
PDF ドキュメント内の画像の透過度を設定することは、プロフェッショナルな仕上がりを実現するうえで非常に重要です。これにより、画像の縁を目立たせずに重ね合わせたり、背景や下層のコンテンツと自然に一体化させたりすることができます。この操作は見た目の魅力を高めるだけでなく、特にグラフィック要素の多いドキュメントにおいて、洗練された統一感のある印象を与えます。この記事では、Spire.PDF for Python を使用して、Python プログラム内で PDF 画像の透過度を効果的に設定する方法を紹介します。
この操作には Spire.PDF for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.XLS for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.PDF
Spire.PDF for Python では、PdfPageBase.Canvas.DrawImage() メソッドを使用して指定位置に画像を描画できます。描画前に PdfPageBase.Canvas.SetTransparency() メソッドを呼び出すことで、描画する画像の透明度を設定できます。以下の手順で操作します。
from spire.pdf import *
# PdfDocumentインスタンスを作成
pdf = PdfDocument()
# PDFファイルを読み込み
pdf.LoadFromFile("Sample.pdf")
# 1ページ目を取得
page = pdf.Pages.get_Item(0)
# 画像を読み込み
image = PdfImage.FromFile("Screen.jpg")
# キャンバスの透明度を設定(0~1の範囲で指定)
page.Canvas.SetTransparency(0.2)
# 指定位置に画像を描画
page.Canvas.DrawImage(image, PointF(80.0, 200.0))
# ドキュメントを保存
pdf.SaveToFile("output/AddTranslucentPicture.pdf")
pdf.Close()
上記のコードでは、透明度0.2(20%)で画像がページに追加されます。これにより、背景との自然な重なりを実現できます。
実行結果プレビュー:
すでにPDF内に存在する画像の透明度を変更するには、その画像を取得して削除し、同じ位置に指定した透明度で再描画します。これにより、画像の位置を保ったまま不透明度を調整できます。手順は以下の通りです。
from spire.pdf import *
# PdfDocumentインスタンスを作成
pdf = PdfDocument()
# PDFファイルを読み込み
pdf.LoadFromFile("Sample.pdf")
# 1ページ目を取得
page = pdf.Pages.get_Item(0)
# ページ上の最初の画像とその位置を取得
imageHelper = PdfImageHelper()
imagesInfo = imageHelper.GetImagesInfo(page)
imageStream = imagesInfo[0].Image
bounds = imagesInfo[0].Bounds
# 元の画像を削除
imageHelper.DeleteImage(imagesInfo[0])
# ストリームから新しい画像を生成
image = PdfImage.FromStream(imageStream)
# 透明度を設定
page.Canvas.SetTransparency(0.3)
# 同じ位置に再描画
page.Canvas.DrawImage(image, bounds)
# ドキュメントを保存
pdf.SaveToFile("output/SetExistingImageTransparency.pdf")
pdf.Close()
この方法を使うことで、既存の画像を保持したまま透明度のみを変更できます。
実行結果プレビュー:

生成されたドキュメントから評価メッセージを削除したい場合、または機能制限を解除したい場合は、30日間の試用ライセンス を申請してください。
スタンプはPDFドキュメント内で特定のエリアやセクションをマーク・注釈するための強力なツールです。承認やレビュー、状態表示などに広く使用されており、チームでのコラボレーションや文書管理の効率を大幅に向上させます。PDFにおけるスタンプは、チェックマークのような単純なものから、カスタマイズされた画像、日時スタンプ、署名など、さまざまな形式を取ることができます。この記事では、Spire.PDF for Python を使用して PythonでPDFに画像スタンプおよび動的スタンプを追加する方法 を解説します。
この操作には Spire.PDF for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.PDF for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.PDF
Spire.PDF for Python では、PDFドキュメント内のゴム印(ラバースタンプ)を表すために PdfRubberStampAnnotation クラスを使用します。スタンプの外観を作成するには、PdfTemplate クラスを利用します。PdfTemplate はテキスト、画像、日付や時刻など任意の情報を描画できるキャンバスのようなものです。
画像スタンプは、ロゴ、署名、透かし、または任意のカスタムグラフィックをPDF上に重ねる用途に使えます。Spire.PDF for Python を使用して画像スタンプをPDFに追加する主な手順は以下の通りです。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocumentオブジェクトを作成
doc = PdfDocument()
# PDFを読み込み
doc.LoadFromFile("Sample.pdf")
# 指定ページを取得
page = doc.Pages[0]
# 画像ファイルを読み込み
image = PdfImage.FromFile("Stamp.png")
# 画像の幅と高さを取得
width = (float)(image.Width)
height = (float)(image.Height)
# 画像サイズに基づいてPdfTemplateオブジェクトを作成
template = PdfTemplate(width, height, True)
# テンプレート上に画像を描画
template.Graphics.DrawImage(image, 0.0, 0.0, width, height)
# ラバースタンプ注釈を作成(位置とサイズを指定)
rect = RectangleF((float)(page.ActualSize.Width - width - 50), (float)(10), width, height)
stamp = PdfRubberStampAnnotation(rect)
# PdfAppearanceオブジェクトを作成
pdfAppearance = PdfAppearance(stamp)
# テンプレートを外観の通常状態として設定
pdfAppearance.Normal = template
# スタンプに外観を適用
stamp.Appearance = pdfAppearance
# PDFにスタンプを追加
page.AnnotationsWidget.Add(stamp)
# ファイルを保存
doc.SaveToFile("output/ImageStamp.pdf")
doc.Close()
実行結果プレビュー:

PDFに画像スタンプを追加する方法を理解したら、PythonでPDFに画像を挿入する方法 もあわせてご覧ください。
静的スタンプとは異なり、動的スタンプは日付、時刻、ユーザー情報などの可変データを含むことができます。以下では、Spire.PDF for Python を使用してPDFに動的スタンプを作成する手順を説明します。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocumentオブジェクトを作成
doc = PdfDocument()
# PDFを読み込み
doc.LoadFromFile("Sample.pdf")
# 指定ページを取得
page = doc.Pages[0]
# PdfTemplateオブジェクトを作成
template = PdfTemplate(220.0, 50.0, True)
# フォントを作成
font1 = PdfTrueTypeFont("Yu Gothic UI", 16.0, 0, True)
font2 = PdfTrueTypeFont("Yu Mincho", 10.0, 0, True)
# ブラシを作成
solidBrush = PdfSolidBrush(PdfRGBColor(Color.get_Blue()))
rectangle1 = RectangleF(PointF(0.0, 0.0), template.Size)
linearGradientBrush = PdfLinearGradientBrush(rectangle1, PdfRGBColor(Color.get_White()), PdfRGBColor(Color.get_LightBlue()), PdfLinearGradientMode.Horizontal)
# ペンを作成
pen = PdfPen(solidBrush)
