

ドキュメント印刷 は、デスクトップアプリケーション、バックグラウンドサービス、サーバーサイドシステムにおいて非常に一般的な要件です。実際の開発や業務シナリオでは、ユーザー操作に依存せず、サイレント印刷 や 特定プリンターへの出力、あるいは コードによる印刷動作の制御 が求められるケースが多くあります。
本記事では、Spire.Printing を使用して、Windows、Linux、macOS 環境において C# で PDF および Office ドキュメントを自動的に印刷する方法 を解説します。印刷用ドキュメントストリームの扱い方、プリンターのプログラム制御、そして高度な印刷設定について理解することで、モダンな .NET アプリケーションにおける安定したクロスプラットフォーム印刷を実現できます。
目次
Spire.Printing は NuGet パッケージとして提供されており、以下のコマンドで簡単に導入できます。
Install-Package Spire.Printing
Spire.Printing は、モダンな .NET アプリケーション向けに設計された クロスプラットフォーム印刷ライブラリ です。.NET Standard に対応した Spire.Office ライブラリと組み合わせることで、Microsoft Office Interop に依存せず、Windows、Linux、macOS 上で Word、Excel、PowerPoint、PDF などのドキュメントを印刷できます。
対応する .NET ランタイムは以下のとおりです。
対応プラットフォーム:
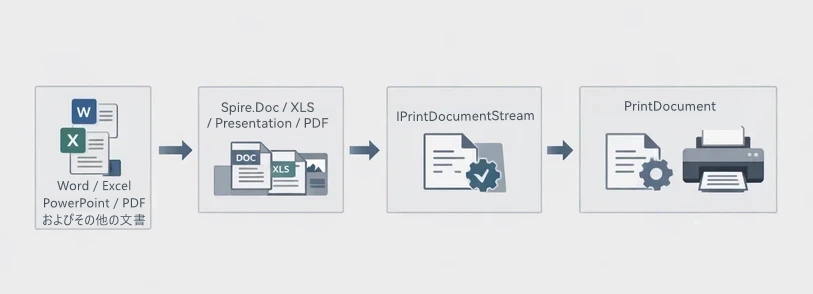
Spire.Printing は、印刷可能なドキュメントストリームを直接プリンターへ送信する という設計思想を採用しています。異なるオペレーティングシステムでは、印刷可能なストリームの形式が若干異なります。Windows では XPS ドキュメントストリームを使用し、Linux / macOS では通常 PDF ドキュメントストリームを使用します。
実際の開発では、Spire.Printing を Spire.Office for .NET と組み合わせて使用することで、統一されたクロスプラットフォーム印刷フローを構築できます。
using Spire.Printing;
IPrintDocumentStream documentStream;
if (System.Runtime.InteropServices.RuntimeInformation.IsOSPlatform(
System.Runtime.InteropServices.OSPlatform.Windows))
{
// Windows 環境では XPS を使用
documentStream = new XpsPrintDocument("test.xps");
}
else
{
// Linux / macOS では PDF を使用
documentStream = new PdfPrintDocument("test.pdf");
}
PrintDocument printDocument = new PrintDocument(documentStream);
// 用紙サイズの設定
printDocument.PrintSettings.PaperSize = PaperSize.A4;
// 印刷部数
printDocument.PrintSettings.Copies = 2;
// ページ範囲の指定
printDocument.PrintSettings.SelectPageRange(2, 5);
// 両面印刷
if (printDocument.PrintSettings.CanDuplex)
{
printDocument.PrintSettings.Duplex = Duplex.Vertical;
}
// 部単位で印刷するかどうか
printDocument.PrintSettings.Collate = true;
// 使用するプリンター(未指定の場合は既定のプリンター)
printDocument.PrintSettings.PrinterName = "Your Printer Name";
// ファイルとして出力
printDocument.PrintSettings.PrintToFile("toXps.xps");
// 印刷ログの記録
printDocument.PrintSettings.PrintLogger =
new DefaultPrintLogger("log.txt");
// 印刷実行
printDocument.Print();
// リソース解放
printDocument.Dispose();
このストリームベースの仕組みにより、プラットフォーム間で一貫した印刷処理を維持しつつ、PrintSettings API を通じて詳細な印刷制御が可能になります。
実際のプロジェクトでは、Spire.Printing は通常、対応する Spire.Office ドキュメントコンポーネント(Spire.Doc、Spire.XLS、Spire.Presentation、Spire.PDF)と連携して使用されます。これらのコンポーネントは元のドキュメントを読み込み、PDF または XPS のドキュメントストリームとして保存し、Spire.Printing に渡してプリンターへ送信する役割を担います。
ライブラリのインストール
Install-Package Spire.Printing
Install-Package Spire.Docfor.NETStandard
サンプルコード
using Spire.Doc;
using Spire.Printing;
bool isWindows = System.Runtime.InteropServices.RuntimeInformation
.IsOSPlatform(System.Runtime.InteropServices.OSPlatform.Windows);
using (Document document = new Document())
{
document.LoadFromFile("test.docx");
var fileFormat = !isWindows
? Spire.Doc.FileFormat.PDF
: Spire.Doc.FileFormat.XPS;
MemoryStream stream = new MemoryStream();
document.SaveToStream(stream, fileFormat);
IPrintDocumentStream docStream = !isWindows
? new PdfPrintDocument(stream)
: new XpsPrintDocument(stream);
PrintDocument printDoc = new PrintDocument(docStream);
printDoc.PrintSettings.SelectPageRange(1, 1);
printDoc.Print();
printDoc.Dispose();
}
ライブラリのインストール
Install-Package Spire.Printing
Install-Package Spire.XLSfor.NETStandard
サンプルコード
using Spire.Printing;
using Spire.Xls;
// 実行環境の判定
bool isWindows = System.Runtime.InteropServices.RuntimeInformation
.IsOSPlatform(System.Runtime.InteropServices.OSPlatform.Windows);
using (Workbook workbook = new Workbook())
{
// Excel ファイルを読み込み
workbook.LoadFromFile("test.xlsx");
// OS に応じて PDF または XPS 形式でストリームに保存
var fileFormat = !isWindows
? Spire.Xls.FileFormat.PDF
: Spire.Xls.FileFormat.XPS;
MemoryStream stream = new MemoryStream();
workbook.SaveToStream(stream, fileFormat);
// 印刷用ドキュメントストリームを作成
IPrintDocumentStream xlsStream = !isWindows
? new PdfPrintDocument(stream)
: new XpsPrintDocument(stream);
// 印刷実行
PrintDocument printXls = new PrintDocument(xlsStream);
printXls.PrintSettings.SelectPageRange(1, 1);
printXls.Print();
// リソース解放
printXls.Dispose();
}
ライブラリのインストール
Install-Package Spire.Printing
Install-Package Spire.PDFfor.NETStandard
サンプルコード
using Spire.Pdf;
using Spire.Printing;
// 実行環境の判定
bool isWindows = System.Runtime.InteropServices.RuntimeInformation
.IsOSPlatform(System.Runtime.InteropServices.OSPlatform.Windows);
using (PdfDocument pdfDocument = new PdfDocument())
{
// PDF ファイルを読み込み
pdfDocument.LoadFromFile("test.pdf");
// OS に応じて保存形式を切り替え
var fileFormat = !isWindows
? Spire.Pdf.FileFormat.PDF
: Spire.Pdf.FileFormat.XPS;
MemoryStream stream = new MemoryStream();
pdfDocument.SaveToStream(stream, fileFormat);
// 印刷用ストリームを生成
IPrintDocumentStream pdfStream = !isWindows
? new PdfPrintDocument(stream)
: new XpsPrintDocument(stream);
// 印刷実行
PrintDocument printPdf = new PrintDocument(pdfStream);
printPdf.PrintSettings.SelectPageRange(1, 1);
printPdf.Print();
// リソース解放
printPdf.Dispose();
}
ライブラリのインストール
Install-Package Spire.Printing
Install-Package Spire.Presentationfor.NETStandard
サンプルコード
using Spire.Presentation;
using Spire.Printing;
// 実行環境の判定
bool isWindows = System.Runtime.InteropServices.RuntimeInformation
.IsOSPlatform(System.Runtime.InteropServices.OSPlatform.Windows);
using (Presentation presentation = new Presentation())
{
// PowerPoint ファイルを読み込み
presentation.LoadFromFile("test.pptx");
// OS に応じて PDF / XPS 形式でストリーム保存
var fileFormat = !isWindows
? Spire.Presentation.FileFormat.PDF
: Spire.Presentation.FileFormat.XPS;
MemoryStream stream = new MemoryStream();
presentation.SaveToFile(stream, fileFormat);
// 印刷用ドキュメントストリームを作成
IPrintDocumentStream pptStream = !isWindows
? new PdfPrintDocument(stream)
: new XpsPrintDocument(stream);
// 印刷実行
PrintDocument printPpt = new PrintDocument(pptStream);
printPpt.PrintSettings.SelectPageRange(1, 1);
printPpt.Print();
// リソース解放
printPpt.Dispose();
}
自動印刷やクロスプラットフォーム環境においては、単にドキュメントを印刷するだけでなく、使用するプリンター、用紙サイズ、印刷対象ページ を正確に制御することが重要です。
Spire.Printing では、PrintSettings API を通じて、これらの要素をプログラムから柔軟に制御できます。この機能は、バックグラウンドサービス、バッチ印刷処理、業務システムなど、ユーザー操作を伴わない印刷シナリオで特に有効です。
既定のプリンターを使用する代わりに、インストールされているプリンターを列挙し、任意のプリンターを選択して印刷することができます。
IEnumerable<string> printers = printDocument.PrintSettings.Printers;
// ビジネスロジックに基づいてプリンターを選択
string selectedPrinterName = printers.First();
printDocument.PrintSettings.PrinterName = selectedPrinterName;
この方法は、複数のプリンターが接続されている環境や、帳票の種類ごとに出力先を切り替える必要がある場合に役立ちます。
プリンターごとに対応している用紙サイズは異なるため、あらかじめ使用可能な用紙サイズを取得し、その中から選択することで、印刷エラーを防ぐことができます。
IEnumerable<PaperSize> paperSizes =
printDocument.PrintSettings.PaperSizes;
// 使用可能な用紙サイズから選択
PaperSize selectedPaperSize = paperSizes.First();
printDocument.PrintSettings.PaperSize = selectedPaperSize;
このアプローチにより、選択した用紙サイズが対象プリンターで確実に使用可能であることを保証できます。
Spire.Printing では、印刷対象ページを連続した範囲 または 特定のページ一覧 として指定できます。
// 2 ページ目から 5 ページ目までを印刷
printDocument.PrintSettings.SelectPageRange(2, 5);
// 特定のページのみを印刷(例:1, 3, 5, 7 ページ)
int[] pages = { 1, 3, 5, 7 };
printDocument.PrintSettings.SelectSomePages(pages);
※ 同一の印刷ジョブ内では、いずれか一方のみを使用してください。
この機能を利用することで、不要なページの出力を避け、用紙や印刷コストの削減につながります。
これらの高度な印刷設定を活用することで、 複数のドキュメントやプリンターに対しても、一貫した印刷結果を得ることができます。 そのため、Spire.Printing は自動化ワークフローや業務向け印刷処理に非常に適しています。
ライセンス未適用の場合、Spire.Printing は最初の 10 ページのみ印刷可能 です。 Spire.Office for .NET、または Spire.Doc / Spire.XLS / Spire.PDF / Spire.Presentation のライセンスを適用することで、この制限を解除できます。
Spire.Pdf.License.LicenseProvider.SetLicenseKey(key);
Spire.Doc.License.LicenseProvider.SetLicenseKey(key);
Spire.Xls.License.LicenseProvider.SetLicenseKey(key);
Spire.Presentation.License.LicenseProvider.SetLicenseKey(key);
詳細は ライセンスガイド を参照してください。
Spire.Printing は、C# アプリケーションにおいて PDF、Word、Excel、PowerPoint をストリームベースで印刷できる柔軟かつ信頼性の高いソリューション です。 Windows、Linux、macOS に対応し、Spire.Office for .NET(特に .NET Standard 版)と組み合わせることで、モダンな .NET 環境でも安定した印刷処理を実現できます。
基本的な印刷フローを理解すれば、プリンター選択、用紙サイズ、ページ指定などの高度な設定 も容易に適用でき、実務に即した自動化印刷システムを構築できます。
評価や短期間の開発用途には、一時ライセンス を申請することで、試用制限を解除した状態で検証できます。

Python アプリケーションにおいて、Word 文書をプログラムで生成することは非常に一般的な要件です。
レポート、請求書、契約書、監査ログ、エクスポートされたデータセットなどは、単なるテキストや PDF ではなく、編集可能な .docx ファイルとして提供されることが多くあります。
プレーンテキストとは異なり、Word 文書は 構造化ドキュメント です。
セクション、段落、スタイル、レイアウト規則といった要素で構成されており、.docx ファイルを単なる文字列コンテナとして扱うと、レイアウト崩れや保守性の低下を招きます。
本チュートリアルでは、Spire.Doc for Python を使用し、実践的な Word 文書作成方法 を解説します。
Word 本来のドキュメントオブジェクトモデルに沿って文書を構築し、正しい構造レベルで書式を適用することで、コンテンツが増えても安定して編集可能な .docx ファイルを生成する方法を紹介します。
コンテンツ一覧
コードを書き始める前に、Word 文書が内部的にどのような構造を持っているかを理解することが重要です。
.docx ファイルは単なるテキストの連続ではありません。
