チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション
CSV(Comma-Separated Values)は、アプリケーション、データベース、プログラミング言語間でのデータ交換において最も広く使用されている形式の1つです。Python 開発者にとって、Python リストを CSV 形式に変換する必要性は頻繁に発生します。アプリケーションデータのエクスポート、レポートの生成、分析用データセットの準備など、さまざまな場面で必要となります。
Python の組み込み csv モジュールは基本的な操作を処理できますが、ネストされたリストや辞書などの複雑なデータ構造を扱うには、追加のロジックとエラー処理が必要です。これらの変換を手動で管理することは、特に複数のデータ型やカスタムフォーマット要件を扱う場合、非効率的でエラーが発生しやすくなります。
このガイドでは、Spire.XLS for Python を使用して、さまざまな Python リスト構造を CSV 形式に変換する完全なパイプラインの構築に焦点を当てます。このアプローチは、単純な1次元リストから複雑なネストされた辞書まで、データの整合性を維持しながら柔軟な方法を提供する堅牢でスケーラブルなソリューションです。
クイックナビゲーション
実装に入る前に、CSV に変換される一般的な Python リスト構造の種類を理解することが重要です。
["りんご", "バナナ", "さくらんぼ"])— 単一行または単一列のデータに最適[{"名前": "田中", "年齢": 30}])— キーを通じて意味的な意味を維持この包括的なアプローチは、現実世界のアプリケーションがリストから CSV へのワークフローをどのように処理するかを反映しています。異なるデータ構造に対して柔軟な方法を提供しながら、一貫した出力品質を確保します。
開始する前に、以下を用意してください。
Python 3.x がインストールされていること
Spire.XLS for Python がインストールされていること:
pip install Spire.XLS
または、Spire.XLS for Python をダウンロードして、プロジェクトに手動で追加することもできます。
Python コードを記述するためのテキストエディタまたは IDE
Python の組み込み csv モジュールは単純な CSV 操作に優れていますが、Spire.XLS は以下の追加の利点を提供します。
1次元リストは値の単純なシーケンスです。以下の手順では、これらの値を CSV の単一行または単一列に書き込む方法を説明します。
手順1: Spire.XLS モジュールをインポート
まず、Spire.XLS から必要なクラスをインポートします。
from spire.xls import *
from spire.xls.common import *
手順2: ワークブックとワークシートを作成
Spire.XLS はデータを整理するためにワークブックとワークシートを使用します。新しいワークブックを作成し、新しいワークシートを追加します。
# ワークブックインスタンスを作成
workbook = Workbook()
# デフォルトのワークシートを削除し、新しいワークシートを追加
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
手順3: 1次元リストデータをワークシートに書き込む
リストを単一行(横方向)または単一列(縦方向)に書き込むかを選択します。
例1: 1次元リストを単一行に書き込む
# サンプル 1次元リスト
data_list = ["りんご", "バナナ", "オレンジ", "ぶどう", "マンゴー"]
# リストを行1に書き込む
for i, item in enumerate(data_list):
worksheet.Range[1, i+1].Value = item
例2: 1次元リストを単一列に書き込む
# サンプル 1次元リスト
data_list = ["りんご", "バナナ", "オレンジ", "ぶどう", "マンゴー"]
# リストを列1に書き込む
for i, item in enumerate(data_list):
worksheet.Range[i + 1, 1].Value = item
手順4: ワークシートを CSV として保存
SaveToFile() を使用してワークブックを CSV ファイルにエクスポートします。適切なフォーマットを確保するために FileFormat.CSV を指定します。
# CSV ファイルとして保存
workbook.SaveToFile("ListToCSV.csv", FileFormat.CSV)
# リソースを解放するためにワークブックを閉じる
workbook.Dispose()
以下は変換結果のプレビューです。
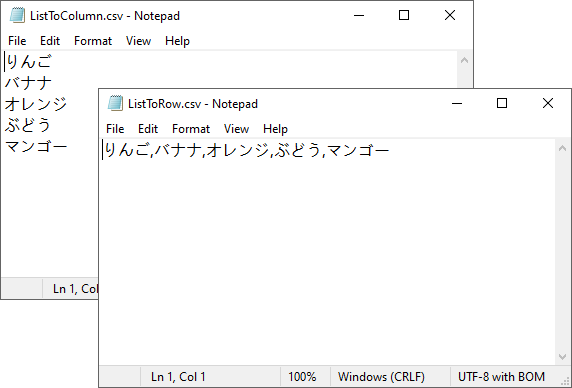
この段階で、1次元リストは正常に CSV 形式に変換されました。このアプローチは、商品名、スコア、識別子などの単純なシーケンスに適しています。
2次元リストは、タブラーデータを表すリストのリストです。より一般的には、各内部リストが CSV ファイルの行を表すこのタイプのリストを扱います。
以下のコードは、2次元リストを CSV に変換する方法を示しています。
from spire.xls import *
from spire.xls.common import *
# ワークブックインスタンスを作成
workbook = Workbook()
# デフォルトのワークシートを削除し、新しいワークシートを追加
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add()
# サンプル 2次元リスト(ヘッダー + データ)
data = [
["名前", "年齢", "都市", "給与"],
["佐藤太郎", 30, "東京", 500000],
["鈴木花子", 25, "大阪", 450000],
["高橋次郎", 35, "名古屋", 600000],
["田中美咲", 28, "福岡", 520000]
]
# 2次元リストをワークシートに書き込む
for row_index, row_data in enumerate(data):
for col_index, cell_data in enumerate(row_data):
worksheet.Range[row_index + 1, col_index + 1].Value = str(cell_data)
# CSV ファイルとして保存
workbook.SaveToFile("2DListToCSV.csv", FileFormat.CSV)
workbook.Dispose()
以下は変換結果のプレビューです。