# 角丸矩形パスを作成
CornerRadius = 10.0
path = PdfPath()
path.AddArc(template.GetBounds().X, template.GetBounds().Y, CornerRadius, CornerRadius, 180.0, 90.0)
path.AddArc(template.GetBounds().X + template.Width - CornerRadius, template.GetBounds().Y, CornerRadius, CornerRadius, 270.0, 90.0)
path.AddArc(template.GetBounds().X + template.Width - CornerRadius, template.GetBounds().Y + template.Height - CornerRadius, CornerRadius, CornerRadius, 0.0, 90.0)
path.AddArc(template.GetBounds().X, template.GetBounds().Y + template.Height - CornerRadius, CornerRadius, CornerRadius, 90.0, 90.0)
path.AddLine(template.GetBounds().X, template.GetBounds().Y + template.Height - CornerRadius, template.GetBounds().X, template.GetBounds().Y + CornerRadius / 2)
# パスをテンプレート上に描画
template.Graphics.DrawPath(pen, path)
template.Graphics.DrawPath(linearGradientBrush, path)
# テンプレート上にテキストを描画
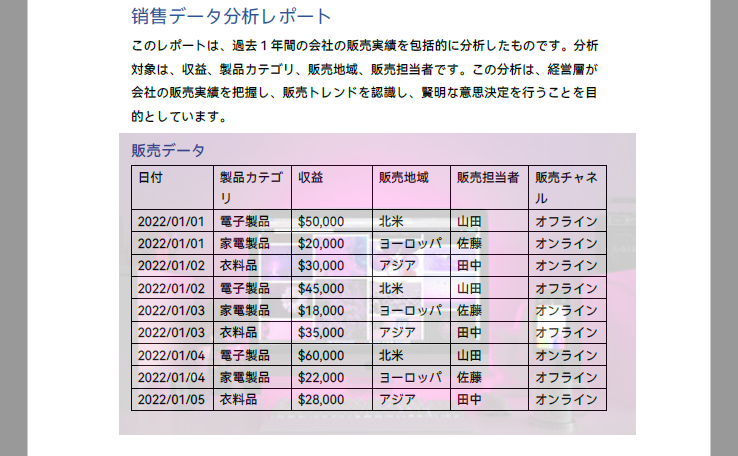
string1 = "承認済み\n"
string2 = "山田による承認時刻: " + DateTime.get_Now().ToString("HH:mm, MMM dd, yyyy")
template.Graphics.DrawString(string1, font1, solidBrush, PointF(5.0, 5.0))
template.Graphics.DrawString(string2, font2, solidBrush, PointF(2.0, 28.0))
# スタンプ注釈を作成(位置とサイズを指定)
rectangle2 = RectangleF((float)(page.ActualSize.Width - 220.0 - 50.0), (float)(page.ActualSize.Height - 60.0), 220.0, 50.0)
hanko = PdfRubberStampAnnotation(rectangle2)
# PdfAppearanceオブジェクトを作成し、テンプレートを通常状態に設定
appearance = PdfAppearance(hanko)
appearance.Normal = template
# 外観をスタンプに適用
hanko.Appearance = appearance
# スタンプを注釈コレクションに追加
page.AnnotationsWidget.Add(hanko)
# PDFを保存
doc.SaveToFile("output/DynamicStamp.pdf", FileFormat.PDF)
doc.Dispose()
実行結果プレビュー:
生成されたドキュメントから評価メッセージを削除したい場合、または機能制限を解除したい場合は、30日間の試用ライセンス を申請してください。
PDF に補足資料を直接組み込むことで、関連情報を 1 つのファイルにまとめられ、整理、共有、アーカイブが容易になります。この機能により、ユーザーは補助的なドキュメント、画像、マルチメディア要素をシームレスに共有でき、別々のファイル転送や外部リンクを必要としません。コミュニケーションの効率化、作業効率の向上、受信者が必要な資料に便利にアクセスできることを実現します。本記事では、Python と Spire.PDF for Python を使って PDF ドキュメントにファイルを添付する方法 を解説します。
この機能を使用するには、Spire.PDF for Pythonとplum-dispatch v1.7.4が必要です。Windows環境では、以下のpipコマンドで簡単にインストールできます。
pip install Spire.PDF
または、Spire.PDF for Pythonのダウンロードページから直接ダウンロードして、プロジェクトに追加することもできます。
PDF には一般的に 2 種類の添付方法があります。すなわち、ドキュメントレベルの添付と注釈添付です。Spire.PDF for Python は両方に対応しています。以下の表に両者の違いをまとめます。
| 添付タイプ | 表すクラス | 定義 |
|---|---|---|
| ドキュメントレベルの添付 | PdfAttachment クラス | PDF のドキュメントレベルに添付されたファイルはページ上には表示されませんが、PDF リーダーの「添付ファイル」パネルで確認できます。 |
| 注釈添付 | PdfAnnotationAttachment クラス | 注釈として添付されたファイルはページ上または「添付ファイル」パネルで確認可能です。注釈添付はページ上にクリップアイコンとして表示され、クリックするとファイルを開けます。 |
ドキュメントレベルで PDF にファイルを添付するには、まず外部ファイルに基づいて PdfAttachment オブジェクトを作成し、PdfDocument.Attachments.Add() メソッドを使って PDF ドキュメントに追加します。詳細な手順は以下の通りです。
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# サンプル PDF を読み込む
doc.LoadFromFile("Sample.pdf")
# 外部ファイルに基づき PdfAttachment オブジェクトを作成
attachment_one = PdfAttachment("Orders.xlsx")
attachment_two = PdfAttachment("Logo.png")
# PDF に添付ファイルを追加
doc.Attachments.Add(attachment_one)
doc.Attachments.Add(attachment_two)
# ファイルとして保存
doc.SaveToFile("output/DocumentAttachment.pdf")
出力 PDF のプレビューはこちらです。
おすすめ参考: Python で PDF に画像を追加する方法
注釈添付は PdfAttachmentAnnotation クラスで表されます。このクラスのインスタンスを作成し、境界、フラグ、テキストなどの属性を設定してから、PdfPageBase.AnnotationsWidget.Add() メソッドで指定ページに追加します。
Spire.PDF for Python を使用して注釈としてファイルを添付する手順は以下の通りです:
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# サンプル PDF を読み込む
doc.LoadFromFile("Sample.pdf")
# 特定のページを取得
page = doc.Pages[1]
# PDF に文字列を描画
str = "こちらがレポートです:"
font = PdfTrueTypeFont("Yu Gothic UI", 16.0, PdfFontStyle.Bold, True)
x = 50.0
y = doc.Pages[0].ActualSize.Height - 30.0
page.Canvas.DrawString(str, font, PdfBrushes.get_Blue(), x, y)
# 外部ファイルに基づき PdfAttachmentAnnotation オブジェクトを作成
data = Stream("Report.docx")
size = font.MeasureString(str)
bounds = RectangleF((x + size.Width + 5.0), y, 10.0, 15.0)
annotation = PdfAttachmentAnnotation(bounds, "Report.docx", data)
# 注釈の色、フラグ、アイコン、テキストを設定
annotation.Color = PdfRGBColor(Color.get_Blue())
annotation.Flags = PdfAnnotationFlags.Default
annotation.Icon = PdfAttachmentIcon.Graph
annotation.Text = "ファイルを開くにはクリック"
# 添付注釈を PDF に追加
page.AnnotationsWidget.Add(annotation)
# ファイルとして保存
doc.SaveToFile("output/AnnotationAttachment.pdf")
出力 PDF のプレビューはこちらです。
詳細参考: Python で PDF ページにアクションを追加する方法
