Python でデータを扱う際、TXT を CSV に変換するニーズは非常に一般的です。TXT ファイルは非構造のプレーンテキストとして保存されることが多く、プログラムでの処理が難しい場合があります。一方、CSV ファイルはデータを行と列に整理して格納するため、データ分析、レポート作成、アプリケーション間での共有に適しています。
テキストデータをより扱いやすく構造化するため、開発者は TXT ファイルの内容を解析し、表形式に整理して CSV に変換する必要があります。しかし、この処理を手動で行うのは非効率でミスも発生しやすく、特に複数ファイルや複雑な区切り文字を扱う場合は問題が顕著になります。
本ガイドでは、Spire.XLS for Python を使用し、Python で TXT ファイルを CSV 形式に変換する一連の処理フローを構築する方法を解説します。実務において拡張性と実用性を兼ね備えたアプローチです。
クイックナビゲーション
- CSV ファイルとは
- 前提条件
- ステップ1:単一の TXT ファイルを CSV に変換
- ステップ2:複数 TXT ファイルの一括変換を自動化
- TXT から CSV 変換の応用テクニック
- TXT から CSV 変換時のよくある問題
- まとめ
- FAQ
CSV ファイルとは
CSV(Comma-Separated Values)は、表形式データを保存するためのシンプルなテキストベースのファイル形式です。各行が1レコードを表し、行内の値はカンマ(またはタブやセミコロンなどの区切り文字)で区切られます。
CSV は、Excel、Google スプレッドシート、データベース、Python などのプログラミング言語で広くサポートされています。そのシンプルな構造により、データのインポート、エクスポート、分析、自動処理が容易に行えます。
CSV ファイルの例:
Name, Age, City
John, 28, New York
Alice, 34, Los Angeles
Bob, 25, Chicago
このような構造化形式は効率的なデータ処理を可能にし、非構造の TXT ファイルからの変換に適しています。
前提条件
開始する前に、以下を準備してください:
Python 3.x がインストールされていること
Spire.XLS for Python のインストール:
pip install Spire.XLSまたは、Spire.XLS for Python をダウンロード して手動でプロジェクトに追加することもできます。
Python コードを作成するためのテキストエディターまたは IDE
ステップ1:単一の TXT ファイルを CSV に変換
Python で TXT ファイルを CSV に変換する処理はシンプルで、以下の手順で実行できます:
- テキストファイルの読み込み:TXT ファイルを読み込み、行単位でデータを取得します
- データの分割:スペースやタブ、カンマなどの区切り文字で各行をフィールドに分割します
- CSV への書き込み:Spire.XLS を使用して処理済みデータを CSV ファイルとして出力します
- 結果の確認:Excel、Google スプレッドシート、またはテキストエディターで確認します
Python で TXT を CSV に変換
以下のコードは、Python を使用して TXT ファイルを CSV にエクスポートする方法を示します:
from spire.xls import *
# TXT ファイルを読み込む
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# 各行をスペースで分割して処理(必要に応じて区切り文字を変更)
processed_data = [line.strip().split() for line in lines]
# Excel ワークブックを作成
workbook = Workbook()
# 最初のワークシートを取得
sheet = workbook.Worksheets[0]
# 処理済みデータをワークシートに書き込む
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
# セルにデータを書き込む
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# ワークシートを CSV ファイルとして保存(UTF-8 エンコーディング)
sheet.SaveToFile("TxtToCsv.csv", ",", Encoding.get_UTF8())
# リソースを解放
workbook.Dispose()
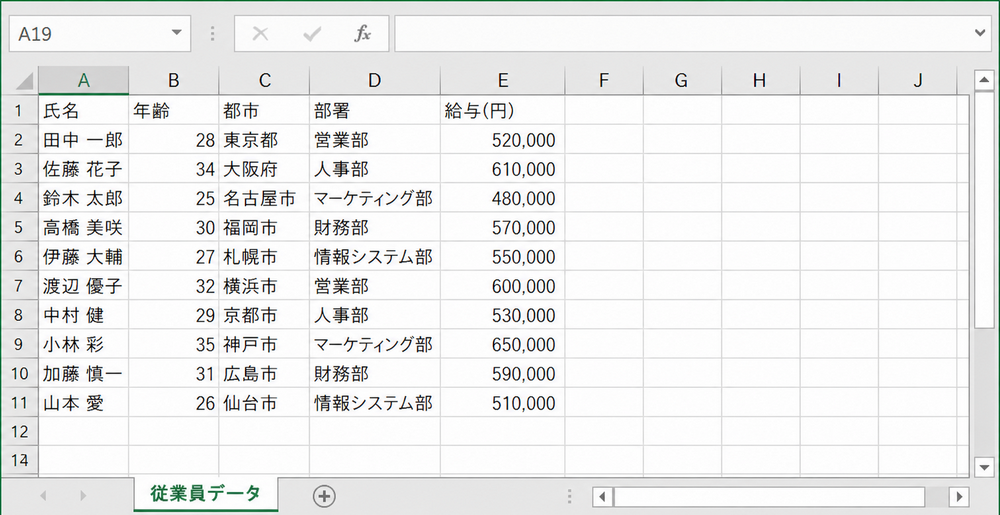
以下は変換結果のイメージです:
コードの説明
- open():UTF-8 エンコーディングで TXT ファイルを読み込み
- readlines():すべての行をリストとして取得
- strip().split():空白を削除し、スペースで分割
- Workbook():新しい Excel ワークブックを作成
- Worksheets[0]:最初のワークシートにアクセス
- Range[row, col].Value:指定セルにデータを書き込み
- SaveToFile():カンマ区切りで CSV として出力
- Dispose():メモリリーク防止のためリソースを解放