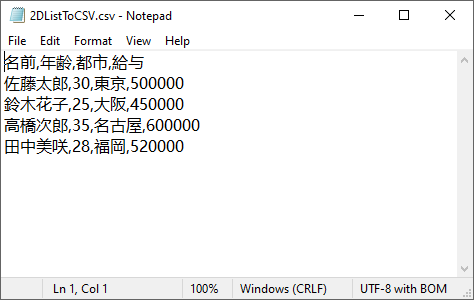
str(cell_data) が混合データ型(数値、文字列)を処理生成された CSV ファイルは、さらに加工することができます。デバイス間で安全にプレゼンテーションを行うために、PDF に変換することも可能です。詳細なオプションについては、Python を使用して Excel や CSV を PDF に変換する方法に関するガイドをご参照ください。
辞書のリストは、データに名前付きフィールドがある場合に理想的です(例: [{"名前": "田中", "年齢": 30}, {"名前": "鈴木", "年齢": 25}])。辞書のキーが CSV ヘッダーになり、値が行になります。
以下のコードは、辞書のリストを CSV に変換する方法を示しています。
from spire.xls import *
from spire.xls.common import *
# ワークブックインスタンスを作成
workbook = Workbook()
# デフォルトのワークシートを削除し、新しいワークシートを追加
workbook.Worksheets.Clear()
worksheet = workbook.Worksheets.Add("Data")
# サンプル辞書のリスト
customer_list = [
{"顧客ID": 101, "名前": "山田花子", "メール": "yamada@ example.com"},
{"顧客ID": 102, "名前": "伊藤健太", "メール": "ito@ example.com"},
{"顧客ID": 103, "名前": "中村美香", "メール": "nakamura@ example.com"}
]
# ヘッダー(辞書キー)を抽出して行1に書き込む
if customer_list: # リストが空でないことを確認
headers = list(customer_list[0].keys())
# ヘッダーを書き込む
for col_index, header in enumerate(headers):
worksheet.Range[1, col_index + 1].Value = str(header)
# 辞書の値を行2以降に書き込む
for row_index, record in enumerate(customer_list):
for col_index, header in enumerate(headers):
# 安全に値を取得、キーが存在しない場合は空の文字列を使用
value = record.get(header, "")
worksheet.Range[row_index + 2, col_index + 1].Value = str(value)
# CSVファイルとして保存
workbook.SaveToFile("Customer_Data.csv", FileFormat.CSV)
workbook.Dispose()
以下は変換結果のプレビューです。
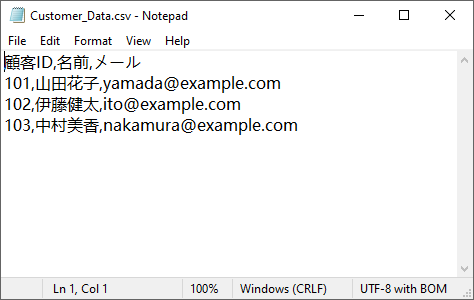
.keys() を使用して列名を自動的に取得.get() メソッドを使用: デフォルトの空の文字列で欠落したキーを適切に処理このアプローチは、API レスポンス、データベースクエリ結果、または CSV にエクスポートする必要がある名前付きフィールドを持つデータに特に役立ちます。
Spire.XLS for Python を使用する最大の利点の1つは、カスタム区切り文字とエンコーディングで CSV ファイルを保存する柔軟性です。これにより、異なる地域、アプリケーション、データ要件に合わせて CSV 出力を調整できます。
区切り文字とエンコーディングを指定するには、Worksheet クラスの SaveToFile() メソッドの対応するパラメーターを変更するだけです。
# 異なる区切り文字とエンコーディングで保存
worksheet.SaveToFile("semicolon_delimited.csv", ";", Encoding.get_UTF8())
worksheet.SaveToFile("tab_delimited.csv", "\t", Encoding.get_UTF8())
worksheet.SaveToFile("unicode_encoded.csv", ",", Encoding.get_Unicode())
セミコロン区切り文字(欧州ロケール)
多くの欧州諸国では小数点の区切り文字としてカンマの代わりにセミコロンを使用するため、カンマ区切りの CSV ファイルは問題を引き起こす可能性があります。セミコロンを使用することで競合を回避できます。
worksheet.SaveToFile("european_data.csv", ";", Encoding.get_UTF8())
タブ区切り文字(TSV 形式)
タブ区切り値は、データ内にフィールドにカンマが含まれている場合に役立ちます。
worksheet.SaveToFile("tab_separated.csv", "\t", Encoding.get_UTF8())
Unicode エンコーディング
国際文字(中国語、日本語、アラビア語など)の場合は、Unicode エンコーディングを使用します。
worksheet.SaveToFile("international_data.csv", ",", Encoding.get_Unicode())
Python リストを CSV に変換するプロセスは単純に見えるかもしれませんが、いくつかの実用的な課題が発生する可能性があります。
リストには混合データ型(文字列、整数、浮動小数点数、None)が含まれる可能性があり、変換中に型エラーが発生する原因となります。
解決策:
str() を使用して文字列に変換None 値をデフォルトの置換で明示的に処理辞書のリストを変換する際、一部のレコードに特定のキーがない場合、KeyError 例外が発生する可能性があります。
解決策:
.get(key, default_value) メソッドを使用空のリストを処理しようとすると、インデックスエラーが発生したり、無効な CSV ファイルが作成されたりする可能性があります。
解決策:
if customer_list:カンマ、引用符、改行を含むフィールド値は CSV 構造を壊す可能性があります。
解決策:
ワークブックの破棄に失敗すると、特にバッチ処理シナリオでメモリリークにつながる可能性があります。
解決策:
workbook.Dispose() を呼び出す非 ASCII 文字は、誤ったエンコーディングが使用されると破損して表示される可能性があります。
解決策:
Encoding.get_UTF8()非常に大きなリストを処理すると、 상당한 메모리와 시간이 소비될 수 있습니다.
