
データベースクエリ結果を PDF にエクスポートすることは、レポート生成、データアーカイブ、ドキュメント作成などの一般的なユースケースにおける要件です。通常、SQL クエリ結果を構造的に明確で読みやすいドキュメントに変換し、後での共有、保存、または印刷に使用できるようにする必要があります。
データベース内のデータは通常テーブル形式で保存されているため、エクスポートプロセス中にその構造の完全性を維持することは、ドキュメントの明瞭さと可読性を確保するために不可欠です。適切なレイアウト制御がない場合、生成された PDF はすぐに乱雑になりやすく、特に大規模なデータセットを扱う際にはこの問題がより顕著になります。
本記事では、Spire.XLS for .NET を使用して C# でデータベースを PDF に変換する方法を実演します。クエリ結果の取得、構造化されたテーブルへの整理、そして最終的に書式設定された PDF ドキュメントへのエクスポートまでの完全な実装プロセスを含みます。
目次
1. データベースから PDF への変換の基本フロー
データベースコンテンツを PDF に変換するには、通常以下の主要なステップが含まれます:
- データ取得:SQL クエリを実行し、結果をメモリにロードする
- データの構造化:クエリ結果を整理し、統一されたテーブル形式に変換する
- PDF エクスポート:構造と可読性を保持した PDF ドキュメントを生成する
実際のアプリケーションでは、このフローは通常、レポート生成、請求書作成、クエリ結果のアーカイブなどのシナリオで使用され、その核心目標はデータを明確かつ構造化された方法で提示し、後での閲覧と使用を容易にすることです。
2. C# でデータベースを PDF に変換(ステップバイステップガイド)
本节では、データベースクエリ結果を PDF ドキュメントに変換する完全なワークフローを提供します。データ取得、テーブル構築、書式設定、エクスポートなどの工程をカバーします。
2.1 環境設定
ソリューションを実装する前に、開発環境が準備できていることを確認してください:
.NET 環境
Visual Studio をインストールするか、互換性のある .NET バージョン(.NET 6 以降など)を持つ .NET CLI を使用します。データベースアクセス
SQL Server データベース(または任意のリレーショナルデータベース)を準備し、有効な接続文字列を持っていることを確認します。最新の .NET アプリケーションでは、推奨される SQL クライアントライブラリを使用してください:dotnet add package Microsoft.Data.SqlClientこのパッケージは SQL Server の ADO.NET 実装を提供し、従来の
System.Data.SqlClientに取って代わります。Spire.XLS for .NET NuGet 経由で Spire.XLS をインストールして、テーブル書式設定と PDF エクスポートを処理します:
dotnet add package Spire.XLSまた、Spire.XLS for .NET パッケージをダウンロードして、プロジェクトに手動で追加することもできます。
設定が完了したら、データベースからデータを取得し、Spire.XLS を使用して PDF ドキュメントを生成およびエクスポートできます。
2.2 データベースからデータを読み取る
最初のステップは、SQL クエリを実行し、結果を DataTable にロードすることです。このデータ構造はクエリ結果のスキーマとデータ型を保持するため、後続の変換処理に適しています。
この例では、SQL クエリ内でフィールドに日本語のエイリアス(「注文番号」、「顧客名」など)を設定することで、エクスポートされたレポートが実際のビジネス閱讀習慣により適合するようにしています。この方法により、エクスポート段階で列名を別途処理する必要がなくなり、レポートの可読性と専門性が向上します。
using System.Data;
using Microsoft.Data.SqlClient;
string connectionString = "Server=localhost\\SQLEXPRESS;Database=SalesDB;User ID=demouser;Password=YourPassword;Encrypt=true;TrustServerCertificate=true;";
string query = @"
SELECT
o.OrderID AS 注文ID,
c.CustomerName AS 顧客名,
o.OrderDate AS 注文日,
o.TotalAmount AS 合計金額
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
WHERE YEAR(o.OrderDate) = 2026;
";
DataTable dataTable = new DataTable();
using (SqlConnection conn = new SqlConnection(connectionString))
