
C# で HTML を効率的に解析することは、Web スクレイピング、データ抽出、コンテンツ自動化など、多くの開発シーンで求められる一般的な要件です。.NET には標準的なツール(例:HtmlAgilityPack)も存在しますが、Spire.Doc for .NET を使用すると、直感的なオブジェクトモデルとシームレスな統合により、C# での HTML 解析をより簡単に実現できます。
本記事では、Spire.Doc for .NET を使用して HTML を解析する方法について解説します。HTML の読み込み方法、ドキュメント構造の操作、重要なデータの抽出までを段階的に紹介します。
Spire.Doc のセットアップ
C# 用 HTML パーサーライブラリをプロジェクトへ追加する最も簡単な方法は、NuGet を利用することです。
- Visual Studio でプロジェクトを開きます。
- ソリューションエクスプローラーでプロジェクトを右クリック → NuGet パッケージの管理 を選択します。
- NuGet パッケージマネージャーで Spire.Doc を検索します。
- 最新の安定版を選択し、インストールをクリックします。
または、E-iceblue の公式サイトからライブラリを直接ダウンロードし、ZIP ファイルを展開後、Spire.Doc.dll を参照追加することも可能です。
Spire.Doc による HTML 解析の仕組み
Spire.Doc は HTML を構造化されたオブジェクトモデルへ変換します。たとえば、<p>、<a>、<table> などの HTML 要素は、それぞれ対応するクラスとしてマッピングされ、C# コードから直接アクセスできます。
主な構成要素は以下の通りです。
- Document:解析された HTML コンテンツのコンテナとして機能します。
- Section:コンテンツのブロックを表します(HTML の
<body>や<div>セクションに類似)。 - Paragraph:
<p>、<h1>、<li>などのブロック要素に対応します。 - DocumentObject:Paragraph 内に含まれるすべての要素(画像、リンクなど)の基底クラス。
このモデルにより、HTML 構造を維持したまま、直感的な C# のプロパティやメソッドを使って操作できます。
HTML コンテンツを読み込み・解析する方法
Spire.Doc は、文字列、ローカルファイル、さらにはリモート URL からの HTML 解析をサポートしています(HTTP クライアントと組み合わせた場合)。
以下では、それぞれのケースを詳しく解説します。
C# で HTML 文字列を解析
Web API やデータベースから取得した HTML 文字列を、Spire.Doc のオブジェクトモデルへ変換して解析します。
using Spire.Doc;
using Spire.Doc.Documents;
namespace ParseHtmlString
{
class Program
{
static void Main(string[] args)
{
// Document オブジェクトを作成
Document doc = new Document();
// セクションを追加
Section section = doc.AddSection();
// 段落を追加
Paragraph para = section.AddParagraph();
// 解析する HTML
string htmlContent = @"
<h2>HTML文字列のサンプル</h2>
<p>これは<strong>太字テキスト</strong>と<a href='https://www.e-iceblue.com/'>リンク</a>を含む段落です。</p>
<ul>
<li>リスト項目1:Word文書作成</li>
<li>リスト項目2:HTML変換対応</li>
</ul>
";
// HTML を段落へ追加
para.AppendHTML(htmlContent);
// 段落テキストを出力
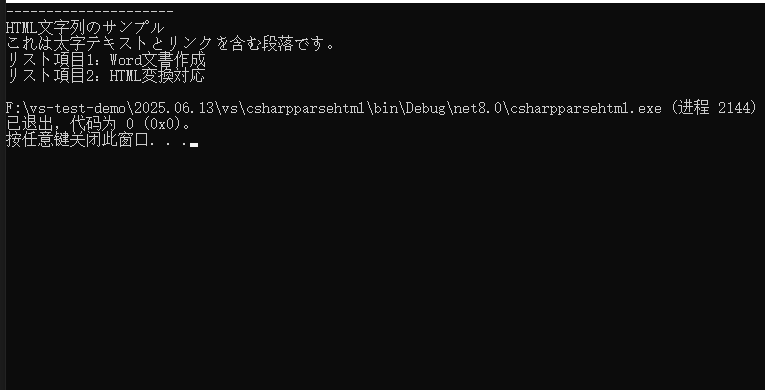
Console.WriteLine("Parsed HTML Content:");
Console.WriteLine("---------------------");
foreach (Paragraph paragraph in section.Paragraphs)
{
Console.WriteLine(paragraph.Text);
}
}
}
}
このコードでは、AppendHTML() メソッドによって HTML タグが自動的に対応する Spire.Doc オブジェクトへ変換されます(例:<h1> → Heading1 スタイル、<ul> → リスト段落)。