解決策:
これらの問題を予測することで、より信頼性の高いリストから CSV への変換ワークフローを構築できます。
Python リストを CSV に変換することは、単純なデータ変換だけでなく、リストデータの読み取り、タブラー形式への整理、標準化された CSV ファイルへの書き込みを含む構造化されたプロセスです。
適切なデータ構造化に焦点を当て、Python と Spire.XLS を使用することで、完全なリストから CSV へのパイプラインを効率的に実装でき、データエクスポートタスクの自動化が容易になります。
このアプローチは、以下の処理に特に役立ちます。
Spire.XLS for Python を使用すると、以下のことが可能です。
単純なシーケンス、構造化されたテーブル、意味的な辞書のいずれを扱っていても、Spire.XLS は基本的なスクリプトから本番システムまでスケールする堅牢なソリューションを提供します。
Spire.XLS for Python のパフォーマンスを評価し、制限を解除したい場合は、30日間の無料トライアルを申請できます。
以下のベストプラクティスに従ってください。
Dispose() を使用してリソースをクリーンアップはい。リストをループ処理し、それぞれを別々の CSV として保存できます。
lists = {
"fruits": ["りんご", "バナナ", "さくらんぼ"],
"scores": [85, 92, 78]
}
for name, data in lists.items():
wb = Workbook()
wb.Worksheets.Clear()
ws = wb.Worksheets.Add(name)
for i, val in enumerate(data):
ws.Range[i + 1, 1].Value = str(val)
wb.SaveToFile(f"{name}.csv", FileFormat.CSV)
wb.Dispose()
このアプローチは、複数のデータセットを一括エクスポートする場合に役立ちます。
CSV は数値をプレーンテキストとして保存するため、保存前にフォーマットを適用する必要があります。
ws.Range["A1:A10"].NumberFormat = "¥#,##0"
これにより、数値が CSV で ¥1,234 として表示されます。詳細な数値フォーマットオプションについては、Python で数値フォーマットを設定を参照してください。
CSV 形式は XLSX と比較してフォーマットサポートが限られていることに注意してください。豊富なフォーマットが必要な場合は、代わりに Excel 形式で保存することを検討してください。
はい!Spire.XLS for Python はクロスプラットフォームであり、Windows、macOS、Linux システムをサポートしています。このライブラリは可能な限り純粋な Python 実装を使用しており、異なる環境間での互換性を確保しています。
2次元リストを変換する際、すべての行が同じ数の列を持っていることを確認してください。
# 短い行を空の文字列でパディング
max_cols = max(len(row) for row in data)
for row in data:
while len(row) < max_cols:
row.append("")
これにより、出力 CSV で列のずれを防ぎます。
はい。データを書き込む前にヘッダー行を挿入するだけです。
worksheet.Range[1, 1].Value = "項目" # ヘッダー
for i, item in enumerate(data_list):
worksheet.Range[i + 2, 1].Value = item # データは行2から開始
これにより、CSV 出力にラベル付きの列が作成されます。
カスタム設定を使用した CSV 変換の場合、最大限の柔軟性のために Worksheet.SaveToFile(delimiter, encoding) を使用してください。
Python でデータを扱う際、TXT を CSV に変換するニーズは非常に一般的です。TXT ファイルは非構造のプレーンテキストとして保存されることが多く、プログラムでの処理が難しい場合があります。一方、CSV ファイルはデータを行と列に整理して格納するため、データ分析、レポート作成、アプリケーション間での共有に適しています。
テキストデータをより扱いやすく構造化するため、開発者は TXT ファイルの内容を解析し、表形式に整理して CSV に変換する必要があります。しかし、この処理を手動で行うのは非効率でミスも発生しやすく、特に複数ファイルや複雑な区切り文字を扱う場合は問題が顕著になります。
本ガイドでは、Spire.XLS for Python を使用し、Python で TXT ファイルを CSV 形式に変換する一連の処理フローを構築する方法を解説します。実務において拡張性と実用性を兼ね備えたアプローチです。
クイックナビゲーション
CSV(Comma-Separated Values)は、表形式データを保存するためのシンプルなテキストベースのファイル形式です。各行が1レコードを表し、行内の値はカンマ(またはタブやセミコロンなどの区切り文字)で区切られます。
CSV は、Excel、Google スプレッドシート、データベース、Python などのプログラミング言語で広くサポートされています。そのシンプルな構造により、データのインポート、エクスポート、分析、自動処理が容易に行えます。
CSV ファイルの例:
Name, Age, City
John, 28, New York
Alice, 34, Los Angeles
Bob, 25, Chicago
このような構造化形式は効率的なデータ処理を可能にし、非構造の TXT ファイルからの変換に適しています。
開始する前に、以下を準備してください:
Python 3.x がインストールされていること
Spire.XLS for Python のインストール:
pip install Spire.XLS
または、Spire.XLS for Python をダウンロード して手動でプロジェクトに追加することもできます。