以下のような複数のオブジェクト階層で構成されています。
Python で Word 文書を作成する際は、この階層構造を コード上で明示的に構築 することになります。
書式やレイアウトは、適切な階層レベルで設定した場合にのみ、予測通りに動作します。
Spire.Doc for Python は、これらの要素に対応する抽象化を提供しており、Word 自体の構造に非常に近い形で文書を操作できます。
このセクションでは、Spire.Doc を使用して Python から有効な Word 文書を生成する方法を紹介します。
正しい文書構造と基本的な処理フローに焦点を当てます。
pip install spire.doc
または、Spire.Doc for Python をダウンロード して手動で組み込むことも可能です。
.docx ファイルの作成from spire.doc import Document, FileFormat
# 文書オブジェクトを作成
document = Document()
# セクションを追加(ページレイアウトを定義)
section = document.AddSection()
# 段落を追加
paragraph = section.AddParagraph()
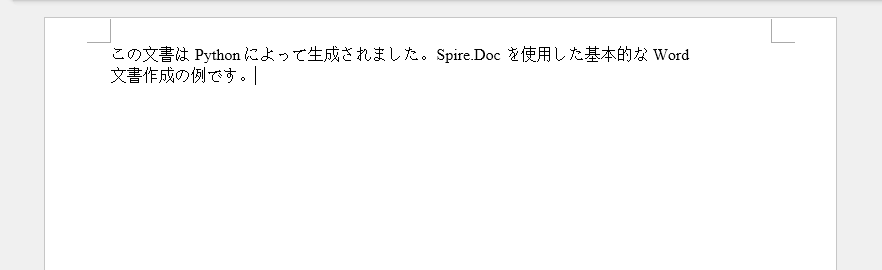
paragraph.AppendText(
"この文書は Python によって生成されました。"
"Spire.Doc を使用した基本的な Word 文書作成の例です。"
)
# 文書を保存
document.SaveToFile("basic_document.docx", FileFormat.Docx)
document.Close()
このコードは、Microsoft Word で正常に開くことができる、最小構成の .docx ファイルを生成します。
文書作成の基本的な流れ(Document → Section → Paragraph → 保存)を示しています。
技術的な観点では次の通りです。
Spire.Doc で生成されるすべての Word 文書は、この構造パターンに基づいており、以降の高度な操作の基盤となります。
Word 文書内のテキストは階層的に管理されます。 書式設定は以下の 2 つのレベルで適用できます。
さらに、スタイル を使用すると、これらの書式設定をまとめて定義し、複数の段落やテキストに再利用できます。 段落書式・文字書式・スタイルの違いを理解することは、Python で Word 文書を作成・編集する上で非常に重要です。
Word 文書に表示されるすべてのテキストは、必ず段落を通して追加されます。 段落はテキストとレイアウトのコンテナであり、Paragraph.Format を通じて段落レベルの書式を設定できます。 文字レベルの書式は、TextRange.CharacterFormat を使用して設定します。
from spire.doc import Document, HorizontalAlignment, FileFormat, Color
document = Document()
section = document.AddSection()
# タイトル段落を追加
title = section.AddParagraph()
title.Format.HorizontalAlignment = HorizontalAlignment.Center
title.Format.AfterSpacing = 20
title.Format.BeforeSpacing = 20
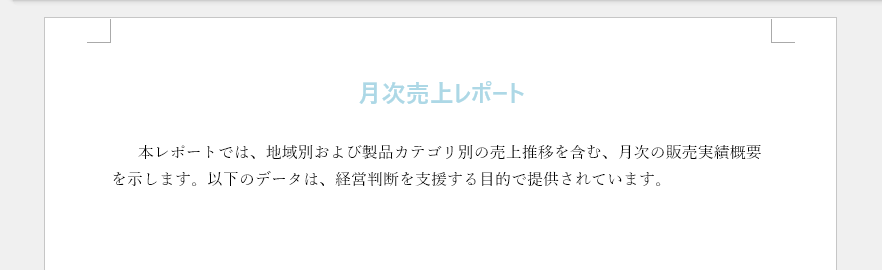
title_range = title.AppendText("月次売上レポート")
title_range.CharacterFormat.FontSize = 18
title_range.CharacterFormat.Bold = True
title_range.CharacterFormat.TextColor = Color.get_LightBlue()
title_range.CharacterFormat.FontName = "Yu Gothic UI"
# 本文段落を追加
body = section.AddParagraph()
body.Format.FirstLineIndent = 20
body_range = body.AppendText(
"本レポートでは、地域別および製品カテゴリ別の売上推移を含む、"
"月次の販売実績概要を示します。"
"以下のデータは、経営判断を支援する目的で提供されています。"
)
body_range.CharacterFormat.FontSize = 12
body_range.CharacterFormat.FontName = "Yu Mincho"
# 文書を保存
document.SaveToFile("formatted_paragraph.docx", FileFormat.Docx)
document.Close()
生成された Word 文書のプレビューです。
技術メモ
スタイルを使用すると、段落レベルおよび文字レベルの書式設定を一度定義し、文書全体で再利用できます。
配置、余白、フォント、強調表現などをスタイルとして管理することで、書式の一貫性が向上し、保守も容易になります。
Word 文書では、カスタムスタイル と 組み込みスタイル の両方を使用できます。
いずれの場合も、スタイルは適用前に文書へ追加する必要があります。
from spire.doc import (
Document, HorizontalAlignment, BuiltinStyle,
TextAlignment, ParagraphStyle, FileFormat
)
document = Document()
# カスタム段落スタイルを作成
custom_style = ParagraphStyle(document)
custom_style.Name = "CustomStyle"
custom_style.ParagraphFormat.HorizontalAlignment = HorizontalAlignment.Center
custom_style.ParagraphFormat.TextAlignment = TextAlignment.Auto
custom_style.CharacterFormat.Bold = True
custom_style.CharacterFormat.FontSize = 20
# 組み込みの見出しスタイルを基に継承
custom_style.ApplyBaseStyle(BuiltinStyle.Heading1)
# スタイルを文書に追加
document.Styles.Add(custom_style)
# カスタムスタイルを適用
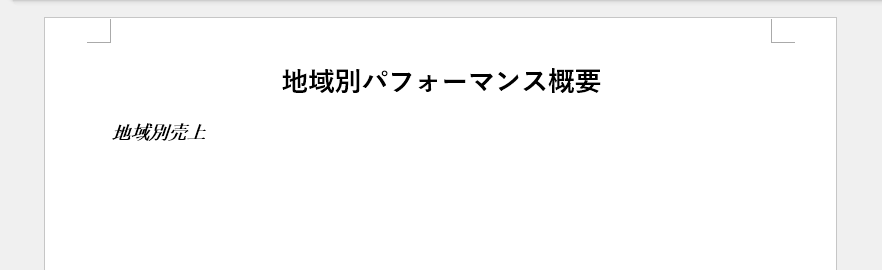
title_para = document.AddSection().AddParagraph()
title_para.ApplyStyle(custom_style.Name)
title_para.AppendText("地域別パフォーマンス概要")
# 組み込みスタイルを追加
built_in_style = document.AddStyle(BuiltinStyle.Heading2)
document.Styles.Add(built_in_style)
# 組み込みスタイルを適用
heading_para = document.Sections.get_Item(0).AddParagraph()
heading_para.ApplyStyle(built_in_style.Name)
heading_para.AppendText("地域別売上")
document.SaveToFile("document_styles.docx", FileFormat.Docx)
document.Dispose()
生成された Word 文書のプレビューです。
技術的な解説
見出し 2(Heading 2) などの組み込みスタイルを適切に使用することで、アウトライン表示や目次生成など、Word の機能とも高い互換性を保てます。
Word のドキュメントモデルでは、画像は段落に属する埋め込みオブジェクトとして扱われます。 段落にアンカーされた画像は、テキストと自然に連動し、コンテンツ変更時にもページ分割や位置関係が自動調整されます。
from spire.doc import Document, TextWrappingStyle, HorizontalAlignment, FileFormat, ShapeHorizontalAlignment
document = Document()
section = document.AddSection()
section.AddParagraph().AppendText("\r\n\r\n画像サンプル\r\n")
# 画像を挿入
image_para = section.AddParagraph()
image_para.Format.HorizontalAlignment = HorizontalAlignment.Center
image = image_para.AppendPicture("Screen.jpg")
# 文字列の折り返し方法を設定
image.TextWrappingStyle = TextWrappingStyle.Square
# 画像サイズを設定
image.Width = 350
image.Height = 200
# 透明度を設定
image.FillTransparency(0.7)
# 水平方向の配置を設定
image.HorizontalAlignment = ShapeHorizontalAlignment.Center
document.SaveToFile("document_images.docx", FileFormat.Docx)
document.Dispose()
生成された Word 文書のプレビューです。
技術的なポイント
画像を段落に属させることで、以下の利点があります。
これらの挙動は、Word におけるインライン画像の標準的な動作と一致しています。
より高度な画像操作については、 Python で Word 文書に画像を挿入する方法 を参照してください。
表は、レポート、集計結果、比較データなどの構造化情報を表現する際によく使用されます。
内部的には、表は 行・セル・セル内の段落 で構成されています。
from spire.doc import Document, DefaultTableStyle, FileFormat, AutoFitBehaviorType
document = Document()
section = document.AddSection()
section.AddParagraph().AppendText("\r\n\r\n表のサンプル\r\n")
# 表データを定義
table_headers = ["地域", "製品", "販売数量", "単価(円)", "売上合計(円)"]
table_data = [
["北", "ノートPC", 120, 95000, 11400000],
["北", "スマートフォン", 300, 50000, 15000000],
["南", "ノートPC", 80, 95000, 7600000],
["南", "スマートフォン", 200, 50000, 10000000],
["東", "ノートPC", 150, 95000, 14250000],
["東", "スマートフォン", 250, 50000, 12500000],
["西", "ノートPC", 100, 95000, 9500000],
["西", "スマートフォン", 220, 50000, 11000000]
]
# セクションに表を追加
table = section.AddTable()
table.ResetCells(len(table_data) + 1, len(table_headers))
# ヘッダー行を設定
for col_index, header in enumerate(table_headers):
header_range = table.Rows[0].Cells[col_index].AddParagraph().AppendText(header)
header_range.CharacterFormat.FontSize = 14
header_range.CharacterFormat.Bold = True
header_range.CharacterFormat.FontName = "Yu Gothic UI Semibold"
# データ行を設定
for row_index, row_data in enumerate(table_data):
for col_index, cell_data in enumerate(row_data):
data_range = table.Rows[row_index + 1].Cells[col_index] \
.AddParagraph().AppendText(str(cell_data))
data_range.CharacterFormat.FontSize = 12
data_range.CharacterFormat.FontName = "Yu Gothic UI"
# 表スタイルを適用し、列幅を自動調整
table.ApplyStyle(DefaultTableStyle.ColorfulListAccent6)
table.AutoFit(AutoFitBehaviorType.AutoFitToContents)
document.SaveToFile("document_tables.docx", FileFormat.Docx)
document.Dispose()
生成された Word 文書のプレビューです。
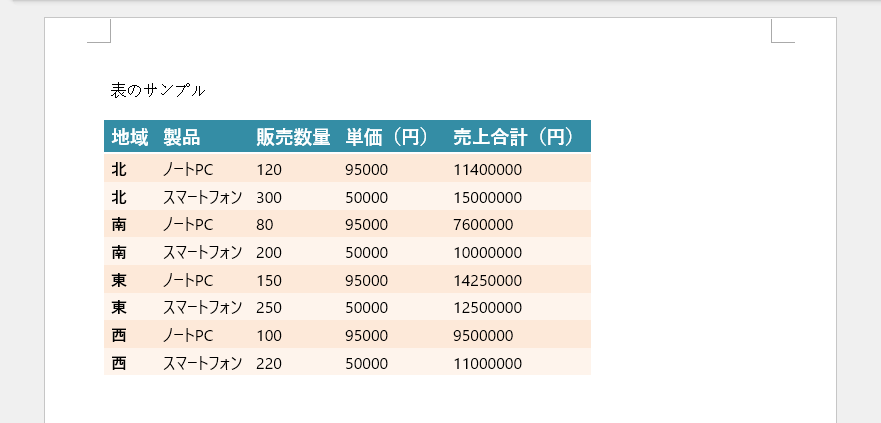
技術的なポイント
Word の表では、各セルが独立したコンテンツコンテナとして扱われます。 セル内には複数の段落、画像、書式付きテキストを配置できるため、単純な表から複雑なレポートレイアウトまで柔軟に対応できます。
動的な表生成、セル結合、個別セルの書式設定など、より高度な操作については、 Python で Word 文書に表を挿入する方法 を参照してください。
Word におけるヘッダーとフッターは セクション単位の要素 です。 本文コンテンツとは独立しており、本文のページ分割には影響しません。
各セクションは独自のヘッダー・フッターを持つため、文書内で異なる繰り返し情報を表示できます。
from spire.doc import Document, FileFormat, HorizontalAlignment, FieldType, BreakType
document = Document()
section = document.AddSection()
section.AddParagraph().AppendBreak(BreakType.PageBreak)
# ヘッダーを追加
header = section.HeadersFooters.Header
header_para1 = header.AddParagraph()
header_para1.AppendText("月次売上レポート").CharacterFormat.FontSize = 12
header_para1.Format.HorizontalAlignment = HorizontalAlignment.Left
header_para2 = header.AddParagraph()
header_para2.AppendText("会社名").CharacterFormat.FontSize = 12
header_para2.Format.HorizontalAlignment = HorizontalAlignment.Right
# フッターにページ番号を追加
footer = section.HeadersFooters.Footer
footer_para = footer.AddParagraph()
footer_para.Format.HorizontalAlignment = HorizontalAlignment.Center
footer_para.AppendText("ページ ").CharacterFormat.FontSize = 12
footer_para.AppendField("PageNum", FieldType.FieldPage).CharacterFormat.FontSize = 12
footer_para.AppendText(" / ").CharacterFormat.FontSize = 12
footer_para.AppendField("NumPages", FieldType.FieldNumPages).CharacterFormat.FontSize = 12
document.SaveToFile("document_header_footer.docx", FileFormat.Docx)
document.Dispose()
生成された Word 文書のプレビューです。
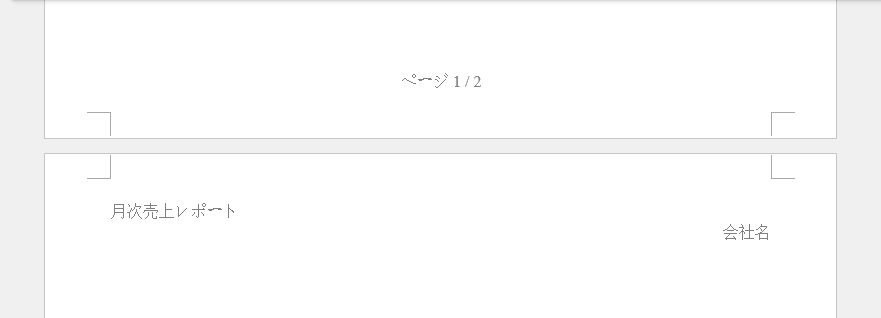
技術メモ
ヘッダーとフッターは、レポートタイトル、会社情報、ページ番号表示などに広く使用されます。 文書内容が変更されても自動的に更新され、Word・PDF などの出力形式とも高い互換性を保ちます。
より詳細な使用例については、 Python で Word 文書にヘッダーとフッターを挿入する方法 を参照してください。
Spire.Doc for Python では、ページレベルのレイアウト設定はすべて Section オブジェクトを通じて管理されます。
ページサイズ、向き、余白などは、セクションが持つ PageSetup によって定義され、そのセクション内のすべてのコンテンツに適用されます。
from spire.doc import PageSize, PageOrientation
section.PageSetup.PageSize = PageSize.A4()
section.PageSetup.Orientation = PageOrientation.Portrait
技術的な解説
PageSetup の設定は、セクション全体に適用されます。 そのセクションに追加される段落、表、画像はすべて同じレイアウト規則に従います。 他のセクションには影響しないため、文書内で異なるレイアウトを共存させることが可能です。
section.PageSetup.Margins.Top = 50
section.PageSetup.Margins.Bottom = 50
section.PageSetup.Margins.Left = 60