{
SqlDataAdapter adapter = new SqlDataAdapter(query, conn);
adapter.Fill(dataTable);
}
この例では、.NET 用の現代的な SQL クライアントライブラリである Microsoft.Data.SqlClient を使用しており、従来の System.Data.SqlClient の代わりに使用することを推奨します。
SqlDataAdapter はデータベースとメモリデータ間のブリッジとして機能します。クエリの実行と DataTable への填充を担当し、讀み取り操作の接続を手動で管理する必要がありません。
実際の開発では、このステップを以下のように拡張できます:
- SQL インジェクションを防ぐためのパラメータ化クエリ
- 複雑なデータ取得のためのストアドプロシージャ
- SQL 内での直接的なデータフィルタリングと集計
この段階で清潔かつ構造化されたデータを準備することで、後続の書式処理の複雑さを低減し、全体的なパフォーマンスを向上させることができます。
データベースクエリ結果を Excel(PDF ではなく)にエクスポートする類似のシナリオについては、以下を参照してください:C# でデータベースを Excel にエクスポート。
2.3 データをインポートし、書式設定して PDF にエクスポート
データを取得した後、次のステップはそれをワークシートにマッピングし、書式を適用してから PDF ドキュメントにエクスポートすることです。ここでは、ワークシートベースのレイアウト制御を利用して、出力内容が構造化され可読性を維持するようにします。
using Spire.Xls;
using System.Drawing;
// ワークブックとワークシートを作成
Workbook workbook = new Workbook();
Worksheet sheet = workbook.Worksheets[0];
// ヘッダーを含む DataTable をインポート
sheet.InsertDataTable(dataTable, true, 1, 1);
// テーブルヘッダーの書式設定
CellRange headerRange = sheet.Range[1, 1, 1, dataTable.Columns.Count];
headerRange.Style.Font.IsBold = true;
headerRange.Style.Font.Size = 11;
headerRange.Style.Color = Color.LightGray;
// 罫線を適用してテーブル構造を強化
CellRange dataRange = sheet.AllocatedRange;
dataRange.BorderAround(LineStyleType.Thin);
dataRange.BorderInside(LineStyleType.Thin);
// 一貫性を保つために内容を整列
dataRange.Style.HorizontalAlignment = HorizontalAlignType.Center;
dataRange.Style.VerticalAlignment = VerticalAlignType.Center;
// グローバルフォントを適用
sheet.AllocatedRange.Style.Font.FontName = "MS Gothic";
// より良いレイアウトのために列幅を自動調整
sheet.AllocatedRange.AutoFitColumns();
// ページ内で内容を水平方向に中央揃え
sheet.PageSetup.CenterHorizontally = true;
// PDF にエクスポート
workbook.SaveToFile("SalesReport_2026.pdf", FileFormat.PDF);
このステップでは、レイアウト制御と PDF 生成を一つのワークフローに統合しています。
注意すべき重要なポイント:
ワークシートをレイアウトエンジンとして使用 ワークシートは構造化されたキャンバスとして機能し、データベースデータが行と列に配置されます。これにより、元のテーブル構造が最終ドキュメントで完全に保持されることが保証されます。
書式設定が PDF 出力効果に直接影響 列幅、フォントスタイル、罫線などの調整は単なる視覚的な美化ではありません——それらは PDF 内でのコンテンツのレンダリング効果を直接決定します。不適切な書式設定は、テキストの切り捨てや読みにくいレイアウトを引き起こす可能性があります。
自動ページ分割機能 エクスポート時、ワークシートの内容はレイアウトと用紙サイズに基づいて自動的にページ分割処理されます。これは大規模なデータセットを扱う際に特に有用です。
レイアウトをさらに最適化するには、以下の方法でテーブル書式を強化できます:
- 長いフィールドに対してテキスト折り返しを有効化
- 可読性を向上させるために数値/日付形式を適用