Python コードを作成するためのテキストエディターまたは IDE
Python で TXT ファイルを CSV に変換する処理はシンプルで、以下の手順で実行できます:
以下のコードは、Python を使用して TXT ファイルを CSV にエクスポートする方法を示します:
from spire.xls import *
# TXT ファイルを読み込む
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# 各行をスペースで分割して処理(必要に応じて区切り文字を変更)
processed_data = [line.strip().split() for line in lines]
# Excel ワークブックを作成
workbook = Workbook()
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# 処理済みデータをワークシートに書き込む
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
# セルにデータを書き込む
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# ワークシートを CSV ファイルとして保存(UTF-8 エンコーディング)
sheet.SaveToFile("TxtToCsv.csv", ",", Encoding.get_UTF8())
# リソースを解放
workbook.Dispose()
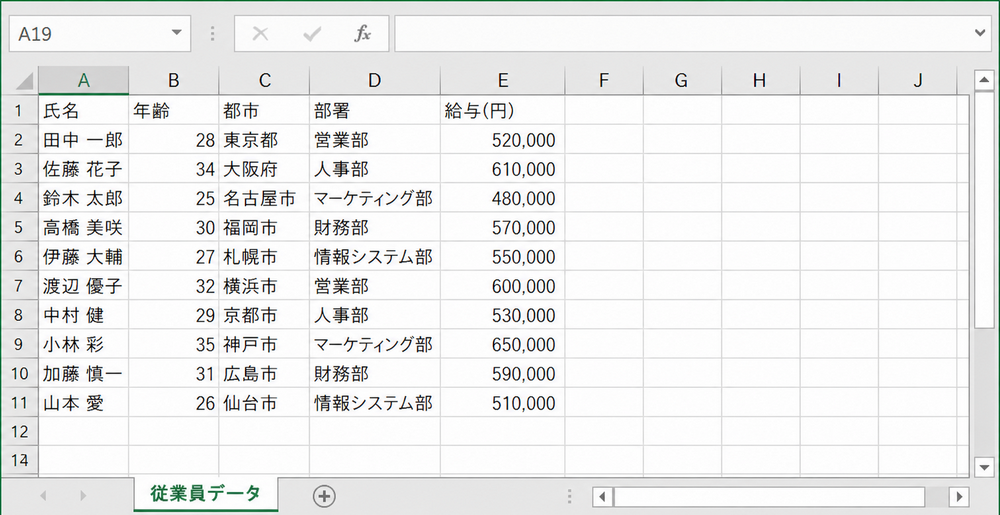
以下は変換結果のイメージです:
データがすでにリスト形式になっている場合は、Spire.XLS for Python を使用して、そのリストを Excel や CSV ファイルに変換することもできます。
複数の TXT ファイルを自動的に CSV に変換する場合、フォルダー内のすべての .txt ファイルをループ処理して順番に変換できます。
以下のコードは、複数の TXT ファイルを一括で CSV に変換する方法を示します:
import os
from spire.xls import *
# TXT ファイルが格納されているフォルダー
input_folder = "txt_files"
output_folder = "csv_files"
# 出力フォルダーが存在しない場合は作成
os.makedirs(output_folder, exist_ok=True)
# 単一ファイルを変換する関数
def convert_txt_to_csv(file_path, output_path):
# TXT ファイルを読み込む
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
# 各行を処理(スペース区切り。必要に応じて変更)
processed_data = [line.strip().split() for line in lines if line.strip()]
# ワークブックを作成し、最初のワークシートを取得
workbook = Workbook()
sheet = workbook.Worksheets[0]
# データを書き込み
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# CSV として保存(UTF-8)
sheet.SaveToFile(output_path, ",", Encoding.get_UTF8())
workbook.Dispose()
print(f"Converted '{file_path}' -> '{output_path}'")
# フォルダー内のすべての TXT ファイルを処理
for filename in os.listdir(input_folder):
if filename.lower().endswith(".txt"):
input_path = os.path.join(input_folder, filename)
output_name = os.path.splitext(filename)[0] + ".csv"
output_path = os.path.join(output_folder, output_name)
convert_txt_to_csv(input_path, output_path)
この方法により、大量のファイルを扱う際の作業効率が大幅に向上します。
テキストファイルを CSV に変換する際は、ファイルのレイアウトの違いや想定外のエラーが発生する可能性があります。以下のポイントを押さえることで、さまざまなケースに柔軟かつ安定して対応できます。
すべての TXT ファイルがスペース区切りとは限りません。タブ、カンマ、またはその他の文字が使用されている場合は、split() 関数の引数を適切に変更する必要があります。
タブ区切りファイル(.tsv)の場合:
processed_data = [line.strip().split('\t') for line in lines]
カンマ区切りの場合:
processed_data = [line.strip().split(',') for line in lines]
カスタム区切り文字(例:|)の場合:
processed_data = [line.strip().split('|') for line in lines]
このように事前に正しく列分割を行うことで、CSV 出力時のデータ構造を正確に保つことができます。
ファイルの読み込み・書き込み処理では、例外処理(try-except)を導入することが重要です。これにより、スクリプトの安定性が向上し、予期しないクラッシュを防ぐことができます。
try:
# 変換処理
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# ... 続きの処理
except FileNotFoundError:
print("エラー:指定されたファイルが見つかりません。")
except Exception as e:
print(f"エラー:{e}")
補足: エラーメッセージはできるだけ具体的に記述すると、原因特定が容易になります。
TXT ファイルには空行が含まれている場合があります。そのまま処理すると、CSV に空行が出力されてしまいます。
processed_data = [line.strip().split() for line in lines if line.strip()]
このように条件を付けてフィルタリングすることで、実データのみを処理し、よりクリーンな CSV を生成できます。
TXT から CSV への変換は一見シンプルですが、実際にはいくつかの実務的な課題が存在します。
同一ファイル内でも、行ごとに異なる区切り文字が使われている場合があります。その結果、列がずれてしまうことがあります。
対策:
行によって列数が異なると、データの整合性が崩れます。
対策:
TXT ファイルは UTF-8、ASCII、Latin-1 など異なるエンコーディングで保存されている場合があります。これにより文字化けが発生する可能性があります。
対策:
chardet などのライブラリでエンコーディングを検出するカンマ、引用符、改行などを含むフィールドは、CSV の構造を破壊する可能性があります。
対策:
非常に大きな TXT ファイルを扱う場合、メモリ使用量が増大する可能性があります。
対策:
余分なスペースや不統一なフォーマットは、データ品質に影響します。
対策:
これらのポイントを事前に考慮することで、より信頼性の高い TXT → CSV 変換ワークフロー を構築できます。
TXT ファイルを CSV に変換する処理は、単なるファイル形式の変換ではなく、テキストデータの読み込み・解析・構造化を含む一連のプロセスです。
Python と Spire.XLS を組み合わせることで、安定性と拡張性を兼ね備えた TXT → CSV 変換パイプライン を効率よく構築できます。これにより、データ前処理の自動化が大幅に容易になります。
この手法は、ログファイル、データエクスポート、各種テキストデータを分析・レポート・スプレッドシート連携用に構造化する場面で特に有効です。
Spire.XLS for Python を使用することで、以下が実現できます:
より詳細に機能を評価したい場合や制限を解除したい場合は、30日間の無料トライアル を利用できます。
はい。Spire.XLS for Python は Microsoft Excel に依存せずに動作するため、Excel がインストールされていない環境でも CSV ファイルの生成・出力が可能です。
フォルダー内のすべての TXT ファイルをループ処理し、各ファイルに対して変換関数を適用します。本記事では、指定ディレクトリ内の .txt ファイルを自動処理するサンプルコードを紹介しています。
if line.strip() のような条件で空行を除外し、さらに列数の検証ロジックを追加することで、不整合や空行の出力を防ぐことができます。
TXT ファイルの区切り文字に応じて、split() の引数を変更します。例えば、タブ(\t)、カンマ、パイプ(|)などに対応するには、split('\t')、split(',')、split('|') のように指定します。
UTF-8 の使用が推奨されます。多言語文字に対応でき、さまざまな環境・アプリケーションとの互換性を確保できます。
はい。Spire.XLS for Python を使用すれば、TXT ファイルを XLSX / XLS 形式に直接変換することも可能です。詳細は関連チュートリアルを参照してください。
データ主導の業務が一般化している現在、Python 開発者にとって「リスト(Python の基本データ構造)を Excel へ変換する」作業は非常に一般的です。Excel は多くの業界で、データの可視化・共有・レポート作成の標準ツールとして広く利用されています。
レポート生成、分析前の前処理、非エンジニアへのデータ共有など、Python のリストを Excel に出力するスキルは欠かせません。
pandas のような軽量ライブラリでも基本的な出力は可能ですが、Spire.XLS for Python は Excel の書式設定、スタイル、ファイル生成を細かく制御でき、Microsoft Excel のインストールも不要です。このガイドでは、さまざまなリスト構造を Excel へ変換する方法を、実例とベストプラクティスとともに解説します。
Python のリストは柔軟にデータを保持できますが、Excel には次のような利点があります:
売上データ、ユーザー情報、アンケート結果など、Excel に書き出すことでデータの共有性と実用性が大幅に向上します。
Spire.XLS for Python を使用するには、pip でインストールします:
pip install Spire.XLS
Excel(.xls/.xlsx)形式の読み書きに対応し、太字、列幅、色などの書式設定が自由に行えます。 本番レベルの Excel 出力に最適なライブラリです。
さらに多くの機能を試すには、30日間の無料評価ライセンスを取得できます。
一次元リストを Excel に書き込む場合、リストをループし、1 列に順番に挿入します。
以下のコード例では、文字列のリストを 1 列に書き込みます。 数値リストの場合は、保存前に数値書式を設定できます。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("シンプルなリスト")
# サンプルデータ(文字列のリスト)
data_list = ["佐藤", "鈴木", "高橋", "田中", "伊藤"]
# リストの内容を Excel セルに書き込みます(1行目・1列目から開始)
for index, value in enumerate(data_list):
worksheet.Range[index + 1, 1].Value = value
# 表示を見やすくするため、列幅を設定します
worksheet.Range[1, 1].ColumnWidth = 15