生成されたドキュメントから評価メッセージを削除したり、機能制限を解除したい場合は、30 日間の試用ライセンスを申請してください。
PDF ドキュメントのインタラクティブ性と利便性を向上させる強力な機能の一つに、ドキュメント内でのアクションがあります。ドキュメント内にページ移動、ナビゲーション制御、あるいはメディア再生などのアクションを埋め込むことで、ユーザーは静的なドキュメントを動的なツールに変換でき、ワークフローの効率化、ユーザーのエンゲージメント向上、ルーチンタスクの自動化を実現できます。これにより、PDF の利用はこれまで以上に効率的かつ多用途になります。本記事では、Spire.PDF for Python を使って Python コードで PDF ドキュメントにアクションを作成する方法 を紹介します。
この機能を使用するには、Spire.PDF for Pythonとplum-dispatch v1.7.4が必要です。Windows環境では、以下のpipコマンドで簡単にインストールできます。
pip install Spire.PDF
または、Spire.PDF for Pythonのダウンロードページから直接ダウンロードして、プロジェクトに追加することもできます。
ナビゲーションボタンは、ユーザーがドキュメント内の指定ページの特定の位置にジャンプできるアクションです。開発者は PdfDestination オブジェクトを作成し、それを使って PdfGoToAction を作成し、さらにこのアクションに基づいて注釈を作成し、ページに追加することでナビゲーションボタンを完成させます。詳細な手順は以下の通りです:
from spire.pdf import *
# PdfDocument クラスのインスタンスを作成し PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# PdfDestination インスタンスを作成しプロパティを設定
destination = PdfDestination(pdf.Pages[0])
destination.Location = PointF(0.0, 0.0)
destination.Mode = PdfDestinationMode.Location
destination.Zoom = 0.8
# 矩形を作成
rect = RectangleF.FromLTRB(70, pdf.PageSettings.Size.Height - 120, 140, pdf.PageSettings.Size.Height - 100)
# PdfGoToAction インスタンスを作成
action = PdfGoToAction(destination)
# 2 ページ目に矩形を描画
pdf.Pages.get_Item(1).Canvas.DrawRectangle(PdfBrushes.get_LightGray(), rect)
# ボタンのテキストを描画
font = PdfTrueTypeFont("Yu Gothic UI", 12.0, PdfFontStyle.Regular, True)
stringFormat = PdfStringFormat(PdfTextAlignment.Center)
pdf.Pages.get_Item(1).Canvas.DrawString("ページ1に移動", font, PdfBrushes.get_Green(), rect, stringFormat)
# PdfActionAnnotation インスタンスを作成
annotation = PdfActionAnnotation(rect, action)
# 注釈を 2 ページ目に追加
pdf.Pages.get_Item(1).Annotations.Add(annotation)
# ドキュメントを保存
pdf.SaveToFile("output/AddPDFNavigationButton.pdf")
pdf.Close()
結果ドキュメントのプレビューはこちらです。
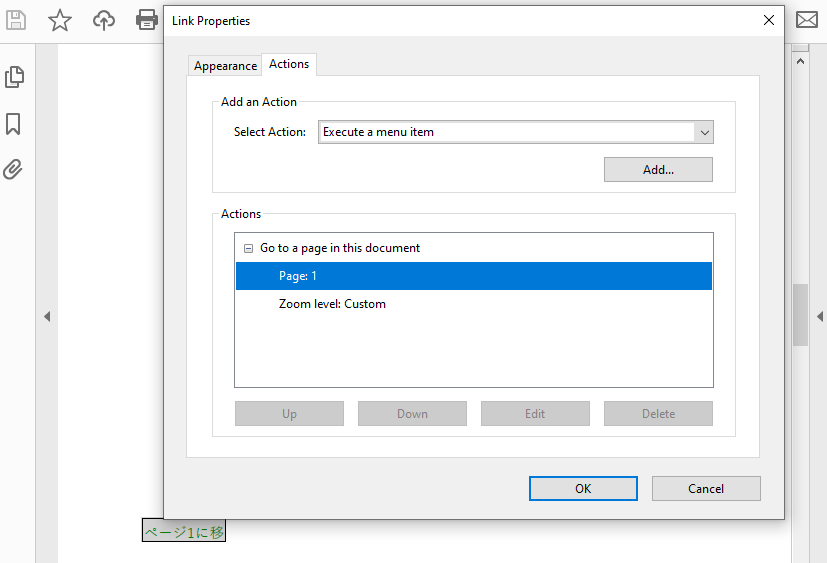
開発者は PDF ドキュメント内に音声をアクションとして埋め込むことができ、ユーザーが特定の操作を行ったとき(ファイルを開いたときやボタンをクリックしたときなど)に音声を再生できます。サウンドアクションを作成する手順は以下の通りです:
from spire.pdf import *
# PdfDocument インスタンスを作成し PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# ドキュメントの最初のページを取得
page = pdf.Pages.get_Item(0)
# サウンドファイルパスで PdfSoundAction インスタンスを作成
soundAction = PdfSoundAction("Wave.wav")
# 音声パラメータを設定
soundAction.Sound.Bits = 16
soundAction.Sound.Channels = PdfSoundChannels.Stereo
soundAction.Sound.Encoding = PdfSoundEncoding.Signed
soundAction.Sound.Rate = 44100
# 再生パラメータを設定
soundAction.Volume = 0.5
soundAction.Repeat = True
soundAction.Mix = True
soundAction.Synchronous = False
# ページに画像を描画
image = PdfImage.FromFile("Sound.png")
page.Canvas.DrawImage(image, PointF(30.0, 30.0))
# サウンドアクションで PdfActionAnnotation インスタンスを作成
rect = RectangleF.FromLTRB(30.0, 30.0, image.GetBounds().Width + 30.0, image.GetBounds().Height + 30.0)
annotation = PdfActionAnnotation(rect, soundAction)
# 注釈をページに追加
page.Annotations.Add(annotation)
# ドキュメントを開いた後にサウンドアクションを設定
# pdf.AfterOpenAction = soundAction
# ドキュメントを保存
pdf.SaveToFile("output/AddMusicPDF.pdf")
pdf.Close()
結果ドキュメントのプレビューはこちらです。
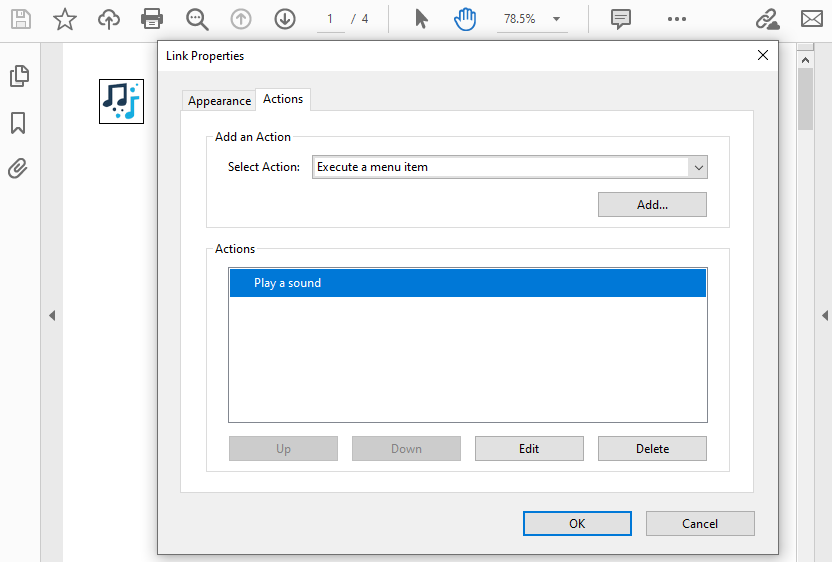
こちらもおすすめ:PythonでPDF内の画像を挿入、置換、または削除する方法
PdfLaunchAction クラスは PDF のファイルオープンアクションを表し、ユーザーが PDF ページ上のボタンをクリックすることで対応するファイルを開くことができます。開発者はファイルを開くための絶対パスまたは相対パス、および新しいウィンドウで開くかどうかを指定できます。PDF ドキュメントでファイルオープンアクションを作成する詳細手順は以下の通りです:
from spire.pdf import *
# PdfDocument クラスのインスタンスを作成
pdf = PdfDocument()
# PDF ファイルを読み込む
pdf.LoadFromFile("Sample.pdf")
# ドキュメントの最初のページを取得
page = pdf.Pages.get_Item(0)
# ページに矩形を描画
rect = RectangleF.FromLTRB(50, pdf.PageSettings.Size.Height - 100, 200, pdf.PageSettings.Size.Height - 80)
page.Canvas.DrawRectangle(PdfPens.get_LightGray(), rect)
# 矩形内にテキストを描画
page.Canvas.DrawString("Sample2 を開くにはクリック", PdfTrueTypeFont("Yu Gothic UI", 12.0, PdfFontStyle.Regular, True), PdfBrushes.get_Green(), rect, PdfStringFormat(PdfTextAlignment.Center))
# PdfLaunchAction オブジェクトを作成
action = PdfLaunchAction("Sample2.pdf", PdfFilePathType.Relative)
action.IsNewWindow = True
# アクションに基づいて PdfActionAnnotation オブジェクトを作成
annotation = PdfActionAnnotation(rect, action)
annotation.Color = PdfRGBColor(Color.get_Blue())
# 注釈をページに追加
page.Annotations.Add(annotation)
# ドキュメントを保存
pdf.SaveToFile("output/CreatePDFLaunchAction.pdf")
pdf.Close()
結果ドキュメントのプレビューはこちらです。
生成されたドキュメントから評価メッセージを削除したり、機能制限を解除したい場合は、30 日間の試用ライセンスを申請してください。
