チュートリアル
簡単にライブラリーを使用するためのチュートリアルコレクション

PDF ドキュメント内のテキストの検索と強調表示は、ドキュメントのレビュー、注釈付け、情報抽出に不可欠です。法務文書における重要な条項のマーキング、研究論文における主要な発見の強調、レポートにおける重要データの強調など、プログラム的にテキストを検索して視覚的な強調を適用することで、ドキュメントの可読性とワークフローの効率性を大幅に向上させることができます。
長大な PDF を手動で検索するのは時間がかかり、エラーが発生しやすい作業です。Python による自動化により、開発者は特定のテキストパターンを迅速に見つけ、ドキュメント全体または対象領域に視覚的な強調表示を適用できます。
本ガイドでは、Spire.PDF for Python を使用して PDF 内のテキストを検索・強調表示 する 3 つの強力なアプローチを紹介します。
目次
開始する前に、以下を用意してください。
Python 3.x がインストールされていること
Spire.PDF for Python がインストールされていること:
pip install Spire.PDF
または、Spire.PDF for Python パッケージをダウンロード して手動でインストールすることもできます。
テスト用のサンプル PDF ドキュメント
最も一般的な使用例は、PDF ドキュメント全体で特定のテキストのすべての発生箇所を検索し、強調表示を適用することです。この方法は、キーワード、技術用語、重要なフレーズをマークするのに最適です。
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# PDF ドキュメントのすべてのページをループ処理
for i in range(pdf.Pages.Count):
# 現在のページを取得
page = pdf.Pages.get_Item(i)
# 特定のテキストのすべての発生箇所を検索 (大文字小文字を区別しない)
finder = PdfTextFinder(page)
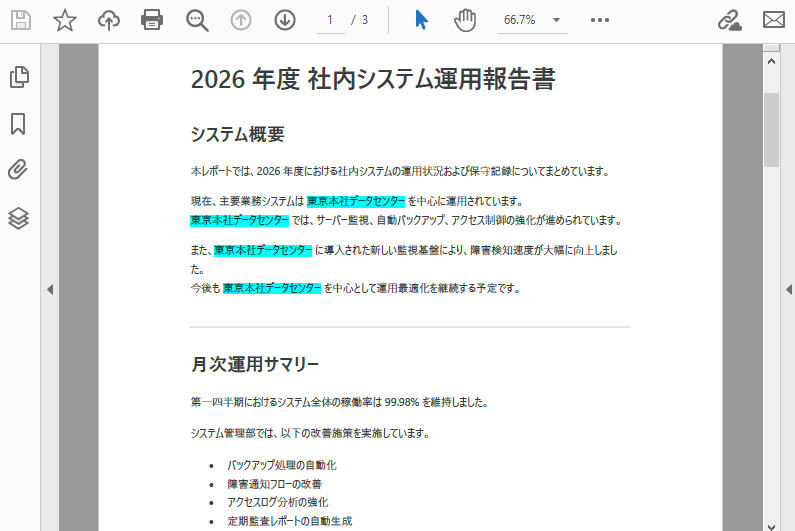
result = finder.Find("東京本社データセンター")
# 見つかったすべての箇所をシアン色で強調表示
for text in result:
text.HighLight(Color.get_Cyan())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlight.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
LoadFromFile(): ソース PDF ドキュメントを読み込むPages.Count: ページの総数を返すPdfTextFinder: テキスト検索を実行するためのクラスFind() メソッドで特定のテキストを検索Find() の戻り値: 見つかったテキストインスタンスのコレクションを返すHighLight(): テキストに背景の強調表示色を適用場合によっては、ヘッダー、フッター、サイドバー、特定のセクションなど、ページの特定の領域内でのみ検索が必要なことがあります。Spire.PDF for Python は、RectangleF パラメータを受け取ることで、領域ベースのテキスト検索をサポートしています。
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 最初のページ (インデックス 0) を取得
pdfPageBase = pdf.Pages.get_Item(0)