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("SimpleListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
1 行に並べたい場合は以下のようにします:
for index, value in enumerate(data_list):
worksheet.Range[1, index + 1].Value = value
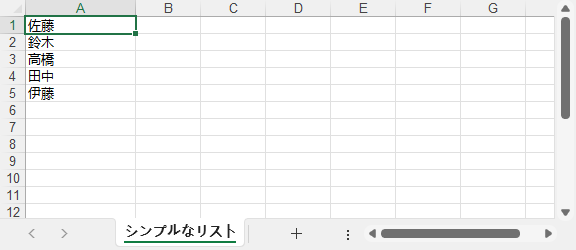
出力結果: きれいに整った 1 列の Excel になります。
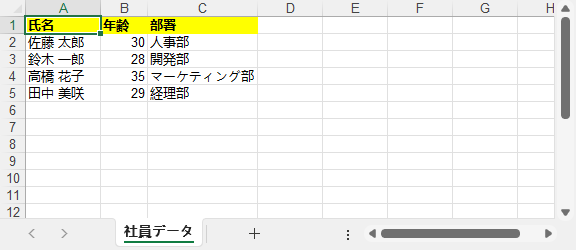
ネストされたリスト(2D リスト)は、行列形式のデータで、Excel シートに直接マッピングできます。 以下は、従業員データ(名前・年齢・部署)を Excel テーブルへ変換する例です。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("社員データ")
# ネストされたリスト(各行:[氏名、年齢、部署])
employee_data = [
["氏名", "年齢", "部署"], # ヘッダー行
["佐藤 太郎", 30, "人事部"],
["鈴木 一郎", 28, "開発部"],
["高橋 花子", 35, "マーケティング部"],
["田中 美咲", 29, "経理部"]
]
# ネストされたリストの内容を Excel に書き込みます
for row_idx, row_data in enumerate(employee_data):
for col_idx, value in enumerate(row_data):
if isinstance(value, int):
worksheet.Range[row_idx + 1, col_idx + 1].NumberValue = value
else:
worksheet.Range[row_idx + 1, col_idx + 1].Value = value
# ヘッダー行の書式を設定します
worksheet.Range["A1:C1"].Style.Font.IsBold = True
worksheet.Range["A1:C1"].Style.Color = Color.get_Yellow()
# 列幅を設定します
worksheet.Range[1, 1].ColumnWidth = 10
worksheet.Range[1, 2].ColumnWidth = 6
worksheet.Range[1, 3].ColumnWidth = 15
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("NestedListToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
ポイント
出力結果: ヘッダーが太字・黄色で、型が正しく保持された Excel テーブル。
Excel ファイルをよりプロフェッショナルな仕上がりにするために、Spire.XLS for Python を使用して、セルの罫線を追加したり、条件付き書式を設定したり、その他の書式設定オプションを適用したりできます。
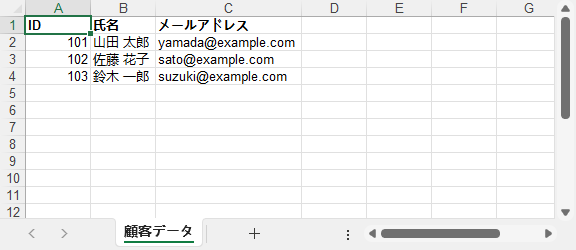
辞書型のリストは、フィールド名付きのデータ構造を扱う際に一般的です。 以下の例では、顧客情報のリストを Excel に書き出します。
from spire.xls import *
from spire.xls.common import *
# Workbook オブジェクトを作成します
workbook = Workbook()
# 既定で作成されるワークシートをすべて削除します
workbook.Worksheets.Clear()
# 新しいワークシートを追加します
worksheet = workbook.Worksheets.Add("顧客データ")
# 辞書のリスト
customers = [
{"ID": 101, "氏名": "山田 太郎", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"},
{"ID": 102, "氏名": "佐藤 花子", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"},
{"ID": 103, "氏名": "鈴木 一郎", "メールアドレス": "このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。"}
]
# 辞書のキーからヘッダーを取得します
headers = list(customers[0].keys())
# ヘッダーを 1 行目に書き込みます
for col, header in enumerate(headers):
worksheet.Range[1, col + 1].Value = header
worksheet.Range[1, col + 1].Style.Font.IsBold = True # ヘッダーを太字に設定します
# データ行を書き込みます
for row, customer in enumerate(customers, start=2): # 2 行目から開始します
for col, key in enumerate(headers):
value = customer[key]
if isinstance(value, (int, float)):
worksheet.Range[row, col + 1].NumberValue = value
else:
worksheet.Range[row, col + 1].Value = value
# 列幅を自動調整します
worksheet.AutoFitColumn(2)
worksheet.AutoFitColumn(3)
# Workbook を Excel ファイルとして保存します
workbook.SaveToFile("CustomerDataToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