section.PageSetup.Margins.Right = 60
技術的な解説
余白はセクション単位で評価されるため、個々の段落ごとに設定する必要はありません。 なお、ヘッダーやフッターの領域には影響しません。
文書内で異なるページレイアウトが必要な場合は、新しいセクションを追加します。
landscape_section = document.AddSection()
landscape_section.PageSetup.Orientation = PageOrientation.Landscape
複数のセクションを活用することで、縦向きと横向きのページを混在させたり、 用途に応じたレイアウトを 1 つの Word 文書内で実現できます。
以下は、上記設定を反映した Word 文書の例です。

Word 文書には、表示されるコンテンツとは別に、文書レベルのメタデータ を設定できます。 これらはレイアウトや描画には影響せず、文書管理や検索に利用されます。
document.BuiltinDocumentProperties.Title = "月次売上レポート"
document.BuiltinDocumentProperties.Author = "データ分析システム"
document.BuiltinDocumentProperties.Company = "サンプル株式会社"
Title、Author、Company などをプログラムから設定可能です文書プロパティは、ファイルのインデックス化、検索、文書管理、監査フローなどで広く利用されます。このほかにも、Keywords、Subject、Comments、Hyperlink base などのメタデータを設定できます。また、Document.CustomDocumentProperties を使用すれば、カスタムプロパティの定義も可能です。
カスタムメタデータの管理方法については、Python で Word 文書のカスタムプロパティを管理する方法 を参照してください。
Word 文書をメモリ上で構築した後、最終ステップとして保存またはエクスポートを行います。Spire.Doc for Python では、統一された API により、同一の文書構造を複数の出力形式に再利用できます。
文書は編集用の DOCX として保存できるほか、配布用途向けに他形式へエクスポートできます。
from spire.doc import FileFormat
document.SaveToFile("output.docx", FileFormat.Docx)
document.SaveToFile("output.pdf", FileFormat.PDF)
document.SaveToFile("output.html", FileFormat.Html)
document.SaveToFile("output.rtf", FileFormat.Rtf)
エクスポート時には、セクション、表、画像、ヘッダー、フッターなどの構造が保持され、 出力形式が異なっても一貫したレイアウトが維持されます。 対応フォーマットの一覧は、FileFormat 列挙型 を参照してください。
大量または高頻度で Word 文書を生成する場合、以下の点を意識すると効率が向上します。
類似した文書を大量に生成する場合は、 個別にコンテンツを挿入するよりも 差し込み印刷(メールマージ) の方が効率的です。 Spire.Doc for Python には、バッチ生成向けのメールマージ機能が標準で用意されています。
詳細については、 Python で差し込み印刷を使用して Word 文書を一括生成する方法 を参照してください。
保存およびエクスポートは、Python による Word 文書生成の重要な工程です。 Spire.Doc for Python の出力機能と基本的なパフォーマンス対策を組み合わせることで、 単一ファイルからバッチ処理まで、安定した文書生成を実現できます。
Word 文書をプログラムで生成する際によく発生する問題を以下に示します。
問題点
コンテンツ量が変化すると書式やレイアウトが崩れる。
推奨事項
生テキストを直接挿入せず、セクション・段落・スタイルを正しく使用する。
問題点
レイアウト変更時に、複数箇所のコード修正が必要になる。
推奨事項
スタイルやセクション設定を用いて、書式ルールを一元管理する。
問題点
余白やページ向きの変更が文書全体に影響してしまう。
推奨事項
異なるレイアウトは別セクションで明確に分離する。
Python で Word 文書を作成する という作業は、単にテキストを書き込むだけではありません。.docx 文書は、セクション、段落、スタイル、埋め込み要素から構成される構造化オブジェクトです。
Spire.Doc for Python を使用し、Word のドキュメントモデルに沿ってコードを設計することで、編集可能で構造が明確な Word 文書を、要件の変化にも耐えられる形で生成できます。このアプローチは、バックエンドサービス、レポート生成パイプライン、文書自動化システムに特に適しています。
大規模文書の生成や文書変換機能を利用する場合は、ライセンス版 の使用が必要となります。
表は、Word 文書内で情報を構造的に整理・提示するための非常に強力なツールです。行と列から構成され、グリッド状の構造を形成します。表は、スケジュールの作成、データの比較、情報を整然と表示するなど、さまざまな用途で広く利用されています。本記事では、Spire.Doc for Python を使用して、Python で Word 文書に表をプログラム的に作成する方法を解説します。
この操作には Spire.Doc for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.Doc for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.PDF
Spire.Doc for Python では、Word 文書内の表を表現するために Table クラスが提供されています。表オブジェクトは、コンストラクターを使用する方法、または Section.AddTable() メソッドを使用して作成できます。表オブジェクトを作成した後は、Table.AddRow() メソッドを使って行を動的に追加することも、あらかじめ行数と列数を指定して一括でデータを設定することも可能です。
また、Spire.Doc for Python は HTML 文字列から表を作成する機能もサポートしています。この方法では Table オブジェクトは返されません。そのため、HTML 文字列から作成された表に対して Table クラスのプロパティやメソッドを使用することはできません。表の内容やスタイルは、HTML 文字列内であらかじめ設定する必要があります。
この例では、Table クラスを使用して基本的な表を作成し、行を 1 つずつ追加する方法を示します。主な手順は以下のとおりです。
from spire.doc import *
from spire.doc.common import *
# Document オブジェクトを作成します
doc = Document()
# セクションを追加します
section = doc.AddSection()
# テーブルを作成します
table = Table(doc, True)
# テーブルの幅を設定します(100%)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, int(100))
# テーブルの罫線スタイルを設定します
table.TableFormat.Borders.BorderType = BorderStyle.Single
table.TableFormat.Borders.Color = Color.get_Black()
# 行を追加します(3 列)
row = table.AddRow(False, 3)
row.Height = 20.0
# セルにデータを追加します
cell = row.Cells[0]
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("1 行目・1 列目")
cell = row.Cells[1]
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("1 行目・2 列目")
cell = row.Cells[2]
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("1 行目・3 列目")
# 2 行目を追加します
row = table.AddRow(False, 3)
row.Height = 20.0
cell = row.Cells[0]
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("2 行目・1 列目")
cell = row.Cells[1]
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("2 行目・2 列目")
cell = row.Cells[2]
cell.CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = cell.AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText("2 行目・3 列目")
# セクションにテーブルを追加します
section.Tables.Add(table)
# ドキュメントを保存します
doc.SaveToFile("output/CreateTable.docx", FileFormat.Docx)
doc.Close()

HTML 文字列から表を作成するには、Paragraph.AppendHTML() メソッドを使用します。手順は以下のとおりです。
from spire.doc import *
from spire.doc.common import *
# Document オブジェクトを作成します
document = Document()
# セクションを追加します
section = document.AddSection()
# HTML 形式のテーブル文字列を定義します
HTML = (
"<table border='1' style='border-collapse:collapse;width:100%'>"
"<tr>"
"<th>商品名</th>"
"<th>カテゴリ</th>"
"<th>数量</th>"
"<th>単価(円)</th>"
"<th>小計(円)</th>"
"</tr>"
"<tr>"
"<td>ワイヤレスマウス</td>"
"<td>周辺機器</td>"
"<td>2</td>"
"<td>2,500</td>"
"<td>5,000</td>"
"</tr>"
"<tr>"
"<td>メカニカルキーボード</td>"
"<td>周辺機器</td>"
"<td>1</td>"
"<td>12,800</td>"
"<td>12,800</td>"
"</tr>"
"<tr>"
"<td>USB-C ハブ</td>"
"<td>アクセサリ</td>"
"<td>3</td>"
"<td>3,200</td>"
"<td>9,600</td>"
"</tr>"
"<tr>"
"<td>合計</td>"
"<td colspan='3' style='text-align:right'>税込合計金額</td>"
"<td>27,400</td>"
"</tr>"
"</table>"
)
# 段落を追加します
paragraph = section.AddParagraph()
# HTML テーブルを段落に追加します
paragraph.AppendHTML(HTML)
# Word ドキュメントとして保存します
document.SaveToFile("output/HtmlTable.docx", FileFormat.Docx2013)
document.Close()
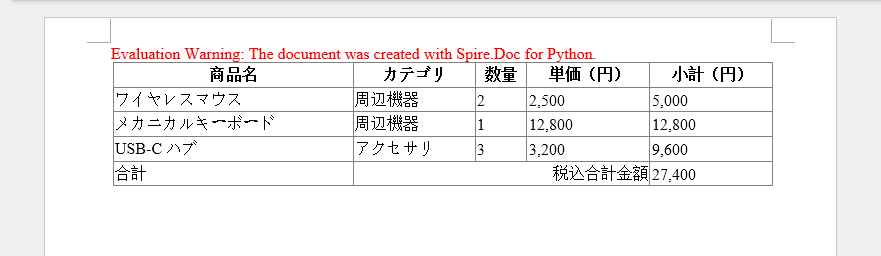
HTML が完全なドキュメント形式の場合は、表として挿入するのではなく、Word 文書へ直接変換する方法もあります。詳細については「Python を使用して HTML ファイルを Word 文書に変換する方法」をご確認ください。
表を操作する際、セルの結合や分割はデータの見せ方を柔軟にカスタマイズするための重要な機能です。この例では、Spire.Doc for Python を使用して、隣接するセルを 1 つに結合する方法と、1 つのセルを複数の小さなセルに分割する方法を紹介します。
from spire.doc import *
from spire.doc.common import *
# Document オブジェクトを作成します
document = Document()
# セクションを追加します
section = document.AddSection()
# テーブルを作成します
table = section.AddTable(True)
# テーブルの行数と列数を設定します(4 行 × 4 列)
table.ResetCells(4, 4)
# テーブルの幅を設定します(100%)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, int(100))
# 行の高さを設定します
for i in range(0, table.Rows.Count):
table.Rows[i].Height = 20.0
# 2 行目・4 列目のセルを取得します
cell = table.Rows[1].Cells[3]
# セルを縦方向に 3 分割します
cell.SplitCell(3, 0)
# 1 行目を水平方向に結合します
table.ApplyHorizontalMerge(0, 0, 3)
# 1 列目の 3~4 行目を垂直方向に結合します
table.ApplyVerticalMerge(0, 2, 3)
# 見出しセル
table.Rows[0].Cells[0].CellFormat.BackColor = Color.get_LightBlue()
# 左側の結合セル
table.Rows[2].Cells[0].CellFormat.BackColor = Color.get_LightBlue()
# 分割されたセル
table.Rows[1].Cells[3].CellFormat.BackColor = Color.get_LightGray()
table.Rows[1].Cells[4].CellFormat.BackColor = Color.get_LightGray()
table.Rows[1].Cells[5].CellFormat.BackColor = Color.get_LightGray()
# ドキュメントを保存します
document.SaveToFile("output/MergeAndSplit.docx", FileFormat.Docx2013)
document.Close()
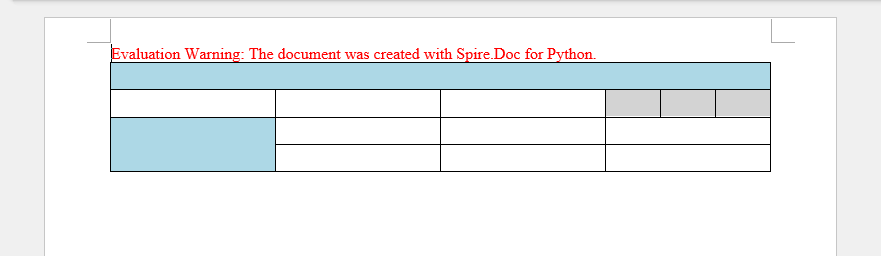
この例では、5 行 7 列の表を作成し、リスト内のデータを各セルに書き込み、ヘッダー行とそれ以外の行に異なる書式を適用します。主な手順は以下のとおりです。
import math
from spire.doc import *
from spire.doc.common import *
# Document オブジェクトを作成します
doc = Document()
# セクションを追加します
section = doc.AddSection()
# テーブルを作成します
table = section.AddTable(True)
# テーブルに使用するデータを定義します
header_data = ["日付", "商品名", "国・地域", "在庫数", "発注中数量"]
row_data = [
["2021/08/07", "ダイビングカヤック", "アメリカ", "24", "16"],
["2021/08/07", "水中スクーター", "アメリカ", "5", "3"],
["2021/08/07", "レギュレーターシステム", "チェコ", "165", "216"],
["2021/08/08", "ダイビングソナー", "アメリカ", "46", "45"],
["2021/08/09", "レギュレーターシステム", "イギリス", "166", "100"],
["2021/08/10", "インフレーションレギュレーター", "イギリス", "47", "43"]
]
# テーブルの行数と列数を設定します
table.ResetCells(len(row_data) + 1, len(header_data))
# テーブルの幅を設定します(100%)
table.PreferredWidth = PreferredWidth(WidthType.Percentage, int(100))
# ヘッダー行を取得します
headerRow = table.Rows[0]
headerRow.IsHeader = True
headerRow.Height = 23
headerRow.RowFormat.BackColor = Color.get_LightGray()
# ヘッダー行にデータを入力し、書式を設定します
i = 0
while i < len(header_data):
headerRow.Cells[i].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = headerRow.Cells[i].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
txtRange = paragraph.AppendText(header_data[i])
txtRange.CharacterFormat.Bold = True
txtRange.CharacterFormat.FontSize = 12
txtRange.CharacterFormat.FontName = "Yu Gothic UI"
i += 1
# データ行に値を入力し、書式を設定します
r = 0
while r < len(row_data):
dataRow = table.Rows[r + 1]
dataRow.Height = 20
dataRow.HeightType = TableRowHeightType.Exactly
c = 0
while c < len(row_data[r]):
dataRow.Cells[c].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = dataRow.Cells[c].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
