PDF ファイルの分割は、ドキュメント処理のワークフローにおいて一般的な要件です。個々のページを抽出したり、章ごとに分けたり、大きなドキュメントを扱いやすいサイズに分割したりする場合でも、Python を使えば効率的に自動化できます。
本チュートリアルでは、Python を使って PDF ファイルを分割する方法を解説します:
ここでは、シンプルで分かりやすい API でPDF操作を行える強力なライブラリである Spire.PDF for Python を使用します。
PDF 分割に使用する Python ライブラリ
Spire.PDF for Python を使う理由
Spire.PDF for Python は、多機能なライブラリで、以下のような操作が可能です:
- PDF の分割・結合・圧縮
- テキストや画像の抽出
- 注釈や透かしの追加 など
ドキュメント処理ツールや自動化スクリプトを開発するエンジニアに特に適しています。
インストール方法
以下のコマンドでインストールできます:
pip install spire.pdf
インストールが完了すれば、すぐに PDF 分割を始められます。
PDF をページ単位の複数ファイルに分割する
PDF を1ページ単位で分割するのは、最も一般的な処理のひとつです。以下のような場合に適しています:
- 個別ページを共有または保存する
- 各ページを個別に処理する(例:OCR や形式変換)
- 大きなPDF を小さく扱いやすいファイルに分割する
Spire.PDF for Python を使えば、最小限のコードで簡単にページ単位の PDF に分割できます。
サンプルコード
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDFファイルを読み込む
doc.LoadFromFile("Input.pdf")
# PDF をページ単位のファイルに分割
# 第2引数は出力ファイル名の{0}の開始インデックスを指定
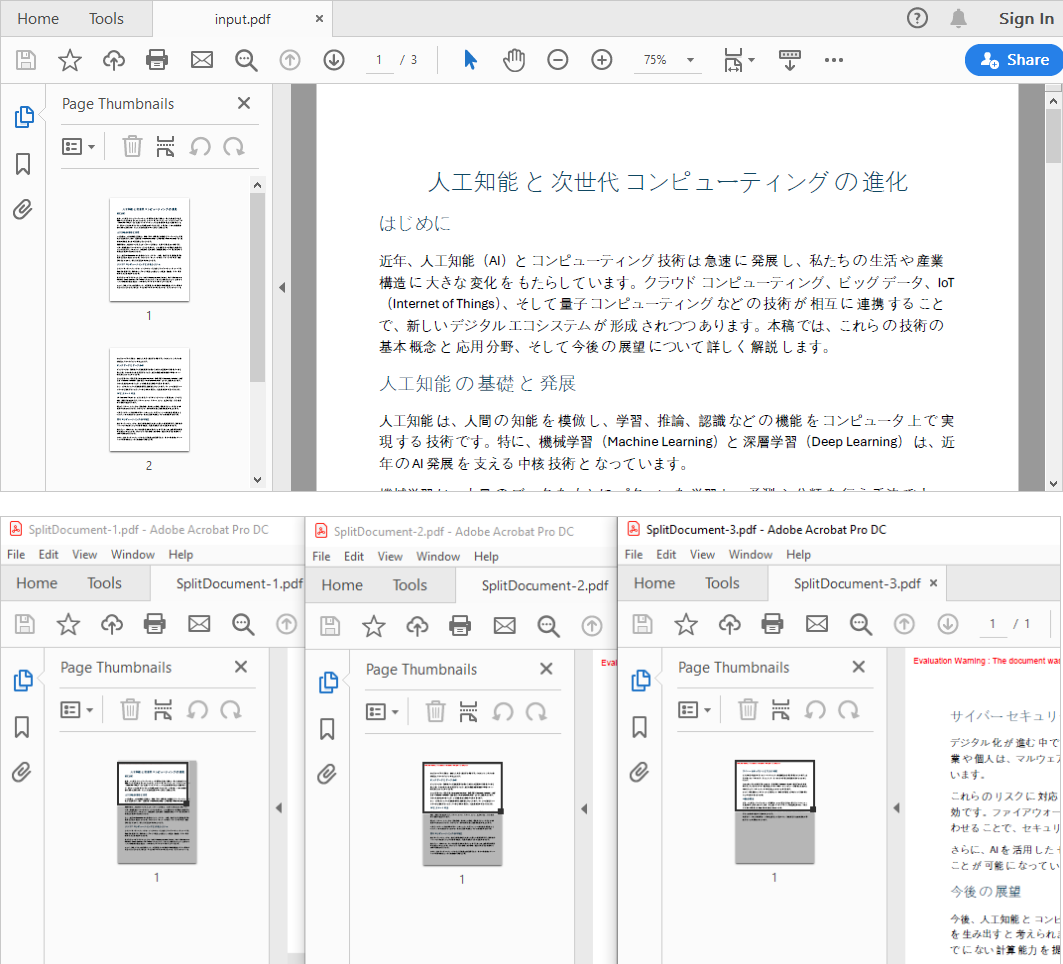
doc.Split("Output/SplitDocument-{0}.pdf", 1)
# PdfDocument を閉じる
doc.Close()
仕組み
Split("Output/SplitDocument-{0}.pdf", 1):