出力結果:
プロのヒント:SaveToFile() メソッドを使用すれば、HTML を Word に変換することも可能です。
C# で HTML ファイルを解析
ファイルに保存された HTML コンテンツ(ダウンロードした Web ページや静的な HTML レポートなど)の場合、LoadFromFile() で読み込み、その構造を分析します(見出しや段落の抽出など)。
using Spire.Doc;
using Spire.Doc.Documents;
namespace ParseHtmlFile
{
class Program
{
static void Main(string[] args)
{
// Document オブジェクトを作成
Document doc = new Document();
// HTML ファイルを読み込み
doc.LoadFromFile("sample.html", FileFormat.Html);
// セクションを走査
foreach (Section section in doc.Sections)
{
Console.WriteLine($"Section {doc.Sections.IndexOf(section) + 1}:");
Console.WriteLine("---------------------------------");
// 段落を走査
foreach (Paragraph para in section.Paragraphs)
{
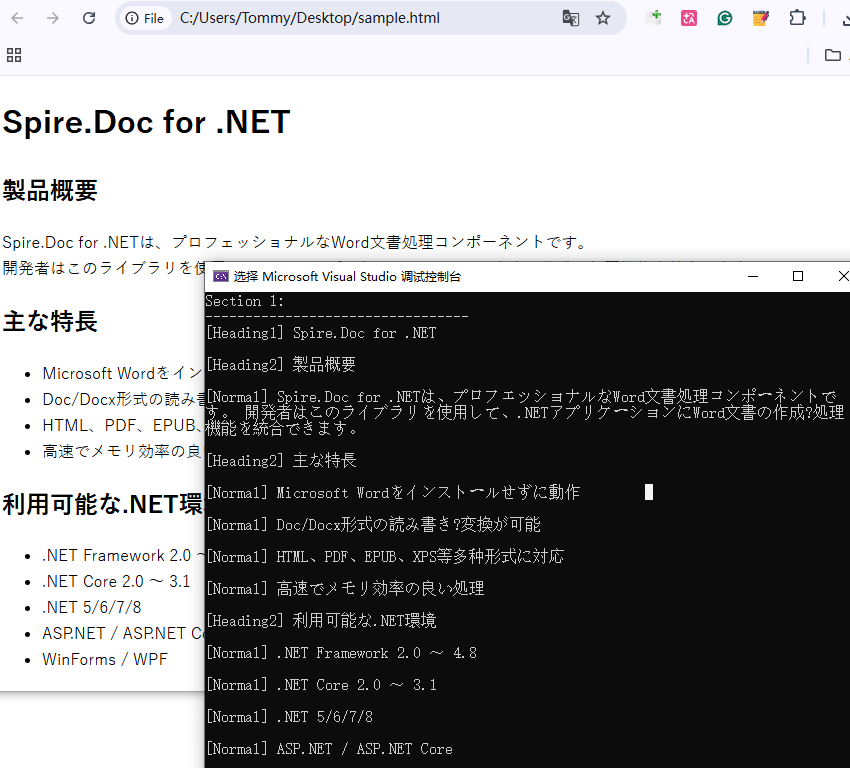
// スタイル名とテキストを表示
string styleName = para.StyleName;
Console.WriteLine($"[{styleName}] {para.Text}" + "\n");
}
Console.WriteLine();
}
}
}
}
この例では、Paragraph.StyleName と Paragraph.Text を利用して、スタイル情報付きで HTML コンテンツを取得しています。
出力結果:
Spire.Doc のオブジェクトモデルを使用すると、Word 文書と同じように HTML ファイルを操作できます。テキストコンテンツの抽出に加えて、リンクやテーブルなどの要素を HTML から抽出することも可能です。
C# で URL を解析
Web ページから HTML を解析するには、Spire.Doc と HttpClient を組み合わせて、まず HTML コンテンツを取得し、それを解析します。
using Spire.Doc;
using Spire.Doc.Documents;
namespace HtmlUrlParsing
{
class Program
{
// HttpClient インスタンス
private static readonly HttpClient httpClient = new HttpClient();
static async Task Main(string[] args)
{
try
{
// URL から HTML を取得
string url = "https://jp.e-iceblue.com/misc/privacy-policy.html";
Console.WriteLine($"Fetching HTML from: {url}");
string htmlContent = await FetchHtmlFromUrl(url);
// HTML を解析
Document doc = new Document();
Section section = doc.AddSection();
Paragraph paragraph = section.AddParagraph();
paragraph.AppendHTML(htmlContent);
// 情報を抽出
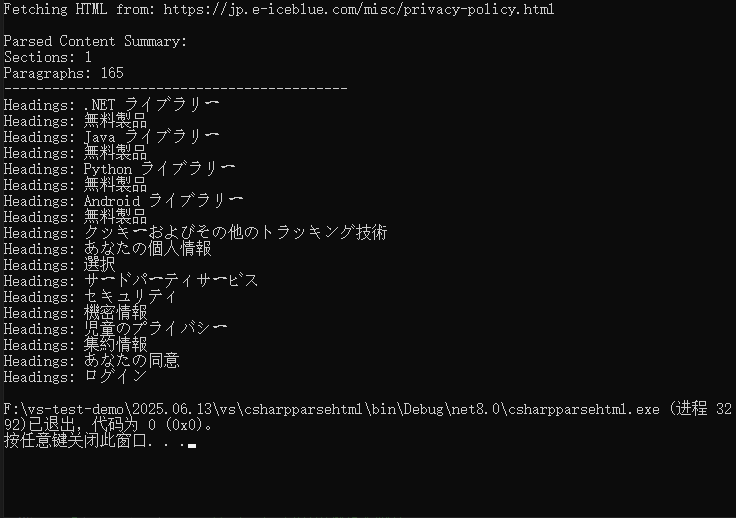
Console.WriteLine("\nParsed Content Summary:");
Console.WriteLine($"Sections: {doc.Sections.Count}");
Console.WriteLine($"Paragraphs: {section.Paragraphs.Count}");
Console.WriteLine("-------------------------------------------");
// 見出しを抽出