txtRange = paragraph.AppendText(row_data[r][c])
txtRange.CharacterFormat.FontSize = 11
txtRange.CharacterFormat.FontName = "Yu Gothic"
c += 1
r += 1
# 行の背景色を交互に設定します
for j in range(1, table.Rows.Count):
if math.fmod(j, 2) == 0:
row2 = table.Rows[j]
for f in range(row2.Cells.Count):
row2.Cells[f].CellFormat.BackColor = Color.get_LightBlue()
# テーブルの罫線を設定します
table.Format.Borders.BorderType = BorderStyle.Single
table.Format.Borders.LineWidth = 1.0
table.Format.Borders.Color = Color.get_Black()
# テーブルを自動調整します
table.AutoFit(AutoFitBehaviorType.AutoFitToContents)
# Word ドキュメントとして保存します
doc.SaveToFile("output/Table.docx", FileFormat.Docx2013)
doc.Dispose()
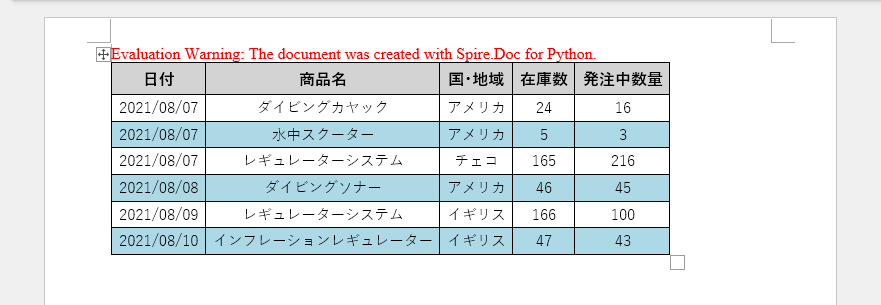
生成された文書から評価メッセージを削除したい場合や、機能制限を解除したい場合は、30 日間の試用ライセンスを申請 してください。

多くの Web アプリケーションにおいて、PDF ファイルは単なるダウンロード用の添付ファイルではありません。請求書、財務レポート、契約書、証明書、あるいは異なるデバイス間でもレイアウトを維持する必要のあるデータ出力など、PDF は業務フローの最終成果物として重要な役割を果たします。
ASP.NET 開発者にとって、サーバーサイドで PDF を直接生成することは非常に一般的な要件です。 従来の ASP.NET MVC アプリケーションを保守している場合でも、最新の ASP.NET Core サービスを構築している場合でも、コードによって PDF を生成することで、ドキュメントの構造・レイアウト・印刷結果を一貫して制御できます。
しかし、実際の開発現場では、ASP.NET における PDF 生成は必ずしも「すぐに使える」ものではなく、次のような課題に直面することが少なくありません。
本記事では、これらの課題を踏まえつつ、Spire.PDF for .NET を使用して、ASP.NET および ASP.NET Core 環境で C# による PDF 生成を行う実践的な方法を体系的に解説します。MVC や Web API といった一般的なプロジェクト構成にも対応しており、実務にそのまま適用できる内容となっています。
この記事を読み終える頃には、ASP.NET における PDF 生成の仕組みを明確に理解し、実際の業務システムへスムーズに組み込めるようになるでしょう。
ASP.NET または ASP.NET Core プロジェクトで PDF 生成を開始する前に、まず開発環境が正しく構成されていることを確認する必要があります。適切な環境設定を行うことで、実行時エラーや互換性の問題を未然に防ぐことができます。
ASP.NET Framework プロジェクトのターゲット フレームワークは .NET Framework 4.6.1 以上である必要があります。
ASP.NET Core プロジェクト要件に応じて .NET 6 または .NET 7 SDK をインストールしてください。
インストール済みの SDK バージョンは、次のコマンドで確認できます。
dotnet --version
PDF を生成するには、プロジェクトと互換性のある PDF ライブラリが必要です。Spire.PDF for .NET は、ASP.NET Framework と ASP.NET Core の両方をサポートする実績あるライブラリです。
Install-Package Spire.PDF
または、直接Spire.PDF for .NET をダウンロードして手動で追加することもできます。
ASP.NET Framework
ASP.NET Core
また、PDF をファイルとして保存する場合は、実行環境に書き込み権限があること、および日本語表示に必要なフォントが利用可能であることも確認しておきましょう。
本章では、ASP.NET Framework アプリケーションにおいて C# を使用して PDF ファイルを生成する方法を紹介します。従来型の ASP.NET Web Forms および ASP.NET MVC プロジェクトのいずれにも適用可能です。
ASP.NET で PDF を生成する基本的な流れは次のとおりです。
以下は、PDF を作成してサーバー側に保存するシンプルな例です。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
PdfDocument document = new PdfDocument();
PdfPageBase page = document.Pages.Add();
// 日本語表示に対応したフォント(Yu Gothic UI)を指定
PdfTrueTypeFont font = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 12f, FontStyle.Regular),
true
);
page.Canvas.DrawString(
"本 PDF は、業務システムにより自動生成されたレポートです。",
font,
PdfBrushes.Black,
new PointF(40, 40)
);
// サーバー上に保存
document.SaveToFile(Server.MapPath("~/Output/Sample.pdf"));
document.Close();
この例では、ASP.NET 環境における PDF 生成の基本的な仕組みを示しています。PDF のページ構成、テキスト内容、配置位置はすべてコードで制御されているため、業務要件に応じてレイアウトを柔軟に調整できます。
必要に応じて、テキストだけでなく、表や画像を追加することで、請求書・帳票・報告書など、実用的な PDF ドキュメントを構築できます。
※ PDF に画像を挿入する方法については、次のチュートリアルを参照してください: C# を使用して PDF に画像を追加する方法
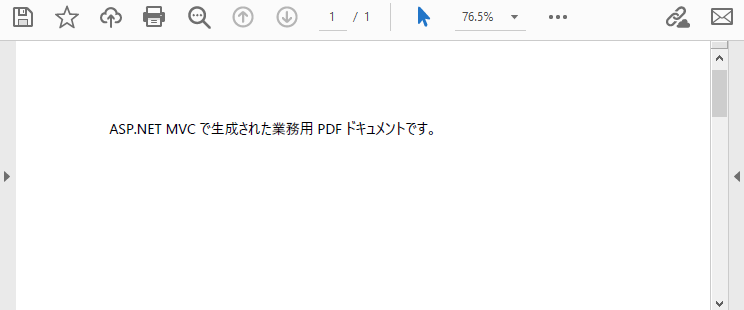
ASP.NET MVC プロジェクトでは、PDF は通常 Controller の Action メソッド内で生成され、 そのままブラウザへ返却されます。これにより、PDF を一時ファイルとして保存せず、オンライン表示やダウンロードを実現できます。
以下は、MVC コントローラーから PDF を返却する一般的な実装例です。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;
using System.Web.Mvc;
namespace WebApplication.Controllers
{
public class DefaultController : Controller
{
public ActionResult GeneratePdf()
{
using (PdfDocument document = new PdfDocument())
{
PdfPageBase page = document.Pages.Add();
PdfTrueTypeFont font = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 12f, FontStyle.Regular),
true
);
page.Canvas.DrawString(
"ASP.NET MVC で生成された業務用 PDF ドキュメントです。",
font,
PdfBrushes.Black,
new PointF(40, 40)
);
// メモリストリームに保存してブラウザへ返却
using (MemoryStream stream = new MemoryStream())
{
document.SaveToStream(stream);
return File(
stream.ToArray(),
"application/pdf",
"MvcSample.pdf"
);
}
}
}
}
}
生成された PDF の表示例は次のとおりです。
ヒント:ブラウザ上で PDF を直接プレビューしたい場合は、Spire.PDFViewer for ASP.NET を使用すると、Web ページ内で PDF を表示できます。
ASP.NET Core で PDF を生成する際、基本的な API の使い方は ASP.NET Framework とほぼ同じですが、ファイルの返却方法・パスの扱い・実行環境の前提条件には明確な違いがあります。
たとえば、ASP.NET Core では System.Web に依存せず、物理パスへの直接出力も推奨されていません。そのため、PDF は ストリーム(Stream)ベースで生成・返却する実装が一般的です。
本章では、ASP.NET Core MVC および ASP.NET Core Web API プロジェクトにおいて、C# を使って PDF を生成し、クライアントへ返却する方法を具体例とともに解説します。この方式は、クロスプラットフォーム環境やクラウド/コンテナ環境との親和性も高いのが特徴です。
ASP.NET Core MVC では、PDF は Controller の Action メソッド内で生成され、ファイルレスポンスとしてそのまま返却されるのが一般的です。
以下の例では、ASP.NET Core Web App(MVC)プロジェクトを作成し、Controllers フォルダーに PdfController を追加して PDF を生成します。
using Microsoft.AspNetCore.Mvc;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;
namespace CoreWebApplication.Controllers
{
public class PdfController : Controller
{
public IActionResult CreatePdf()
{
using (PdfDocument document = new PdfDocument())
{
PdfPageBase page = document.Pages.Add();
PdfTrueTypeFont font = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 14f, FontStyle.Bold),
true
);
page.Canvas.DrawString(
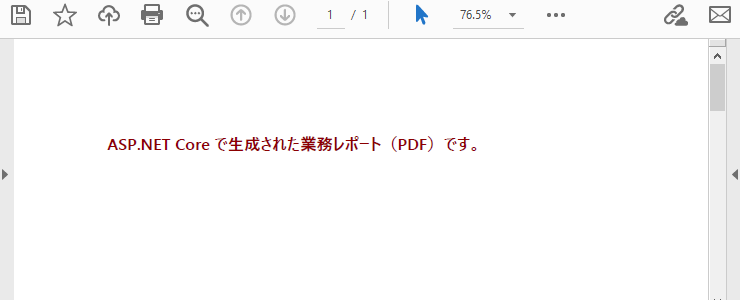
"ASP.NET Core で生成された業務レポート(PDF)です。",
font,
PdfBrushes.DarkRed,
new PointF(40, 40)
);
using (MemoryStream stream = new MemoryStream())
{
document.SaveToStream(stream);
return File(
stream.ToArray(),
"application/pdf",
"AspNetCoreSample.pdf"
);
}
}
}
}
}
生成される PDF の表示例は次のとおりです。
このようなストリームベースの PDF 生成方式は、社内管理画面や業務システムでの帳票出力など、「ユーザー操作に応じて即時ダウンロードする PDF」に非常に適しています。
PDF 内に表形式のデータを出力したい場合は、ASP.NET Core で C# を使用して PDF テーブルを生成する方法もあわせて参照してください。
フロントエンドとバックエンドを分離したアーキテクチャでは、PDF 生成処理を ASP.NET Core Web API として提供するケースが一般的です。
この場合、API は PDF を **バイナリデータ(byte 配列)**として返却し、Web フロントエンド、モバイルアプリ、または他のサービスから利用されます。
以下は、Web API で PDF を生成する基本的な実装例です。
using Microsoft.AspNetCore.Mvc;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;
[ApiController]
[Route("api/pdf")]
public class PdfApiController : ControllerBase
{
[HttpGet("generate")]
public IActionResult GeneratePdf()
{
PdfDocument document = new PdfDocument();
PdfPageBase page = document.Pages.Add();
PdfTrueTypeFont font = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 14f, FontStyle.Bold),
true
);
page.Canvas.DrawString(
"ASP.NET Core Web API により生成された PDF ドキュメントです。",
font,
PdfBrushes.BlueViolet,
new PointF(40, 40)
);
using (MemoryStream stream = new MemoryStream())
{
document.SaveToStream(stream);
document.Close();
return File(
stream.ToArray(),
"application/pdf",
"ApiGenerated.pdf"
);
}
}
}
生成された PDF のプレビュー例は次のとおりです。
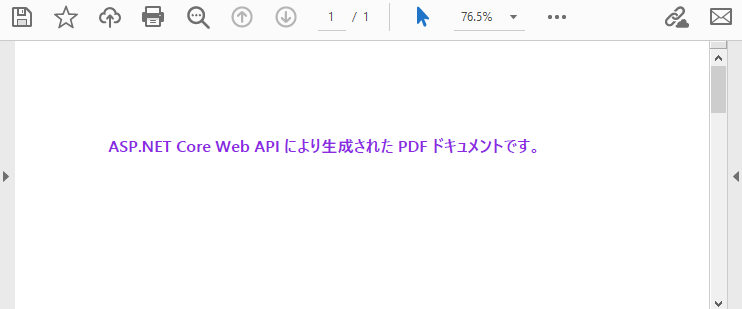
このように、PDF 生成を Web API として提供することで、フロントエンドの実装とドキュメント生成ロジックを明確に分離でき、システム全体の保守性と拡張性を高めることができます。
これまでの例では、PDF を作成するための基本的な流れを紹介してきました。しかし、実際の業務システムでは、PDF は固定文書ではなく、実行時のデータに基づいて動的に生成されるケースがほとんどです。
また、データ量の増加に伴い、レイアウトの維持や改ページ制御も重要な要件となります。本章では、代表的な応用シナリオを通して、ASP.NET アプリケーションで安定した構造を持つ PDF を生成する方法を解説します。
業務用 PDF では、データベースや Web API から取得した情報をもとに、受注一覧、売上レポート、明細表などを生成することが一般的です。
このようなケースでは、ループ処理でデータを描画しながら、縦位置(Y 座標)と改ページのタイミングを明示的に制御する必要があります。
以下の例では、簡易的な「受注レポート」を PDF として出力します。
PdfDocument document = new PdfDocument();
PdfPageBase page = document.Pages.Add();
PdfTrueTypeFont headerFont = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 12f, FontStyle.Bold),
true
);
PdfTrueTypeFont bodyFont = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 10f, FontStyle.Regular),
true
);
float startY = 40;
float y = startY;
float pageHeight = page.Canvas.ClientSize.Height - 40;
// タイトル
page.Canvas.DrawString(
"受注一覧レポート",
headerFont,
PdfBrushes.Black,
40,
y
);
y += 30;
// 動的データ(サンプル)
string[] orders =
{
"受注番号:A-1001 金額:¥250,000",
"受注番号:A-1002 金額:¥180,000",
"受注番号:A-1003 金額:¥320,000"
};
foreach (string order in orders)
{
// 改ページ判定
if (y > pageHeight)
{
page = document.Pages.Add();
y = startY;
}
page.Canvas.DrawString(
order,
bodyFont,
PdfBrushes.Black,
40,
y
);
y += 20;
}
document.SaveToFile("OrderReport.pdf");
document.Close();
出力結果のイメージ:
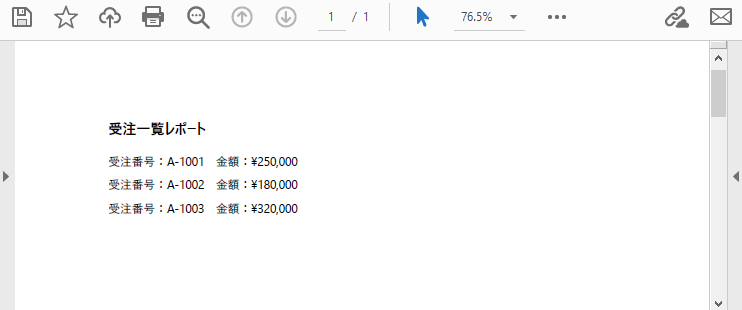
このように、コードで描画位置を管理することで、データ件数が変動してもレイアウトが崩れない PDF を生成できます。特に、帳票・一覧表・レポート系の出力では、この方法が非常に有効です。
コードベースで PDF を生成する場合、HTML のように自動でレイアウトが調整されることはありません。 そのため、ヘッダー・フッター・余白・行間などを明示的に定義する必要があります。
以下は、ページヘッダーとフッターを追加するシンプルな例です。
PdfPageBase page = document.Pages.Add();
PdfTrueTypeFont font = new PdfTrueTypeFont(
new Font("Yu Gothic UI", 10f),
true
);
// ヘッダー
page.Canvas.DrawString(
"社内資料(機密)",
font,
PdfBrushes.Gray,
new PointF(40, 15)
);
// フッター(ページ番号)
page.Canvas.DrawString(
"Page 1",
font,
PdfBrushes.Gray,
new PointF(
page.Canvas.ClientSize.Width - 60,