プロジェクトでより柔軟な PDF 構造制御が必要な場合は、Spire.PDF for .NET を使用してDataTable を直接 PDF に変換することも検討できます。これにより、複雑なレポート要件に対してより高度なドキュメントレベルの操作機能を提供します。
3. データベースを PDF に変換する完全な C# 例
以下は、データベース取得、データ書式設定、PDF エクスポートを単一のワークフローに統合した完全な実装コードです。
using System;
using System.Data;
using Microsoft.Data.SqlClient;
using Spire.Xls;
using System.Drawing;
class Program
{
static void Main()
{
// ステップ1:データベースからデータを取得
string connectionString = "Server=localhost\\SQLEXPRESS;Database=SalesDB;User ID=demouser;Password=YourPassword;Encrypt=true;TrustServerCertificate=true;";
string query = @"
SELECT
o.OrderID AS 注文ID,
c.CustomerName AS 顧客名,
o.OrderDate AS 注文日,
o.TotalAmount AS 合計金額
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
WHERE YEAR(o.OrderDate) = 2026;
";
DataTable dataTable = new DataTable();
using (SqlConnection conn = new SqlConnection(connectionString))
{
SqlDataAdapter adapter = new SqlDataAdapter(query, conn);
adapter.Fill(dataTable);
}
// ステップ2:ワークブックを作成しデータをインポート
Workbook workbook = new Workbook();
Worksheet sheet = workbook.Worksheets[0];
sheet.InsertDataTable(dataTable, true, 1, 1);
// ステップ3:プロフェッショナルな書式を適用
// テーブルヘッダーの書式設定
CellRange headerRange = sheet.Range[1, 1, 1, dataTable.Columns.Count];
headerRange.Style.Font.IsBold = true;
headerRange.Style.Font.Size = 11;
headerRange.Style.Color = Color.LightGray;
// 罫線を適用
CellRange dataRange = sheet.AllocatedRange;
dataRange.BorderAround(LineStyleType.Thin);
dataRange.BorderInside(LineStyleType.Thin);
// 整列方式を設定
dataRange.Style.HorizontalAlignment = HorizontalAlignType.Center;
dataRange.Style.VerticalAlignment = VerticalAlignType.Center;
// グローバルフォントを適用
sheet.AllocatedRange.Style.Font.FontName = "MS Gothic";
// 列幅を自動調整
sheet.AllocatedRange.AutoFitColumns();
// ページ内で内容を水平方向に中央揃え
sheet.PageSetup.CenterHorizontally = true;
// ステップ4:PDF にエクスポート
workbook.SaveToFile("SalesReport_2026.pdf", FileFormat.PDF);
Console.WriteLine("データベースクエリ結果が正常に PDF にエクスポートされました。");
}
}
生成された PDF のプレビューは以下の通りです:
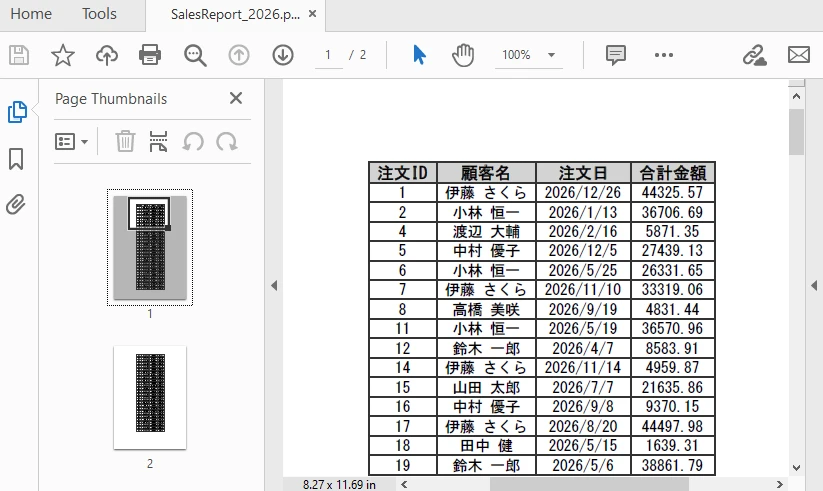
この例は、SQL クエリの実行から PDF 生成までの完全なワークフローを示しています。
4. 高度なシナリオ
実際のアプリケーションでは、データベースデータを PDF にエクスポートすることは基本的な変換だけでなく、バッチエクスポートの処理、ドキュメントの可読性向上、またはより良い表示効果を得るためのレイアウト設定の調整なども必要になる場合があります。以下の例は、実際の使用で一般的な強化機能を示しています。
複数のクエリ結果をエクスポート
