
Python を使用して HTML を Markdown に変換することは、Web コンテンツ、ドキュメント、または API データを管理する開発者にとって一般的なタスクです。HTML は強力なレイアウトや構造化機能を提供しますが、タグが冗長になりやすく、技術文書や静的サイト生成などの用途では保守が難しくなることがあります。対照的に、Markdown は軽量で可読性が高く、GitHub、GitLab、Jekyll、Hugo などのプラットフォームと高い互換性があります。
Python で HTML から Markdown への変換を自動化することで、ワークフローが合理化され、エラーが減少し、一貫した出力が保証されます。このガイドでは、HTML ファイルや文字列の変換から複数ファイルのバッチ処理、正確な Markdown 結果を保証するためのベストプラクティスまですべてを網羅しています。
- HTML を Markdown に変換する理由
- Python 向け HTML→Markdown ライブラリのインストール
- Python で HTML ファイルを Markdown に変換する
- Python で HTML 文字列を Markdown に変換する
- 複数 HTML ファイルの一括変換
- HTML→Markdown 変換のベストプラクティス
- まとめ
- よくある質問
HTML を Markdown に変換する理由
コードを見ていく前に、多くの開発ワークフローで生の HTML より Markdown が好まれる理由を確認しておきましょう。
- シンプルで読みやすい:Markdown は冗長な HTML タグよりも読みやすく、編集しやすいです。
- ツール間の高い互換性:Markdown は、GitHub、GitLab、Bitbucket、Obsidian、Notion、さらに Hugo や Jekyll などの静的サイトジェネレーターで広くサポートされています。
- バージョン管理に適している:プレーンテキストであるため、Markdown は Git での変更追跡、diff のレビュー、共同作業を容易にします。
- コンテンツ作成の高速化:Markdown の記述は、HTML タグ構造を覚えるよりも迅速です。
- 静的サイトジェネレーターとの統合:人気のフレームワークは、主要なコンテンツ形式として Markdown に依存しています。HTML から変換することで、スムーズな移行が保証されます。
- ドキュメント管理がクリーンになる:多くのドキュメントシステムや Wiki は、Markdown を標準フォーマットとして採用しています。
要するに、HTML を Markdown に変換することで、保守性が向上し、煩雑さが軽減され、現代の開発ワークフローにシームレスに適合します。
Python 向け HTML→Markdown ライブラリのインストール
Python で HTML コンテンツを Markdown に変換する前に、両方のフォーマットを効果的に処理できるライブラリが必要です。Spire.Doc for Python は、見出し、リスト、画像、リンクをそのまま保持しながら、HTML ファイルや HTML 文字列を Markdown に変換できる信頼性の高い選択肢です。
pip を使用して PyPI からインストールできます。
pip install spire.doc
インストール後、Python スクリプトで HTML から Markdown への変換を自動化できます。同じライブラリは、より幅広いシナリオもサポートしています。たとえば、編集可能なドキュメントが必要な場合は、HTML→Word 変換機能を使用して Web ページを Word ファイルに変換できます。また、配布やアーカイブには、標準化されたプラットフォームに依存しないドキュメントを生成するために、HTML→PDF 変換が特に役立ちます。
Python で HTML ファイルを Markdown に変換する