page.Canvas.ClientSize.Height - 30
)
);
出力結果のイメージ:
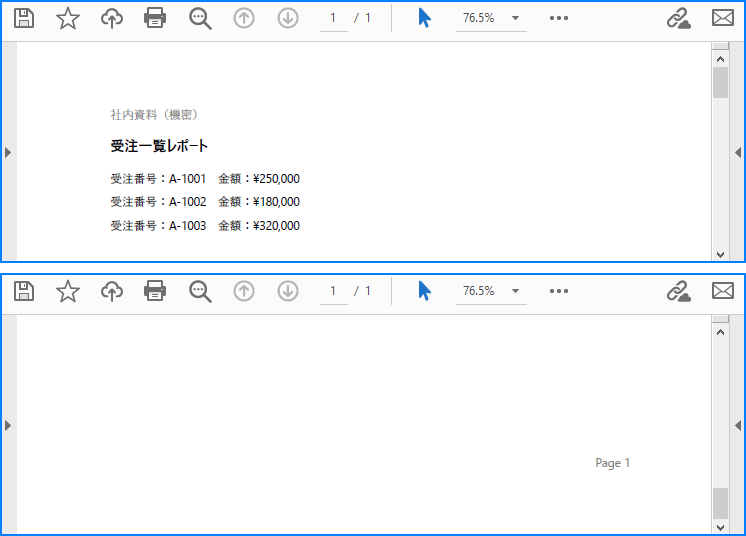
多ページの PDF ドキュメントを生成する場合、縦方向の位置計算を一元的に管理し、コンテンツを書き込む前に残りのスペースを判定することで、データが単一ページの容量を超えた際にも安全に新しいページへ切り替えることができます。
また、ヘッダー、行間、改ページのルールを集中的に管理することで、ページをまたいだレイアウトの一貫性を保ち、画面表示にも印刷にも適したドキュメントを生成できます。
ASP.NET アプリケーションでは、 直接 PDF を生成する方法以外にも、用途に応じた変換処理が利用されます。
以下の関連チュートリアルも参考にしてください。
ASP.NET または ASP.NET Core アプリケーションで PDF 生成を実装する際、どの PDF ライブラリを選択するかは、開発効率・保守性・実行時の安定性に直結します。
単に「機能が多いかどうか」だけで判断するのではなく、実際の運用シーンを想定した観点から評価することが重要です。
優れた PDF ライブラリは、次のような特徴を備えています。
PDF 出力ロジックは、帳票追加やレイアウト変更などにより長期的に拡張されることが多いため、API の理解しやすさは非常に重要です。
多くの開発現場では、次のような環境が混在しています。
そのため、同一の API で両環境に対応できる PDF ライブラリを選択することで、 移行コストや学習コストを大幅に削減できます。
本番環境での PDF 生成は、次のような条件下で実行されることが一般的です。
そのため、大量ページの PDF を安定して生成できるか、メモリ使用量が適切に制御されているかといった点も重要な評価基準となります。
ASP.NET における PDF 生成ライブラリは、大きく次の 2 種類に分けられます。
HTML 変換型は、既存の Web ページをそのまま PDF 化できる一方で、ブラウザ依存やレイアウトの再現性に課題が生じることがあります。一方、コード生成型PDFライブラリは、ページ構造、ページ分割、印刷効果を精密に制御でき、レポート、請求書、報告書、契約書などの業務文書生成シーンに特に適しています。
ASP.NET で PDF 生成を行う場合、「簡単に作れるか」よりも 「安定して運用できるか」 を重視して PDF ライブラリを選定することが、長期的には大きなメリットになります。
数ある .NET 向け PDF ライブラリの中でも、Spire.PDF for .NET は、ASP.NET および ASP.NET Core 環境において業務用途の PDF 生成に特化した機能と設計を備えています。
以下では、実際の開発・運用の視点から、その主な特長を整理します。
Spire.PDF は、PDF ドキュメントを構成する各要素を 明確なクラス構造として提供しています。
これにより、レイアウト意図をコード上で明確に表現できるため、帳票やレポートのような複雑な構成でも保守性を維持しやすくなります。
業務システムでは、日本語・英語・中国語など複数言語を含む PDF 出力が求められるケースが少なくありません。
Spire.PDF では、TrueType フォントを直接指定できるため、
などの 日本語フォントを正しく埋め込んだ PDF を生成できます。
これにより、
といった点で、大きなメリットがあります。
Spire.PDF for .NET は、
といった複数の実行環境に対応しており、同一のコードベースで PDF 生成処理を共通化できます。
これにより、
にも柔軟に対応可能です。
Spire.PDF は、単なるテキスト出力にとどまらず、 実務で必要とされる機能を幅広くサポートしています。
これにより、 請求書・見積書・業務レポートなどの PDF を コードベースで安定して生成できます。
可能です。ASP.NET Core での PDF 生成は MVC に依存する必要はありません。MVC コントローラー以外でも、以下のような場面で PDF を生成して返すことができます:
返却する内容が有効な PDF バイト列であり、Content-Type を正しく設定していれば、正常に動作します。
PDF 作成の基本的なロジックは共通していますが、いくつかの差異があります:
PDF API の観点から見ると、大部分のコードロジックは共通して再利用可能です。
可能です。多くの実運用システムでは、C# コードのみで PDF を生成しています。この方法には以下の利点があります:
一貫性と信頼性を重視する ASP.NET PDF ソリューションでは、この実装方式が非常に一般的です。
ASP.NET および ASP.NET Core アプリケーションにおいて、PDF ファイルを生成することは非常に一般的な要件であり、特に帳票、請求書、データエクスポートなどのシーンで有用です。C# コードを直接用いて PDF を生成することで、文書の構造、レイアウト、出力挙動を完全に制御できます。
本記事では、ASP.NET Framework と ASP.NET Core における PDF 生成方法を体系的に解説し、MVC や Web API の各シナリオ、動的データ出力、基本的なレイアウト制御をカバーしました。また、実際のプロジェクト要件に応じて適切な PDF ライブラリを選択するポイントについても触れています。
実際のプロジェクト環境でこれらのサンプルを制限なく試したい場合は、試用ライセンスを申請 することで、評価段階で全機能を利用できます。

Python で Excel ファイルを作成することは、データドリブンなアプリケーションにおいて非常に一般的な要件です。
業務ユーザーが内容を確認・共有しやすい形式でアプリケーションデータを提供する必要がある場合、Excel は現在でも最も実用的で広く受け入れられている選択肢の一つです。
実際のプロジェクトでは、Python を使って Excel ファイルを生成する処理は、自動化フローの出発点になることがよくあります。
データはデータベース、API、内部サービスなどから取得され、Python がそれらを一定のレイアウトや命名規則に従った構造化された Excel ファイルへ変換します。
本記事では、Spire.XLS for Python を使用した Python による Excel ファイル作成について、ワークブックを一から生成する方法をはじめ、データの書き込み、基本的な書式設定、既存ファイルの更新までを段階的に解説します。 すべてのサンプルは、実際の自動化シナリオを想定した実用的な視点で紹介します。
目次
Python による Excel ファイル作成は、単独の処理としてではなく、より大きなシステムの一部として利用されることがほとんどです。代表的な例は次のとおりです。
これらの場面では、Python を用いて Excel ファイルを自動生成することで、手作業を削減し、データの一貫性と再現性を確保できます。
本チュートリアルでは、Excel 操作の例として Spire.XLS for Python を使用します。
Excel ファイルを生成する前に、開発環境を整えておきましょう。
Excel 自動化には、Python 3.x のいずれの最新版でも問題ありません。
Spire.XLS for Python は pip から簡単にインストールできます。
pip install Spire.XLS
または、Spire.XLS for Python をダウンロード して、プロジェクトに手動で組み込むことも可能です。
本ライブラリは Microsoft Excel に依存せず動作するため、サーバー環境、定期実行ジョブ、Excel がインストールされていない自動化環境にも適しています。
このセクションでは、Python を使用して Excel ファイルを一から作成する方法を紹介します。 データを書き込む前に、ワークブックやワークシート、ヘッダー行などの基本構造を定義することが目的です。
初期レイアウトをコードで生成することで、すべての出力ファイルが同じ構造を持ち、後続のデータ処理に適した状態になります。
from spire.xls import Workbook, FileFormat
# 新しいワークブックを作成
workbook = Workbook()
# 既定のワークシートを取得
sheet = workbook.Worksheets[0]
sheet.Name = "テンプレート"
# タイトル用のプレースホルダーを追加
sheet.Range["B2"].Text = "月次レポート(テンプレート)"
# Excelファイルとして保存
workbook.SaveToFile("template.xlsx", FileFormat.Version2016)
workbook.Dispose()
テンプレートファイルのプレビュー:

この例では次の処理を行っています。
Python による Excel 自動生成では、1 つのワークブック内に複数のワークシートを配置し、関連データを論理的に整理することが一般的です。 各ワークシートには、異なるデータセット、集計結果、処理結果を格納できます。
from spire.xls import Workbook, FileFormat
workbook = Workbook()
# 最初のワークシートを取得して名前を設定
sales_sheet = workbook.Worksheets[0]
sales_sheet.Name = "売上データ"
# 不要な2番目のワークシートを削除
workbook.Worksheets.RemoveAt(1)
# 集計用の新しいワークシートを追加
report_sheet = workbook.Worksheets.Add("集計")
report_sheet.Range["A1"].Text = "月次売上レポート"
# ファイルを保存
workbook.SaveToFile("sales_report.xlsx", FileFormat.Version2016)
workbook.Dispose()
この構成は、1 つのシートに元データを読み込み、別のシートに処理結果を書き出すといった読み書きワークフローでよく利用されます。
Python で Excel ファイルを生成する場合、XLSX は最も一般的な形式で、最新の Microsoft Excel で完全にサポートされています。 複数シート、数式、書式設定にも対応しており、ほとんどの自動化シナリオに適しています。
Spire.XLS for Python では、以下の形式も生成可能です。
本記事では、レポート生成やテンプレート用途に適した XLSX 形式を使用します。対応形式の一覧は FileFormat 列挙型 を参照してください。
実際のアプリケーションでは、Excel に書き込まれるデータがコード内にハードコードされることはほとんどありません。
多くの場合、データはデータベースのクエリ結果、API レスポンス、または中間処理の結果として生成されます。
一般的なパターンとして、すでに構造化されたデータの最終出力先として Excel を使用するケースが挙げられます。
ここでは、アプリケーション側ですでに売上データが生成されていると仮定します。
各レコードには、商品情報と計算済みの数値が含まれており、Python ではそれを 辞書のリスト として扱います。
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "売上レポート"
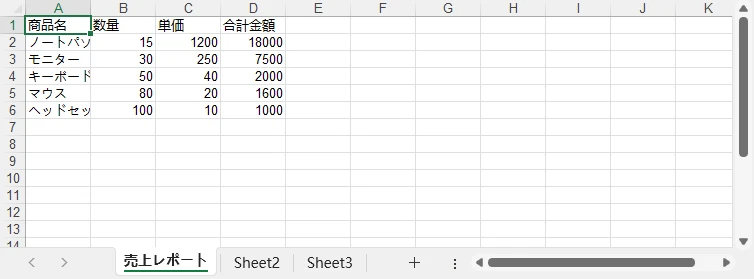
# ヘッダー行の設定
headers = ["商品名", "数量", "単価", "合計金額"]
for col, header in enumerate(headers, start=1):
sheet.Range[1, col].Text = header
# 通常、データはデータベースやサービス層から取得される
sales_data = [
{"product": "ノートパソコン", "qty": 15, "price": 1200},
{"product": "モニター", "qty": 30, "price": 250},
{"product": "キーボード", "qty": 50, "price": 40},
{"product": "マウス", "qty": 80, "price": 20},
{"product": "ヘッドセット", "qty": 100, "price": 10}
]
# データ行の入力
row = 2
for item in sales_data:
sheet.Range[row, 1].Text = item["product"]
sheet.Range[row, 2].NumberValue = item["qty"]
sheet.Range[row, 3].NumberValue = item["price"]
sheet.Range[row, 4].NumberValue = item["qty"] * item["price"]
row += 1
# Excelファイルの保存
workbook.SaveToFile("monthly_sales_report.xlsx")
workbook.Dispose()
月次売上レポートのプレビュー:
この例では、商品名などの文字列は CellRange.Text、数量や金額などの数値は CellRange.NumberValue を使用して書き込んでいます。 これにより、Excel 上で正しく計算・並び替え・書式設定を行うことができます。
この方法はデータ量が増えても自然にスケールし、ビジネスロジックと Excel 出力処理を分離できる点が特長です。 さらに詳しい書き込み例については、PythonでExcel書き込みを自動化する方法 を参照してください。
実際の業務では、Excel ファイルはそのまま関係者へ共有されることが多く、 書式設定のない生データは可読性や理解性に欠ける場合があります。
よく行われる書式設定には、次のようなものがあります。
以下の例では、これらの基本的な書式設定を組み合わせて、レポートの視認性を向上させています。
from spire.xls import Workbook, Color, LineStyleType
# 作成済みのExcelファイルを読み込む
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# 使用されているセルのフォント名を設定する
sheet.Range.Style.Font.FontName = "Yu Gothic UI"
# ヘッダー行の書式設定
header_range = sheet.Range.Rows[0]
header_range.Style.Font.IsBold = True
header_range.Style.Font.Size = 12
header_range.Style.Color = Color.get_LightBlue()
# 通貨形式を適用
sheet.Range["C2:D6"].NumberFormat = "$#,##0.00"
# データ行の背景色を交互に設定
for i in range(1, sheet.Range.Rows.Count):
row_range = sheet.Range[i, 1, i, sheet.Range.Columns.Count]
if i % 2 == 0:
row_range.Style.Color = Color.get_LightGreen()
else:
row_range.Style.Color = Color.get_LightYellow()
# データ範囲に罫線を追加
sheet.Range["A2:D6"].BorderAround(LineStyleType.Medium, Color.get_LightBlue())
# 列幅を自動調整
sheet.AllocatedRange.AutoFitColumns()
# 書式設定済みファイルを保存
workbook.SaveToFile("monthly_sales_report_formatted.xlsx")
workbook.Dispose()
書式設定後の月次売上レポート:

書式設定はデータの正確性そのものには影響しませんが、 共有・保存される業務レポートでは、事実上必須とされることが多いです。 より高度な書式設定については、PythonでExcelワークシートの書式設定を行う方法 を参照してください。
既存の Excel ファイルを更新する場合、特定のセルを固定位置で更新するのではなく、 条件に一致する行を検索して更新するケースが一般的です。
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("monthly_sales_report.xlsx")
sheet = workbook.Worksheets[0]
# 商品名で対象行を検索し、ステータスを設定
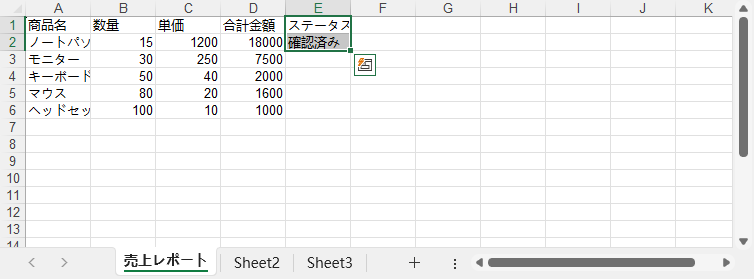
sheet.Range["E1"].Text = "ステータス" # ヘッダーを設定
for row in range(2, sheet.LastRow + 1):
product_name = sheet.Range[row, 1].Text
if product_name == "ノートパソコン": # 日語商品名に合わせる
sheet.Range[row, 5].Text = "確認済み"
break
# 更新されたファイルを保存
workbook.SaveToFile("monthly_sales_report_updated.xlsx")
workbook.Dispose()
更新後の月次売上レポート:
外部から取り込んだ Excel ファイルのデータは、そのままでは分析やレポートに適さないことがあります。 重複行、不整合な値、不完全なデータなどが含まれている場合が少なくありません。
実際の自動化システムでは、Excel ファイルは最終成果物ではなく中間データとして使われることも多く、 次のような課題が頻繁に発生します。
こうした場合、Excel を読み込み、Python 側で正規化・集計処理を行い、結果を新しいシートに書き出すことが一般的です。
以下の例では、商品ごとに複数行存在する売上データを読み込み、 商品ごとの合計売上金額を計算した サマリーシート を生成します。
from spire.xls import Workbook, Color
workbook = Workbook()
workbook.LoadFromFile("raw_sales_data.xlsx")
source = workbook.Worksheets[0]
summary = workbook.Worksheets.Add("集計") # 日語名に変更
# 出力用ヘッダーを定義
summary.Range["A1"].Text = "注文ID"
summary.Range["B1"].Text = "売上合計"