# 矩形領域を定義 (x, y, 幅, 高さ)
# この例では、ページの上部 (高さ 240 ポイント) を検索
rctg = RectangleF(0.0, 0.0, pdfPageBase.ActualSize.Width, 240.0)
# PdfTextFindOptions を作成し、矩形領域を検索領域として設定
options = PdfTextFindOptions()
options.Area = rctg
# 「検索」オプションを使用してテキストを検索
finder = PdfTextFinder(pdfPageBase)
finder.Options = options
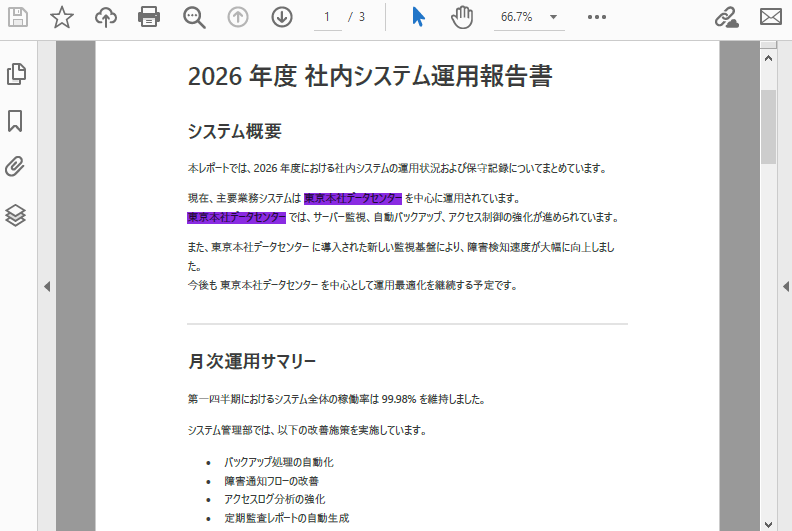
findCollection = finder.Find("東京本社データセンター")
# 見つかったすべてのテキストを青色でハイライト
for find in findCollection:
find.HighLight(Color.get_BlueViolet())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlightArea.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
強調表示が必要なテキストが完全一致ではなくパターンに従っている場合、正規表現は強力な柔軟性を提供します。たとえば、すべてのメールアドレス、電話番号、日付、特定の単語の組み合わせを強調表示したい場合があります。
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 正規表現パターンを定義
# この例では、アスタリスク (*) の後に続く 2 つの単語にマッチ
regex = "\\*(\\w+\\s+\\w+)"
# 2 番目のページ (インデックス 1) を取得
page = pdf.Pages.get_Item(1)
# 正規表現にマッチするテキストを検索 PdfTextFindOptions オブジェクトを作成し、正規表現を使用して検索するように設定
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.Regex
# 検索オプションを適用し、正規表現を使用してテキストを検索
finder = PdfTextFinder(page)
finder.Options = options
result = finder.Find(regex)
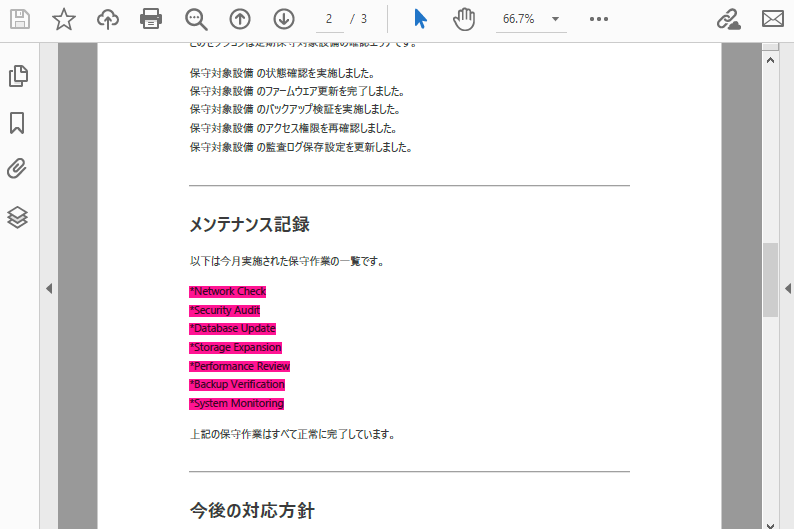
# マッチしたすべてのテキストをディープピンク色で強調表示
for text in result:
text.HighLight(Color.get_DeepPink())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlightRegex.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
理論的には PDF でのテキスト検索と強調表示は簡単ですが、実際にはいくつかの課題が発生する可能性があります。
問題: PDF ビューアーにはテキストが表示されているが、Find() が結果を返さない。
原因:
解決策:
PdfTextFinder の検索オプションを確認問題: 数百ページの検索が遅い。
解決策:
# 例: 特定のページのみを検索
target_pages = [0, 5, 10, 15] # ページインデックス
for i in target_pages:
page = pdf.Pages.get_Item(i)
