
PDF ドキュメント内のテキストの検索と強調表示は、ドキュメントのレビュー、注釈付け、情報抽出に不可欠です。法務文書における重要な条項のマーキング、研究論文における主要な発見の強調、レポートにおける重要データの強調など、プログラム的にテキストを検索して視覚的な強調を適用することで、ドキュメントの可読性とワークフローの効率性を大幅に向上させることができます。
長大な PDF を手動で検索するのは時間がかかり、エラーが発生しやすい作業です。Python による自動化により、開発者は特定のテキストパターンを迅速に見つけ、ドキュメント全体または対象領域に視覚的な強調表示を適用できます。
本ガイドでは、Spire.PDF for Python を使用して PDF 内のテキストを検索・強調表示 する 3 つの強力なアプローチを紹介します。
- すべてのページで特定のテキストを検索・強調表示
- 定義されたページ領域内でテキストを検索・強調表示
- パターンベースのテキストマッチングに正規表現を使用
目次
- 前提条件
- 方法 1: 特定のテキストを検索・強調表示
- 方法 2: 指定した領域内のテキストを検索・強調表示
- 方法 3: 正規表現を使用したパターンマッチング (上級)
- 一般的な課題と解決策
- まとめ
- よくある質問
前提条件
開始する前に、以下を用意してください。
Python 3.x がインストールされていること
Spire.PDF for Python がインストールされていること:
pip install Spire.PDFまたは、Spire.PDF for Python パッケージをダウンロード して手動でインストールすることもできます。
テスト用のサンプル PDF ドキュメント
方法 1: 特定のテキストを検索・強調表示
最も一般的な使用例は、PDF ドキュメント全体で特定のテキストのすべての発生箇所を検索し、強調表示を適用することです。この方法は、キーワード、技術用語、重要なフレーズをマークするのに最適です。
コード例
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# PDF ドキュメントのすべてのページをループ処理
for i in range(pdf.Pages.Count):
# 現在のページを取得
page = pdf.Pages.get_Item(i)
# 特定のテキストのすべての発生箇所を検索 (大文字小文字を区別しない)
finder = PdfTextFinder(page)
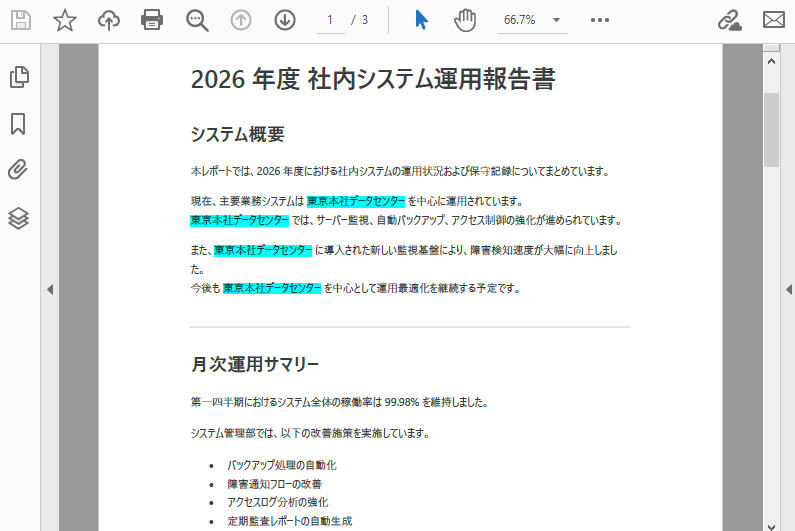
result = finder.Find("東京本社データセンター")
# 見つかったすべての箇所をシアン色で強調表示
for text in result:
text.HighLight(Color.get_Cyan())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlight.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
重要なポイント
LoadFromFile(): ソース PDF ドキュメントを読み込むPages.Count: ページの総数を返すPdfTextFinder: テキスト検索を実行するためのクラス- コンストラクタにページオブジェクトを渡して初期化
Find()メソッドで特定のテキストを検索
Find()の戻り値: 見つかったテキストインスタンスのコレクションを返すHighLight(): テキストに背景の強調表示色を適用
この方法を使用する場合
- 正確なキーワードやフレーズの検索
- ドキュメント全体で一貫した用語の強調表示
- 特定の製品名、日付、識別子のマーキング
- 契約書における特定の条項のレビュー
方法 2: 指定した領域内のテキストを検索・強調表示
場合によっては、ヘッダー、フッター、サイドバー、特定のセクションなど、ページの特定の領域内でのみ検索が必要なことがあります。Spire.PDF for Python は、RectangleF パラメータを受け取ることで、領域ベースのテキスト検索をサポートしています。
コード例
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 最初のページ (インデックス 0) を取得
pdfPageBase = pdf.Pages.get_Item(0)
