XML は構造化データを保存するために広く利用されている形式ですが、分析や Excel のような表形式ツールで扱うには必ずしも最適ではありません。XML を CSV に変換することで、データをよりシンプルでフラットな形式に整理でき、スプレッドシートやデータ分析ライブラリとの互換性が向上します。
XML を CSV に変換すれば、データを簡単に Excel にインポートしたり、計算を実行したり、Pandas などの Python データ分析ツールに渡したりできます。
また、このアプローチは、複雑な階層データを、さまざまなアプリケーション間で読み取り、操作、共有しやすい形式に標準化するのにも役立ちます。このチュートリアルでは、Spire.XLS for Python を使用して XML ファイルを効率的に CSV に変換する方法を探ります。
- Spire.XLS for Python のセットアップ
- XML データ構造の理解
- XMLデータの抽出と変換方法
- 基本例:Python で XML を CSV に変換する
- 応用テクニック
- トラブルシューティングとよくある問題
- まとめ
- FAQs
Spire.XLS for Python のセットアップ
まずは Spire.XLS ライブラリをインストールします。このパッケージは PyPI で公開されているため、以下のコマンドで簡単にインストールできます。
pip install spire.xls
インストール後、必要なクラスをインポートします。
from spire.xls import *
from spire.xls.common import *
Spire.XLS は、Excel ライクなファイルを管理するための Workbook オブジェクトと Worksheet オブジェクトを提供します。これらを使用して CSV ファイルを作成し、XML データを書き込みます。
XML データ構造の理解
XML ファイルはツリー状の階層構造で構成されており、要素(ノード)はタグで囲まれています。各要素にはテキスト、属性、または子要素を含めることができます。
例えば、次のような Books.xml を考えてみましょう。
<catalog>
<book isbn="9784167110017">
<title>ノルウェイの森</title>
<author>村上春樹</author>
<genre>小説</genre>
<price>720</price>
<reviews>
<review>青春の喪失を描いた名作</review>
<review>何度読み返しても新しい発見がある</review>
</reviews>
</book>
<book isbn="9784101001012">
<title>吾輩は猫である</title>
<author>夏目漱石</author>
<year>1905</year>
<genre>古典文学</genre>
</book>
</catalog>
- ルートノード:<catalog> は最上位のコンテナです。
- 子ノード:各 <book> は <catalog> の子ノードです。
- 要素(Element):<title>、<author>、<genre> は、各 <book> 内の要素です。
- 属性(Attribute):<book isbn="..."> の isbn は、book 要素に付加された属性です。
- ネストされた要素:<reviews> の中に複数の <review> 要素があります。
XML を CSV に変換する際の課題
- 階層構造:XML はネスト構造を持てますが、CSV はフラットな形式です。
- 属性と要素:データが属性(isbn)として格納される場合もあれば、要素(title)として格納される場合もあります。
- オプション項目:すべての <book> が同じタグを持つとは限らず、欠損値が発生する可能性があります。
そのため、変換ツールは XML の階層構造を CSV の表形式に適切にマッピングする必要があります。
XML データの抽出と変換方法
Python で XML ファイルを読み込み解析するには、組み込みの xml.etree.ElementTree ライブラリを使用できます。このライブラリを使用すると、XML ツリーをナビゲートし、要素を取得し、属性にアクセスできます。
例:
import xml.etree.ElementTree as ET
# XMLファイルを読み込む
tree = ET.parse("Books.xml")
root = tree.getroot()
# 要素を走査する
for book in root.findall("book"):