メリット
出力結果:ヘッダーが自動生成され、データ型が保持され、列幅が自動調整された Excel ファイル。
Python のリストを Excel に変換する作業はデータ処理の基本スキルです。 Spire.XLS を利用することで、簡単なリストから複雑な入れ子構造、辞書型データまで、きれいで実用的な Excel ファイルを簡単に生成できます。
より高度な操作(グラフ、数式追加など)については、公式ドキュメントをご覧ください。
A: pandas は素早い基本出力に適していますが、書式設定の自由度は低めです。 Spire.XLS は以下の用途に向いています:
workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016)
workbook.SaveToFile("output.xls", ExcelVersion.Version97to2003)
A: Workbook を作成すると空のシートが自動生成されるため、
Workbook.Worksheets.Clear() を呼ばないと不要なシートが残ります。
A: 主な原因は次の通りです:
CSV(Comma-Separated Values)は表形式データの保存に広く利用される汎用フォーマットです。一方、リストは Python における基本データ構造で、データ処理に柔軟に対応できます。Python で CSV をリストへ変換する ことで、データ分析や他の処理フローとの統合をスムーズに行えます。
Python 標準の csv モジュールでも基本的な読み込みは可能ですが、Spire.XLS for Python を使用すると、スプレッドシートのような直感的な操作で構造的な CSV データを扱うことができます。
本記事では、Python で CSV をリスト(および辞書のリスト)に読み込む方法 を、基礎から応用までコード例付きで分かりやすく解説します。
目次:
Spire.XLS はスプレッドシート処理用の強力なライブラリで、CSV 取り扱いにおいて次のような利点があります。
インストール方法
以下の pip コマンドで Spire.XLS for Python をインストールできます:
pip install Spire.XLS
インストール後、すぐにプロジェクトで使用できます。
CSV にヘッダーがない場合(データ行のみの場合)、Spire.XLS を使うと、行ごとにリストへ変換し、最終的に「リストのリスト」として取得できます。
手順:
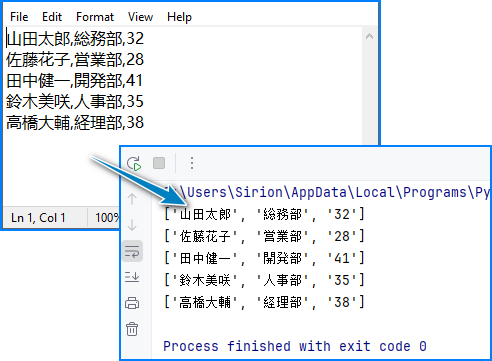
CSV → リスト変換コード例:
from spire.xls import *
from spire.xls.common import *
# Workbook を初期化し、CSV を読み込む
workbook = Workbook()
workbook.LoadFromFile("Employee.csv",",")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# シートのデータを二次元リストへ変換
data_list = []
for i in range(sheet.Rows.Length):
row = []
for j in range(sheet.Columns.Length):
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
# 結果を表示
for row in data_list:
print(row)
# リソースを解放
workbook.Dispose()
出力例:
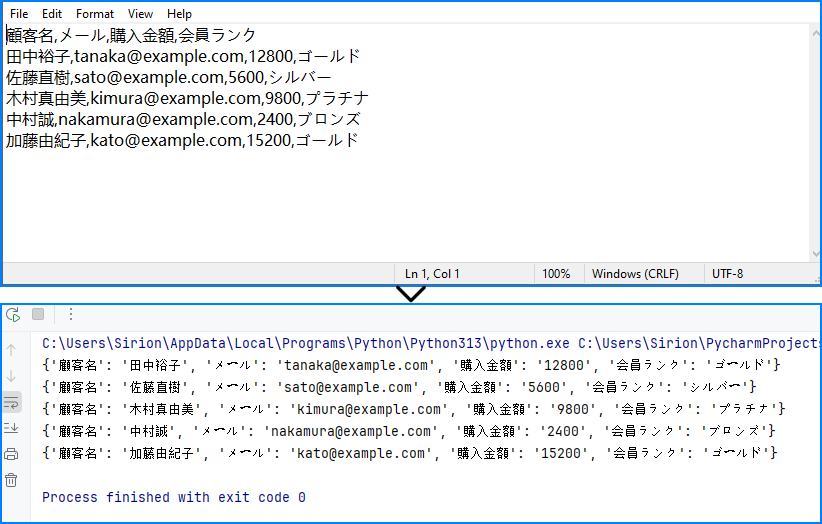
ヘッダー(例:name,age,city)がある CSV の場合、辞書のリストへ変換すると、列名をキーとして扱えるためデータ操作がより直感的になります。
CSV → 辞書リスト変換コード例:
from spire.xls import *
# Workbook を初期化し、CSV を読み込む
workbook = Workbook()
workbook.LoadFromFile("Customer_Data.csv", ",")
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# ヘッダー(1 行目)を取得
headers = []
for j in range(sheet.Columns.Length):
headers.append(sheet.Range[1, j + 1].Value)
# データ行をディクショナリのリストへ変換
dict_list = []
for i in range(1, sheet.Rows.Length): # ヘッダー行をスキップ
row_dict = {}
for j in range(sheet.Columns.Length):
key = headers[j]
value = sheet.Range[i + 1, j + 1].Value
row_dict[key] = value
dict_list.append(row_dict)
# 結果を出力
for record in dict_list:
print(record)
# リソースを解放
workbook.Dispose()
説明
出力例:
カンマ以外の区切り文字(TSV など)を使う場合は、LoadFromFile の第 2 引数で区切り文字を指定します:
# タブ区切りファイル
workbook.LoadFromFile("data.tsv", "\t")
# セミコロン区切りファイル
workbook.LoadFromFile("data_eu.csv", ";")
CSV に空セルがある場合、リストでは空文字 ('') として保持されます。空文字を "N/A" などに置き換える場合は以下のようにします:
cell_value = sheet.Range[i + 1, j + 1].Value or "N/A"