- PDF をページ単位に分割し、ページごとに1ファイルを生成
- {0} は出力ファイル名内でページ番号に置き換えられるプレースホルダー
- 1 は番号付けを1から開始することを意味する
使用シーン
この方法は以下に最適です:
- 1ページ=1ファイルの PDF を素早く生成したい場合
- 大量ファイルの一括分割を自動化する場合
- 後続処理のためにページ単位のドキュメントが必要な場合
PDF をページ単位に分解する最もシンプルかつ高速な方法です。
ページ範囲で PDF を分割する
実務では、PDF を単純に1ページずつ分割するだけでは不十分な場合も多くあります。章やレポート、関連データなど、意味のある単位で分割したいケースです。このような場合に、ページ範囲による分割が有効です。
Spire.PDF for Python を使えば、どのページをどの出力ファイルに含めるかを細かく制御できます。
サンプルコード
from spire.pdf.common import *
from spire.pdf import *
# PdfDocument オブジェクトを作成
doc = PdfDocument()
# PDF ファイルを読み込む
doc.LoadFromFile("Input.pdf")
# 新しい PdfDocument オブジェクトを2つ作成
newDoc_1 = PdfDocument()
newDoc_2 = PdfDocument()
# 元ファイルの1ページ目を最初のドキュメントに挿入
newDoc_1.InsertPage(doc, 0)
# 残りのページを2つ目のドキュメントに挿入
newDoc_2.InsertPageRange(doc, 1, doc.Pages.Count - 1)
# ファイルを保存
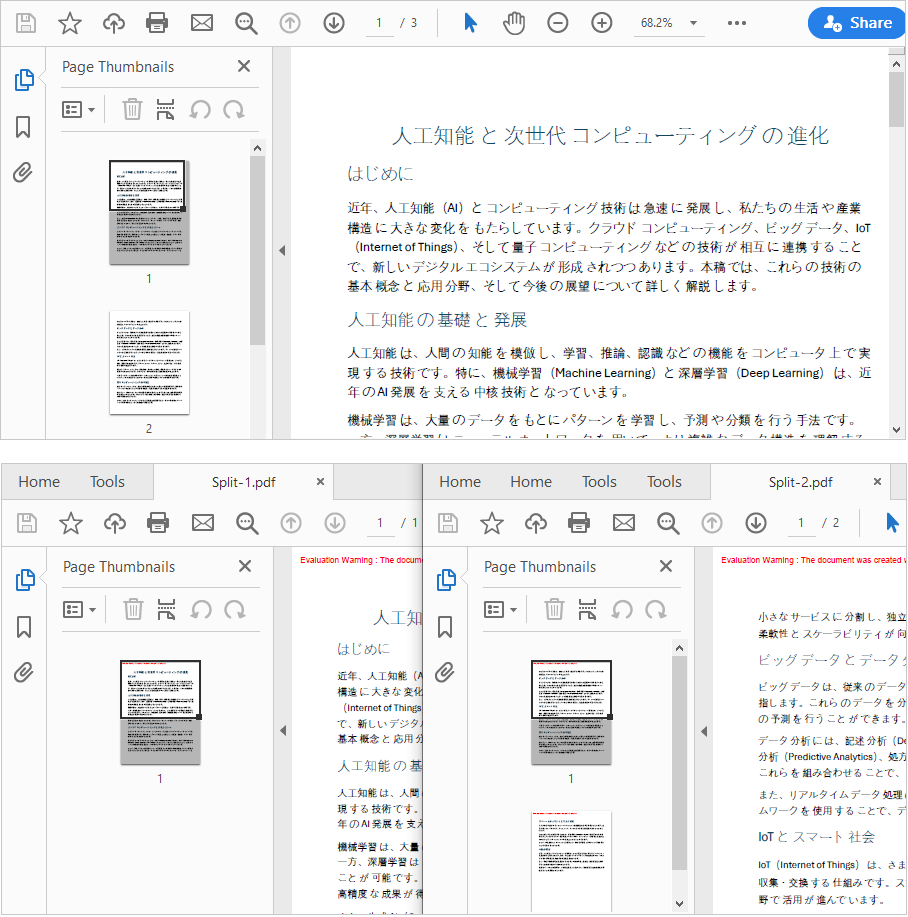
newDoc_1.SaveToFile("Output/Split-1.pdf")
newDoc_2.SaveToFile("Output/Split-2.pdf")
# PdfDocument を閉じる
doc.Close()
newDoc_1.Close()
newDoc_2.Close()
仕組み
- InsertPage(doc, 0) → 単一ページ(インデックスは0から開始) を抽出