# 検索を実行...
問題: 特殊文字、アクセント付き文字、非 ASCII 記号を含むテキストの検索が失敗する。
解決策:
# 例: アクセント付き文字にマッチ
pattern = r"café|naïve|résumé"
問題: 大文字小文字のバリエーションを見逃す。
解決策:
PdfTextFinder のオプションで大文字小文字を区別しない設定を使用# 大文字小文字を区別しない検索の設定例
finder = PdfTextFinder(page)
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.IgnoreCase
finder.Options = options
result = finder.Find("keyword")
# 大文字小文字を区別しない正規表現
finder = PdfTextFinder(page)
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.Regex
finder.Options = options
result = finder.Find(r"(?i)pattern")
Spire.PDF を使用すれば、Python での PDF テキストの検索と強調表示は簡単です。完全一致、領域ベースのフィルタリング、正規表現パターンのいずれが必要でも、これらの方法でほとんどの使用例をカバーできます。
このプロセスを自動化することで、ドキュメントレビューを高速化し、データ抽出の効率性を向上させることができます。本番環境での使用では、スキャン済み PDF の処理とパフォーマンスの最適化を検討してください。
制限なしで Spire.PDF for Python を評価したい場合は、30 日間の無料トライアルを申請 できます。
Spire.PDF for Python の PdfTextFinder クラスを使用してテキストを検索し、HighLight() メソッドで色の強調表示を追加します。PdfDocument.LoadFromFile() で PDF を読み込み、PdfTextFinder でページを検索し、SaveToFile() で結果を保存します。
はい。PdfTextFindOptions の Parameter プロパティに TextFindParameter.Regex を設定し、PdfTextFinder.Find() メソッドに正規表現パターンを渡します。これにより、メール、日付、電話番号、その他の構造化データのパターンベースのマッチングが可能になります。
必要な座標と寸法で RectangleF オブジェクトを定義し、PdfTextFindOptions の Area プロパティに設定します。その後、このオプションを PdfTextFinder に適用して検索を実行します。これにより、指定した矩形領域に検索が制限されます。
はい。pdf.Pages.Count をループ処理し、各ページで PdfTextFinder を使用して検索を実行します。本ガイドの例では、複数ページの検索を示しています。
はい。パスワードを指定してパスワード保護された PDF を読み込みます。
pdf.LoadFromFile("protected.pdf", "your_password")
その後、通常の検索と強調表示操作を進めます。

PDF 処理において、文字の追加は非常に一般的なニーズです。レポートの自動生成、注釈の追加、テンプレートへの入力、バージョン情報の記載など、Python で PDF にテキストを追加すること によって、文書処理の効率と柔軟性が大幅に向上します。
手動編集や複雑な外部ツールに頼ることなく、PDF 専用ライブラリを用いれば、数行のコードで文字を正確に挿入することが可能です。この記事では、強力な PDF 操作ライブラリ Spire.PDF for Python を使用して、PDF へのテキスト挿入手順を解説します。
コンテンツ一覧
まずは Python 用 PDF 処理ライブラリ Spire.PDF for Python をインストールします。
pip install Spire.PDF
Free Spire.PDF for Pythonをご利用の場合は以下をインストールしてください:
pip install spire.pdf.free
おすすめポイント:
Python で 白紙の PDF を新たに作成し、テキストを挿入 するには、以下のように操作します。
from spire.pdf import PdfDocument, PdfTrueTypeFont, PdfFontStyle, PdfSolidBrush, PdfRGBColor, PointF, RectangleF, \
PdfStringFormat, PdfTextAlignment, PdfVerticalAlignment
# 新しい PDF ドキュメントを作成し、新しいページを追加
pdf = PdfDocument()
page = pdf.Pages.Add()
# ページに追加するテキスト(例文)
text = ("本レポートは、2025年第1四半期における各製品の販売実績をまとめたものです。"
+ "以下に、製品カテゴリごとの総売上の内訳を示し、"
+ "続いて、地域別の売上比較を行います。")