foreach (Paragraph para in section.Paragraphs)
{
if (para.StyleName.StartsWith("Heading"))
{
string headings = para.Text;
Console.WriteLine($"Headings: {headings}");
}
}
}
catch (Exception ex)
{
Console.WriteLine($"Error: {ex.Message}");
}
}
// URL から HTML を取得
private static async Task<string> FetchHtmlFromUrl(string url)
{
// User-Agent を設定
httpClient.DefaultRequestHeaders.UserAgent.ParseAdd(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64)");
// GET リクエスト送信
HttpResponseMessage response =
await httpClient.GetAsync(url);
// HTTP エラー時は例外
response.EnsureSuccessStatusCode();
return await response.Content.ReadAsStringAsync();
}
}
}
このコードでは、Web スクレイピング(HTML の取得)とドキュメント解析(Spire.Doc)を組み合わせて、見出しなどの構造化データを抽出しています。コンテンツ分析や Web データ抽出に役立ちます。
出力結果:
まとめ
Spire.Doc for .NET は、C# アプリケーションで HTML を読み取るための包括的なソリューションを提供します。HTML 文字列、ローカルファイル、さらには Web URL を扱う場合でも、このライブラリは直感的な API と信頼性の高いパフォーマンスでプロセスを効率化します。このガイドで概説した例に従うことで、HTML 解析機能を .NET プロジェクトに効率的に統合できます。
Spire.Doc for .NET の機能を完全に体験するには、こちらから 30 日間の無料トライアルライセンスをリクエストしてください。
よくある質問
Q1:HtmlAgilityPack ではなく Spire.Doc を使う理由は?
A:Spire.Doc と HtmlAgilityPack は主な目的が異なるため、選択はニーズによって異なります。
- HtmlAgilityPack:生の HTML の解析と操作(タグの抽出、無効な HTML の修正など)のみに特化した軽量ライブラリです。文書の書式設定や Word へのエクスポートは処理しません。
- Spire.Doc:文書操作を主目的として設計されており、HTML を解析し、構造化された Word 要素(セクション、段落、見出し/太字などのスタイル)に直接マッピングします。これは、次のような場合に重要です:
- HTML 構造を保持したまま Word 化したい
- 見出しなどのスタイル情報を取得したい
- HTML を PDF / TXT / RTF へ変換したい
Q2:C# で HTML をテキストへ変換する方法は?
A:GetText() メソッドを利用して HTML からテキストを取得し、.txt ファイルへ保存できます。
// Document オブジェクトを作成
Document doc = new Document();
// HTML ファイルを読み込み
doc.LoadFromFile("sample.html", FileFormat.Html);
// テキストを取得
string text = doc.GetText();
// テキストファイルへ保存
File.WriteAllText("HTMLText.txt", text);
Q3:Spire.Doc は不完全な HTML に対応できますか?
A:はい。Spire.Doc は十分なエラー耐性を持っており、不完全な HTML もある程度処理できます。ただし、著しく不正な形式の HTML は解析の問題を引き起こす可能性があります。最良の結果を得るには、HTML が適切な形式であることを確認するか、Spire.Doc で解析する前に HTML サニタイゼーションライブラリを使用してください。
Q4:Spire.Doc は ASP.NET Core アプリケーションで使用できますか?
A:はい。Spire.Doc は ASP.NET Core と完全互換です。インストール方法や使用手順は、通常の .NET アプリケーションと同じです。





