
PDF をデータベースに変換することは、データ駆動型アプリケーションにおける一般的な要件です。請求書、レポート、財務記録など、多くのビジネス文書は構造化情報を PDF 形式で保存していますが、これらのデータはクエリや分析に直接使用できません。
これらのデータを利用可能にするために、開発者は通常、構造化コンテンツを抽出してリレーショナルデータベース(SQL Server、MySQL、PostgreSQL など)に挿入することで、PDF を SQL に変換する必要があります。このプロセスを手動で処理するのは非効率的でエラーが発生しやすく、特に大規模な処理では問題となります。
このガイドでは、PDF からテーブルデータを抽出し、Spire.PDF for Python を使用してデータを Python の SQL データベースに変換および挿入する完全なパイプラインを構築することに焦点を当てています。このアプローチは、現実世界の PDF からデータベースへのワークフローにおいて、最も実用的でスケーラブルなソリューションを反映しています。
クイックナビゲーション
- ワークフローの理解
- 前提条件
- ステップ1:PDF からテーブルデータを抽出
- ステップ2:データを変換してデータベースに挿入
- 完全なパイプライン:PDF 抽出から SQL 保存まで
- 他の SQL データベースへの適応
- 他の種類の PDF データの処理
- PDF データをデータベースに変換する際の一般的な落とし穴
- 結論
- よくある質問
ワークフローの理解
実装に入る前に、PDF データをデータベースに変換する全体的なプロセスを理解することが重要です。
各操作を完全に独立したプロセスとして扱うのではなく、このワークフローは2つの主要な段階として見ることができます。
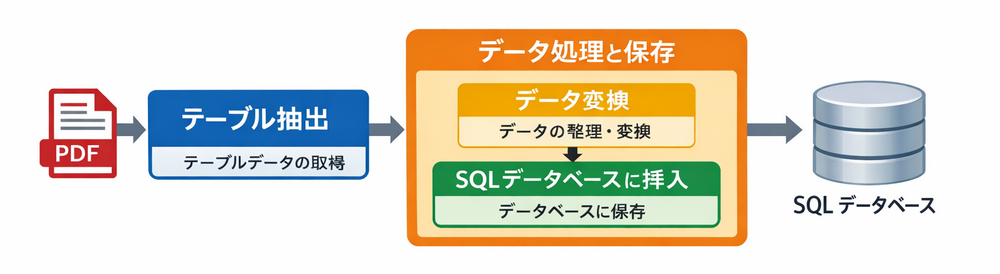
各段階はパイプライン内で独自の役割を果たします。
テーブル抽出:PDF ドキュメントから構造化されたテーブルデータを取得
データ処理と保存:抽出したデータをクリーニング、構造化し、リレーショナルデータベースに挿入
- データ変換:生の行を構造化されたデータベース対応のレコードに変換
- SQL データベースに挿入:処理済みのデータを SQL データベースに永続化
このエンドツーエンドのパイプラインは、ほとんどの実際のシステムが PDF からデータベース へのワークフローをどのように処理するかを反映しています——まず利用可能なデータを抽出し、次に処理してクエリと分析のためにデータベースに保存します。
前提条件
開始する前に、以下を用意してください。
Python 3.x がインストールされている
Spire.PDF for Python がインストールされている:
pip install Spire.PDFまた、Spire.PDF for Python をダウンロードしてプロジェクトに手動で追加することもできます。
リレーショナルデータベースシステム(SQLite、SQL Server、MySQL、PostgreSQL など)
このガイドでは簡略化のため SQLite を使用してデモを行いますが、同じアプローチを他の SQL データベースにも適用できる方法も示しています。
ステップ1:PDF からテーブルデータを抽出
請求書やレポートなどのほとんどのビジネス文書では、データは表形式で整理されています。これらのテーブルはすでに行と列の構造に従っているため、SQL データベースへの直接挿入に最適です。
PDF 内のテーブルデータは通常、すでに行と列の形式で構造化されており、これがデータベース保存に最も適した形式です。
Python を使用してテーブルを抽出
以下は、Spire.PDF を使用して PDF ファイルからテーブルデータを抽出する例です。
from spire.pdf import *
from spire.pdf.common import *
# PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Quarterly Sales.pdf")
table_data = []
# ページを繰り返し処理
for i in range(pdf.Pages.Count):
# ページからテーブルを抽出
extractor = PdfTableExtractor(pdf)
tables = extractor.ExtractTable(i)
if tables:
print(f"{i+1} ページ目に {len(tables)} 個のテーブルがあります。")
for table in tables:
rows = []
for row in range(table.GetRowCount()):
row_data = []
for col in range(table.GetColumnCount()):
text = table.GetText(row, col)
row_data.append(text.strip() if text else "")
rows.append(row_data)