product_totals = {}
# 元データを読み込み、商品ごとに売上を集計
for row in range(2, source.LastRow + 1):
product = source.Range[row, 1].Text
value = source.Range[row, 4].Value
# 不完全・無効な行をスキップ
if not product or value is None:
continue
try:
amount = float(value)
except ValueError:
continue
if product not in product_totals:
product_totals[product] = 0
product_totals[product] += amount
# 集計結果を書き込み
target_row = 2
for product, total in product_totals.items():
summary.Range[target_row, 1].Text = product
summary.Range[target_row, 2].NumberValue = total
target_row += 1
# 合計行を追加
summary.Range[summary.LastRow, 1].Text = "合計"
summary.Range[summary.LastRow, 2].Formula = "=SUM(B2:B" + str(summary.LastRow - 1) + ")"
# 書式設定
summary.Range.Style.Font.FontName = "Yu Gothic UI"
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.Size = 12
summary.Range[1, 1, 1, summary.LastColumn].Style.Font.IsBold = True
for row in range(2, summary.LastRow + 1):
for column in range(1, summary.LastColumn + 1):
summary.Range[row, column].Style.Font.Size = 10
summary.Range[
summary.LastRow, 1, summary.LastRow, summary.LastColumn
].Style.Color = Color.get_LightGray()
summary.Range.AutoFitColumns()
workbook.SaveToFile("normalized_sales_summary.xlsx")
workbook.Dispose()
正規化・集計後のサマリー:

データ検証や集計、正規化といった処理は Python が担い、Excel は業務ユーザー向けの最終出力形式として利用されます。これにより、手作業による修正や複雑な数式に頼る必要がなくなります。
Python には Excel ファイルを作成する方法が複数存在しますが、 最適な選択は Excel をワークフローの中でどのように使うかによって異なります。
Spire.XLS for Python は、次のようなシナリオに特に適しています。
データ分析や統計処理は別のライブラリで行い、 最終段階で Free Spire.XLS を使って Excel ファイルを生成するという構成も一般的です。
このように処理と表示を分離することで、保守性と信頼性を高めることができます。 詳細なガイドについては、Spire.XLS for Python チュートリアル を参照してください。
Excel 自動化では、次のような実務的な問題に遭遇することがあります。
ファイルパスや権限エラー 保存先ディレクトリの存在と書き込み権限を事前に確認してください。
想定外のデータ型 文字列と数値を明示的に使い分け、Excel 上での計算エラーを防ぎます。
ファイルの上書き タイムスタンプ付きのファイル名や専用出力フォルダを利用しましょう。
大規模データの処理 行単位で順次書き込み、ループ内での不要な書式設定を避けることが重要です。
これらを早期に考慮することで、データ量や処理の複雑さが増しても安定した自動化が可能になります。
PythonでExcelファイルを作成することは、レポート作成、データエクスポート、ドキュメント更新を自動化するための実用的な手段です。 ファイル生成、構造化データの書き込み、書式設定、更新処理を組み合わせることで、 単発のスクリプトを超えた安定した自動化システムを構築できます。
Spire.XLS for Python は、自動化・一貫性・保守性が求められる環境において、 Excel 処理を確実に実装するための有効な選択肢です。 一時ライセンスを申請 することで、Excel 自動化の可能性を最大限に活用できます。
はい。 Spire.XLS for Python のようなライブラリは Microsoft Excel に依存せず動作するため、 サーバー環境やクラウド、自動化ワークフローに適しています。
適切に実装すれば可能です。 行を順次書き込み、ループ内で不要な書式設定を避けることで、大量データにも対応できます。
タイムスタンプ付きのファイル名を使用する、 または出力専用ディレクトリを用意する方法が一般的です。
はい。 対応しているファイル形式であれば、Python で読み取り・修正・拡張が可能です。

HTMLの解析は、Java開発において非常に重要な処理のひとつです。構造化データの抽出、コンテンツ分析、Webベースの情報活用など、さまざまな場面で活用されます。Webスクレイパーの構築、HTMLコンテンツの検証、Webページからのテキストや属性の抽出など、用途は多岐にわたりますが、信頼性の高いツールを使うことで実装は大幅に簡素化できます。
本ガイドでは、Spire.Doc for Java を使用して JavaでHTMLを解析する方法 を解説します。Spire.Docは、HTML解析とドキュメント処理を統合的に扱える強力なライブラリで、実用的なHTMLデータ抽出を効率よく実装できます。
JavaにはJsoupなど複数のHTML解析ライブラリがありますが、Spire.Docはドキュメント処理との親和性と低コードで実装できる点が大きな特長です。効率を重視する開発者にとって、以下の理由からHTML解析用途に適しています。
JavaでHTMLを読み込む前に、以下の環境が整っていることを確認してください。
Mavenを使用する場合
以下のリポジトリと依存関係を pom.xml に追加します。必要なライブラリは自動的にダウンロードされます。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.12.2</version>
</dependency>
手動で導入する場合は、公式サイト からJARファイルをダウンロードし、プロジェクトに追加してください。
デフォルトでは、Spire.Docの出力結果に評価用ウォーターマークが付与されます。制限を解除するには、30日間の無料トライアルライセンス を申請できます。
Spire.Docは、HTMLを構造化されたドキュメントモデルに変換します。段落、表、フィールドなどの要素をJavaオブジェクトとして直接操作できるため、データ抽出が容易になります。ここでは代表的なケースを紹介します。
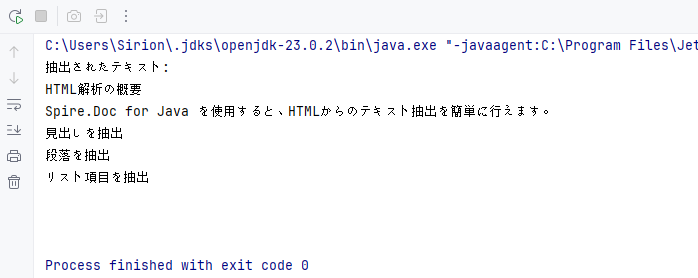
HTMLタグを除外した純粋なテキスト抽出は、全文検索やコンテンツ分析でよく使われます。以下の例では、HTML文字列を解析し、すべての段落テキストを取得します。
Javaコード:HTML文字列からテキストを抽出
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTextFromHtml {
public static void main(String[] args) {
// 解析するHTMLコンテンツを定義
String htmlContent = "<html>" +
"<body>" +
"<h1>HTML解析の概要</h1>" +
"<p>Spire.Doc for Java を使用すると、HTMLからのテキスト抽出を簡単に行えます。</p>" +
"<ul>" +
"<li>見出しを抽出</li>" +
"<li>段落を抽出</li>" +
"<li>リスト項目を抽出</li>" +
"</ul>" +
"</body>" +
"</html>";
// 解析したHTMLを格納するためのDocumentオブジェクトを作成
Document doc = new Document();
// HTML文字列をドキュメントに解析して追加
doc.addSection().addParagraph().appendHTML(htmlContent);
// すべての段落からテキストを抽出
StringBuilder extractedText = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph paragraph : (Iterable<Paragraph>) section.getParagraphs()) {
extractedText.append(paragraph.getText()).append("\n");
}
}
// 抽出したテキストを出力または後続処理
System.out.println("抽出されたテキスト:\n" + extractedText);
}
}
出力例:
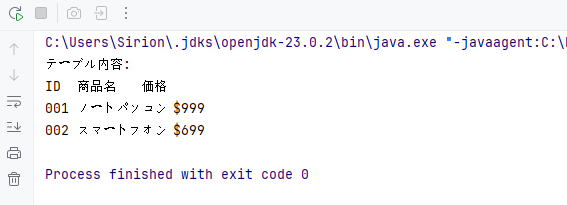
HTMLの <table> 要素は、商品一覧やレポートなどの構造化データを含むことが多くあります。Spire.Docでは、HTMLテーブルを Table オブジェクトとして扱えるため、行やセル単位で簡単にアクセスできます。
Javaコード:HTMLテーブルの行・セルを抽出
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTableFromHtml {
public static void main(String[] args) {
// テーブルを含むHTMLコンテンツ
String htmlWithTable = "<html>" +
"<body>" +
"<table border='1'>" +
"<tr><th>ID</th><th>商品名</th><th>価格</th></tr>" +
"<tr><td>001</td><td>ノートパソコン</td><td>$999</td></tr>" +
"<tr><td>002</td><td>スマートフォン</td><td>$699</td></tr>" +
"</table>" +
"</body>" +
"</html>";
// HTMLをDocumentオブジェクトに解析して読み込む
Document doc = new Document();
doc.addSection().addParagraph().appendHTML(htmlWithTable);
// テーブルデータを抽出
for (Section section : (Iterable<Section>) doc.getSections()) {
// セクション本文内のすべてのオブジェクトを走査
for (Object obj : section.getBody().getChildObjects()) {
if (obj instanceof Table) { // オブジェクトがテーブルかどうかを判定
Table table = (Table) obj;
System.out.println("テーブル内容:");
// 行を順に処理
for (TableRow row : (Iterable<TableRow>) table.getRows()) {
// 行内のセルを順に処理
for (TableCell cell : (Iterable<TableCell>) row.getCells()) {
// 各セル内の段落からテキストを抽出
for (Paragraph para : (Iterable<Paragraph>) cell.getParagraphs()) {
System.out.print(para.getText() + "\t");
}
}
System.out.println(); // 各行の後で改行
}
}
}
}
}
}
出力例:
appendHTML() メソッドでHTMLをWordドキュメントとして解析した後、Spire.DocのAPIを使って ハイパーリンクを抽出 することも可能です。
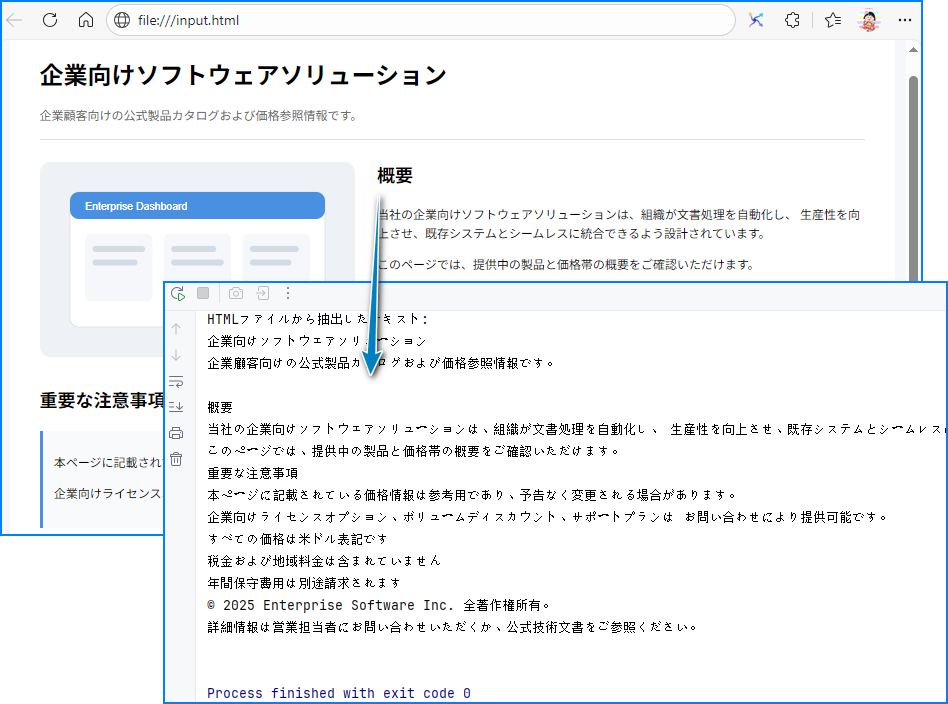
Spire.Doc for Javaは、ローカルHTMLファイルやWeb上のURLからHTMLを解析することもでき、実運用に適した柔軟性を備えています。
ローカルのHTMLファイルは、loadFromFile(String, FileFormat.Html) メソッドを使用して読み込みます。
Javaコード:ローカルHTMLファイルを解析
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ParseHtmlFile {
public static void main(String[] args) {
// Documentオブジェクトを作成
Document doc = new Document();
// HTMLファイルを読み込む
doc.loadFromFile("input.html", FileFormat.Html);
// テキストを抽出して出力
StringBuilder text = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
text.append(para.getText()).append("\n");
}
}
System.out.println("HTMLファイルから抽出したテキスト:\n" + text);
}
}
この例ではHTMLファイル内のテキストを抽出しています。段落のスタイル(例:「Heading1」「Normal」)も同時に取得したい場合は、Paragraph.getStyleName() メソッドを使用します。
出力例:
関連情報:JavaでWordをHTMLに変換
実際のWebスクレイピングでは、URLからHTMLを取得して解析する必要があります。Spire.Docは、JDK 11以降で利用可能な HttpClient と組み合わせて使用できます。
Javaコード:URLからHTMLを取得して解析
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class ParseHtmlFromUrl {
// 再利用可能な HttpClient(タイムアウトを設定してハングアップを防ぐ)
private static final HttpClient httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
public static void main(String[] args) {
String url = "https://jp.e-iceblue.com/misc/privacy-policy.html";
try {
// URLからHTMLコンテンツを取得
System.out.println("Fetching from: " + url);
String html = fetchHtml(url);
// Spire.DocでHTMLを解析
Document doc = new Document();
Section section = doc.addSection();
section.addParagraph().appendHTML(html);
System.out.println("--- 見出し ---");
// 見出しを抽出
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
// 段落スタイルが見出しかどうかを確認(例:"Heading1", "Heading2")
if (para.getStyleName() != null && para.getStyleName().startsWith("Heading")) {
System.out.println(para.getText());
}
}
} catch (Exception e) {
System.err.println("エラー: " + e.getMessage());
}
}
// ヘルパーメソッド: 指定したURLからHTMLコンテンツを取得
private static String fetchHtml(String url) throws Exception {
// User-Agentヘッダー付きでHTTPリクエストを作成(ブロック回避のため)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("User-Agent", "Mozilla/5.0")
.timeout(Duration.ofSeconds(10))
.GET()
.build();
// リクエストを送信してレスポンスを取得
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
// リクエストが成功したか確認(HTTP 200 = OK)
if (response.statusCode() != 200) {
throw new Exception("HTTPエラー: " + response.statusCode());
}
return response.body(); // 生のHTMLコンテンツを返す
}
}
処理のポイント:
出力例:
JavaでのHTML解析は、Spire.Doc for Javaを使うことで大幅に簡素化できます。HTML文字列、ローカルファイル、URLのいずれからでも、テキストや表データを最小限のコードで抽出可能です。生のHTMLタグを直接扱ったり、重い依存関係を管理したりする必要はありません。
Webスクレイピング、コンテンツ分析、HTML変換(例:HTMLをPDFに変換)など、さまざまな用途で活用できます。本ガイドの手順に沿って実装すれば、Javaプロジェクトに実用的なHTML解析機能をスムーズに組み込めるでしょう。
A:用途によって異なります。
A:はい。Spire.Doc for Javaでは、XHTMLValidationType.None を指定して厳密な検証を無効化することで、不完全なHTML構造にも対応できます。
doc.loadFromFile("input.html", FileFormat.Html, XHTMLValidationType.None);
