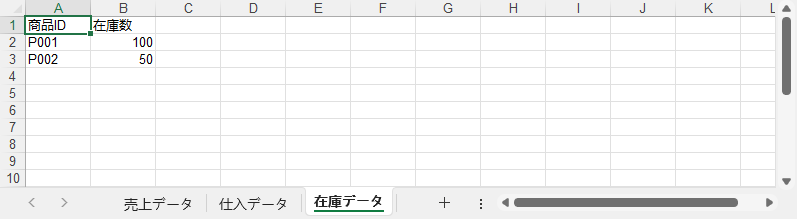
Excel では、複数のワークシートを使うことで関連情報を分離し、管理しやすくできます。たとえば、売上・仕入・在庫を同じワークブック内の別シートに整理できます。このセクションでは、Python で 複数シートを作成・参照・管理する方法を紹介します。
from spire.xls import Workbook, ExcelVersion
workbook = Workbook()
# 新しく作成されたワークブックには、
# デフォルトのワークシートが3つ含まれています
# ワークシート名を日本語に設定
sheet = workbook.Worksheets[0]
sheet.Name = "売上データ"
sheet1 = workbook.Worksheets["Sheet2"]
sheet1.Name = "仕入データ"
sheet2 = workbook.Worksheets.Add("在庫データ")
sheet2.Range["A1"].Value = "商品ID"
sheet2.Range["B1"].Value = "在庫数"
sheet2.Range["A2"].Value = "P001"
sheet2.Range["B2"].NumberValue = 100
sheet2.Range["A3"].Value = "P002"
sheet2.Range["B3"].NumberValue = 50
workbook.Worksheets.RemoveAt(2)
workbook.SaveToFile("output/multi_sheet.xlsx", ExcelVersion.Version2016)
主な操作:
これにより、Excel ファイルを論理的に構成し、関連データを分離して明確かつ管理しやすくできます。
効率性・一貫性・使いやすさを確保するため、以下のベストプラクティスに従うことを推奨します:
これらを実践することで、再利用可能でプロフェッショナルなレポートを効率的に作成できます。
Python で Excel 書き込みを自動化すれば、レポート作成が大幅に効率化されます。ワークブック作成、データの効率的な書き込み、スタイル適用、シート管理、多様なデータ型の処理を組み合わせることで、一貫性・正確性・プロフェッショナル性を備えた Excel レポートが実現できます。さらに詳しく試すには、無料の一時ライセンスを申請するか、Free Spire.XLS for Python を利用できます。
はい、既存のワークブックを読み込み、データを追加・修正した上で保存できます。既存の内容は保持されます。
複数行のバッチ書き込みと、書式設定を最小限に抑えた挿入で、数千行規模でも高いパフォーマンスを維持できます。
はい、=SUM() などの基本数式から複雑な計算式まで挿入でき、レポートを動的に更新できます。
Spire.XLS for Python は .xlsx、.xls、CSV、さらに PDF へのエクスポートにも対応しており、一般的な利用シナリオと互換性要件をカバーします。
Excel スプレッドシートは、データの整理、分析、表形式での表示に広く利用されています。プログラムから Excel ファイルを操作できるようになると、自動化や他のアプリケーションとの連携が可能になり、大変便利です。特に、新しい Excel ファイルを作成したり、既存のファイルから情報を取得したり、必要に応じてデータを更新・変更する方法を理解しておくと役立ちます。
本記事では、Spire.XLS for Python ライブラリを使用して、Python で Excel ドキュメントを作成・読み取り・更新する方法を紹介します。
この操作には、Spire.XLS for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.XLS for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.XLSSpire.XLS for Python は、Excel ドキュメントを作成・編集するためのさまざまなクラスやインターフェースを提供しています。以下は、この記事で使用する主なクラス、プロパティ、およびメソッドの一覧です。
| メンバー | 説明 |
| Workbook クラス | Excel ブック(ファイル全体)を表します。 |
| Workbook.Worksheets.Add() メソッド | 新しいワークシートをブックに追加します。 |
| Workbook.SaveToFile() メソッド | ワークブックを Excel ファイルとして保存します。 |