PythonでPDFから表を抽出するには、通常、行と列で構成された視覚的レイアウトを理解する必要があります。多くのPDF表はセル境界を使用して定義されており、プログラム的に検出しやすくなっています。そのような場合、単にテキストを読み取るのではなく、レイアウト情報を解析できるライブラリを使うことが、正確なPDF表の抽出には不可欠です。
このチュートリアルでは、OCRや機械学習を使用せずにPythonでPDFから表を抽出する信頼性の高い方法を解説します。PDFに格子状の表がある場合でも複雑なレイアウトでも、表データをExcelやpandas DataFrameなどの構造化形式に変換する手順を学べます。
目次
ExcelやCSVファイルとは異なり、PDFは表を構造化データとして保持していません。PythonでPDFから表を抽出するには、レイアウトを解析して表構造を検出できるライブラリが必要です。
Spire.PDF for Pythonは、ページごとに表を抽出するための組み込みメソッドを提供しており、明確にフォーマットされた表との相性が良く、PDFの内容をExcelやCSVなどの扱いやすいデータ形式に変換できます。
ライブラリのインストール方法:
pip install Spire.PDF
小規模なPDF表抽出には無料版も利用可能です:
pip install spire.pdf.free
PythonでPDFから表を抽出するには、まず文書を読み込み、各ページを個別に解析します。Spire.PDF for Pythonを使えば、レイアウト構造に基づいて表を検出し、プログラムで抽出できます。複数ページのPDFにも対応可能です。
以下は、PythonでPDFから表を読み取る基本例です。Spire.PDFを使い、文書の各ページから表を抽出します。プログラムで表データを扱いたい開発者に最適です。
from spire.pdf import PdfDocument, PdfTableExtractor
# PDF文書を読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# PdfTableExtractorオブジェクトを作成
table_extractor = PdfTableExtractor(pdf)
# 各ページの表を抽出
for i in range(pdf.Pages.Count):
tables = table_extractor.ExtractTable(i)
for table_index, table in enumerate(tables):
print(f"Page {i + 1} の Table {table_index + 1}:")
for row in range(table.GetRowCount()):
row_data = []
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ")
row_data.append(text.strip())
print("\t".join(row_data))
この方法は、境界線のある表に対して信頼性があります。ただし、境界線のない表や複数行セル、未マークのヘッダーを含む表では、抽出が正確に行えない場合があります。
抽出結果の例:
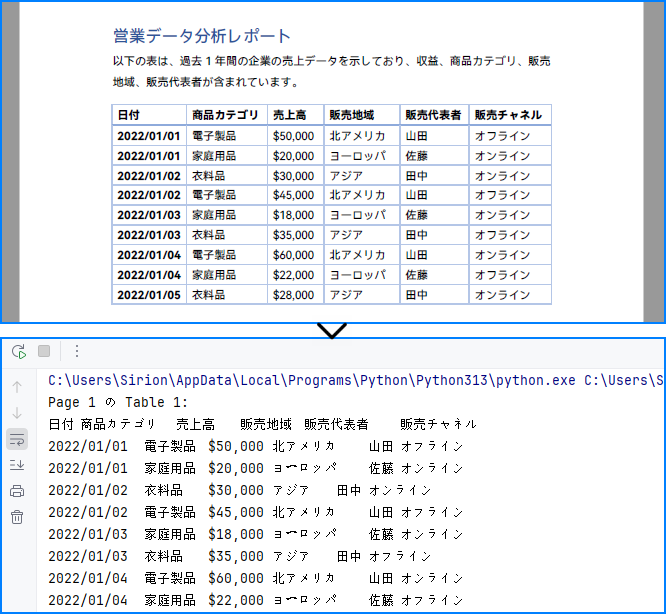
抽出したPDF表を分析や保存したい場合、PythonでExcelやCSVに変換できます。この例ではSpire.XLS for Pythonを使い、各表をスプレッドシートに出力します。
pipでのインストール:
pip install spire.xls
PDF表をExcel/CSVに出力するコード例
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.xls import Workbook, FileFormat
# PDF文書を読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 抽出器とExcelワークブックを設定
extractor = PdfTableExtractor(pdf)
workbook = Workbook()
workbook.Worksheets.Clear()
# ページごとに表を抽出
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
for t_index, table in enumerate(tables):
sheet = workbook.Worksheets.Add(f"Page{page_index+1}_Table{t_index+1}")
for row in range(table.GetRowCount()):
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ").strip()
sheet.Range.get_Item(row + 1, col + 1).Value = text
sheet.AutoFitColumn(col + 1)
# すべての表を1つのExcelファイルに保存
workbook.SaveToFile("output/Sample.xlsx", FileFormat.Version2016)
下記のように、抽出したPDFの表はSpire.XLS for Pythonを使用してExcelやCSVに変換されます。
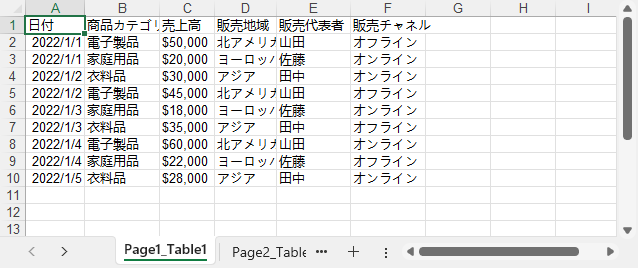
複雑なレイアウトや改ページ、フォーマットの不一致により、PDFからの表抽出は完全でない場合があります。Pythonでより正確な結果を得るための実用的な方法を紹介します。
Spire.PDFはページ単位で表を抽出します。表が複数ページにまたがる場合、行を結合して対応できます。
# 表を抽出して結合
combined_rows = []
for i in range(start_page, end_page + 1):
tables = table_extractor.ExtractTable(i)
if tables:
table = tables[0] # ページごとに1つの表を想定
for row in range(table.GetRowCount()):
cells = [table.GetText(row, col).strip().replace("\n", " ") for col in range(table.GetColumnCount())]
combined_rows.append(cells)
結合後、ExcelやCSVに変換して分析できます。
表には空行や空列が含まれることがあります。抽出前にフィルタリングすると精度が向上します。
# 空行を除外
filtered_rows = []
for row in range(table.GetRowCount()):
row_data = [table.GetText(row, col).strip().replace("\n", " ") for col in range(table.GetColumnCount())]
if any(cell for cell in row_data):
filtered_rows.append(row_data)
# 空列を除外
transposed = list(zip(*filtered_rows))
filtered_columns = [col for col in transposed if any(cell.strip() for cell in col)]
filtered_data = list(zip(*filtered_columns))
これにより、雑多なレイアウトでもより正確な表抽出が可能です。
はい、PdfTextExtractorでページ全体のテキストを取得し、PdfTableExtractorで構造化された表を抽出できます。
PDFがテキストベース(スキャン画像ではない)であり、行列形式のレイアウトになっていることを確認してください。Spire.PDF for Pythonは境界線付き表のみを検出します。境界線のない表は認識されない場合があります。
画像ベースPDFの場合、Spire.OCR for Pythonを使用して表データを抽出できます。詳細は「Pythonで画像からテキストを抽出する方法」を参照してください。
Spire.PDFでは境界線のない表の抽出は難しい場合があります。以下の方法を検討してください:
PdfTextExtractorでテキストを抽出し、行列を特定するカスタムロジックを作成Spire.PDFには直接DataFrame出力はありませんが、セル値をリストのリストに格納してから変換可能です。
import pandas as pd
df = pd.DataFrame(table_data)
これにより、PythonでPDF表をDataFrameに変換して分析できます。
はい、以下の2つのオプションがあります:
構造化されたレポートや財務データ、標準フォームなど、PythonでPDF表を抽出すると作業効率が大幅に向上します。Spire.PDF for Pythonのようなレイアウト認識型パーサを使えば、OCRや手動調整なしで表を正確に検出・抽出可能です。Excel、CSV、DataFrameに変換すれば、自動化やデータ分析にすぐ活用できます。
総じて、Spire.PDFを使ったPythonによるPDF表抽出は、ExcelやCSVなどの構造化形式への変換を通じて、分析や自動処理に非常に便利です。

PDF ファイルには、グラフ、図、スキャン画像などの重要なビジュアル情報が含まれていることが多くあります。
開発者にとって、PythonでPDFから画像を抽出する方法を知っておくことは、レポートの自動生成や画像解析、OCR などの機械学習タスクにおいて非常に有用です。