- InsertPageRange(doc, 1, doc.Pages.Count - 1) → 残りすべてのページを抽出
この方法により、柔軟にカスタム分割が可能になります。
この方法のメリット
- 論理構造(章・セクション)に基づいた分割が可能
- ユーザー入力やメタデータに応じた動的な範囲指定
- 以下のような業務用途に最適:
- 複数請求書が含まれる PDF の分割
- レポートの特定セクションの抽出
- 後続処理のためのページグルーピング
1ページ分割と比べてコード量は増えますが、より高い柔軟性を得られます。
まとめ
Spire.PDF for Python を使えば、Python での PDF 分割はシンプルかつ柔軟に実現できます。
- スピードとシンプルさを重視するなら、Split() メソッドで ページ単位に分割
- 精度やカスタマイズ性を重視するなら、InsertPage() と InsertPageRange() で ページ範囲を自由に指定
実際のアプリケーションでは、これら2つの方法を組み合わせて使用するケースも多くあります。例えば、まずドキュメントをセクションごとに分割し、その後さらにページ単位に分解するといった使い方です。
これらの手法をワークフローに組み込むことで、効率的でスケーラブルな PDF 処理システムを構築できます。
よくある質問(FAQ)
1. 任意のページグループ(例:3ページごと)で分割できますか?
はい。ループ処理と InsertPageRange() を組み合わせることで、任意のページ単位でグループ化できます。
2. 大きなPDFファイルにも対応していますか?
はい。大規模な PDF にも対応していますが、処理性能はシステムリソースに依存します。
3. パスワード付き PDF も分割できますか?
はい。ただし、操作前に正しいパスワードでドキュメントを読み込む必要があります。
4. このライブラリは無料ですか?
Spire.PDF for Python には一部制限付きの無料版があります。すべての機能を利用するには商用ライセンスが必要です。
一時ライセンスを申請する
評価メッセージの削除や機能制限の解除をご希望の場合は、営業担当者までお問い合わせのうえ、30日間有効な一時ライセンスを取得してください。