バッチレポート生成や定時タスクなどのシナリオでは、複数のクエリを実行し、各クエリ結果を独立した PDF ドキュメントとしてエクスポートする必要がある場合があります:
string[] queries = {
"SELECT * FROM Orders WHERE Status = 'Pending'",
"SELECT * FROM Customers WHERE Region = 'North'"
};
for (int i = 0; i < queries.Length; i++)
{
DataTable dt = ExecuteQuery(queries[i]);
Workbook wb = new Workbook();
Worksheet ws = wb.Worksheets[0];
ws.InsertDataTable(dt, true, 1, 1);
ws.AllocatedRange.AutoFitColumns();
wb.SaveToFile($"Report_{i + 1}.pdf", FileFormat.PDF);
}
この方法は、複数のデータセットを独立してエクスポートする必要がある自動化レポート生成シナリオに適しています。
タイトルと追加情報を追加
可読性を向上させ、コンテキスト情報を提供するために、データをエクスポートする前にデータの上にタイトル行を追加できます:
// タイトル行を挿入
sheet.InsertRow(1);
sheet.Range[1, 1].Text = "販売レポート - 2026";
sheet.Range[1, 1].Style.Font.IsBold = true;
sheet.Range[1, 1].Style.Font.Size = 14;
// タイトルセルを結合
sheet.Range[1, 1, 1, dataTable.Columns.Count].Merge();
// タイトル行を自動調整
sheet.AutoFitRow(1);
以下の図は、タイトル行を適用後に生成された PDF を示しています:
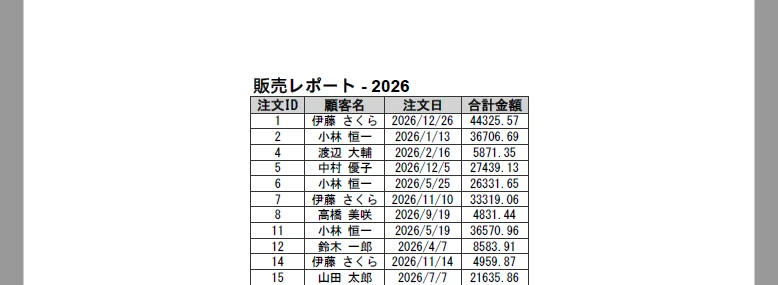
タイトルを追加することで、ユーザーはドキュメントの内容を迅速に理解でき、特にレポートを共有または印刷する際に非常に実用的です。
ページサイズ、向き、余白を設定
PDF レイアウトがデータに適切に適合するようにするために、エクスポート前にページサイズ、向き、余白を設定できます:
// ページサイズと向きを設定
sheet.PageSetup.PaperSize = PaperSizeType.PaperA4;
sheet.PageSetup.Orientation = PageOrientationType.Portrait;
// ページ余白を設定
sheet.PageSetup.TopMargin = 0.5f;
sheet.PageSetup.BottomMargin = 0.2f;
sheet.PageSetup.LeftMargin = 0.2f;
sheet.PageSetup.RightMargin = 0.2f;
これらの設定を調整することで、コンテンツの溢出を防ぎ、異なるレポート間でのレイアウトの一貫性を確保できます。
ページレイアウトとスケーリングを制御
大きなテーブルを扱う場合、コンテンツがページ間でどのように分布するかを制御する必要があるかもしれません。デフォルトでは、コンテンツは自動的にページ分割されますが、スケーリング動作を調整して、単一ページにより多くのデータを収容することもできます。
// コンテンツをページ幅に合わせる
workbook.ConverterSetting.SheetFitToWidth = true;
// 全体のワークシートを単一ページに合わせる(可読性が低下する可能性あり)
workbook.ConverterSetting.SheetFitToPage = true;
SheetFitToWidthはテーブル幅をページに合わせ、垂直方向のページ分割を許可しますSheetFitToPageは全体のワークシートを単一ページ内にスケーリングします
これらの設定はコンパクトなレポートを生成する際に有用ですが、文字が小さくなりすぎて読みにくくなるのを避けるために慎重に使用する必要があります。
ヘッダーとフッターを追加
ヘッダーとフッターは、レポートタイトル、生成日時、ページ番号などのコンテキスト情報を追加するために使用できます:
sheet.PageSetup.LeftHeader = "&\"MS Gothic,Bold\"&16 販売レポート - 2026";
sheet.PageSetup.RightHeader = "&\"MS Gothic,Italic\"&10 生成日:&D";
sheet.PageSetup.CenterFooter = "&\"MS Gothic,Regular\"&16 &P / &N ページ";
以下の図は、ヘッダーとフッターを適用後に生成された PDF を示しています:
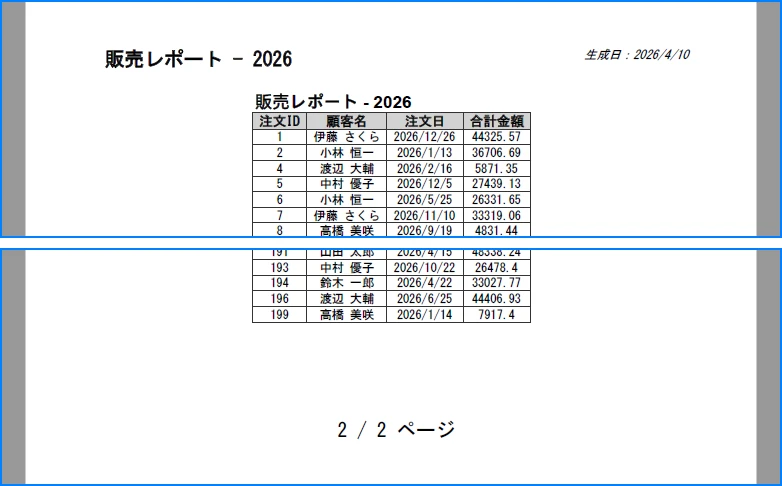