最も一般的なユースケースの一つは、既存の .html ファイルを .md ファイルに変換することです。これは、古い Web サイト、技術ドキュメント、ブログ投稿を、静的サイトジェネレーター(Jekyll、Hugo)や Git ベースのドキュメントプラットフォーム(GitHub、GitLab、Read the Docs)などの Markdown ベースのワークフローに移行する場合に特に便利です。
手順
- 新しい Document インスタンスを作成します。
- LoadFromFile() を使用してHTMLファイルを読み込む。
- SaveToFile() と FileFormat.Markdown を使って Markdown として保存。
- ドキュメントを閉じてリソースを解放します。
コード例
from spire.doc import *
# Document インスタンスを作成
doc = Document()
# HTML ファイルを読み込む
doc.LoadFromFile("input.html", FileFormat.Html)
# Markdown ファイルとして保存
doc.SaveToFile("output.md", FileFormat.Markdown)
# ドキュメントを閉じる
doc.Close()
これにより、input.html が output.md に変換され、見出し、段落、リスト、リンク、画像などの構造要素が保持されます。
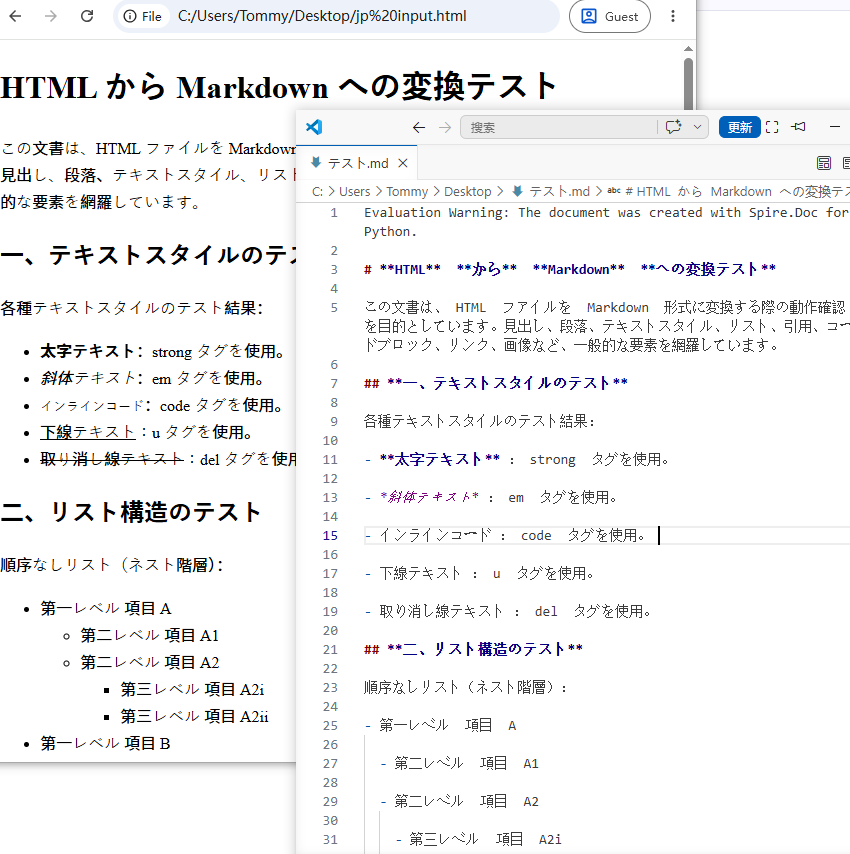
Python で HTML 文字列を Markdown に変換する
場合によっては、HTML コンテンツがファイルではなく動的に生成されることがあります。たとえば、API から Web コンテンツを取得したり、スクレイピングしたりする場合です。このようなシナリオでは、一時的な HTML ファイルを作成することなく、文字列から直接変換できます。
手順
- 新しい Document インスタンスを作成します。
- ドキュメントに Section を追加します。
- セクションに Paragraph を追加します。
- AppendHTML() を使用して段落に HTML 文字列を追加します。
- SaveToFile() を使用してドキュメントを Markdown ファイルとして保存します。
- ドキュメントを閉じてリソースを解放します。
コード例
from spire.doc import *
# HTML 文字列
html_content = """
<h1>HTML 文字列の変換テスト</h1>
<p>このテストは、<strong>HTML 文字列</strong>を直接 <em>Markdown</em> に変換する動作を確認します。</p>
<ul>
<li><code>インラインコード</code> に対応</li>
<li><a href="https://example.com">ハイパーリンク</a> に対応</li>
</ul>
"""
# Document インスタンスを作成
doc = Document()
# Section を追加
section = doc.AddSection()
# 段落を追加して HTML 文字列を挿入
paragraph = section.AddParagraph()
paragraph.AppendHTML(html_content)
# Markdown として保存
doc.SaveToFile("string_output.md", FileFormat.Markdown)
# ドキュメントを閉じる
doc.Close()
生成される Markdown は次のようになります。
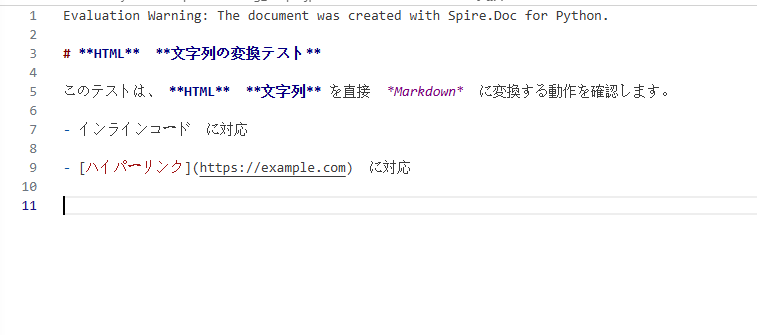
複数 HTML ファイルの一括変換
大規模なプロジェクトでは、複数の .html ファイルを一括変換する必要がある場合があります。シンプルなループでプロセスを自動化できます。
import os
from spire.doc import *
# HTML ファイルの入力フォルダ
input_folder = "html_files"
# Markdown 出力フォルダ
output_folder = "markdown_files"
