
Web コンテンツやドキュメントを扱う際、Python で HTML を解析する能力は、さまざまな分野の開発者にとって不可欠なスキルです。HTML 解析とは、HTML ドキュメントから必要な情報を抽出し、コンテンツを操作し、Web データを効率的に処理することを指します。Web スクレイピング、データ抽出、コンテンツ分析、ドキュメント処理など、どのような用途でも、Python での HTML 解析を習得することで、開発効率と処理能力を大幅に向上させることができます。
本記事では、Spire.Doc for Python を使用して HTML を効率的に解析する方法を紹介します。HTML 文字列・ローカル HTML ファイル・Web URL から HTML を読み込む実践的な方法と、HTML 解析のベストプラクティスについて解説します。
- Python で HTML を解析する理由
- はじめに:Python 用 HTML 解析ライブラリをインストールする
- Spire.Doc による HTML 解析の仕組み
- HTML 解析のベストプラクティス
- まとめ
Python で HTML を解析する理由
HTML(HyperText Markup Language)は Web の基盤であり、Web コンテンツの構造化と表示に使用されます。HTML を解析することで、次のような処理が可能になります。
- Web ページやローカルファイルから特定のデータ(テキスト、画像、表、ハイパーリンクなど)を抽出する。
- コンテンツ構造を分析し、キーワードや傾向を把握する。
- 調査、レポート、コンテンツ管理のためのデータ収集を自動化する。
- 整理されていない HTML をクリーンアップして構造化データへ変換する。
BeautifulSoup のようなライブラリが軽量な解析に優れている一方で、Spire.Doc for Python は、HTML 解析とドキュメント作成や変換を統合する必要がある場合に真価を発揮します。構造化されたドキュメントオブジェクトモデル (DOM) として HTML コンテンツを解析し、操作するための堅牢なフレームワークを提供します。
はじめに:Python 用 HTML 解析ライブラリをインストールする
HTML 解析を始める前に、Spire.Doc for Python をインストールする必要があります。PyPI から簡単にインストールできます。
pip install Spire.Doc
このコマンドにより、最新バージョンのライブラリと依存関係がインストールされます。インストール後、すぐに HTML 解析を開始できます。
Spire.Doc による HTML 解析の仕組み
Spire.Doc は、HTML のタグベース構造を階層型ドキュメントモデルへ変換することで HTML を解析します。このモデルは、セクション・段落・その他の要素を表すオブジェクトで構成されており、元の HTML 構造を再現します。
それでは、実際のコードで確認してみましょう。
1. Python で HTML 文字列を解析する
API レスポンスやユーザー入力など、小さな HTML スニペットを扱う場合は、文字列から直接 HTML を解析できます。テスト用途や短い静的 HTML の処理に最適です。
from spire.doc import *
from spire.doc.common import *
# HTMLコンテンツを文字列として定義
html_string = """
<html>
<head>
<title>サンプルページ</title>
</head>
<body>
<h1>ようこそ</h1>
<p>これは<strong>HTML解析</strong>のデモです。</p>
<ul>
<li>機能1:文字列の読み取り</li>
<li>機能2:ファイルの読み取り</li>
<li>機能3:URLの読み取り</li>
</ul>
</body>
</html>
"""
# 新しいDocumentオブジェクトを初期化
doc = Document()
# ドキュメントにセクションと段落を追加
section = doc.AddSection()
paragraph = section.AddParagraph()
# 文字列からHTMLコンテンツを読み込む
paragraph.AppendHTML(html_string)
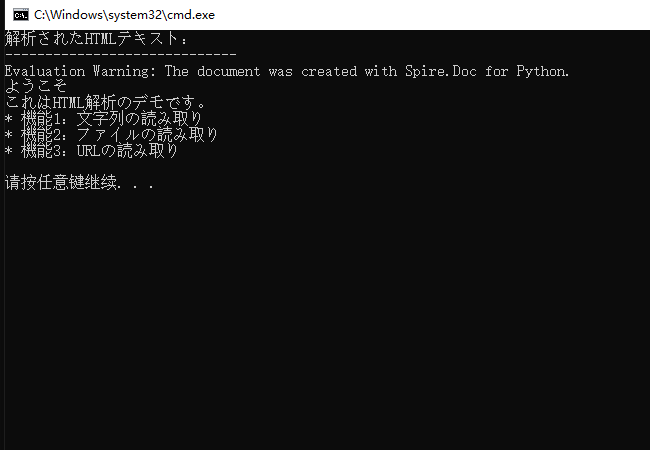
print("解析されたHTMLテキスト:")
print("-----------------------------")
# 解析されたHTMLからテキストコンテンツを抽出
parsed_text = doc.GetText()