この記事では、Spire.PDF for Python を利用して、Python で PDF から画像を抽出する方法を次の観点から詳しく紹介します。
Python で Spire.PDF を使用して PDF から画像を抽出する前に、以下の準備を行ってください。
Python 環境:システムに Python がインストールされていることを確認します。
最新の安定版を使用することで、より良い互換性とパフォーマンスが得られます。
Python公式サイト からダウンロード可能です。
Spire.PDF for Python ライブラリ:
Python 用の PDF SDK をインストールします。pip を使うのが最も簡単です。
コマンドプロンプトまたはターミナルで以下を実行します:
pip install Spire.PDF
Spire.PDF をインストールしたら、すぐに PDF ドキュメントから画像を抽出できるようになります。 以下の例では、ページ単位および全ページから画像を抽出する方法を順に紹介します。
次のコードは、PDF の特定ページに含まれるすべての画像を抽出して保存する完全なスクリプトです。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
pdf = PdfDocument()
# PDFファイルを読み込む
pdf.LoadFromFile("template1.pdf")
# 最初のページを取得
page = pdf.Pages[0]
# PdfImageHelper インスタンスを作成
imageHelper = PdfImageHelper()
# ページ上の画像情報を取得
imageInfo = imageHelper.GetImagesInfo(page)
# 取得した画像情報をループ処理して保存
for i in range(0, len(imageInfo)):
imageInfo[i].Image.Save("Images/Image" + str(i) + ".png")
# リソースを解放
pdf.Dispose()
ポイント解説:
出力例プレビュー:
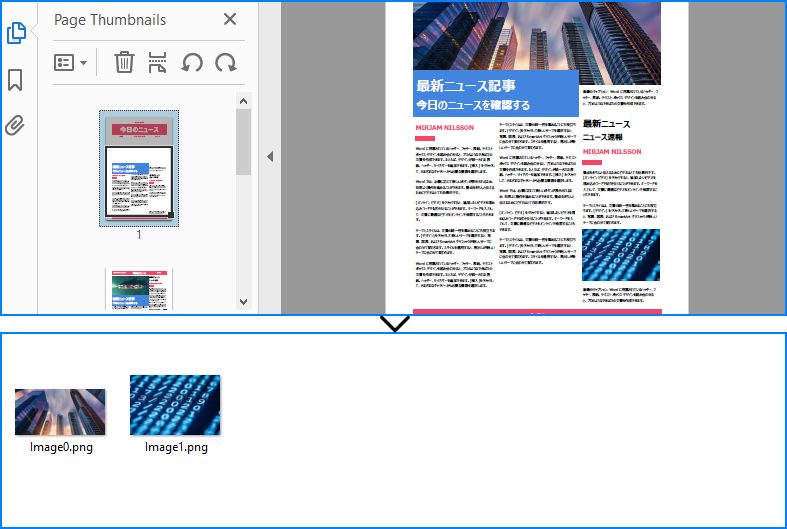
単一ページからの抽出を拡張し、すべてのページをループして全画像を抽出することも可能です。 以下のスクリプトでは、PDF 全体からすべての埋め込み画像を取得します。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
pdf = PdfDocument()
# PDFファイルを読み込む
pdf.LoadFromFile("template1.pdf")
# PdfImageHelper インスタンスを作成
imageHelper = PdfImageHelper()
# すべてのページをループ
for i in range(0, pdf.Pages.Count):
page = pdf.Pages[i]
imageInfo = imageHelper.GetImagesInfo(page)
for j in range(0, len(imageInfo)):
imageInfo[j].Image.Save(f"Images\\Page{i + 1}_Image{j + 1}.png")
# PDFを閉じる
pdf.Close()
出力例プレビュー:
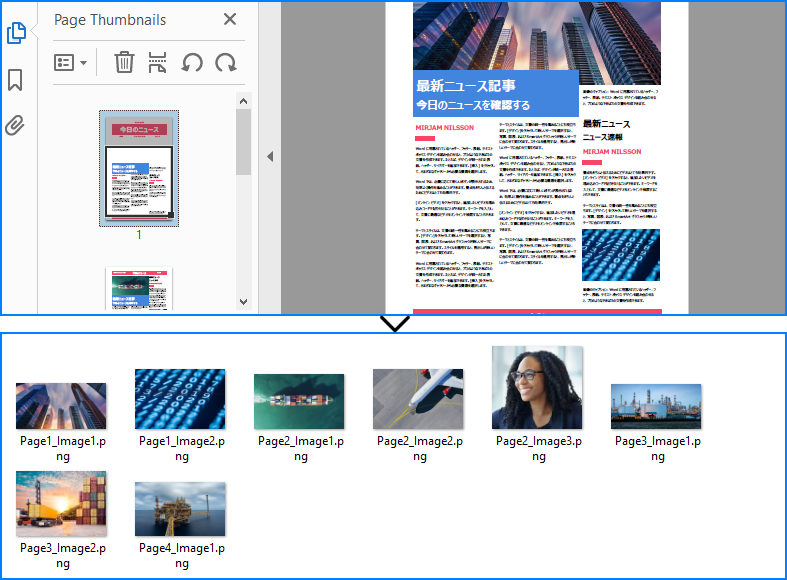
PDF内の画像をさらに操作したい場合は、PythonでPDFに画像を追加・置換・削除する方法の記事も参考にしてください。
Spire.PDF for Python は、PNG、JPG/JPEG、BMP などさまざまな画像形式の抽出をサポートしています。 抽出した画像を保存する際、用途に合わせて最適なフォーマットを選択することができます。
主な画像形式と特徴:
| 形式 | 主な用途 | 備考 |
|---|---|---|
| JPG/JPEG | 写真・スキャン画像 | 圧縮で若干の劣化あり。PDFで最も一般的。 |
| PNG | 図表・スクリーンショット | 透過保持。ファイルサイズはやや大きめ。 |
| BMP | 一時保存やWindowsアプリ用 | 現在のPDFではまれ。Web用途には不向き。 |
| TIFF | 保存・印刷・OCR入力 | アーカイブや文書保存向け。複数ページ対応。 |
| EMF | ベクター画像編集 | IllustratorやInkscapeで編集可能。 |
Spire.PDF for Python には無料版と商用版があります。 Free Spire.PDF for Python は、1ファイルあたり最大10ページなどの制限があります。 制限のない試用版ライセンスを希望する場合は、こちらから申請してください。
可能です。全ページをループする代わりに、抽出したいページのインデックスを指定します。 例えば 2~5 ページの画像を抽出するには次のように書きます。
# ページ2~5の画像を抽出(ページは0始まり)
for i in range(1, 4):
page = pdf.Pages[i]
# 上記と同じ処理を実行
はい。スキャンPDFのように画像内に文字が含まれている場合は、Spire.OCR for Python を組み合わせることで、抽出画像から文字認識を行うことができます。
PythonでPDFから画像を抽出する作業は、Spire.PDF for Python を使うことで簡単かつ効率的に実現できます。 この記事で紹介したサンプルコードを活用すれば、特定ページや全ページから画像を抽出し、任意の形式で保存することが可能です。 さらに、OCRツールと組み合わせることで、画像からテキストを自動的に抽出することもできます。
この機能を活用すれば、レポート作成や画像解析などの業務効率を大幅に向上させ、PDFに埋め込まれたビジュアルデータを柔軟に再利用できます。

PDF ドキュメントには、まれに空白ページが含まれていることがあります。こうしたページは閲覧体験を損なうだけでなく、ファイルサイズを無駄に大きくしたり、印刷時に紙の無駄を生む原因にもなります。
PDF の品質とプロフェッショナリズムを高めるためには、空白ページを検出して削除することが重要です。
この記事では、Python と Spire.PDF for Python、さらに Pillow を利用して、見た目にも正確に空白ページを検出・削除する方法を解説します。
見た目は空白でも実際には不可視要素(透明オブジェクトや白文字など)が含まれているケースにも対応します。
記事の構成
このチュートリアルでは、以下の2つの Python ライブラリを使用します:
インストールは次のコマンドで簡単に行えます:
pip install Spire.PDF Pillow
Spire.PDF には、ページが完全に空であるかどうかを確認できる PdfPageBase.IsBlank() メソッドが用意されています。 しかし、ページによっては一見空白に見えても、白文字のテキストや透過画像、透かしなどが含まれている場合があります。 そのため、このメソッドだけでは正確に空白ページを検出できないケースがあります。
より精度を高めるために、この記事では次の2段階の検出方法を採用します:
注意点: PDF を画像に変換する際、有効なライセンスを適用していないと評価版の透かしが画像に追加されます。 これが検出結果に影響する可能性があるため、テスト時は一時ライセンスの取得をおすすめします。
一時ライセンスは E-iceblue セールスチーム へお問い合わせください。
また、小規模な処理であれば、透かしなしで基本機能を利用できる Free Spire.PDF for Python を使うこともできます。
以下の手順で空白ページの検出と削除を実装します。
空白画像を判定する関数 is_blank_image() を定義する Pillow を使用して、ページを画像に変換した結果が真っ白(全ピクセルが白)かどうかを判定します。
PDFドキュメントを読み込む PdfDocument.LoadFromFile() メソッドを使って PDF ファイルを読み込みます。
ページを順に確認する 各ページをループ処理で確認し、次の2つの条件をチェックします:
処理結果のPDFを保存する PdfDocument.SaveToFile() メソッドを使って、空白ページを削除した新しいPDFを保存します。
サンプルコード:
import io
from spire.pdf import PdfDocument
from PIL import Image
# ライセンスキーの適用
License.SetLicenseKey("License-Key")
# 画像が空白かどうかを確認する関数
def is_blank_image(image):
img = image.convert("RGB")
white_pixel = (255, 255, 255)
return all(pixel == white_pixel for pixel in img.getdata())
# PDFを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample1111.pdf")
# 削除時のインデックスずれを防ぐため、逆順でページを確認
for i in range(pdf.Pages.Count - 1, -1, -1):
page = pdf.Pages[i]
if page.IsBlank():
pdf.Pages.RemoveAt(i)
else:
with pdf.SaveAsImage(i) as image_data:
image_bytes = image_data.ToArray()
pil_image = Image.open(io.BytesIO(image_bytes))
if is_blank_image(pil_image):
pdf.Pages.RemoveAt(i)
# 結果を保存
pdf.SaveToFile("RemoveBlankPages.pdf")
pdf.Close()
以下は、空白ページ削除後のプレビューです:
A:完全に何もないページのほか、白文字や透過オブジェクト、透かしなど見えない要素を含むページも空白ページとみなされます。 このソリューションでは、2段階の検出で両方のケースに対応します。
A:はい、ライセンスなしでも動作します。ただし、PDFを画像に変換する際に評価版の透かしが追加されるため、空白ページ検出の精度に影響する可能性があります。 テスト用途の場合は、無料の一時ライセンスを申請するのがおすすめです。
A:Spire.PDF for Python は Python 3.7以降 に対応しています。画像解析を行う場合は、Pillow も併せてインストールしてください。
A:可能です。pdf.Pages.RemoveAt(i) の行をコメントアウトし、print() や logging で空白ページのリストを出力するだけでOKです。
PDF から不要な空白ページを削除することは、可読性の向上やファイルサイズの削減、そしてよりプロフェッショナルな仕上がりに欠かせない工程です。 Spire.PDF for Python と Pillow を組み合わせることで、完全に空のページだけでなく、見た目は空白でも内部に不可視要素を含むページも正確に検出できます。
レポート生成、スキャン文書の整理、印刷前の最終調整など、あらゆるシーンで役立つ実用的な Python ソリューションです。
SVG ファイルは、拡大縮小や調整が容易であることから、Web グラフィックスやベクター形式のイラストによく利用されます。一方 PDF は、さまざまなデバイスや OS で幅広くサポートされている汎用性の高い形式です。SVG を PDF に変換することで、受け取る側が特別なソフトウェアを用意したり、ブラウザの互換性を気にする必要なく、グラフィックスやイラストを簡単に共有できます。本記事では、Python で SVG ファイルを PDF 形式に変換する方法を Spire.PDF for Python を用いて解説します。
目次
この操作には Spire.PDF for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.XLS for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.PDF
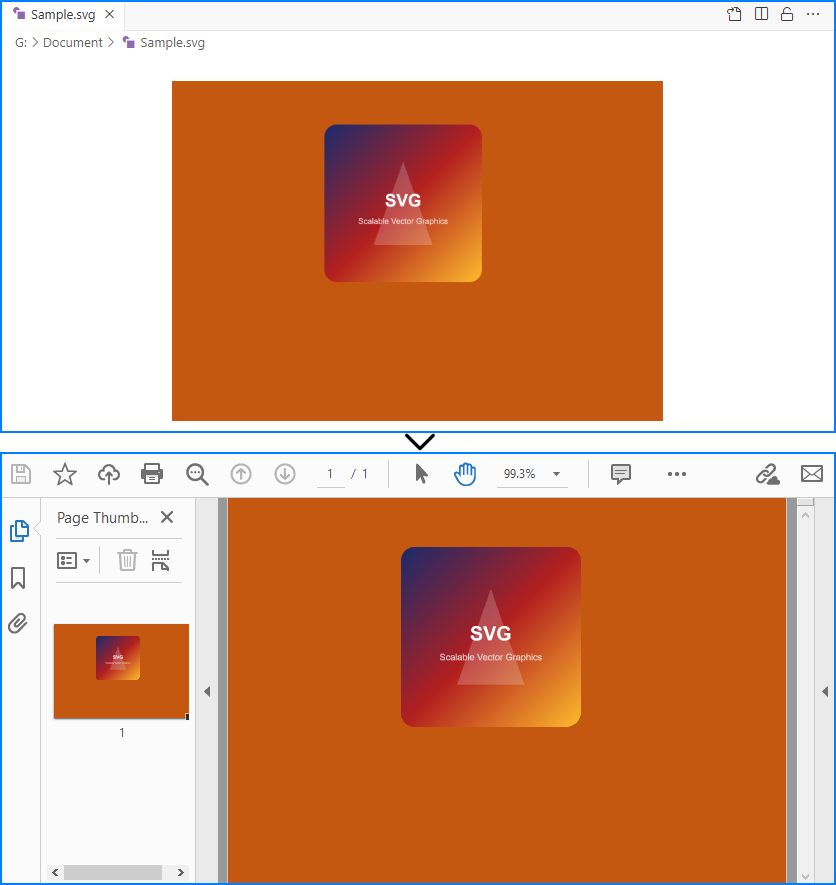
Spire.PDF for Python では、PdfDocument.LoadFromSvg() メソッドを使用して SVG ファイルを読み込み、PdfDocument.SaveToFile() メソッドで PDF として保存できます。手順は以下の通りです。
from spire.pdf import PdfDocument, FileFormat
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# SVG ファイルを読み込む
doc.LoadFromSvg("Sample.svg")
# SVG を PDF 形式に保存
doc.SaveToFile("output/ConvertSvgToPdf.pdf", FileFormat.PDF)
# PdfDocument オブジェクトを閉じる
doc.Close()
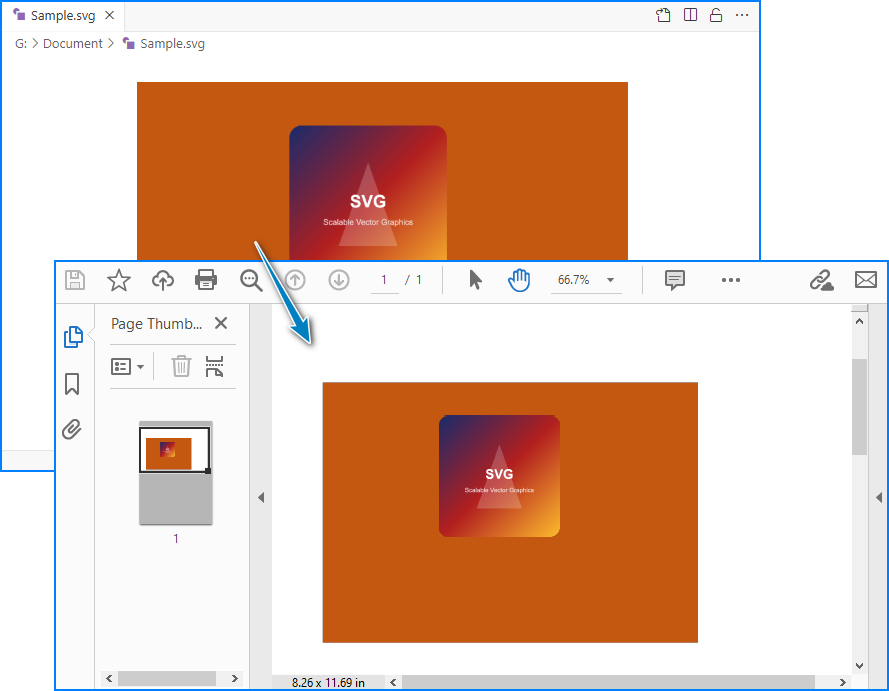
Spire.PDF for Python では、SVG を PDF に直接変換するだけでなく、既存の PDF に任意の位置へ追加することも可能です。手順は以下の通りです。
from spire.pdf import PdfDocument, PointF, FileFormat
# PdfDocument オブジェクトを作成
doc1 = PdfDocument()
# SVG ファイルを読み込む
doc1.LoadFromSvg("Sample.svg")
# SVG 内容を基にテンプレートを作成
template = doc1.Pages.get_Item(0).CreateTemplate()
# 別の PdfDocument オブジェクトを作成
doc2 = PdfDocument()
page = doc2.Pages.Add()
# 読み込んだ PDF の 1 ページ目に、テンプレートを指定位置に描画
page.Canvas.DrawTemplate(template, PointF(10.0, 100.0))
# 結果を保存
doc2.SaveToFile("output/AddSvgToPdf.pdf", FileFormat.PDF)
# PdfDocument オブジェクトを閉じる
doc2.Close()
doc1.Close()
もし PDF に他の種類の画像を挿入したい場合は、Python で PDF に画像を追加・削除・置換する方法をご参照ください。
生成した文書から評価用の透かしを削除したい場合や、機能制限を解除したい場合は、30 日間有効の試用ライセンスを申請してください。

Excel ワークシートのセルに数値書式を設定することは、データ管理や可視化において欠かせない作業です。適切な数値書式を設定することで、データの可読性が向上し、一貫性が保たれ、正確なデータ分析を行いやすくなります。通貨、パーセンテージ、日付、科学的記数法など異なる種類の数値データを直感的に区別できるため、大量のデータを一目で理解しやすくなります。この記事では、Python プログラムで Spire.XLS for Python を使用して Excel ワークシートのセルに数値書式を自動設定する方法 を解説します。
この操作には、Spire.XLS for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.XLS for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.XLS
Excel では、セルの数値書式は「書式コード」によって決まります。開発者は書式コードの中でさまざまな記号を利用して、数値、日付や時刻、通貨などの表示形式を定義できます。以下は代表的な記号です:
Spire.XLS for Python では、セルに数値を設定するために CellRange.NumberValue プロパティを、数値書式を設定するために CellRange.NumberFormat プロパティを使用します。
以下のコード例では、数値、パーセンテージ、通貨、日付、時刻、科学的記数法など、さまざまな数値書式をセルに適用する方法を示します。
from spire.xls import *
from spire.xls.common import *
# Workbook を作成
workbook = Workbook()
# 最初のワークシートを取得
sheet = workbook.Worksheets.get_Item(0)
# ヘッダー行を設定
sheet.Range["B9"].Text = "数値書式"
sheet.Range["C9"].Text = "値"
sheet.Range["D9"].Text = "表示"
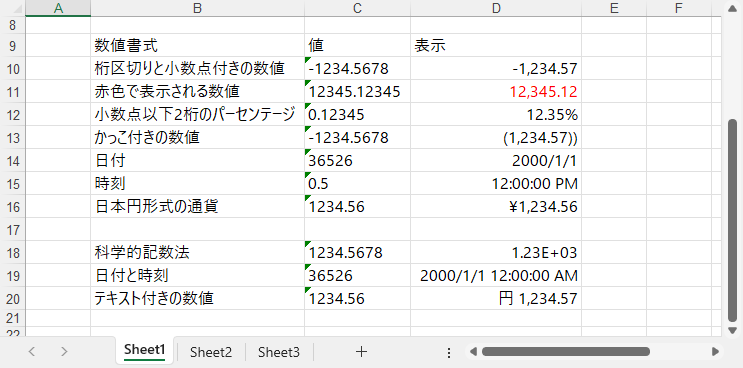
# 桁区切りと小数点付きの数値
sheet.Range["B10"].Text = "桁区切りと小数点付きの数値"
sheet.Range["C10"].Text = "-1234.5678"
sheet.Range["D10"].NumberValue = -1234.5678
sheet.Range["D10"].NumberFormat = "#,##0.00"
# 赤色で表示される数値
sheet.Range["B11"].Text = "赤色で表示される数値"
sheet.Range["C11"].Text = "12345.12345"
sheet.Range["D11"].NumberValue = 12345.12345
sheet.Range["D11"].NumberFormat = "[Red]#,##0.00"
# 小数点以下2桁のパーセンテージ
sheet.Range["B12"].Text = "小数点以下2桁のパーセンテージ"
sheet.Range["C12"].Text = "0.12345"
sheet.Range["D12"].NumberValue = 0.12345
sheet.Range["D12"].NumberFormat = "0.00%"
# かっこ付きの数値
sheet.Range["B13"].Text = "かっこ付きの数値"
sheet.Range["C13"].Text = "-1234.5678"
sheet.Range["D13"].NumberValue = -1234.5678
sheet.Range["D13"].NumberFormat = "(#,##0.00;(#,##0.00))"
# 日付
sheet.Range["B14"].Text = "日付"
sheet.Range["C14"].Text = "36526"
sheet.Range["D14"].NumberValue = 36526