# 出力フォルダが存在しない場合は作成
os.makedirs(output_folder, exist_ok=True)
# 入力フォルダ内の全ファイルを処理
for filename in os.listdir(input_folder):
# .html ファイルのみ処理
if filename.endswith(".html"):
# Document オブジェクトを作成
doc = Document()
# HTML ファイルを読み込む
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Html)
# 出力ファイルパスを生成
output_file = os.path.join(output_folder, filename.replace(".html", ".md"))
# Markdown ファイルとして保存
doc.SaveToFile(output_file, FileFormat.Markdown)
# リソース解放
doc.Close()
このスクリプトは、html_files/ 内のすべての .html ファイルを処理し、Markdown の結果を markdown_files/ に保存します。
HTML→Markdown 変換のベストプラクティス
HTML を Markdown に変換することで、コンテンツが読みやすく、管理しやすく、バージョン管理しやすくなります。正確でクリーンな変換を保証するために、以下のベストプラクティスに従ってください。
- 変換前に HTML を検証する:HTML が適切に構造化されていることを確認します。無効なタグは、不完全または壊れた Markdown 出力を引き起こす可能性があります。
- Markdown の制限を理解する:Markdown は、高度な CSS スタイリングやカスタム HTML タグをサポートしていません。一部のフォーマットが失われる可能性があります。
- 文字エンコーディングに注意する:特殊文字の問題を防ぐために、特定のエンコーディング(UTF-8 など)でファイルを開いて保存します。
- バッチ処理:複数のファイルを変換する場合は、エラー処理(try-except ブロック)、ログ記録を含み、問題のあるファイルでプロセス全体が停止するのではなく、スキップする堅牢なスクリプトを作成します。
まとめ
Python で HTML を Markdown に変換することは、ドキュメントパイプラインの処理、Web コンテンツの移行、または API からのデータ処理を行う開発者にとって貴重なスキルです。Spire.Doc for Python を使用すると、次のことが可能です。
- 個々の HTML ファイルを簡単に Markdown に変換する。
- HTML 文字列を直接 .md ファイルに変換する。
- バッチ変換を自動化し、大規模なプロジェクトを効率的に管理する。
これらの方法を活用することで、ワークフローを効率化し、コンテンツをよりクリーンで保守しやすい状態に保てます。
よくある質問
Q1: Python で Markdown を HTML に戻すことはできますか?
A: はい、Spire.Doc は Markdown から HTML への変換をサポートしており、これらのフォーマット間のシームレスな移行を可能にします。
Q2: 変換ではテーブルのような複雑な HTML 要素も保持されますか?
A: Spire.Doc は標準的な HTML 要素を効果的に処理しますが、テーブルやネストされた要素などの複雑なレイアウトについては、正確な変換結果を保証するために確認することをお勧めします。
Q3: 複数の HTML ファイルのバッチ変換を自動化できますか?
A: もちろんです。Python のスクリプトを使用してバッチ変換を自動化し、複数の HTML ファイルを一度に効率的に処理できます。
Q4: Spire.Doc は無料で使用できますか?
A: Spire.Doc は無料版と商用版の両方を提供しており、開発者は基本的な機能を無料で利用するか、ライセンスによって高度な機能を利用するかの柔軟性を得られます。