# 矩形領域を定義 (x, y, 幅, 高さ)
# この例では、ページの上部 (高さ 240 ポイント) を検索
rctg = RectangleF(0.0, 0.0, pdfPageBase.ActualSize.Width, 240.0)
# PdfTextFindOptions を作成し、矩形領域を検索領域として設定
options = PdfTextFindOptions()
options.Area = rctg
# 「検索」オプションを使用してテキストを検索
finder = PdfTextFinder(pdfPageBase)
finder.Options = options
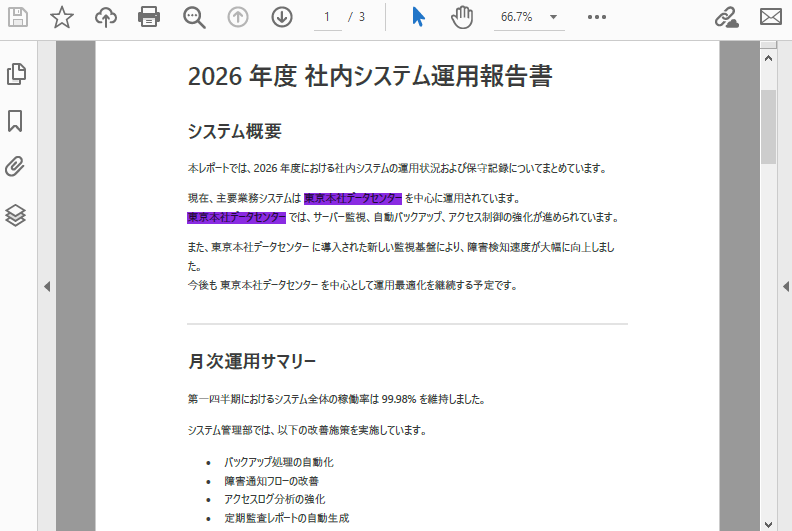
findCollection = finder.Find("東京本社データセンター")
# 見つかったすべてのテキストを青色でハイライト
for find in findCollection:
find.HighLight(Color.get_BlueViolet())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlightArea.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
実用的な使用例
- ヘッダーやフッターでドキュメントメタデータを検索
- サイドバーやコールアウトボックスから情報を抽出
- 要約、概要、結論などの特定のセクションに焦点を当てる
- 固定レイアウト構造を持つフォームの処理
方法 3: 正規表現を使用したパターンマッチング (上級)
強調表示が必要なテキストが完全一致ではなくパターンに従っている場合、正規表現は強力な柔軟性を提供します。たとえば、すべてのメールアドレス、電話番号、日付、特定の単語の組み合わせを強調表示したい場合があります。
コード例
from spire.pdf import *
from spire.pdf.common import *
# PdfDocument オブジェクトを作成し、PDF ドキュメントを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 正規表現パターンを定義
# この例では、アスタリスク (*) の後に続く 2 つの単語にマッチ
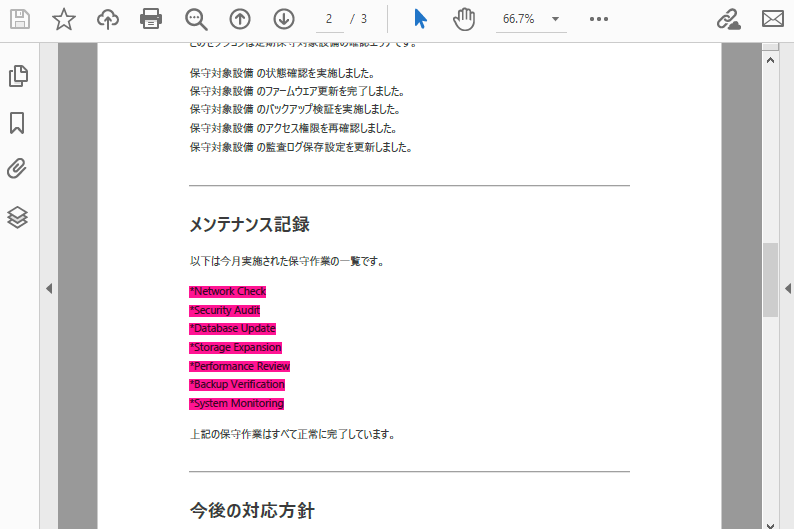
regex = "\\*(\\w+\\s+\\w+)"
# 2 番目のページ (インデックス 1) を取得
page = pdf.Pages.get_Item(1)
# 正規表現にマッチするテキストを検索 PdfTextFindOptions オブジェクトを作成し、正規表現を使用して検索するように設定
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.Regex
# 検索オプションを適用し、正規表現を使用してテキストを検索
finder = PdfTextFinder(page)
finder.Options = options
result = finder.Find(regex)
# マッチしたすべてのテキストをディープピンク色で強調表示
for text in result:
text.HighLight(Color.get_DeepPink())
# 変更後のドキュメントを保存
pdf.SaveToFile("output/FindHighlightRegex.pdf")
pdf.Close()
以下は、テキスト検索と強調表示の結果のスクリーンショットです。
正規表現を使用する場合
- 構造化データ (メール、日付、ID) の抽出
- テキストのバリエーションの検索 (異なる日付形式、名前のバリエーション)
- パターンベースの検証 (必須フィールドの確認)
- データマイニングおよび情報抽出タスク
一般的な課題と解決策
理論的には PDF でのテキスト検索と強調表示は簡単ですが、実際にはいくつかの課題が発生する可能性があります。
1. テキストが表示されているのに検出されない
問題: PDF ビューアーにはテキストが表示されているが、Find() が結果を返さない。
原因:
- テキストが画像としてレンダリングされている (スキャン文書)
- フォントエンコーディングの問題
- 非表示または重なり合うテキストレイヤー
解決策:
- スキャン文書には OCR を使用: Spire.OCR で画像からテキストを抽出
PdfTextFinderの検索オプションを確認- PDF ビューアーでテキストが選択可能か確認