ただし、構造が大きく崩れているHTMLでは、解析に失敗する場合があります。
A:可能です。段落テキストの編集、表の行削除、新しい要素の追加などを行った後、HTMLとして保存できます。
doc.saveToFile("modified.html", FileFormat.Html);
A:ローカルファイルやHTML文字列を解析する場合、インターネット接続は不要です。URLからHTMLを取得する場合のみ、事前にネットワーク接続が必要になります。

Java での PDF 解析は、PDFを単に画面表示するだけでなく、内部に含まれる情報をプログラムで抽出・活用したい場合によく必要とされます。代表的なユースケースとしては、ドキュメントのインデックス化、自動レポート処理、請求書分析、データ取り込みパイプラインなどが挙げられます。
JSON や XML のような構造化データ形式とは異なり、PDF は見た目の正確な再現(ビジュアル忠実度)を目的として設計されています。そのため、テキスト・表・画像といった要素は、論理構造としてではなく、描画位置を指定する命令の集合として格納されています。
このような特性から、Java で PDF を解析する際には、PDF内部のコンテンツ表現を理解し、それを Java ライブラリがどのように API として提供しているかを把握することが重要になります。
本記事では、Spire.PDF for Java を使用し、実際の Java アプリケーションで役立つ PDF 解析処理を実践的に解説します。PDF 解析を一連の単一フローとして扱うのではなく、テキスト・表・画像・メタデータといった目的別の抽出タスクごとに説明していきます。
目次
実装の観点から見ると、Java での PDF 解析は単一の処理ではなく、同一ドキュメントに対して実行される複数の抽出タスクの集合です。アプリケーションが必要とするデータの種類に応じて、実行すべき解析処理が決まります。
実際のシステムにおいて、PDF 解析は主に以下の情報を取得する目的で使用されます。
PDF 解析が複雑になる最大の理由は、PDF が論理構造を保持しない形式であることにあります。段落、行、表といった構造は明示的には保存されず、主に以下の要素として表現されています。
そのため、Java での PDF 解析は、あらかじめ定義されたデータ構造を読み取るのではなく、レイアウト情報から意味を再構築する処理になります。
このような理由から、実用的な Java 実装では、低レベルなページコンテンツへアクセスできるだけでなく、テキスト抽出や表検出といった高レベル機能も提供する専用 PDF 解析ライブラリを利用するのが一般的です。これにより、独自ロジックの実装量を大幅に削減できます。
本番環境では、PDF 解析を厳密なステップ型パイプラインとして設計するよりも、必要に応じて個別に適用可能な独立した解析処理の集合として設計する方が適しています。
この設計により、障害の切り分けが容易になり、アプリケーションは本当に必要な解析処理だけを選択的に実行できます。
ここでは、テキスト抽出、表検出、画像エクスポート、メタデータ取得などの API を提供する Java PDF ライブラリ Spire.PDF for Java を使用します。バックエンドサービス、バッチ処理、ドキュメント自動化システムなどに適しています。
ライブラリは Spire.PDF for Java ダウンロードページ から取得し、手動でプロジェクトに追加できます。
Maven を使用している場合は、以下の依存関係を追加することで簡単に導入できます。
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.11.11</version>
</dependency>
インストール後は、外部ツールに依存せず、Java コードだけで PDF ドキュメントの読み込み・解析が可能になります。
解析処理を行う前に、まず PDF ドキュメントを読み込み、安全に処理できるかどうかを検証する必要があります。このステップは、後続の解析ロジックとは独立した処理として扱うのが望ましいです。
import com.spire.pdf.PdfDocument;
public class loadPDF {
public static void main(String[] args) {
// PdfDocument インスタンスを作成
PdfDocument pdf = new PdfDocument();
// PDF ファイルを読み込み
pdf.loadFromFile("sample.pdf");
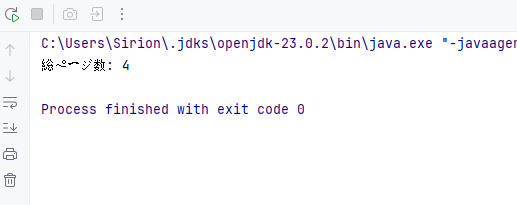
// ページ数を取得
int pageCount = pdf.getPages().getCount();
System.out.println("総ページ数: " + pageCount);
}
}
コンソール出力例
実装上、この段階で以下の重要な点が確認できます。
本番システムでは、この検証処理がゲートキーパーとして機能し、読み込みに失敗した PDF は早期に除外されます。
ドキュメント検証と抽出ロジックを分離することで、特にバッチ処理や自動解析フローにおいて、障害の連鎖を防ぐことができます。
テキスト解析は、Java における PDF 処理で最も一般的なタスクの一つです。PDF ページから可読なテキストを抽出・再構成する処理を指します。
Spire.PDF for Java では、単一の高レベル API に頼るのではなく、PdfTextExtractor クラスと PdfTextExtractOptions を組み合わせて実装することで、柔軟かつ制御しやすいテキスト抽出が可能です。
テキスト解析を独立した処理として設計することで、インデックス作成、分析、コンテンツ移行など、必要なタイミングで自由に利用できます。
一般的な Java 実装では、テキスト解析は以下の明確なステップで構成されます。
このページ単位の設計は、PDF の内部構造と自然に対応しており、複数ページの処理でも高い制御性を提供します。
以下は、Spire.PDF for Java の PdfTextExtractor と PdfTextExtractOptions を使用して、PDF ファイルからテキストを抽出する例です。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
public class extractPdfText {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// 抽出結果を効率的に保持するため StringBuilder を使用
StringBuilder extractedText = new StringBuilder();
// テキスト抽出オプションを設定
PdfTextExtractOptions options = new PdfTextExtractOptions();
// シンプル抽出モードを有効化(可読性向上)
options.setSimpleExtraction(true);
// 各ページを順に処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// ページごとに PdfTextExtractor を作成
PdfTextExtractor extractor =
new PdfTextExtractor(pdf.getPages().get(i));
// オプションを指定してテキストを抽出
String pageText = extractor.extract(options);
extractedText.append(pageText).append("\n");
}
System.out.println(extractedText.toString());
}
}
コンソール出力例
PdfTextExtractor ページ単位で動作し、テキスト再構成を細かく制御できます。
PdfTextExtractOptions 抽出挙動を調整可能です。setSimpleExtraction(true) を有効にすると、レイアウト処理を簡略化し、読みやすいテキストが得られます。
ページ単位処理 大容量 PDF への対応や、問題のあるページの切り分けが容易になります。
この方法は、レポート、契約書など、比較的レイアウトが安定したテキスト中心の PDF に適しており、Spire.PDF for Java を使用した Java での PDF テキスト解析として推奨されるアプローチです。 その他のテキスト抽出の例については、「Javaを使用してPDFページからテキストを抽出する方法」を参照してください。
**表解析(テーブル抽出)**は、PDF 内の表構造を検出し、行と列を持つ構造化データとして再構築する高度な解析処理です。単純なテキスト抽出と異なり、セル間の意味的な関係を保持できるため、請求書、財務諸表、業務レポートなどで広く利用されます。
Java で PDF を解析する際、表解析を行うことで、視覚的に整列された情報をプログラムで扱いやすい構造化データへ変換できます。
表解析では、単純なテキスト抽出から、視覚的な配置とレイアウトの一貫性に基づく構造推定へと処理の焦点が移ります。
表解析は、テキストの位置関係をもとに構造を推定するため、行・列インデックスを用いたセル単位のアクセスが可能になります。
以下は、Spire.PDF for Java の PdfTableExtractor を使用して PDF ページから表を解析する例です。抽出された表は、行と列を持つ構造化データとして扱えます。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
public class extractPdfTable {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// 表抽出器を作成
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// 1 ページ目から表を解析(インデックスは 0 から)
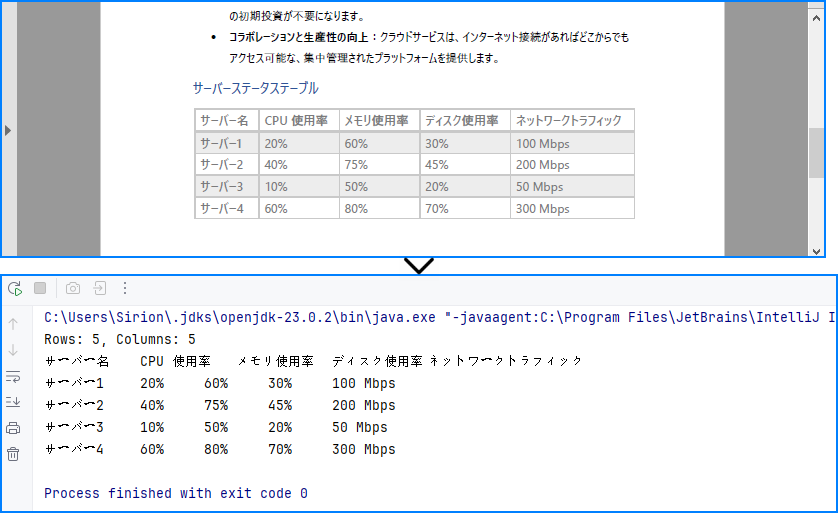
PdfTable[] tables = extractor.extractTable(0);
if (tables != null) {
for (PdfTable table : tables) {
int rowCount = table.getRowCount();
int columnCount = table.getColumnCount();
System.out.println("Rows: " + rowCount +
", Columns: " + columnCount);
StringBuilder tableData = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
tableData.append(table.getText(i, j));
if (j < columnCount - 1) {
tableData.append("\t");
}
}
if (i < rowCount - 1) {
tableData.append("\n");
}
}
System.out.println(tableData.toString());
}
}
}
}
コンソール出力例
PdfTableExtractor ページコンテンツを解析し、視覚的な配置情報から表領域を検出します。
構造の再構築 テキスト要素の相対位置に基づいて行・列を推定し、セル単位でのアクセスを可能にします。
ページ単位解析 ページごとのレイアウト差異に対応しやすく、精度向上につながります。
制約はあるものの、表解析は Java における PDF 解析機能の中でも特に価値が高く、業務文書からのデータ自動抽出において重要な役割を果たします。
PDFページから表構造を解析した後、抽出されたデータは「JavaでPDF表をCSVに変換する」で示されているように、さらなる利用のためにCSVなどの構造化形式へエクスポートされることが多い。
画像解析(画像抽出)は、PDF ページ内に埋め込まれている画像リソースを抽出することに特化した PDF 解析機能です。テキストや表の解析がコンテンツストリームやレイアウト推定に基づくのに対し、画像解析はページレベルのリソース情報を解析し、画像オブジェクトを直接取得します。
Java ベースの PDF 処理システムでは、画像解析は以下のような用途でよく利用されます。
実装レベルでは、画像解析はテキスト解析とは異なり、ページのリソース情報を対象として処理が行われます。
画像はページの独立したリソースとして管理されているため、この処理はテキストフローやレイアウト再構築、表検出のロジックに依存しません。
以下の例では、Spire.PDF for Java の PdfImageHelper と PdfImageInfo を使用して、PDF ページに埋め込まれた画像を抽出し、PNG ファイルとして保存します。
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class extractPdfImages {
public static void main(String[] args) throws IOException {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// PdfImageHelper を作成
PdfImageHelper imageHelper = new PdfImageHelper();
// 各ページを順に処理
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// 現在のページに含まれる画像情報を取得
PdfImageInfo[] imageInfos =
imageHelper.getImagesInfo(pdf.getPages().get(i));
if (imageInfos != null) {
for (int j = 0; j < imageInfos.length; j++) {
// BufferedImage として画像を取得
BufferedImage image = imageInfos[j].getImage();
// 画像を PNG ファイルとして保存
File output = new File(
"output/images/page_" + i + "_image_" + j + ".png"
);
ImageIO.write(image, "PNG", output);
}
}
}
}
}
抽出された画像の例
PdfImageHelper / PdfImageInfo ページレベルのリソースを解析し、埋め込まれた画像を BufferedImage として取得できます。
ページ単位の解析 複数ページ PDF や、同一画像が再利用されている場合でも正確に抽出できます。
レイアウト非依存 テキスト配置や表構造に依存しないため、あらゆるビジュアル要素の抽出に適しています。
個別画像の抽出だけでなく、PDF ページ全体を画像として変換することも可能です。詳細は Java で PDF ページを画像に変換する方法 を参照してください。
メタデータ解析は、PDF の視覚コンテンツとは独立して保存されているドキュメントレベル情報を取得する基本的な PDF 解析機能です。ページレイアウトに依存しないため、ほぼすべての PDF に対して安定して適用できます。
Java ベースの PDF 処理システムでは、メタデータ解析は以下の目的で利用されることが多くあります。
メタデータ解析は、ページ単位の解析とは異なり、ドキュメント全体に対する処理として実装されます。
メタデータはレンダリング内容とは独立して保存されているため、高速かつ一貫性のある解析処理が可能です。
以下の例では、Spire.PDF for Java を使用して、一般的な PDF メタデータ項目を取得します。これらの情報は、検索・分類・ワークフロー制御などに利用できます。
import com.spire.pdf.PdfDocument;
public class ParsePdfMetadata {
public static void main(String[] args) {
// PDF を読み込み
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// ドキュメントメタデータを取得
String title = pdf.getDocumentInformation().getTitle();
String author = pdf.getDocumentInformation().getAuthor();
String subject = pdf.getDocumentInformation().getSubject();
String keywords = pdf.getDocumentInformation().getKeywords();
String creator = pdf.getDocumentInformation().getCreator();
String producer = pdf.getDocumentInformation().getProducer();
String creationDate = pdf.getDocumentInformation()
.getCreationDate().toString();
String modificationDate = pdf.getDocumentInformation()
.getModificationDate().toString();
System.out.println(
"Title: " + title +
"\nAuthor: " + author +
"\nSubject: " + subject +
"\nKeywords: " + keywords +
"\nCreator: " + creator +
"\nProducer: " + producer +
"\nCreation Date: " + creationDate +
"\nModification Date: " + modificationDate
);
}
}
コンソール出力例
ドキュメント情報ディクショナリ メタデータは専用の構造に保存されており、ページ描画内容とは独立しています。
項目の有無に注意 すべての PDF に完全なメタデータが含まれているとは限らず、null や空文字になる場合があります。
低い処理コスト ページ走査が不要なため、高速な前処理として適しています。
メタデータ解析は、視覚レイアウトに依存しないため、複雑な PDF においても比較的安定した結果が得られます。
個々の解析処理は独立して実装できますが、実際の Java アプリケーションでは、複数の PDF 解析機能を組み合わせて同一パイプライン内で使用するケースが一般的です。