# フォント、ブラシ、描画位置を設定
font = PdfTrueTypeFont("Yu Gothic UI", 14.0, PdfFontStyle.Regular, True)
brush = PdfSolidBrush(PdfRGBColor(0, 0, 0)) # 黒色
point = PointF(50.0, 100.0)
# レイアウト領域と文字列フォーマットを設定
layoutArea = RectangleF(50.0, 50.0, page.GetClientSize().Width - 100.0, page.GetClientSize().Height)
stringFormat = PdfStringFormat(PdfTextAlignment.Left, PdfVerticalAlignment.Top)
# テキストを描画
page.Canvas.DrawString(text, font, brush, layoutArea, stringFormat, False)
# PDF ファイルとして保存して閉じる
pdf.SaveToFile("output/new.pdf")
pdf.Close()
🔍 技術解説:
PdfTrueTypeFont() はシステムフォントを読み込み、サイズやスタイルも指定可能PdfSolidBrush() によって文字色を設定(例:黒=(0, 0, 0))RectangleF() でテキスト描画エリアを定義し、自動改行にも対応PdfStringFormat() によって文字の配置(左上、中央など)を指定DrawString() で PDF ページにテキストを描画(既存内容には影響なし)生成されたPDFファイル:

📌 ポイント: 複数行の文字列を表示するには、Y 座標を調整したり、複数回 DrawString() を使うことで実現可能です。
既存の PDF ファイルに 文字を追記する には、ファイルを読み込んで任意のページを取得し、必要な位置にテキストを描画します。
よくある用途:
from spire.pdf import PdfDocument, PdfFontStyle, PdfSolidBrush, PdfRGBColor, PointF, PdfCjkStandardFont, PdfCjkFontFamily
# 既存の PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("input.pdf")
page = pdf.Pages[0]
# フォントを作成(Times Roman、12ポイント、太字)
font = PdfCjkStandardFont(PdfCjkFontFamily.HeiseiMinchoW3, 16.0, PdfFontStyle.Bold)
# 赤色のブラシを作成
brush = PdfSolidBrush(PdfRGBColor(255, 0, 0)) # 赤
# テキストの描画位置を設定
location = PointF(150.0, 110.0)
# 指定位置にテキストを描画
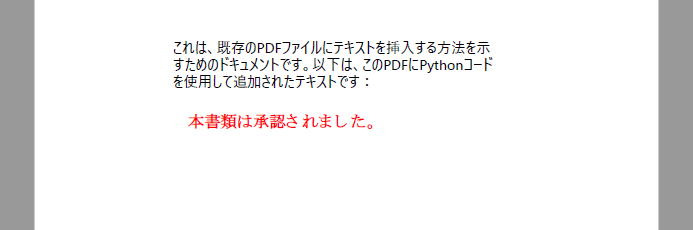
page.Canvas.DrawString("本書類は承認されました。", font, brush, location)
# 修正後の PDF を保存して閉じる
pdf.SaveToFile("output/modified.pdf")
pdf.Close()
🔍 技術解説:
LoadFromFile() で既存 PDF を読み込みpdf.Pages[index] によりページ単位でアクセス可能PointF(x, y) でテキストの描画位置を設定(単位はポイント)生成されたPDFファイル:
💡 必要に応じて座標を調整することで、任意の位置にテキストを自由に配置できます。
テキストの見た目をカスタマイズすることも可能です。Spire.PDF for Python では、フォント・カラー・透明度・回転などのスタイル設定に対応しており、水印や強調表示の表現に便利です。
# PdfTrueTypeFont を作成(Calibri、16ポイント、斜体、フォント埋め込みあり)
font = PdfTrueTypeFont("Calibri", 16.0, PdfFontStyle.Italic, True)
# PdfFont を作成(Times Roman、16ポイント、斜体)
font = PdfFont(PdfFontFamily.TimesRoman, 16.0, PdfFontStyle.Italic)
# テキストの描画色を指定する PdfBrush を作成
brush = PdfSolidBrush(PdfRGBColor(34, 139, 34)) # フォレストグリーン(濃緑)
💡 PdfTrueTypeFont を使えばフォントを PDF 内に埋め込み、他の環境でも文字化けを防げます。ファイル容量を抑えたい場合は、埋め込みなしの PdfFont を使うのも一手です。
# 現在のキャンバス状態を保存
state = page.Canvas.Save()
# 半透明を設定(0.0 = 完全に透明、1.0 = 完全に不透明)
page.Canvas.SetTransparency(0.4)
# 原点をページの中央に移動
page.Canvas.TranslateTransform(page.Size.Width / 2, page.Size.Height / 2)