| Worksheet クラス | ワークブック内のワークシートを表します。 |
| Worksheet.Range プロパティ | ワークシート内の特定のセルまたはセル範囲を取得します。 |
| Worksheet.Range.Text プロパティ | セルの文字列データを取得または設定します。 |
| Worksheet.Rows プロパティ | ワークシート内のすべての行を取得します。 |
| CellRange クラス | セルまたはセル範囲を表します。 |
以下は、Spire.XLS for Python を使用してゼロから Excel ドキュメントを作成する手順です。
from spire.xls import Workbook, HorizontalAlignType, VerticalAlignType, LineStyleType, ExcelColors, FileFormat
# Workbook オブジェクトを作成します
wb = Workbook()
# 既定のワークシートを削除します
wb.Worksheets.Clear()
# ワークシートを追加し、「社員」と名前を付けます
sheet = wb.Worksheets.Add("社員")
# A1 から G1 のセルを結合します
sheet.Range["A1:G1"].Merge()
# A1 にデータを書き込み、書式を設定します
sheet.Range["A1"].Text = "寰宇自動車会社の社員基本情報"
sheet.Range["A1"].HorizontalAlignment = HorizontalAlignType.Center
sheet.Range["A1"].VerticalAlignment = VerticalAlignType.Center
sheet.Range["A1"].Style.Font.IsBold = True
sheet.Range["A1"].Style.Font.Size = 13
# 1行目の行の高さを設定します
sheet.Rows[0].RowHeight = 30
# 特定のセルにデータを書き込みます
sheet.Range["A2"].Text = "氏名"
sheet.Range["B2"].Text = "性別"
sheet.Range["C2"].Text = "生年月日"
sheet.Range["D2"].Text = "学歴"
sheet.Range["E2"].Text = "連絡先"
sheet.Range["F2"].Text = "職位"
sheet.Range["G2"].Text = "社員ID"
sheet.Range["A3"].Text = "健太"
sheet.Range["B3"].Text = "男性"
sheet.Range["C3"].Text = "1990-02-10"
sheet.Range["D3"].Text = "学士"
sheet.Range["E3"].Text = "24756854"
sheet.Range["F3"].Text = "整備士"
sheet.Range["G3"].Text = "0021"
sheet.Range["A4"].Text = "翔太"
sheet.Range["B4"].Text = "男性"
sheet.Range["C4"].Text = "1985-06-08"
sheet.Range["D4"].Text = "修士"
sheet.Range["E4"].Text = "59863247"
sheet.Range["F4"].Text = "整備士"
sheet.Range["G4"].Text = "0022"
sheet.Range["A5"].Text = "彩香"
sheet.Range["B5"].Text = "女性"
sheet.Range["C5"].Text = "1989-11-25"
sheet.Range["D5"].Text = "学士"
sheet.Range["E5"].Text = "79540352"
sheet.Range["F5"].Text = "営業"
sheet.Range["G5"].Text = "0023"
sheet.Range["A6"].Text = "大輔"
sheet.Range["B6"].Text = "男性"
sheet.Range["C6"].Text = "1988-04-16"
sheet.Range["D6"].Text = "修士"
sheet.Range["E6"].Text = "52014060"
sheet.Range["F6"].Text = "整備士"