Python で CSV をリストへ変換する方法 は、Spire.XLS を使うことで効率的かつ柔軟になります。 生データ用にリストのリストを使う場合も、構造化された分析のために辞書リストを使う場合も、Spire.XLS はパース処理・インデックス管理・リソース解放を自動的に行ってくれます。
この記事のコード例を活用すれば、データパイプライン、分析スクリプト、アプリケーションへ簡単に組み込むことができます。
より高度な機能については、Spire.XLS for Python ドキュメント を参照してください。
A: はい。一般的な業務データであれば問題なく処理できます。ただし、数百万行規模など極端に大きいデータについては、分割処理やビッグデータ専用のツールの利用を検討してください。
A: Spire.XLS はパース処理を細かく制御でき、追加のデータサイエンス系依存パッケージも不要です。 分析中心なら pandas が便利ですが、CSV の解析を正確に行いたい場合 や pandas が使えない環境 では Spire.XLS が適しています。
A: 辞書のリストへ変換する方法がおすすめです。1 行目をヘッダーとして読み取り、各行のデータとマッピングすることで、列名でデータへアクセスできます。
A: 内側のループで対象列のみを読み込むよう変更してください。
# 1 列目と 3 列目のみを抽出(インデックス 0 と 2)
target_columns = [0, 2]
for i in range(sheet.Rows.Length):
row = []
for j in target_columns:
cell_value = sheet.Range[i + 1, j + 1].Value
row.append(cell_value)
data_list.append(row)
Excel ファイルを PDF 形式に変換することで、スプレッドシートを他人と共有・配布しやすくなります。特に、異なるデバイスやソフトウェアでもレイアウトや書式を維持したい場合に便利です。さらに、PDF は Excel ファイルよりも見栄えが良く、公式なレポートやプレゼン資料、ビジネス文書としてよく利用されます。
この記事では、Python で Spire.XLS for Python ライブラリを使用して、Excel ファイルを PDF に変換する方法をご紹介します。
この操作には、Spire.XLS for Python と plum-dispatch v1.7.4 が必要です。これらは、Spire.XLS for Python の公式ウェブサイトから手動でダウンロードするか、以下の pip コマンドでインストールできます。
pip install Spire.XLSExcelドキュメント全体を1つのPDFファイルに変換するには、Workbook.SaveToFile() メソッドを使用します。変換後のPDFには、各ワークシートが1ページずつ表示されます。変換の詳細設定は、Workbook.ConverterSetting プロパティを使って調整できます。
以下は、Excel ドキュメント全体を PDF に変換する手順です:
from spire.xls import Workbook, FileFormat
# Workbook オブジェクトを作成します
workbook = Workbook()
# Excel ドキュメントを読み込みます
workbook.LoadFromFile("Sample.xlsx")
# ワークブック内のワークシートを繰り返し処理します
for sheet in workbook.Worksheets:
# PageSetup オブジェクトを取得します
pageSetup = sheet.PageSetup
# ページの余白を設定します
pageSetup.TopMargin = 0.3
pageSetup.BottomMargin = 0.3
pageSetup.LeftMargin = 0.3
pageSetup.RightMargin = 0.3
# PDF 変換時にワークシートをページに収めるように設定します
workbook.ConverterSetting.SheetFitToPage = True
# PDF ファイルに変換します
workbook.SaveToFile("output/ExcelをPDFに変換.pdf", FileFormat.PDF)
workbook.Dispose()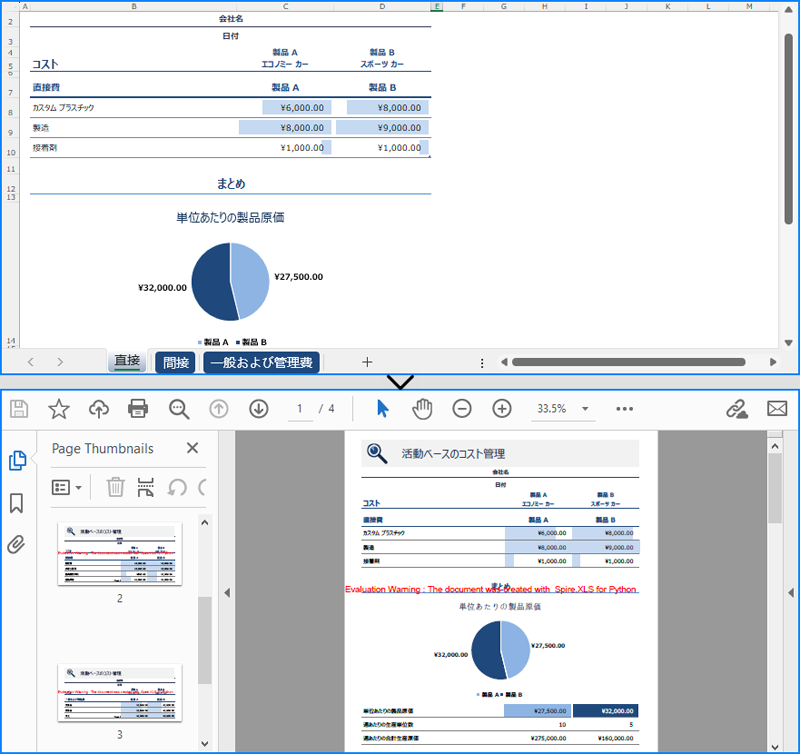
特定のワークシートだけを PDF に変換したい場合は、Worksheet.SaveToPdf() メソッドを使用します。以下がその手順です:
from spire.xls import Workbook
# Workbook オブジェクトを作成します
workbook = Workbook()
# Excel ドキュメントを読み込みます
workbook.LoadFromFile("Sample.xlsx")
# 特定のワークシートを取得します
sheet = workbook.Worksheets[1]
# PageSetup オブジェクトを取得します
pageSetup = sheet.PageSetup
# ページの余白を設定します
pageSetup.TopMargin = 0.3
pageSetup.BottomMargin = 0.3
pageSetup.LeftMargin = 0.3
pageSetup.RightMargin = 0.3
# PDF 変換時にワークシートをページに収めるように設定します
workbook.ConverterSetting.SheetFitToPage = True
# ワークシートを PDF ファイルに変換します
sheet.SaveToPdf("output/ワークシートをPDFに変換.pdf")
workbook.Dispose()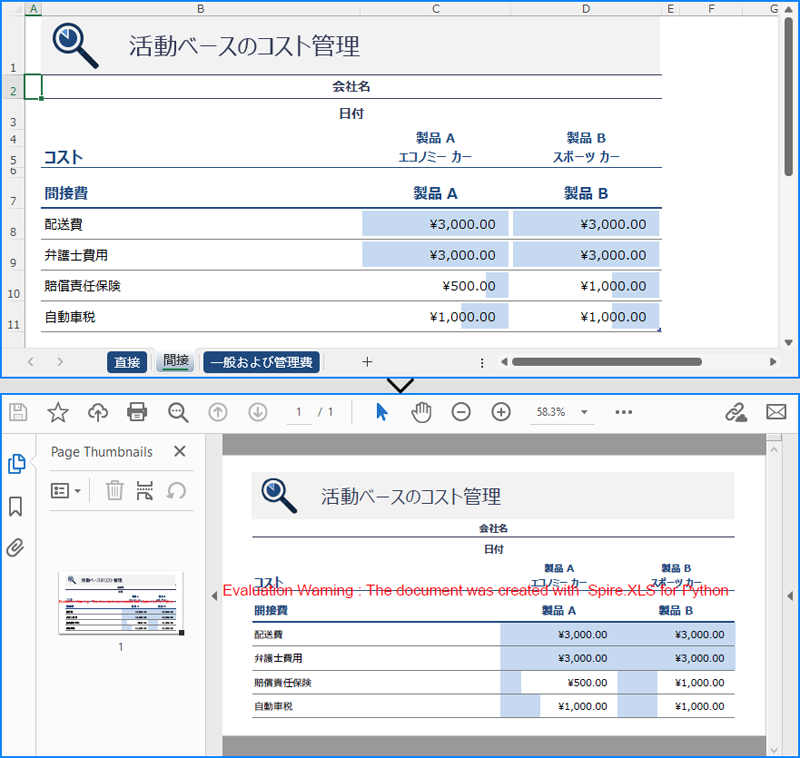
結果ドキュメントから評価メッセージを削除したい場合、または機能制限を取り除く場合は、についてこのメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。にお問い合わせ、30 日間有効な一時ライセンスを取得してください。