sheet.Range["D14"].NumberFormat = "yyyy/m/d"
# 時刻
sheet.Range["B15"].Text = "時刻"
sheet.Range["C15"].Text = "0.5"
sheet.Range["D15"].NumberValue = 0.5
sheet.Range["D15"].NumberFormat = "h:mm:ss AM/PM"
# 日本円形式の通貨
sheet.Range["B16"].Text = "日本円形式の通貨"
sheet.Range["C16"].Text = "1234.56"
sheet.Range["D16"].NumberValue = 1234.56
sheet.Range["D16"].NumberFormat = "¥#,##0.00"
# 科学的記数法
sheet.Range["B18"].Text = "科学的記数法"
sheet.Range["C18"].Text = "1234.5678"
sheet.Range["D18"].NumberValue = 1234.5678
sheet.Range["D18"].NumberFormat = "0.00E+00"
# 日付と時刻
sheet.Range["B19"].Text = "日付と時刻"
sheet.Range["C19"].Text = "36526"
sheet.Range["D19"].NumberValue = 36526
sheet.Range["D19"].NumberFormat = "yyyy/m/d h:mm:ss AM/PM"
# テキスト付きの数値
sheet.Range["B20"].Text = "テキスト付きの数値"
sheet.Range["C20"].Text = "1234.56"
sheet.Range["D20"].NumberValue = 1234.5678
sheet.Range["D20"].NumberFormat = "\"円 \"#,##0.00"
# フォントサイズを設定し、行と列を自動調整
sheet.AllocatedRange.Style.Font.Size = 13
sheet.AllocatedRange.AutoFitRows()
sheet.AllocatedRange.AutoFitColumns()
# ファイルを保存
workbook.SaveToFile("output/SetNumberFormatExcel.xlsx", FileFormat.Version2016)
workbook.Dispose()
適切な数値書式を設定することは、値を直感的に理解できるように表示するための基盤であり、プロフェッショナルな Excel レポートを作成する第一歩です。
生成された Excel ファイルのプレビュー:
数値書式は、Excel セル内の数値表示を制御します。Excel レポートをより見やすく、プロフェッショナルなものに仕上げるには、数値だけでなく書式設定にもしっかり取り組むことが重要です。さらに詳しい書式設定の方法については、「Python で Excel の書式を設定する方法」をご参照ください。
Excel セルに数値書式を設定することで、データはより直感的でわかりやすく表示され、ビジネスレポートの品質も大きく向上します。Python と Spire.XLS を活用すれば、手作業では時間のかかる書式設定も自動化でき、効率的かつ一貫性のあるレポート作成が可能になります。
数値の見せ方は単なる装飾ではなく、データを正しく伝えるための重要な要素です。ぜひ今回紹介した方法を活用し、よりプロフェッショナルな Excel レポートを作成してみてください。なお、すべての機能を利用する場合は 無料の一時ライセンスを申請する か、まずは 無料版をダウンロードする ことをおすすめします。

Excel は、データの整理・分析・可視化において最も広く利用されているツールのひとつです。財務報告書から業務ダッシュボードに至るまで、多くのワークフローで Excel へのデータ出力が必要とされます。手動で情報を入力する代わりに、Python で Excel ファイルを書き込む処理を自動化すれば、処理がより迅速で、信頼性が高く、スケーラブルになります。
本チュートリアルでは、Python を使って Excel ファイルにデータを書き込む方法を解説します。構造化データの挿入、書式設定、エクスポートまでをカバーしており、例ではプログラムからワークブックを生成・カスタマイズできる Python の Excel ライブラリを使用しています。
本チュートリアルの内容:
Python で Excel ファイルを書き込むには、ワークブックの作成・読み込み・保存をプログラム的に行えるライブラリが必要です。Spire.XLS for Python はこれらの操作に対応した完全な API を提供し、レポート作成やデータ処理を自動化できます。
pip を使ってインストールします:
pip install spire.xls
インストール後は、次の 3 つの基本操作が可能になります:
これらの操作が、Python におけるデータ書き込み、書式設定、複数シート管理の基礎となります。
実際のビジネスシーンでは、新しい Excel ファイルの作成、既存レポートの更新、テキスト・数値・日付・数式などさまざまな種類のデータ書き込みが必要です。このセクションでは、これらのケースにおける効率的な Python での Excel データ操作を紹介します。
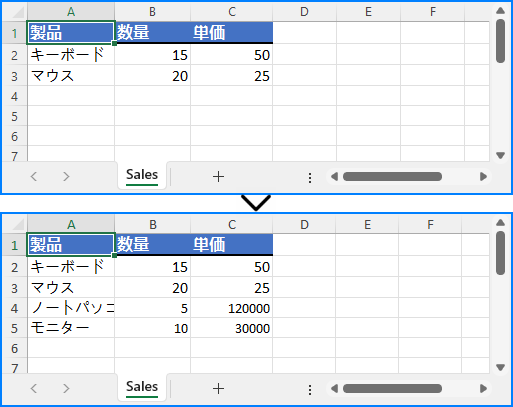
最新の売上データや在庫情報などを既存の Excel ワークブックに追記したい場合、ファイルを開いてプログラムで新しいデータ行を追加し、既存の内容を保持したまま保存できます。
from spire.xls import Workbook, ExcelVersion
workbook = Workbook()
workbook.LoadFromFile("Sample.xlsx")
sheet = workbook.Worksheets[0]
# 新しい行を追加
sheet.Range["A4"].Value = "ノートパソコン"
sheet.Range["B4"].NumberValue = 5
sheet.Range["C4"].NumberValue = 120000
sheet.Range["A5"].Value = "モニター"
sheet.Range["B5"].NumberValue = 10
sheet.Range["C5"].NumberValue = 30000
workbook.SaveToFile("output/updated_excel.xlsx", ExcelVersion.Version2016)
ポイントとなる要素:
この方法により、既存のレポートを保持したまま継続的にデータを更新できます。
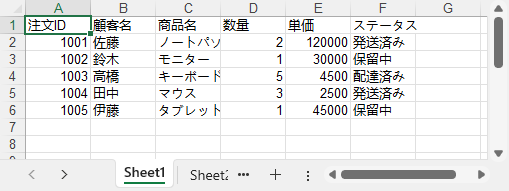
大規模なデータセットを扱う場合、セル単位で更新するよりも複数行・列を一括で書き込む方が効率的です。この方法は処理速度の向上だけでなく、ワークシート全体のデータ整合性を確保できます。
from spire.xls import Workbook, ExcelVersion
# 新しい Excel ワークブックを作成
workbook = Workbook()
sheet = workbook.Worksheets[0]
orders = [
["注文ID", "顧客名", "商品名", "数量", "単価", "ステータス"],
[1001, "佐藤", "ノートパソコン", 2, 120000, "発送済み"],
[1002, "鈴木", "モニター", 1, 30000, "保留中"],
[1003, "高橋", "キーボード", 5, 4500, "配達済み"],
[1004, "田中", "マウス", 3, 2500, "発送済み"],
[1005, "伊藤", "タブレット", 1, 45000, "保留中"]
]
for row_index, row_data in enumerate(orders, start=1):
for col_index, value in enumerate(row_data, start=1):
if isinstance(value, (int, float)):
sheet.Range[row_index, col_index].NumberValue = value
else:
sheet.Range[row_index, col_index].Value = value
workbook.SaveToFile("output/orders.xlsx", ExcelVersion.Version2016)
注目すべき要素:
バッチ書き込みは、データベースのクエリ結果や業務レポートのエクスポートに特に有効です。
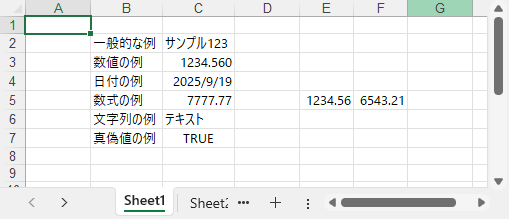
Excel のセルは、テキスト・数値・日付・数式など多様なデータ型を扱えます。正しいプロパティを使うことで、各データ型が適切に保存・表示され、計算や書式設定が正確に行われます。
from spire.xls import Workbook, ExcelVersion, DateTime, TimeSpan
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 一般的な値
sheet.Range[2, 2].Text = "一般的な例"
sheet.Range[2, 3].Value = "サンプル123"
# 数値
sheet.Range[3, 2].Text = "数値の例"