sheet.Range["G6"].Text = "0024"
sheet.Range["A7"].Text = "美咲"
sheet.Range["B7"].Text = "女性"
sheet.Range["C7"].Text = "1998-01-21"
sheet.Range["D7"].Text = "学士"
sheet.Range["E7"].Text = "35401489"
sheet.Range["F7"].Text = "人事"
sheet.Range["G7"].Text = "0025"
# 指定範囲の行の高さを設定します
sheet.Range["A2:G7"].RowHeight = 15
# 列幅を設定します
sheet.SetColumnWidth(3, 15)
sheet.SetColumnWidth(4, 21)
sheet.SetColumnWidth(5, 15)
# 指定範囲の罫線スタイルを設定します
sheet.Range["A2:G7"].BorderAround(LineStyleType.Medium)
sheet.Range["A2:G7"].BorderInside(LineStyleType.Thin)
sheet.Range["A2:G2"].BorderAround(LineStyleType.Medium)
sheet.Range["A2:G7"].Borders.KnownColor = ExcelColors.Black
# 使用するすべてのセルにフォント名を設定する
sheet.Range.Style.Font.FontName = "Yu Gothic UI"
# .xlsx ファイルとして保存します
wb.SaveToFile("output/Excelファイルの作成.xlsx", FileFormat.Version2016)
wb.Dispose()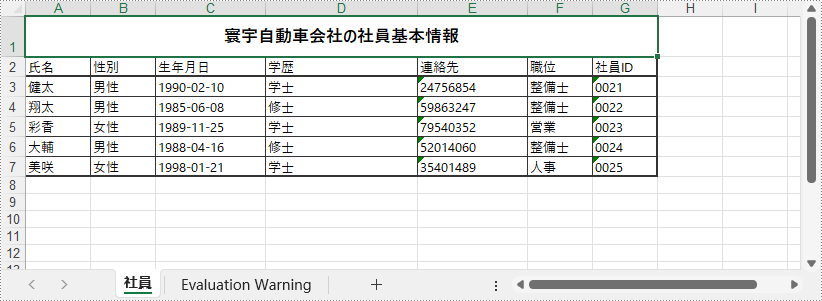
Worksheet.Range.Value プロパティを使用すると、セルの数値または文字列の値を文字列として取得できます。ワークシート全体やセル範囲からデータを取得するには、セルをループ処理することで可能です。
以下は、Spire.XLS for Python を使用してワークシートからデータを取得する手順です。
from spire.xls import Workbook
# Workbook オブジェクトを作成します
wb = Workbook()
# 既存の Excel ファイルを読み込みます
wb.LoadFromFile("output/Excelファイルの作成.xlsx")
# 最初のワークシートを取得します
sheet = wb.Worksheets[0]
# データが入力されているセル範囲を取得します
locatedRange = sheet.AllocatedRange
# 行を繰り返し処理します
for i in range(len(sheet.Rows)):
# 列を繰り返し処理します
for j in range(len(locatedRange.Rows[i].Columns)):
# 特定のセルのデータを取得して出力します
print(locatedRange[i + 1, j + 1].Value + " ", end='')
print("")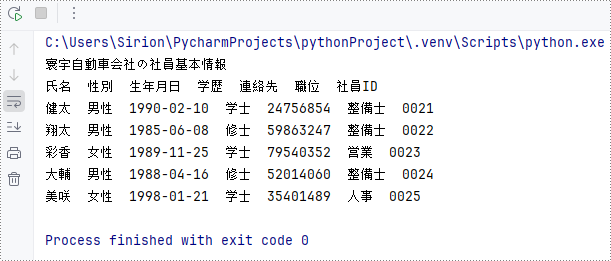
特定のセルの値を変更するには、Worksheet.Range.Value プロパティを使って新しい値を代入するだけで構いません。以下は、その手順です。
from spire.xls import Workbook, ExcelVersion
# Workbook オブジェクトを作成します
wb = Workbook()
# 既存の Excel ファイルを読み込みます
wb.LoadFromFile("output/Excelファイルの作成.xlsx")
# 最初のワークシートを取得します
sheet = wb.Worksheets[0]
# 特定のセルの値を変更します
sheet.Range["A1"].Value = "更新済みの値"
# ファイルとして保存します
wb.SaveToFile("output/Excelファイルの更新.xlsx", ExcelVersion.Version2016)
wb.Dispose()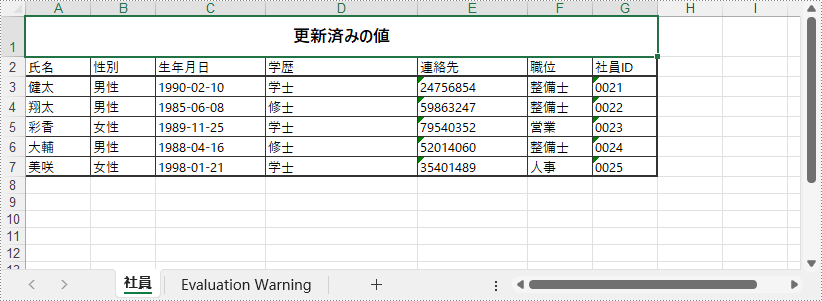
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