# 結果を表示
print(parsed_text)
# ドキュメントを閉じる
doc.Close()
動作の仕組み:
- HTML 文字列:見出し、段落、リストなどを含む HTML スニペットを定義しています。
- ドキュメント構造:Spire.Doc は、Word のような構造(セクション→段落)で HTML を整理します。
- HTML 解析:AppendHTML() が文字列を構造化されたWord要素に変換します(例:
<h1>は「見出し1」スタイルに、<ul>はリストになります)。 - テキスト抽出:GetText() を使用すると、HTML タグを除いたプレーンテキストを取得できます。
出力結果:
また、Spire.Doc は SaveToFile() メソッドを使用して、解析した HTML を PDF や Word 形式などへエクスポートすることも可能です。
2. Python で HTML ファイルを解析する
ローカル HTML ファイルの場合、Spire.Doc を使えば 1 つのメソッドで読み込みと解析を行えます。ダウンロードした Web ページや静的レポートなど、オフラインコンテンツの処理に便利です。
from spire.doc import *
from spire.doc.common import *
# ローカルHTMLファイルへのパスを定義
html_file_path = "example.html"
# Documentインスタンスを作成
doc = Document()
# HTMLファイルを読み込み、解析
doc.LoadFromFile(html_file_path, FileFormat.Html)
# ドキュメント構造を分析
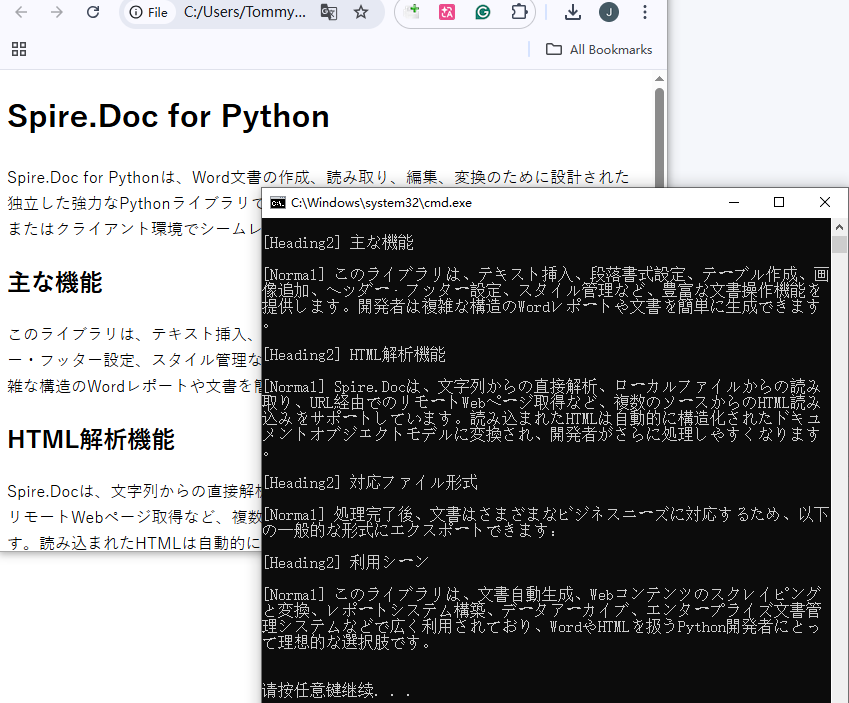
print(f"ドキュメントには{doc.Sections.Count}個のセクションがあります")
print("-"*40)
# 各セクションを処理
for section_idx in range(doc.Sections.Count):
section = doc.Sections.get_Item(section_idx)
print(f"セクション {section_idx + 1}")
print(f"セクションには{section.Body.Paragraphs.Count}個の段落があります")
print("-"*40)
# 現在のセクション内の段落を走査
for para_idx in range(section.Paragraphs.Count):
para = section.Paragraphs.get_Item(para_idx)
# 段落スタイル名とテキストコンテンツを取得
style_name = para.StyleName
para_text = para.Text
# コンテンツが存在する場合に段落情報を表示
if para_text.strip():
print(f"[{style_name}] {para_text}\n")
# セクション間に間隔を追加
print()
# ドキュメントを閉じる
doc.Close()
主な機能:
- ローカルファイルの読み込み:LoadFromFile() は HTML ファイルを読み込み、自動的に Word 構造へ変換します。
- ドキュメント構造の分析:セクション数・段落数・スタイル情報を確認でき、コンテンツ監査に役立ちます。
- スタイルによる分類:「見出し」や「リスト段落」などのスタイルを利用して、コンテンツを整理できます。
出力結果:
HTML を Document オブジェクトへ読み込んだ後は、テキストやハイパーリンクなどの要素も抽出できます。
3. Python で URL を解析する
Web ページを直接解析する場合は、まず requests ライブラリで HTML を取得し、その HTML を Spire.Doc に渡して解析します。これは Web スクレイピングやリアルタイムデータ抽出の基本的な方法です。
Requests ライブラリをインストール:
pip install requests
Web ページ解析用 Python コード:
from spire.doc import *
from spire.doc.common import *
import requests
# URLからHTMLコンテンツを取得
def fetch_html_from_url(url):
"""URLからHTMLを取得し、エラー(404、ネットワーク問題など)を処理する"""