table_data.extend(rows)
pdf.Close()
# 抽出したデータを表示
for row in table_data:
print(row)
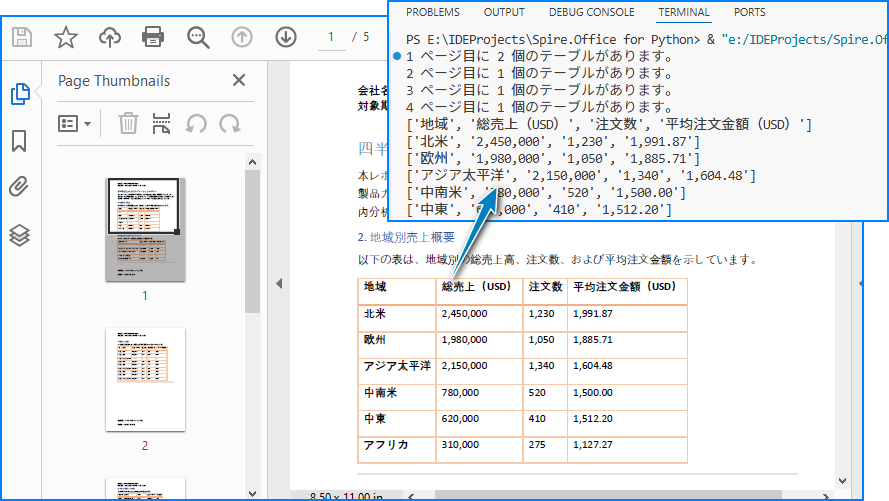
以下は抽出結果のプレビューです。
コードの説明
- LoadFromFile:PDF ドキュメントを読み込む
- PdfTableExtractor:各ページ内のテーブルを識別
- GetText(row, col):セルの内容を取得
- table_data:抽出した行をリストのリストとして保存
この段階では、データは抽出されていますが、データベース使用の観点からはまだ構造化されていません。テーブルデータを抽出したら、SQL 挿入に適した構造化形式に変換する必要があります。
ステップ2:データを変換してデータベースに挿入
PDF から抽出された生のテーブルデータは、SQL データベースに挿入する前に、クリーニングと構造化が必要になることがよくあります。
簡略化のため、以下の例では 単一の抽出されたテーブル を処理する方法を示しています。実際のシナリオでは、PDF に複数のテーブルが含まれている可能性があり、同じロジックをループで使用して処理できます。
データを変換(単一テーブルの例)
structured_data = []
# 最初の行をヘッダーと仮定
headers = table_data[0]
for row in table_data[1:]:
if not any(row):
continue
record = {}
for i in range(len(headers)):
value = row[i] if i < len(row) else ""
record[headers[i]] = value
structured_data.append(record)
# 構造化データのプレビュー
for item in structured_data:
print(item)
このステップの役割
- 行を辞書ベースのレコードに変換
- 列ヘッダーを値にマッピング
- 空の行をフィルタリング
- データベース挿入用に構造化データを準備
さらに以下のことも可能です。
- SQL 互換性のために列名を正規化
- 数値フィールドを変換
- 日付形式を標準化
生の PDF データを構造化形式に変換することで、リレーショナルデータベースへの確実な挿入が可能になります。変換後、データはすぐにデータベースに挿入できるようになり、パイプラインが完了します。
SQLite にデータを挿入(単一テーブルの例)
単一テーブルからの構造化データを使用して、列名をハードコーディングせずにデータベーススキーマを動的に作成し、レコードを挿入できます。
import sqlite3
# SQLite データベースに接続
conn = sqlite3.connect("sales_data.db")
cursor = conn.cursor()
# ヘッダーに基づいてテーブルを動的に作成
columns_def = ", ".join([f'"{h}" TEXT' for h in headers])
cursor.execute(f"""
CREATE TABLE IF NOT EXISTS invoices (
id INTEGER PRIMARY KEY AUTOINCREMENT,
{columns_def}
)
""")
# 挿入ステートメントを準備
placeholders = ", ".join(["?" for _ in headers])
column_names = ", ".join([f'"{h}"' for h in headers])
# データを挿入
for record in structured_data:
values = [record.get(h, "") for h in headers]
cursor.execute(f"""
INSERT INTO invoices ({column_names})
VALUES ({placeholders})
""", values)
# コミットして閉じる
conn.commit()
conn.close()
重要なポイント
- 抽出したヘッダーに基づいてデータベーステーブルを動的に作成
- パラメータ化クエリ(
?)を使用して SQL インジェクションを防止 - 列名をハードコーディングせずに柔軟なスキーマを維持
- SQL 互換性を確保するために列名を正規化可能
- バッチ挿入で大規模データセットのパフォーマンスを向上
このセクションでは、単一テーブルの例を使用して PDF テーブルデータをリレーショナルデータベースに変換するコアワークフローを示しました。次のセクションでは、このアプローチを拡張して 複数のテーブル を自動的に処理する方法を説明します。
完全なパイプライン:PDF 抽出から SQL 保存まで
以下は、PDF からデータベースまでの全ワークフローを示す完全な実行可能例です。
from spire.pdf import *
from spire.pdf.common import *