データがすでにリスト形式になっている場合は、Spire.XLS for Python を使用して、そのリストを Excel や CSV ファイルに変換することもできます。
ステップ2:複数 TXT ファイルの一括変換を自動化
複数の TXT ファイルを自動的に CSV に変換する場合、フォルダー内のすべての .txt ファイルをループ処理して順番に変換できます。
TXT ファイルの一括 CSV 変換
以下のコードは、複数の TXT ファイルを一括で CSV に変換する方法を示します:
import os
from spire.xls import *
# TXT ファイルが格納されているフォルダー
input_folder = "txt_files"
output_folder = "csv_files"
# 出力フォルダーが存在しない場合は作成
os.makedirs(output_folder, exist_ok=True)
# 単一ファイルを変換する関数
def convert_txt_to_csv(file_path, output_path):
# TXT ファイルを読み込む
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
# 各行を処理(スペース区切り。必要に応じて変更)
processed_data = [line.strip().split() for line in lines if line.strip()]
# ワークブックを作成し、最初のワークシートを取得
workbook = Workbook()
sheet = workbook.Worksheets[0]
# データを書き込み
for row_num, row_data in enumerate(processed_data):
for col_num, cell_data in enumerate(row_data):
sheet.Range[row_num + 1, col_num + 1].Value = cell_data
# CSV として保存(UTF-8)
sheet.SaveToFile(output_path, ",", Encoding.get_UTF8())
workbook.Dispose()
print(f"Converted '{file_path}' -> '{output_path}'")
# フォルダー内のすべての TXT ファイルを処理
for filename in os.listdir(input_folder):
if filename.lower().endswith(".txt"):
input_path = os.path.join(input_folder, filename)
output_name = os.path.splitext(filename)[0] + ".csv"
output_path = os.path.join(output_folder, output_name)
convert_txt_to_csv(input_path, output_path)
ポイント
- os.makedirs():出力フォルダーを作成
- 関数化:再利用可能な変換ロジック
- os.listdir():フォルダー内のファイルを列挙
- endswith(".txt"):TXT ファイルのみ対象
- os.path.splitext():拡張子を除いたファイル名を取得
- 一括処理:すべての TXT ファイルを自動変換
この方法により、大量のファイルを扱う際の作業効率が大幅に向上します。
TXT から CSV への変換に関する応用テクニック
テキストファイルを CSV に変換する際は、ファイルのレイアウトの違いや想定外のエラーが発生する可能性があります。以下のポイントを押さえることで、さまざまなケースに柔軟かつ安定して対応できます。
1. 区切り文字(デリミタ)の違いに対応する
すべての TXT ファイルがスペース区切りとは限りません。タブ、カンマ、またはその他の文字が使用されている場合は、split() 関数の引数を適切に変更する必要があります。
タブ区切りファイル(.tsv)の場合:
processed_data = [line.strip().split('\t') for line in lines]
カンマ区切りの場合:
processed_data = [line.strip().split(',') for line in lines]
カスタム区切り文字(例:|)の場合:
processed_data = [line.strip().split('|') for line in lines]
このように事前に正しく列分割を行うことで、CSV 出力時のデータ構造を正確に保つことができます。
2. エラーハンドリングの追加
ファイルの読み込み・書き込み処理では、例外処理(try-except)を導入することが重要です。これにより、スクリプトの安定性が向上し、予期しないクラッシュを防ぐことができます。
try:
# 変換処理
with open("data.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
# ... 続きの処理
except FileNotFoundError:
print("エラー:指定されたファイルが見つかりません。")
except Exception as e:
print(f"エラー:{e}")
補足: エラーメッセージはできるだけ具体的に記述すると、原因特定が容易になります。