# キャンバスを -45 度回転(反時計回り)
page.Canvas.RotateTransform(-45)
# 新しい原点位置にテキストを描画
page.Canvas.DrawString("下書き", font, brush, PointF(-50, -20))
回転と透明度の組み合わせで、水平方向や斜め方向のウォーターマークを表現できます。
from spire.pdf import PdfDocument, PdfTrueTypeFont, PdfFontStyle, PdfSolidBrush, PdfRGBColor, PointF
from spire.pdf.common import Color
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("サンプル.pdf")
page = pdf.Pages[0]
# 透かしとして描画するテキスト
text = "外部提供禁止" # "Confidential" を日本語で「機密」と翻訳
# フォントを作成(Arial、40ポイント、太字、フォント埋め込みあり)
font = PdfTrueTypeFont("Yu Gothic UI", 40.0, PdfFontStyle.Bold, True)
# ブラシを作成(ダークブルー)
brush = PdfSolidBrush(PdfRGBColor(Color.get_DarkBlue())) # ダークブルー
# テキストサイズを測定して中央位置を計算
size = font.MeasureString(text)
x = (page.Canvas.ClientSize.Width - size.Width) / 2
y = (page.Canvas.ClientSize.Height - size.Height) / 2
# キャンバスの状態を保存
state = page.Canvas.Save()
# 透過度を 0.3(30%の不透明度)に設定
page.Canvas.SetTransparency(0.3)
# 原点をページ中央に移動
page.Canvas.TranslateTransform(x + size.Width / 2, y + size.Height / 2)
# キャンバスを -45 度回転(反時計回り)
page.Canvas.RotateTransform(-45.0)
# テキストを中央に描画
page.Canvas.DrawString(text, font, brush, PointF(-size.Width / 2, -size.Height / 2))
# キャンバスの状態を元に戻す
page.Canvas.Restore(state)
# 水印付きの PDF を保存
pdf.SaveToFile("output/with_watermark.pdf")
pdf.Close()
💡 「機密」「副本」などの文字を斜めに薄く表示したい場合に有効です。複数ページへの一括挿入も可能です。
生成されたPDFファイル:

⚠ ファイルが他のプロセスによって使用中の場合、保存時に PermissionError が発生することがあります。
PDF に文字を追加する際、以下のような問題が発生することがあります。主な原因と対処方法を以下にまとめます:
| 問題 | 原因 | 解決策 |
|---|---|---|
| 文字位置がズレる | ページサイズを考慮していない | ClientSize や MeasureString() を使って動的に調整 |
| 文字が表示されない | フォントが未対応または不足 | Arial Unicode や Noto Sans を使用し、必要に応じて埋め込み |
| Unicode 文字が正しく表示されない | フォントが対応していない | 広範な Unicode 対応フォントを選定し、埋め込む |
| テキストと本文が重なる | Y 座標が近すぎる | MeasureString() で高さを計測し、行間を調整 |
| 文書に透かしが表示される | 有償版を未認証のまま使用している | 無料版を使うか、一時ライセンスを申請 |
| ファイルサイズが大きくなる | フォントを埋め込んでいるため | PdfFont を使ってフォント埋め込みを避ける |
| macOS/Linux で表示が崩れる | OS 間のフォント差異や描画方式の違い | クロスプラットフォームフォントを使用し、必要ならフォントを同梱配布 |
Spire.PDF for Python を使えば、PDF ドキュメントに柔軟に文字を追加できます。新規作成・既存編集・バッチ処理まで対応しており、フォント・配置・スタイルも自在に調整可能です。
まずは無料版で試してみるか、一時ライセンス を取得して全機能を体験してみてください。
DrawString() メソッドを使うことで、フォントや位置、スタイルを指定してテキストを描画できます。
はい、できます。LoadFromFile() で PDF を読み込み、対象ページに DrawString() で文字を挿入できます。
テキスト内容を 1 行ずつ読み込み、位置を調整しながら PDF に描画することで変換可能です。
はい。ループ処理で PDF を順次読み込み、共通のテキストを挿入することで実現できます。