import sqlite3
import re
# ---------------------------
# ユーティリティ関数
# ---------------------------
def clean_column_name(name: str, index: int) -> str:
"""
列名の空白を整理する
"""
if not name:
return f"column_{index}"
# 文字列に変換し、前後の空白を削除
name = str(name).strip()
# 複数の空白文字を1つに統一(隠れた空白や改行を防ぐ)
name = re.sub(r'\s+', ' ', name)
return name
# ---------------------------
# ステップ1:PDFからテーブルを抽出
# ---------------------------
pdf = PdfDocument()
pdf.LoadFromFile("Quarterly Sales.pdf")
extractor = PdfTableExtractor(pdf)
all_tables = []
# 全ページをループ処理
for i in range(pdf.Pages.Count):
tables = extractor.ExtractTable(i)
if tables:
for table in tables:
table_rows = []
# テーブルの行を走査
for row in range(table.GetRowCount()):
row_data = []
# 列を走査
for col in range(table.GetColumnCount()):
text = table.GetText(row, col)
row_data.append(text)
table_rows.append(row_data)
if table_rows:
all_tables.append(table_rows)
pdf.Close()
# テーブルが抽出できなかった場合はエラー
if not all_tables:
raise ValueError("PDF内にテーブルが見つかりませんでした")
# ---------------------------
# ステップ2:SQLiteデータベースへ書き込み
# ---------------------------
conn = sqlite3.connect("sales_data.db")
cursor = conn.cursor()
for table_index, table in enumerate(all_tables):
# 無効なテーブル(1行のみなど)はスキップ
if len(table) < 2:
continue
# ヘッダー行(1行目)
raw_headers = table[0]
# ---------------------------
# 列名の整理(空白のみ処理)
# ---------------------------
clean_headers = [
clean_column_name(h, i)
for i, h in enumerate(raw_headers)
]
# テーブル名
table_name = f"table_{table_index+1}"
# ---------------------------
# 既存テーブルがあれば削除(構造衝突を防ぐ)
# ---------------------------
cursor.execute(f'DROP TABLE IF EXISTS "{table_name}"')
# ---------------------------
# テーブル構造の作成
# ---------------------------
columns_def = ", ".join([f'"{col}" TEXT' for col in clean_headers])
cursor.execute(f"""
CREATE TABLE "{table_name}" (
id INTEGER PRIMARY KEY AUTOINCREMENT,
{columns_def}
)
""")
# ---------------------------
# INSERT文の構築
# ---------------------------
placeholders = ", ".join(["?" for _ in clean_headers])
column_names = ", ".join([f'"{col}"' for col in clean_headers])
insert_sql = f"""
INSERT INTO "{table_name}" ({column_names})
VALUES ({placeholders})
"""
# ---------------------------
# バッチ挿入用データ準備
# ---------------------------
batch = []
