
URL から PDF ファイルをプログラムでダウンロードする機能は、 ドキュメント処理システム 、 Web スクレイパー 、 コンテンツアグリゲーター 、自動レポート生成ツール を構築する開発者にとって非常に重要です。PDF のダウンロードと処理を自動化することで、手動操作なしで情報抽出、ドキュメントのアーカイブ、分析などを実行でき、ワークフロー効率を向上できます。
本ガイドでは、Spire.PDF を使用して Python で URL から PDF をダウンロードする方法を紹介します。また、完全なメモリ内処理、ネットワークエラー処理、大容量ファイル管理、一般的な問題のトラブルシューティングについても解説します。
クイックナビゲーション:
- Python 用 Spire.PDF を使用する理由
- 必要なライブラリのインストール
- URL から PDF をダウンロード
- 保存せずに PDF を処理
- 大容量 PDF の処理
- リトライ処理の追加
- よくある問題とトラブルシューティング
- まとめ
- FAQ
1. Python 用 Spire.PDF を使用する理由
Spire.PDF for Python は、ディスクパスを必要とせずに メモリから直接 PDF を読み込む ことを可能にします。これにより、メモリ内処理が高速化され、不要なディスク I/O を回避できます。
主な機能:
- バイトストリームから PDF を読み込み
- テキスト、画像、メタデータを抽出
- PDF を編集し、他の形式へ変換
- 大容量ファイルをメモリ内で効率的に処理
これらの機能は、 Web スクレイピングパイプライン 、 ドキュメントアーカイブシステム 、 自動レポート生成 、コンテンツ抽出ワークフロー など、パフォーマンスとメモリ効率が重要な場面で特に役立ちます。
2. 必要なライブラリのインストール
pip を使用して Spire.PDF と requests をインストールします:
pip install spire.pdf requests
必要なモジュールをインポートします:
from spire.pdf import *
import requests
3. URL から PDF をダウンロード
以下は、URL から PDF をダウンロードし、メモリ内で処理してディスクへ保存する完全なサンプルです。理解しやすいよう、各処理に説明を付けています。
import requests
from spire.pdf import *
def download_pdf_from_url():
# PDF の URL を指定
url = "https://example.com/sample.pdf"
# HTTP GET リクエストを送信して PDF をダウンロード
response = requests.get(url)
# リクエスト失敗時(4xx または 5xx)は例外を発生
response.raise_for_status()
# ダウンロードした bytes から Stream オブジェクトを作成
stream = Stream(response.content)
# Stream から PDF を読み込み
document = PdfDocument(stream)
# PDF をローカルファイルとして保存
document.SaveToFile("Downloaded.pdf")
document.Close()
print("PDF downloaded and saved successfully!")
if __name__ == "__main__":
download_pdf_from_url()
出力結果:
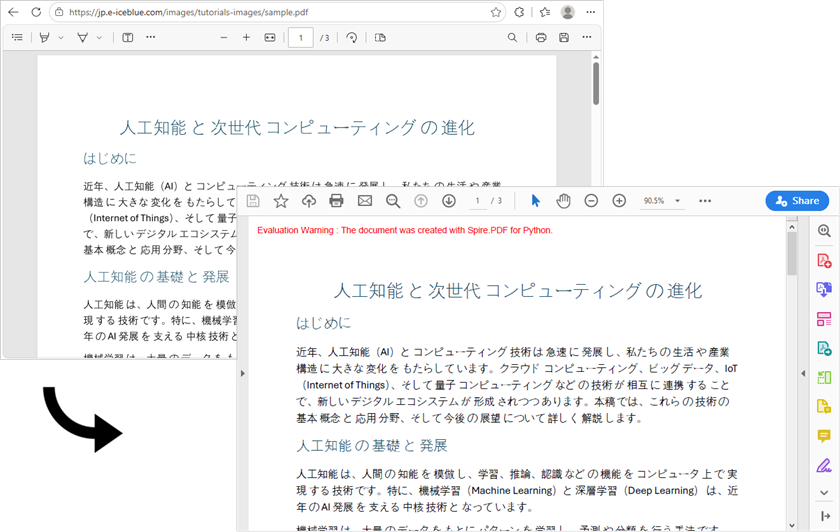
主要コンポーネントの説明:
requests.get(url)– HTTP GET リクエストを送信します。サーバーはヘッダーと PDF バイナリを返します。response.raise_for_status()– HTTP エラー(例:404、500)をチェックします。response.content– 生の PDF bytes を保持します。Stream(response.content)– bytes を読み取り可能・シーク可能なメモリ内ストリームとしてラップします。PdfDocument(stream)– PDF をメモリに読み込み、後続処理を可能にします。document.SaveToFile()– PDF をディスクへ保存します。
このワークフローでは、PDF データをメモリ内に読み込んで即座に保存するため、高速で不要なディスク書き込みを回避できます。
4. 保存せずに PDF を処理
ファイルを書き込まずに、メモリ内で直接メタデータやテキストを抽出できます:
from spire.pdf import PdfTextExtractor
def process_pdf_from_url():
url = "https://example.com/sample.pdf"
response = requests.get(url)
response.raise_for_status()
# PDF をメモリ内で読み込み
document = PdfDocument(Stream(response.content))
# ドキュメント情報を取得
print(f"ページ数: {document.Pages.Count}")
info = document.DocumentInformation
print(f"タイトル: {info.Title}")
print(f"作成者: {info.Author}")
# 1ページ目からテキストを抽出
extractor = PdfTextExtractor(document.Pages[0])
text = extractor.ExtractText()
print(f"先頭100文字: {text[:100]}")
document.Close()
if __name__ == "__main__":
process_pdf_from_url()
この方法の利点: ディスク上に不要なファイルを作成することなく、コンテンツ分析、テキストインデックス作成、または メタデータ抽出を行えます。これは サーバーサイドスクリプト 、 クラウド関数 、バッチ処理 に最適です。
5. 大容量 PDF の処理
非常に大きな PDF(例:100MB 以上)をダウンロードすると、大量のメモリを消費する可能性があります。ストリーミングダウンロード と一時ファイルを使用することで、メモリ使用量を削減できます。
import tempfile
import os
def download_large_pdf(url: str, output_path: str):
try:
response = requests.get(url, stream=True, timeout=60)
response.raise_for_status()
# チャンク単位で一時ファイルへ書き込み
with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
tmp.write(chunk)
temp_path = tmp.name
# 一時ファイルから PDF を読み込み
document = PdfDocument()
document.LoadFromFile(temp_path)
document.SaveToFile(output_path)
document.Close()
# 一時ファイルを削除
os.unlink(temp_path)
print(f"Large PDF saved to: {output_path}")
except Exception as e:
print(f"Error: {e}")
ポイント:
stream=Trueにより、ファイル全体をメモリへ読み込むことを防ぎます。- 一時ファイルを利用することで、RAM を超えるサイズの PDF も処理できます。
6. リトライ処理の追加
ネットワークリクエストは一時的に失敗することがあります。リトライ処理を追加することで、安定性を向上できます。
import time
def download_with_retry(url: str, output_path: str, max_retries: int = 3):
for attempt in range(max_retries):
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
document = PdfDocument(Stream(response.content))
document.SaveToFile(output_path)
document.Close()
print(f"Downloaded successfully: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Retrying in {wait_time} seconds...")