sheet.Range[3, 3].NumberValue = 1234.56
sheet.Range[3, 3].NumberFormat = "0.000"
# 日付
sheet.Range[4, 2].Text = "日付の例"
sheet.Range[4, 3].DateTimeValue = DateTime.get_UtcNow()
# 数式
sheet.Range[5, 2].Text = "数式の例"
sheet.Range[5, 5].NumberValue = 1234.56
sheet.Range[5, 6].NumberValue = 6543.21
sheet.Range[5, 3].Formula = "=SUM(E5:F5)"
# テキスト
sheet.Range[6, 2].Text = "文字列の例"
sheet.Range[6, 3].Text = "テキスト"
# 真偽値
sheet.Range[7, 2].Text = "真偽値の例"
sheet.Range[7, 3].BooleanValue = True
sheet.AllocatedRange.Style.Font.FontName = "Yu Gothic UI"
sheet.AllocatedRange.AutoFitColumns()
workbook.SaveToFile("output/value_types.xlsx", ExcelVersion.Version2016)
主な関数・プロパティ:
異なるデータ型を正しく扱うことは、ビジネス計算やレポートの精度を維持するために不可欠です。対応するデータ型の詳細は XlsRange API リファレンス を参照してください。
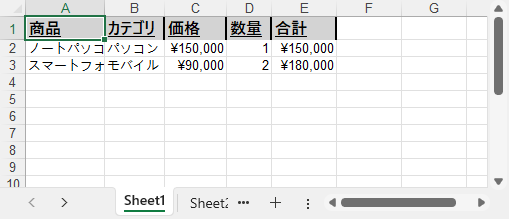
Excel レポートをわかりやすく、プロフェッショナルに仕上げるには、データ入力や更新と同時に書式を適用することが重要です。このセクションでは、セルのスタイル、数値フォーマット、列幅・行高の調整方法を解説します。
フォント・罫線・背景色などのスタイルを適用することで、シートの可読性と視覚的な訴求力を高められます。
from spire.xls import Workbook, Color, FontUnderlineType, ExcelVersion, BordersLineType, LineStyleType
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 見出し
sheet.Range["A1"].Value = "商品"
sheet.Range["B1"].Value = "カテゴリ"
sheet.Range["C1"].Value = "価格"
sheet.Range["D1"].Value = "数量"
sheet.Range["E1"].Value = "合計"
# データ行
sheet.Range["A2"].Value = "ノートパソコン"
sheet.Range["B2"].Value = "パソコン"
sheet.Range["C2"].NumberValue = 150000
sheet.Range["D2"].NumberValue = 1
sheet.Range["E2"].Formula = "=C2*D2"
sheet.Range["A3"].Value = "スマートフォン"
sheet.Range["B3"].Value = "モバイル"
sheet.Range["C3"].NumberValue = 90000
sheet.Range["D3"].NumberValue = 2
sheet.Range["E3"].Formula = "=C3*D3"
# ヘッダーのスタイル
header = sheet.Range["A1:E1"]
header.Style.Font.FontName = "Yu Gothic UI"
header.Style.Font.Size = 12.0
header.Style.Font.IsBold = True
header.Style.Font.Underline = FontUnderlineType.Single
header.Style.Interior.Color = Color.get_LightGray()
header.Style.Borders[BordersLineType.EdgeRight].LineStyle = LineStyleType.Medium
主な構成要素:
スタイルを使うことで、重要な部分を強調し、レポート全体の見栄えを向上させられます。
数値はフォーマットを適切に指定することで、通貨・パーセンテージ・整数など読みやすい形で表示できます。CellRange.NumberFormat を利用して、値の見せ方を制御します。
# 数値のフォーマット(円表示)
sheet.Range["C2:C3"].NumberFormat = "¥#,##0" # 通貨
sheet.Range["D2:D3"].NumberFormat = "0" # 整数
sheet.Range["E2:E3"].NumberFormat = "¥#,##0"
ポイント:
適切な数値フォーマットにより、財務データが理解しやすく、よりプロフェッショナルに見えます。詳細は Python で Excel セルの数値フォーマットを設定する方法 を参照してください。
列幅や行高を適切に設定することで、内容を見やすく表示できます。自動調整や固定値の指定が可能です。
# 列幅と行の高さを自動調整
for col in range(1, 5):
sheet.AutoFitColumn(col)
for row in range(1, 3):
sheet.AutoFitRow(row)
#sheet.Range["A1:E3"].AutoFitColumns()
#sheet.Range["A1:E3"].AutoFitRows()
# 固定の列幅と行の高さを設定
sheet.Columns[1].Width = 150
sheet.Rows[1].Height = 30
workbook.SaveToFile("output/formatted_excel.xlsx", ExcelVersion.Version2016)
ポイント:
動的データには自動調整、定型レイアウトには固定値を用いることで、見やすさと一貫性を両立できます。
より高度な Excel 書式設定(フォント・色・罫線・条件付き書式など)については、Python で Excel を書式設定する方法 を参照してください。
Excel では、複数のワークシートを使うことで関連情報を分離し、管理しやすくできます。たとえば、売上・仕入・在庫を同じワークブック内の別シートに整理できます。このセクションでは、Python で 複数シートを作成・参照・管理する方法を紹介します。
from spire.xls import Workbook, ExcelVersion
workbook = Workbook()
# 新しく作成されたワークブックには、
# デフォルトのワークシートが3つ含まれています
# ワークシート名を日本語に設定
sheet = workbook.Worksheets[0]
sheet.Name = "売上データ"
sheet1 = workbook.Worksheets["Sheet2"]
sheet1.Name = "仕入データ"
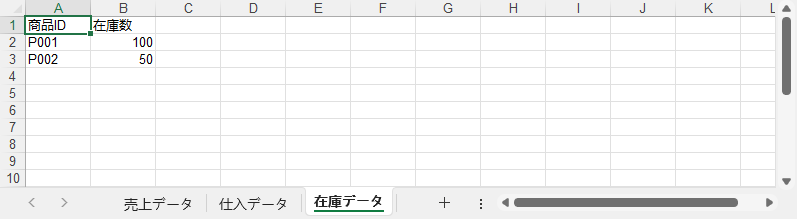
sheet2 = workbook.Worksheets.Add("在庫データ")
sheet2.Range["A1"].Value = "商品ID"
sheet2.Range["B1"].Value = "在庫数"
sheet2.Range["A2"].Value = "P001"
sheet2.Range["B2"].NumberValue = 100
sheet2.Range["A3"].Value = "P002"
sheet2.Range["B3"].NumberValue = 50
workbook.Worksheets.RemoveAt(2)
workbook.SaveToFile("output/multi_sheet.xlsx", ExcelVersion.Version2016)
主な操作:
これにより、Excel ファイルを論理的に構成し、関連データを分離して明確かつ管理しやすくできます。
効率性・一貫性・使いやすさを確保するため、以下のベストプラクティスに従うことを推奨します:
これらを実践することで、再利用可能でプロフェッショナルなレポートを効率的に作成できます。
Python で Excel 書き込みを自動化すれば、レポート作成が大幅に効率化されます。ワークブック作成、データの効率的な書き込み、スタイル適用、シート管理、多様なデータ型の処理を組み合わせることで、一貫性・正確性・プロフェッショナル性を備えた Excel レポートが実現できます。さらに詳しく試すには、無料の一時ライセンスを申請するか、Free Spire.XLS for Python を利用できます。
はい、既存のワークブックを読み込み、データを追加・修正した上で保存できます。既存の内容は保持されます。
複数行のバッチ書き込みと、書式設定を最小限に抑えた挿入で、数千行規模でも高いパフォーマンスを維持できます。
はい、=SUM() などの基本数式から複雑な計算式まで挿入でき、レポートを動的に更新できます。
Spire.XLS for Python は .xlsx、.xls、CSV、さらに PDF へのエクスポートにも対応しており、一般的な利用シナリオと互換性要件をカバーします。