for row in table[1:]:
# 空行をスキップ
if not any(row):
continue
values = [
row[i] if i < len(row) else ""
for i in range(len(clean_headers))
]
batch.append(values)
# バッチ挿入実行
if batch:
cursor.executemany(insert_sql, batch)
print(f"{table_name} に {len(batch)} 行データを挿入しました")
# トランザクションをコミット
conn.commit()
conn.close()
print(f"PDF処理完了:合計 {len(all_tables)} 個のテーブルを抽出しました")
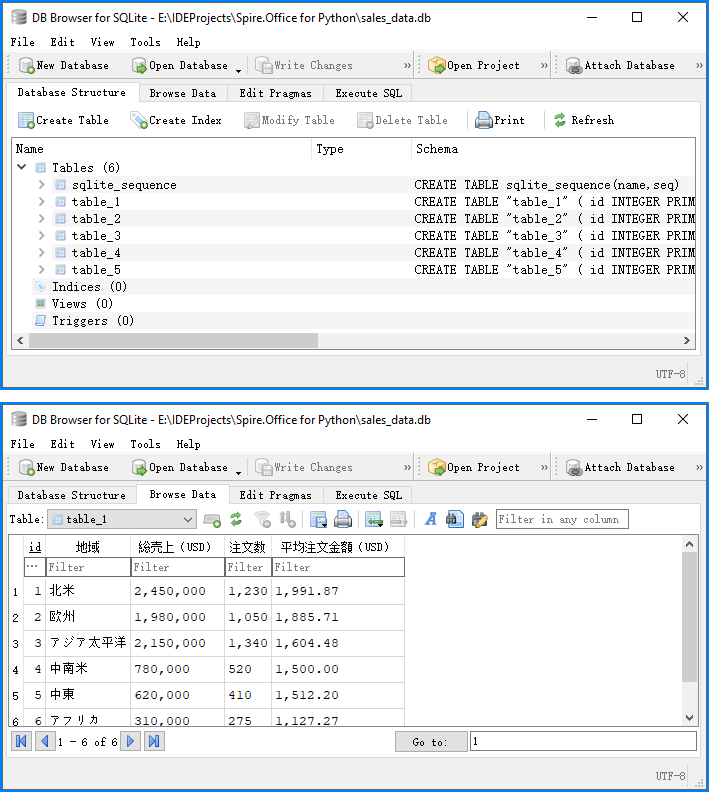
以下はデータベースへの挿入結果のプレビューです。
この完全な例は、PDF からデータベース への完全なパイプラインを示しています。
- 読み込みと抽出:Spire.PDF を使用して PDF からテーブルデータを抽出
- 変換:生データを構造化レコードに変換
- 挿入:適切なスキーマを持つ SQLite データベースに挿入
AUTOINCREMENT を使用すると、SQLite は現在の最大 ID を追跡するために sqlite_sequence というシステムテーブルを自動的に作成します。これは予想される動作であり、データには影響しません。このコードを直接実行して、PDF テーブルデータをデータベースに変換できます。
注意:この例では、テーブルデータ内の日本語のヘッダーをそのままカラム名として使用しています。データベースがUnicode(例:SQLite、MySQL、SQL Server)をサポートしている場合、日本語のカラム名を安全に使用することができます。ただし、システム間連携やエンタープライズ環境では、互換性を高めるために英語へマッピングすることを推奨します。
他の SQL データベースへの適応
このガイドでは簡略化のため SQLite を使用していますが、同じアプローチは他の SQL データベースでも機能します。抽出と変換の手順は変わらず、データベース接続と挿入構文のみがわずかに異なります。
以下の例では、前の手順で生成された正規化された列名(headers)を使用していることを前提としています。
SQL Server の例
import pyodbc
# SQL Server に接続
conn_str = (
"DRIVER={SQL Server};"
"SERVER=your_server_name;"
"DATABASE=your_database_name;"
"UID=your_username;"
"PWD=your_password"
)
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
# 正規化されたヘッダーを使用して動的な列定義を生成
columns_def = ", ".join([f"[{h}] NVARCHAR(MAX)" for h in headers])
# テーブルを動的に作成
cursor.execute(f"""
IF NOT EXISTS (SELECT * FROM sys.tables WHERE name = 'invoices')
BEGIN
CREATE TABLE invoices (
id INT IDENTITY(1,1) PRIMARY KEY,
{columns_def}
)
END
""")
# 挿入ステートメントを準備
placeholders = ", ".join(["?" for _ in headers])
column_names = ", ".join([f"[{h}]" for h in headers])
# データを挿入
for record in structured_data:
values = [record.get(h, "") for h in headers]
cursor.execute(f"""
INSERT INTO invoices ({column_names})
VALUES ({placeholders})
""", values)
# コミットして閉じる
conn.commit()
conn.close()
MySQL の例
import mysql.connector
conn = mysql.connector.connect(
host="localhost",
user="your_username",
password="your_password",
database="your_database"
)
cursor = conn.cursor()
# 前述と同じ動的なテーブル作成と挿入ロジックを使用し、
# 必要に応じて構文を微調整
PostgreSQL の例
import psycopg2
conn = psycopg2.connect(
host="localhost",
database="your_database",