time.sleep(wait_time)
print("All retry attempts failed.")
return False
なぜ必要か: 指数バックオフによりサーバーへの負荷を防ぎ、一時的なネットワーク障害にも適切に対応できます。
7. よくある問題とトラブルシューティング
PDF が見つからない(404)
問題: URL が有効な PDF を指しておらず、404 エラーになる。
解決方法: URL を確認し、必要に応じて User-Agent ヘッダーを追加します。
import requests
url = "https://example.com/missing.pdf"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 404:
print("PDF not found (404)")
サーバーが PDF ではなく HTML を返す
問題: URL が PDF ではなく HTML ページを返す。
解決方法: Content-Type を確認し、HTML を解析して実際の PDF リンクを取得します。
import requests
from bs4 import BeautifulSoup
url = "https://example.com/download-page"
response = requests.get(url)
content_type = response.headers.get('Content-Type', '')
if 'application/pdf' not in content_type and 'text/html' in content_type:
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a', href=True):
if link['href'].endswith('.pdf'):
print(f"Found PDF link: {link['href']}")
# 実際の PDF URL をダウンロード
抽出したテキストが文字化けする
問題: テキスト抽出結果が読めない文字になる。主にエンコーディング問題やスキャン PDF が原因。
解決方法: 適切な処理を行うか、スキャン PDF には OCR を使用します。
from spire.pdf import PdfDocument, PdfTextExtractor
document = PdfDocument("example.pdf")
extractor = PdfTextExtractor(document.Pages[0])
text = extractor.ExtractText()
print(text[:200])
# 文字化けが続く場合、画像ベース PDF の可能性があるため OCR を検討
PDF は読み込めるがページが存在しない
問題: ファイルは存在するのに document.Pages.Count が 0 を返す。
解決方法: PDF が破損しているか、パスワード保護されている可能性があります。
from spire.pdf import PdfDocument, Stream
with open("protected.pdf", "rb") as f:
pdf_bytes = f.read()
# パスワード保護された PDF の場合
document = PdfDocument(Stream(pdf_bytes), "password")
print(f"Pages: {document.Pages.Count}")
8. まとめ
本記事では、Spire.PDF for Python を使用して Python で URL から PDF ファイルをダウンロードする方法を紹介しました。Stream クラスを活用することで、不要なディスク I/O を行わずに PDF データを直接メモリへ読み込み、効率的なドキュメント処理パイプラインを構築できます。
また、requests ライブラリによる PDF ダウンロード、bytes からの Stream 作成、PdfDocument の読み込み、ネットワークエラー処理、大容量ファイル管理、一般的な問題のトラブルシューティングまで、一連のワークフローを解説しました。これらの実践的なコード例は、堅牢な PDF ダウンロード・処理システムを構築するための基盤となります。
Spire.PDF for Python の機能を評価制限なしで体験したい場合は、30 日間無料トライアルライセンス を申請できます。
9. FAQ
Q1. Python で URL から PDF をダウンロードするには?
requests ライブラリで PDF データを取得し、Spire.PDF を使用してメモリから読み込みます。
response = requests.get(url)
stream = Stream(response.content)
document = PdfDocument(stream)
Q2. 認証付き PDF を処理するには?
Basic 認証の場合は auth パラメータを使用します。
response = requests.get(url, auth=('username', 'password'))
トークン認証の場合はヘッダーを追加します。
headers = {'Authorization': 'Bearer YOUR_TOKEN'}
response = requests.get(url, headers=headers)
Q3. ダウンロード可能な PDF の最大サイズは?
理論上の上限はシステムの利用可能メモリに依存します。200MB を超えるファイルでは、すべてをメモリに読み込む代わりに、一時ファイルを使用したストリーミング方式を推奨します。
Q4. 複数の PDF を並列でダウンロードできますか?
はい。concurrent.futures や asyncio を使用することで、複数の PDF を同時にダウンロードし、パフォーマンスを向上できます。
from concurrent.futures import ThreadPoolExecutor
urls = ["url1.pdf", "url2.pdf", "url3.pdf"]
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_pdf, urls)