3. 空行のスキップ
TXT ファイルには空行が含まれている場合があります。そのまま処理すると、CSV に空行が出力されてしまいます。
processed_data = [line.strip().split() for line in lines if line.strip()]
このように条件を付けてフィルタリングすることで、実データのみを処理し、よりクリーンな CSV を生成できます。
TXT から CSV 変換時によくある問題と対策
TXT から CSV への変換は一見シンプルですが、実際にはいくつかの実務的な課題が存在します。
1. 区切り文字の不統一
同一ファイル内でも、行ごとに異なる区切り文字が使われている場合があります。その結果、列がずれてしまうことがあります。
対策:
- 全行で区切り文字の一貫性を確認する
- 複雑な場合は正規表現(regex)を使用する
- 前処理で区切り文字を統一する
2. 列数の不一致(不足・過剰)
行によって列数が異なると、データの整合性が崩れます。
対策:
- 不足している列には空文字を補完する
- 不要な列は必要に応じて切り捨てる
- 書き込み前に列数を検証する
3. エンコーディングの問題
TXT ファイルは UTF-8、ASCII、Latin-1 など異なるエンコーディングで保存されている場合があります。これにより文字化けが発生する可能性があります。
対策:
chardetなどのライブラリでエンコーディングを検出する- ファイル読み込み時にエンコーディングを明示する
- CSV 出力は UTF-8 を使用して互換性を確保する
4. 特殊文字や引用符の扱い
カンマ、引用符、改行などを含むフィールドは、CSV の構造を破壊する可能性があります。
対策:
- 特殊文字を適切にエスケープする
- 必要に応じてフィールドを引用符で囲む
- (Spire.XLS を使用しない場合)CSV 専用ライブラリを利用する
5. 大規模ファイルの処理性能
非常に大きな TXT ファイルを扱う場合、メモリ使用量が増大する可能性があります。
対策:
- ファイル全体を一度に読み込まず、行単位で処理する
- ストリーミング処理を導入する
- ワークブックは速やかに破棄(Dispose)してメモリを解放する
6. 空白やフォーマットのばらつき
余分なスペースや不統一なフォーマットは、データ品質に影響します。
対策:
- 各フィールドの前後の空白を削除する
- 内部のスペースを正規化する
- 前処理で不要な文字を除去する
これらのポイントを事前に考慮することで、より信頼性の高い TXT → CSV 変換ワークフロー を構築できます。
まとめ
TXT ファイルを CSV に変換する処理は、単なるファイル形式の変換ではなく、テキストデータの読み込み・解析・構造化を含む一連のプロセスです。
Python と Spire.XLS を組み合わせることで、安定性と拡張性を兼ね備えた TXT → CSV 変換パイプライン を効率よく構築できます。これにより、データ前処理の自動化が大幅に容易になります。
この手法は、ログファイル、データエクスポート、各種テキストデータを分析・レポート・スプレッドシート連携用に構造化する場面で特に有効です。
Spire.XLS for Python を使用することで、以下が実現できます:
- 少ないコードで単一の TXT ファイルを CSV に変換
- 複数ファイルの一括変換を自動化
- さまざまな区切り文字やエッジケースに対応
- UTF-8 による多言語対応の確保
より詳細に機能を評価したい場合や制限を解除したい場合は、30日間の無料トライアル を利用できます。
FAQ
Microsoft Excel がインストールされていなくても TXT を CSV に変換できますか?
はい。Spire.XLS for Python は Microsoft Excel に依存せずに動作するため、Excel がインストールされていない環境でも CSV ファイルの生成・出力が可能です。
Python で複数の TXT ファイルを一括で CSV に変換するにはどうすればよいですか?
フォルダー内のすべての TXT ファイルをループ処理し、各ファイルに対して変換関数を適用します。本記事では、指定ディレクトリ内の .txt ファイルを自動処理するサンプルコードを紹介しています。
TXT ファイルに空行や不正な行がある場合はどう処理すればよいですか?
if line.strip() のような条件で空行を除外し、さらに列数の検証ロジックを追加することで、不整合や空行の出力を防ぐことができます。
タブ区切りやカスタム区切りの TXT ファイルはどのように CSV に変換できますか?
TXT ファイルの区切り文字に応じて、split() の引数を変更します。例えば、タブ(\t)、カンマ、パイプ(|)などに対応するには、split('\t')、split(',')、split('|') のように指定します。
TXT から CSV への変換で推奨されるエンコーディングは何ですか?
UTF-8 の使用が推奨されます。多言語文字に対応でき、さまざまな環境・アプリケーションとの互換性を確保できます。
TXT を CSV ではなく Excel に変換することはできますか?
はい。Spire.XLS for Python を使用すれば、TXT ファイルを XLSX / XLS 形式に直接変換することも可能です。詳細は関連チュートリアルを参照してください。