user="your_username",
password="your_password"
)
cursor = conn.cursor()
# 前述と同じ動的なテーブル作成と挿入ロジックを使用し、
# 必要に応じて構文を微調整
コアの抽出と変換手順は、異なる SQL データベース間で変わりません。特に、互換性を確保するために正規化された列名を使用する場合です。
他の種類の PDF データの処理
このガイドはテーブル抽出に焦点を当てていますが、PDF にはユースケースに応じてデータベースにも統合できる他の種類のデータが含まれていることがよくあります。
テキストデータ(非構造化 → 構造化)
多くの文書では、請求書番号、顧客名、日付などの重要な情報は、テーブルではなくプレーンテキストに埋め込まれています。
以下を使用して生テキストを抽出できます。
from spire.pdf import *
pdf = PdfDocument()
pdf.LoadFromFile("Quarterly Sales.pdf")
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
extractor = PdfTextExtractor(page)
options = PdfTextExtractOptions()
options.IsExtractAllText = True
text = extractor.ExtractText(options)
print(text)
ただし、生テキストは直接データベースに挿入できません。通常、構造化フィールドに解析する必要があります。例えば:
- 正規表現を使用してキーと値のペアを抽出
- 日付、ID、合計などのパターンを識別
- テキストを辞書または構造化レコードに変換
構造化されると、データは前述の同じ変換および挿入パイプラインの一部としてデータベースに挿入できます。
より高度な技術については、詳細な Python PDF テキスト抽出ガイド で詳しく学ぶことができます。
画像(OCR またはファイル参照)
PDF 内の画像は通常、構造化データとして直接使用できませんが、2 つの方法でデータベースワークフローに統合できます。
オプション1:OCR(データ抽出に推奨) OCR ツールを使用して画像をテキストに変換し、抽出したコンテンツを処理して保存します。
オプション2:ファイルストレージ(ドキュメントシステムに推奨) 画像を以下として保存:
- データベース内のファイルパス
- 必要に応じてバイナリ(BLOB)データ
以下は画像を抽出する例です。
from spire.pdf import *
pdf = PdfDocument()
pdf.LoadFromFile("Quarterly Sales.pdf")
helper = PdfImageHelper()
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
images = helper.GetImagesInfo(page)
for j, img in enumerate(images):
img.Image.Save(f"image_{i}_{j}.png")
PDFファイルから画像を抽出するPythonの詳細な操作については、「Pythonを使用してPDF文書から画像を抽出する方法」をご参照ください。
完全な PDF ストレージ(BLOB またはファイル参照)
場合によっては、構造化データを抽出するのではなく、PDF ファイル全体をデータベースに保存することが目的です。
これは一般的に以下で使用されます。
- ドキュメント管理システム
- アーカイブシステム
- コンプライアンスおよび監査ワークフロー
PDF を以下として保存できます。
- データベース内の BLOB データ
- 外部ストレージを参照する ファイルパス
このアプローチは、「データベース内の PDF」 の別の意味を表していますが、構造化データ抽出とは異なります。
重要なポイント
PDF には複数の種類のコンテンツを含めることができますが、テーブルデータはデータベース統合において最も効率的でスケーラブルな形式です。他のデータ型は、効果的に保存またはクエリを実行する前に、通常、追加の処理が必要です。
PDF データをデータベースに変換する際の一般的な落とし穴
PDF をデータベースに変換するプロセスは単純に見えるかもしれませんが、いくつかの実用的な課題が発生する可能性があります。
1. 一貫性のないテーブル構造
すべての PDF が一貫したテーブル形式に従っているわけではありません。
- 列の欠落
- 結合されたセル
- 不規則なレイアウト
解決策:
- 行の長さを検証
- 構造を正規化
- 欠損値を処理
2. テーブル検出の不備
一部の PDF は内部的にテーブルが適切に定義されていません。例えば、グリッド構造がない、またはセルサイズが不規則などです。
解決策:
- 複数のファイルでテスト
- フォールバック解析ロジックを使用
- 必要に応じて PDF を前処理
3. データクリーニングの問題
抽出されたデータには以下が含まれる可能性があります。