これらの要素はドキュメントのナビゲーション体験を向上させ、複数ページのレポートにとって特に価値があります。
PDFを暗号化
機密データを保護するために、エクスポートされた PDF に暗号化を適用できます:
workbook.ConverterSetting.PdfSecurity.Encrypt("openpsd");
暗号化機能は、承認されたユーザーのみがドキュメントにアクセスできるようにし、機密情報や重要なビジネスデータを含むレポートにとって重要です。
ドキュメントエクスポートと PDF カスタマイズに関する他の関連シナリオについては、C# での Excel から PDF への変換も探索できます。
5. よくある問題
データベース接続の問題
接続文字列が正しく、データベースサーバーが正常にアクセス可能であることを確認してください。認証設定(SQL 認証または統合セキュリティなど)を検証し、暗号化関連のパラメータが環境設定と一致していることを確認します。
空のクエリ結果
処理を続ける前に、DataTable にデータが含まれているかどうかを確認してください。空の結果セットは、空白の PDF 生成や予期しない書式問題を引き起こす可能性があります。
if (dataTable.Rows.Count == 0)
{
Console.WriteLine("指定されたクエリのデータが見つかりませんでした。");
return;
}
本番環境では、プログラムを直接終了するのではなく、プレースホルダー PDF を生成するか、エラーログを記録することを選択できます。
列幅の溢出
長いテキストフィールドを扱う場合、AutoFitColumns() は過度に広い列を生成し、PDF レイアウトに悪影響を与える可能性があります。
可読性を向上させるために、以下の方案を検討することをお勧めします:
- 最大列幅を設定
- 長いコンテンツに対してテキスト折り返しを有効化
- データ型に基づいて重要な列を手動で調整
これは可変長テキストを含む大規模なデータセットをエクスポートする際に特に重要です。
フォントサポートの欠如
エクスポートされた PDF に特殊文字(非ラテン文字など)やカスタムフォントが含まれる場合、必要なフォントがインストールされており、実行時にアクセス可能であることを確認してください。
フォントが欠如していると、テキストレンダリング異常や代替フォントの使用が発生し、ドキュメントの外観と可読性に影響を与えます。
予期しない PDF レイアウト
エクスポートされた PDF レイアウトが混雑しているか、スケーリングが不適切に見える場合、SheetFitToWidth や SheetFitToPage などのページ設定とスケーリングオプションを確認してください。
不適切なスケーリング設定は、コンテンツが小さすぎたり、元のテーブル構造が歪んだりする原因となります。
まとめ
本記事では、C# でデータベースクエリ結果を PDF に変換する実用的な方法を紹介しました。構造化されたデータ取得とワークシートベースの書式設定を組み合わせることで、SQL データから直接、明確でプロフェッショナルなドキュメントを生成できます。
この方法は、特にテーブル構造と可読性を維持する必要がある場合に、レポート生成とデータ提示シナリオで特に効果的です。
Spire.XLS の評価を行っている場合は、無料の一時ライセンスを申請して、開発プロセス中の評価制限を解除できます。
よくある質問
Spire.XLS はサードパーティツールを使用せずにデータベースデータを PDF にエクスポートできますか?
はい。Spire.XLS はすべての操作を独立して実行し、Microsoft Office や他の外部ツールを必要としません。
大規模なデータセットを PDF にエクスポートする際にはどのように対処すべきですか?
大規模なデータセットの場合、結果のページ分割処理を行うか、フィルタリングクエリを通じて必要なデータのみを取得することをお勧めします。さらに、PDF ページ設定を調整して出力ファイルサイズを最適化することもできます。
PDF ページレイアウトをカスタマイズできますか?
はい。Spire.XLS は、PDF にエクスポートする前にページ設定(向き、余白、用紙サイズなど)を構成することを許可します。
この方法は SQL Server 以外のデータベースにも適用できますか?
はい。この方法は、MySQL、PostgreSQL、Oracle など、ADO.NET データプロバイダーをサポートする任意のデータベースに適用できます。適切な接続クラスとデータアダプターを使用するだけです。
Microsoft.Data.SqlClient と System.Data.SqlClient のどちらを使用すべきですか?
最新の .NET アプリケーションでは、Microsoft.Data.SqlClient を使用することをお勧めします。このライブラリは継続的に更新・保守され、新しい SQL Server 機能に対するより良いサポートを提供します。一方、System.Data.SqlClient はレガシーライブラリと見なされ、主要な機能更新を受け取らなくなっています。