代表的な実装パターンには以下があります。
テキスト・表・画像・メタデータ解析を独立かつ組み合わせ可能な処理として設計することで、拡張性・テスト容易性・保守性が向上します。
高機能な Java PDF パーサーを使用しても、以下の制約は避けられません。
これらの制約を理解したうえで解析戦略を設計することで、本番環境での例外処理やエラー対応を簡素化できます。
Java での PDF 解析は、単一の線形処理としてではなく、目的別に分離された抽出処理の集合として設計することで、最も効果を発揮します。テキスト抽出、表解析、画像取得、メタデータアクセスをそれぞれ独立した関心事として扱うことで、PDF ドキュメントを安定して実用データへ変換できます。
Spire.PDF for Java のような専用 PDF 解析ライブラリを活用することで、実運用に耐える、拡張性の高い Java ベースの PDF 処理システムを構築できます。
Spire.PDF for Java を使用した PDF 解析の可能性を最大限に引き出すには、無料トライアルライセンスの申請 をご利用ください。
A1: Spire.PDF for Java の PdfTextExtractor と PdfTextExtractOptions を使用することで、ページ単位のテキストを効率的に抽出できます。検索、分析、データ移行など、柔軟な用途に対応できます。
A2: PdfTableExtractor を使用すると、表領域を検出し、行・列構造を再構築できます。抽出結果は構造化データとして保存・変換・エクスポート可能です。
A3: はい。PdfImageHelper と PdfImageInfo を使用することで、各ページに埋め込まれた画像を抽出し、ファイルとして保存できます。PDFページ全体を画像に変換することも可能です。
A4: PDFドキュメントから PdfDocumentInformation を取得することで、タイトル、作成者、作成日時、キーワードなどの標準メタデータを高速に取得できます。
A5: あります。複雑なレイアウト、スキャンPDF、カスタムフォントは解析精度に影響します。スキャンPDFの場合は、OCR処理を先に行う必要があります。
CSV(Comma-Separated Values)は表形式データの保存に広く利用される汎用フォーマットです。一方、リストは Python における基本データ構造で、データ処理に柔軟に対応できます。Python で CSV をリストへ変換する ことで、データ分析や他の処理フローとの統合をスムーズに行えます。
Python 標準の csv モジュールでも基本的な読み込みは可能ですが、Spire.XLS for Python を使用すると、スプレッドシートのような直感的な操作で構造的な CSV データを扱うことができます。
本記事では、Python で CSV をリスト(および辞書のリスト)に読み込む方法 を、基礎から応用までコード例付きで分かりやすく解説します。
目次:
Spire.XLS はスプレッドシート処理用の強力なライブラリで、CSV 取り扱いにおいて次のような利点があります。
インストール方法
以下の pip コマンドで Spire.XLS for Python をインストールできます:
pip install Spire.XLS
インストール後、すぐにプロジェクトで使用できます。
CSV にヘッダーがない場合(データ行のみの場合)、Spire.XLS を使うと、行ごとにリストへ変換し、最終的に「リストのリスト」として取得できます。
手順:
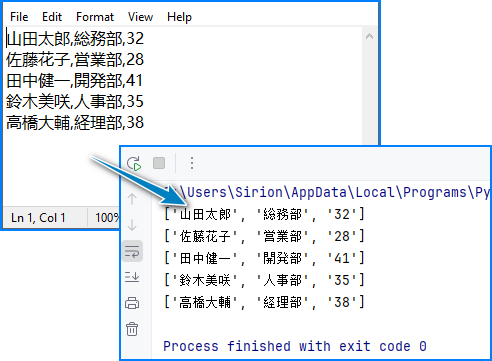
CSV → リスト変換コード例:
from spire.xls import *
from spire.xls.common import *
# Workbook を初期化し、CSV を読み込む
workbook = Workbook()
workbook.LoadFromFile("Employee.csv",",")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# シートのデータを二次元リストへ変換
data_list = []
for i in range(sheet.Rows.Length):
row = []
for j in range(sheet.Columns.Length):
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
# 結果を表示
for row in data_list:
print(row)
# リソースを解放
workbook.Dispose()
出力例:
ヘッダー(例:name,age,city)がある CSV の場合、辞書のリストへ変換すると、列名をキーとして扱えるためデータ操作がより直感的になります。
CSV → 辞書リスト変換コード例:
from spire.xls import *
# Workbook を初期化し、CSV を読み込む
workbook = Workbook()
workbook.LoadFromFile("Customer_Data.csv", ",")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# ヘッダー(1 行目)を取得
headers = []
for j in range(sheet.Columns.Length):
headers.append(sheet.Range[1, j + 1].Value)
# データ行をディクショナリのリストへ変換
dict_list = []
for i in range(1, sheet.Rows.Length): # ヘッダー行をスキップ
row_dict = {}
for j in range(sheet.Columns.Length):
key = headers[j]
value = sheet.Range[i + 1, j + 1].Value
row_dict[key] = value
dict_list.append(row_dict)
# 結果を出力
for record in dict_list:
print(record)
# リソースを解放
workbook.Dispose()
説明
出力例:
カンマ以外の区切り文字(TSV など)を使う場合は、LoadFromFile の第 2 引数で区切り文字を指定します:
# タブ区切りファイル
workbook.LoadFromFile("data.tsv", "\t")
# セミコロン区切りファイル
workbook.LoadFromFile("data_eu.csv", ";")
CSV に空セルがある場合、リストでは空文字 ('') として保持されます。空文字を "N/A" などに置き換える場合は以下のようにします:
cell_value = sheet.Range[i + 1, j + 1].Value or "N/A"
Python で CSV をリストへ変換する方法 は、Spire.XLS を使うことで効率的かつ柔軟になります。 生データ用にリストのリストを使う場合も、構造化された分析のために辞書リストを使う場合も、Spire.XLS はパース処理・インデックス管理・リソース解放を自動的に行ってくれます。
この記事のコード例を活用すれば、データパイプライン、分析スクリプト、アプリケーションへ簡単に組み込むことができます。
より高度な機能については、Spire.XLS for Python ドキュメント を参照してください。
A: はい。一般的な業務データであれば問題なく処理できます。ただし、数百万行規模など極端に大きいデータについては、分割処理やビッグデータ専用のツールの利用を検討してください。
A: Spire.XLS はパース処理を細かく制御でき、追加のデータサイエンス系依存パッケージも不要です。 分析中心なら pandas が便利ですが、CSV の解析を正確に行いたい場合 や pandas が使えない環境 では Spire.XLS が適しています。
A: 辞書のリストへ変換する方法がおすすめです。1 行目をヘッダーとして読み取り、各行のデータとマッピングすることで、列名でデータへアクセスできます。
A: 内側のループで対象列のみを読み込むよう変更してください。
# 1 列目と 3 列目のみを抽出(インデックス 0 と 2)
target_columns = [0, 2]
for i in range(sheet.Rows.Length):
row = []
for j in target_columns:
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
Spire.Presentation for Python 10.12.0 がリリースされました。本バージョンでは、PPTX から PDF への変換機能が強化され、テキスト欠落、内容の重なり、表レイアウトの不整合など複数の問題が修正されました。詳細は以下のとおりです。
| カテゴリー | ID | 説明 |
| 不具合修正 | SPIREPPT-2905 | PPTX を PDF に変換する際、一部テキストが欠落する問題を修正しました。 |
| 不具合修正 | SPIREPPT-3032 | PPTX を PDF に変換する際、内容が重なって表示される問題を修正しました。 |
| 不具合修正 | SPIREPPT-3036 | PPTX を PDF に変換した後、表のレイアウトが正しく表示されない問題を修正しました。 |
PDF ドキュメントにおける図形は、視覚的な情報を補足したりレイアウトを強化したりするうえで、非常に重要な役割を果たします。線・枠線・塗りつぶし・幾何学的変形などの描画操作を組み合わせることで、チャート、装飾、ロゴなど、ドキュメントの可読性やデザイン性を高める要素を自由に作成できます。図形の色、線種、塗りつぶし効果などのプロパティは用途に合わせて柔軟にカスタマイズできます。
本記事では、Spire.PDF for Python を利用して PythonコードでPDFに図形を描画する方法 を紹介します。
クイックナビゲーション
この機能を使用するには、Spire.PDF for Pythonとplum-dispatch v1.7.4が必要です。Windows環境では、以下のpipコマンドで簡単にインストールできます。
pip install Spire.PDF
または、Spire.PDF for Pythonのダウンロードページから直接ダウンロードして、プロジェクトに追加することもできます。
PdfPageBase.Canvas.DrawLine() メソッドを使用すると、始点・終点の座標とペン(PdfPen)を指定して線を描画できます。
from spire.pdf.common import *
from spire.pdf import *
# PDF ドキュメント オブジェクトを作成する
doc = PdfDocument()
# ページを追加する
page = doc.Pages.Add()
# 現在の描画状態を保存する
state = page.Canvas.Save()
# 線の開始位置(X 座標)
x = 100.0
# 線の開始位置(Y 座標)
y = 50.0
# 線の長さ
width = 300.0
# ディープスカイブルーの色と太さ 3.0 のペン オブジェクトを作成する
pen = PdfPen(PdfRGBColor(Color.get_DeepSkyBlue()), 3.0)
# 実線を描画する
page.Canvas.DrawLine(pen, x, y, x + width, y)
# ペンの線種を破線に設定する
pen.DashStyle = PdfDashStyle.Dash
# 破線パターンを [1, 4, 1] に設定する
pen.DashPattern = [1, 4, 1]
# 破線の開始位置(Y 座標)
y = 80.0
# 破線を描画する
page.Canvas.DrawLine(pen, x, y, x + width, y)
# 保存しておいた描画状態を復元する
page.Canvas.Restore(state)
# ドキュメントをファイルに保存する
doc.SaveToFile("Drawing Lines.pdf")
# ドキュメントを閉じ、リソースを解放する
doc.Close()
doc.Dispose()

図形ではなく画像を挿入したい場合は、PythonでPDFに画像を挿入する方法を参照してください。
PdfPageBase.Canvas.DrawPie() メソッドを使うと、位置・サイズ・開始角度・終了角度を指定してパイ図形を描画できます。
from spire.pdf.common import *
from spire.pdf import *
# PDF ドキュメント オブジェクトを作成する
doc = PdfDocument()
# ページを追加する
page = doc.Pages.Add()
# 現在の描画状態を保存する
state = page.Canvas.Save()
# ダークレッドの色と太さ 2.0 のペン オブジェクトを作成する
pen = PdfPen(PdfRGBColor(Color.get_DarkRed()), 2.0)
# 1 つ目の円グラフを描画する
page.Canvas.DrawPie(pen, 10.0, 30.0, 130.0, 130.0, 360.0, 300.0)
# 2 つ目の円グラフを描画する
page.Canvas.DrawPie(pen, 160.0, 30.0, 130.0, 130.0, 360.0, 330.0)
# 3 つ目の円グラフを描画する
page.Canvas.DrawPie(pen, 320.0, 30.0, 130.0, 130.0, 360.0, 360.0)
# 保存しておいた描画状態を復元する
page.Canvas.Restore(state)
# ドキュメントをファイルに保存する
doc.SaveToFile("Drawing Pie Charts.pdf")
# ドキュメントを閉じ、リソースを解放する
doc.Close()
doc.Dispose()
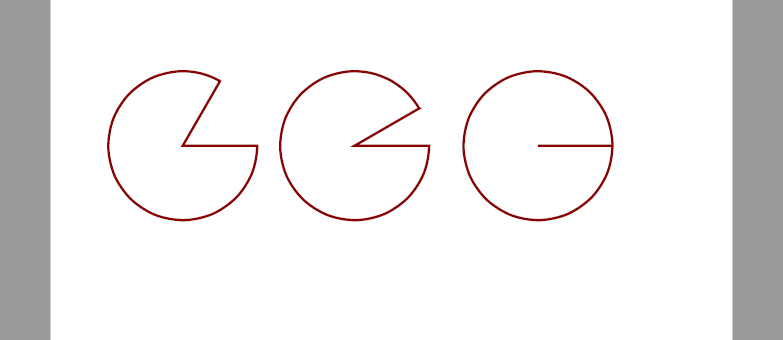
長方形の描画には PdfPageBase.Canvas.DrawRectangle() を使用します。位置(x, y)とサイズ(幅・高さ)を指定すれば任意の長方形を描けます。
from spire.pdf.common import *
from spire.pdf import *
# PDF ドキュメント オブジェクトを作成する
doc = PdfDocument()
# ページを追加する
page = doc.Pages.Add()
# 現在の描画状態を保存する
state = page.Canvas.Save()
# チョコレート色で太さ 1.5 のペン オブジェクトを作成する
pen = PdfPen(PdfRGBColor(Color.get_Chocolate()), 1.5)
# ペンを使用して長方形の枠線を描画する
page.Canvas.DrawRectangle(pen, RectangleF(PointF(20.0, 30.0), SizeF(150.0, 120.0)))
# 線形グラデーション ブラシを作成する
linearGradientBrush = PdfLinearGradientBrush(
PointF(200.0, 30.0),
PointF(350.0, 150.0),
PdfRGBColor(Color.get_Green()),
PdfRGBColor(Color.get_Red())
)
# 線形グラデーション ブラシを使用して長方形を塗りつぶす
page.Canvas.DrawRectangle(linearGradientBrush, RectangleF(PointF(200.0, 30.0), SizeF(150.0, 120.0)))
# 放射状グラデーション ブラシを作成する
radialGradientBrush = PdfRadialGradientBrush(
PointF(380.0, 30.0), 150.0,
PointF(530.0, 150.0), 150.0,
PdfRGBColor(Color.get_Orange()),
PdfRGBColor(Color.get_Blue())
)
# 放射状グラデーション ブラシを使用して長方形を塗りつぶす
page.Canvas.DrawRectangle(radialGradientBrush, RectangleF(PointF(380.0, 30.0), SizeF(150.0, 120.0)))
# 保存しておいた描画状態を復元する
page.Canvas.Restore(state)
# ドキュメントをファイルに保存する
doc.SaveToFile("Drawing Rectangle Shapes.pdf")
# ドキュメントを閉じ、リソースを解放する
doc.Close()
doc.Dispose()
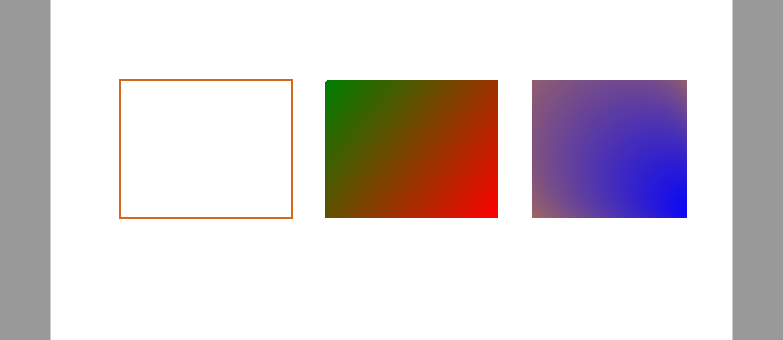
こちらもおすすめ:PythonでPDF内の画像の透明度を設定する方法
楕円の描画には PdfPageBase.Canvas.DrawEllipse() を使用します。輪郭線だけの楕円、塗りつぶし楕円の両方に対応しています。
from spire.pdf.common import *
from spire.pdf import *
# PDF ドキュメント オブジェクトを作成する
doc = PdfDocument()
# ページを追加する
page = doc.Pages.Add()
# 現在の描画状態を保存する
state = page.Canvas.Save()
# ペン オブジェクトを作成する
pen = PdfPens.get_CadetBlue()
# 楕円形の枠線を描画する
page.Canvas.DrawEllipse(pen, 50.0, 30.0, 120.0, 100.0)
# 塗りつぶし用のブラシ オブジェクトを作成する
brush = PdfSolidBrush(PdfRGBColor(Color.get_CadetBlue()))
# 塗りつぶした楕円形を描画する
page.Canvas.DrawEllipse(brush, 180.0, 30.0, 120.0, 100.0)
# 保存しておいた描画状態を復元する
page.Canvas.Restore(state)
# ドキュメントをファイルに保存する
doc.SaveToFile("Drawing Ellipse Shape.pdf")
# ドキュメントを閉じ、リソースを解放する
doc.Close()
doc.Dispose()

生成されたドキュメントから評価メッセージを削除したり、機能制限を解除したい場合は、30 日間の試用ライセンスを申請してください。