- 余分なスペース
- 改行
- 書式設定の問題
解決策:
- 空白をトリム
- 値を正規化
- 型を検証
4. 文字エンコーディングの問題(合字とフォント)
PDF テーブル抽出では、フォントエンコーディングと合字により予期しない文字が導入されることがあります。例えば、一般的な文字の組み合わせ:
fi、ff、ffi、ffl、ft、ti
は PDF で 単一のグリフ として保存されることがあります。抽出時、それらは次のように表示される可能性があります。
di\ue000erence → difference
o\ue002ce → office
\ue005le → file
これらは通常、カスタムフォントマッピングによって引き起こされる プライベート Unicode 文字(例:\ue000–\uf8ff)です。
解決策:
プライベート Unicode 文字(
\ue000–\uf8ff)を検出合字のマッピングテーブルを構築。例えば:
\ue000 → ff\ue001 → ft\ue002 → ffi\ue003 → ffl\ue004 → ti\ue005 → fi
データベースに挿入する前にテキストを正規化
オプションで、さらなる分析のために不明な文字をログに記録
エンコーディングの問題を適切に処理することで、データの正確性が確保され、下流の処理での微妙な破損を防ぐことができます。
5. ページをまたぐテーブルの断片化
PDF 内の大きなテーブルは、多くの場合、複数のページに分割されています。抽出時、各ページは別々のテーブルとして扱われる可能性があり、以下につながります。
- 分割されたデータセット
- 繰り返されるヘッダー
- 不完全なレコード
解決策:
- 連続するテーブル間の列数を比較
- ヘッダーの一貫性または最初の行のデータ型パターンを確認
- 構造とスキーマが一致する場合にテーブルをマージ
- データを連結する際に重複するヘッダー行をスキップ
実際には、列構造と値のパターン検出を組み合わせることで、ページをまたぐ完全なテーブルを再構築する信頼性の高い方法を提供します。
6. データベーススキーマの不一致
抽出されたデータとデータベース列間の不適切なマッピングはエラーを引き起こす可能性があります。
解決策:
- ヘッダーをスキーマに合わせる
- 明示的なフィールドマッピングを使用
7. 大規模ファイルのパフォーマンス問題
大きな PDF の処理は遅くなる可能性があります。
解決策:
- バッチ処理を使用
- 挿入操作を最適化
これらの問題を予測することで、より信頼性の高い PDF からデータベースへのワークフロー を構築できます。
結論
PDF をデータベースに変換することは単一の操作ではなく、データの抽出とデータベース保存のための処理(変換と挿入を含む)を含む構造化されたプロセスです。
テーブルデータに焦点を当て、Python を使用することで、完全な PDF からデータベースへのパイプライン を効率的に実装でき、データ統合タスクの自動化が容易になります。
このアプローチは、SQL Server や他のリレーショナルデータベースに保存する必要がある請求書、レポート、その他の構造化されたビジネス文書を処理する場合に特に役立ちます。
Spire.PDF for Python のパフォーマンスを評価し、制限を解除したい場合は、30 日間の無料トライアルを申請 できます。
よくある質問
「PDF からデータベース」とは何ですか?
PDF ファイルから構造化データを抽出し、データベースに保存するプロセスを指します。これには通常、PDF コンテンツの解析、構造化形式への変換、さらなるクエリと分析のために SQL データベースへの挿入が含まれます。
Python は PDF を直接データベースに変換できますか?
いいえ。Python は PDF をワンステップで直接データベースに変換することはできません。このプロセスには通常、最初に PDF からデータを抽出し、構造化レコードに変換し、SQL コネクタを使用してデータベースに挿入することが含まれます。
Python を使用して PDF を SQL に変換するにはどうすればよいですか?
典型的なワークフローには以下が含まれます。
- PDF からテーブルまたはテキストデータを抽出
- 構造化レコード(行と列)に変換
- Python データベースライブラリを使用して、SQLite、MySQL、SQL Server などの SQL データベースに処理済みデータを挿入
PDF ファイルを直接データベースに保存できますか?
はい。PDF ファイルはバイナリ(BLOB)データとしてデータベースに保存できます。ただし、このアプローチは主にドキュメントストレージシステムに使用され、構造化抽出はデータ分析とクエリに推奨されます。
PDF データ統合にはどの SQL データベースを使用できますか?
SQLite、SQL Server、MySQL、PostgreSQL を含む、ほぼすべての SQL データベースを使用できます。全体的な抽出と変換のプロセスは変わらず、データベース接続と挿入構文のみがわずかに異なります。