# User-Agentでブラウザを模倣する(Webサイトによるブロックを回避)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # HTTPエラーに対して例外を発生させる
return response.text # 生のHTMLコンテンツを返す
except requests.exceptions.RequestException as e:
raise Exception(f"HTMLの取得エラー: {str(e)}")
# 対象URLを指定
url = "https://jp.e-iceblue.com/misc/privacy-policy.html"
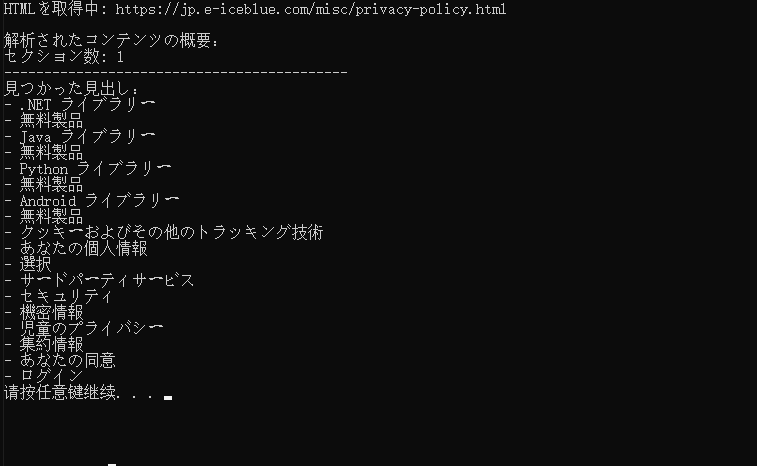
print(f"HTMLを取得中: {url}")
# HTMLコンテンツを取得
html_content = fetch_html_from_url(url)
# ドキュメントを作成し、HTMLコンテンツを挿入
doc = Document()
section = doc.AddSection()
paragraph = section.AddParagraph()
paragraph.AppendHTML(html_content)
# 概要情報を抽出して表示
print("\n解析されたコンテンツの概要:")
print(f"セクション数: {doc.Sections.Count}")
print("-------------------------------------------")
# 見出しを抽出して表示
print("見つかった見出し:")
for para_idx in range(section.Paragraphs.Count):
para = section.Paragraphs.get_Item(para_idx)
if isinstance(para, Paragraph) and para.StyleName.startswith("Heading"):
print(f"- {para.Text.strip()}")
# ドキュメントを閉じる
doc.Close()
手順の説明:
- HTML を取得:requests.get() を使って URL から HTML を取得します。
- HTML を解析:取得した HTML 文字列を Spire.Doc へ渡します。
- コンテンツを抽出:見出しなどの情報を抽出し、SEO 監査やコンテンツ集約に活用できます。
出力結果:
HTML 解析のベストプラクティス
Spire.Doc を使った HTML 解析を最適化するために、以下のポイントを意識しましょう。
- 入力ソースを検証:解析前に HTML ファイルや文字列が存在し、破損していないか確認します。
import os
html_file = "data.html"
if os.path.exists(html_file):
doc.LoadFromFile(html_file, FileFormat.Html)
else:
print(f"エラー: ファイル '{html_file}' が見つかりません。")
- 例外処理:ファイル不足や無効な HTML などのエラーに備えて、try-except を使用します。
try:
doc.LoadFromFile("sample.html", FileFormat.Html)
except Exception as e:
print(f"HTMLの読み込みエラー: {e}")
大きなファイルの最適化:大きな HTML ファイルの場合、パフォーマンスを向上させるために、コンテンツをチャンクで読み込むか、必須でない解析機能を無効にすることを検討してください。
抽出データのクリーニング:strip() や replace() を使って不要な空白や文字を削除します。
ライブラリを最新に保つ:pip install --upgrade Spire.Doc で Spire.Doc を定期的に更新し、改善された解析ロジックとバグ修正の恩恵を受けてください。
まとめ
Python により、あらゆるスキルレベルの開発者が HTML 解析にアクセスできるようになります。HTML 文字列、ローカルファイル、Web URL のいずれを扱う場合でも、Requests(HTML 取得)と Spire.Doc(構造化解析)を組み合わせることで、Web スクレイピングやコンテンツ抽出をシンプルに実現できます。
本記事のサンプルコードとベストプラクティスを活用すれば、非構造化 HTML を数分で整理された実用的なデータへ変換できるようになります。
Spire.Doc for Python の全機能を試したい場合は、30 日間の試用ライセンスを申請してください。