2. 大きなドキュメントでのパフォーマンス問題
問題: 数百ページの検索が遅い。
解決策:
- 関連するページのみを検索対象に限定
- 領域ベースの検索を使用して検索空間を削減
- ページをバッチで処理
# 例: 特定のページのみを検索
target_pages = [0, 5, 10, 15] # ページインデックス
for i in target_pages:
page = pdf.Pages.get_Item(i)
# 検索を実行...
3. 特殊文字とエンコーディング
問題: 特殊文字、アクセント付き文字、非 ASCII 記号を含むテキストの検索が失敗する。
解決策:
- Unicode 対応の正規表現パターンを使用
- 検索前にテキストを正規化
- ドキュメントの実際の文字エンコーディングでテスト
# 例: アクセント付き文字にマッチ
pattern = r"café|naïve|résumé"
4. 大文字小文字の区別に関する問題
問題: 大文字小文字のバリエーションを見逃す。
解決策:
PdfTextFinderのオプションで大文字小文字を区別しない設定を使用- 正規表現では大文字小文字を区別しないフラグを使用
# 大文字小文字を区別しない検索の設定例
finder = PdfTextFinder(page)
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.IgnoreCase
finder.Options = options
result = finder.Find("keyword")
# 大文字小文字を区別しない正規表現
finder = PdfTextFinder(page)
options = PdfTextFindOptions()
options.Parameter = TextFindParameter.Regex
finder.Options = options
result = finder.Find(r"(?i)pattern")
まとめ
Spire.PDF を使用すれば、Python での PDF テキストの検索と強調表示は簡単です。完全一致、領域ベースのフィルタリング、正規表現パターンのいずれが必要でも、これらの方法でほとんどの使用例をカバーできます。
このプロセスを自動化することで、ドキュメントレビューを高速化し、データ抽出の効率性を向上させることができます。本番環境での使用では、スキャン済み PDF の処理とパフォーマンスの最適化を検討してください。
制限なしで Spire.PDF for Python を評価したい場合は、30 日間の無料トライアルを申請 できます。
よくある質問
Python で PDF のテキストを検索・強調表示するにはどうすればよいですか?
Spire.PDF for Python の PdfTextFinder クラスを使用してテキストを検索し、HighLight() メソッドで色の強調表示を追加します。PdfDocument.LoadFromFile() で PDF を読み込み、PdfTextFinder でページを検索し、SaveToFile() で結果を保存します。
PDF で正規表現を使用してテキストを検索できますか?
はい。PdfTextFindOptions の Parameter プロパティに TextFindParameter.Regex を設定し、PdfTextFinder.Find() メソッドに正規表現パターンを渡します。これにより、メール、日付、電話番号、その他の構造化データのパターンベースのマッチングが可能になります。
PDF ページの特定の領域内でのみテキストを検索するにはどうすればよいですか?
必要な座標と寸法で RectangleF オブジェクトを定義し、PdfTextFindOptions の Area プロパティに設定します。その後、このオプションを PdfTextFinder に適用して検索を実行します。これにより、指定した矩形領域に検索が制限されます。
すべてのページを自動的に検索することは可能ですか?
はい。pdf.Pages.Count をループ処理し、各ページで PdfTextFinder を使用して検索を実行します。本ガイドの例では、複数ページの検索を示しています。
パスワード保護された PDF でも機能しますか?
はい。パスワードを指定してパスワード保護された PDF を読み込みます。
pdf.LoadFromFile("protected.pdf", "your_password")
その後、通常の検索と強調表示操作を進めます。