title = book.findtext("title", "")
author = book.findtext("author", "")
isbn = book.attrib.get("isbn", "")
XML データを抽出したら、それを表形式に変換します。Spire.XLS for Python を使用すると、ワークブックを作成し、抽出したデータをワークシートへ書き込み、CSV として保存できます。
Python で XML を CSV へ変換する一般的な手順
- xml.etree.ElementTree で XML を読み込む
- Spire.XLS の Workbook オブジェクトを作成する
- Workbook.Worksheets.Add() でワークシートを追加する
- Worksheet.SetValue() でデータを書き込む
- Worksheet.SaveToFile() で CSV として保存する
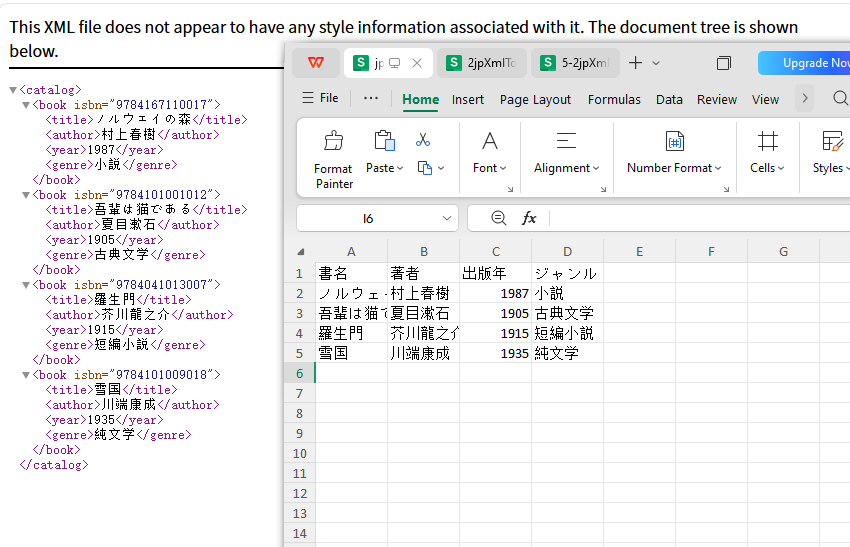
基本例:Python で XML を CSV に変換する
まずはシンプルな XML→CSV 変換を見てみましょう。この例では、最初の <book> 要素から自動的にヘッダーを生成し、すべての子要素を CSV に出力します。
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Workbook オブジェクトを作成
workbook = Workbook()
# デフォルトワークシートを削除
workbook.Worksheets.Clear()
# ワークシートを追加
worksheet = workbook.Worksheets.Add("Books")
# XML ファイルを読み込む
xml_tree = ET.parse("C:\\Users\\Administrator\\Desktop\\Books.xml")
# XML ルート要素を取得
xml_root = xml_tree.getroot()
# 最初の book 要素を取得
first_book = xml_root.find("book")
# ヘッダー情報を抽出
header = list(first_book.iter())[1:]
# 英語と日本語のラベルマッピングを定義する
label_mapping = {
"title": "書名",
"author": "著者",
"year": "出版年",
"genre": "ジャンル",
}
# ヘッダーを書き込む
for col_index, header_node in enumerate(header, start=1):
en_tag = header_node.tag
jp_tag = label_mapping.get(en_tag, en_tag)
worksheet.SetValue(1, col_index, jp_tag)
# データを書き込む
row_index = 2
for book in xml_root.iter("book"):
for col_index, data_node in enumerate(list(book.iter())[1:], start=1):
worksheet.SetValue(row_index, col_index, data_node.text)
row_index += 1
# CSV として保存
worksheet.SaveToFile("output/XmlToCsv.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
このスクリプトは、単純な XML 構造に適しており、書名、著者、ジャンルなどの列を自動生成してデータを書き込みます。
出力:
こちらも参考になるかもしれません: Python で TXT ファイルを CSV に変換する方法
応用テクニック
基本的なスクリプトは多くの場合で機能しますが、XML は多くの場合それほど単純ではありません。実際のシナリオに対処するための高度なテクニックを見ていきましょう。
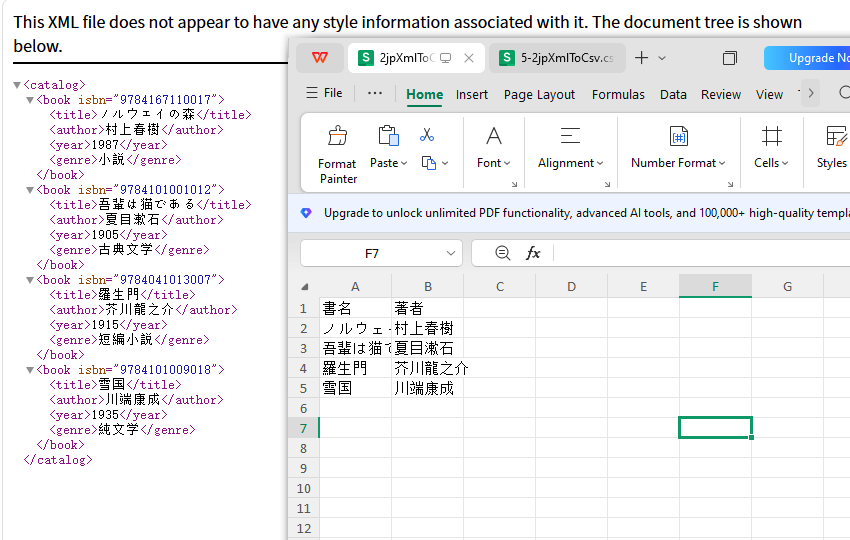
特定の要素のみをエクスポートする
XML に不要なデータが含まれている場合、必要な要素だけを出力できます。
例えば、タイトルと著者のみをエクスポートする場合:
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Workbook オブジェクトを作成する
workbook = Workbook()
# デフォルトのワークシートを削除する
workbook.Worksheets.Clear()
# ワークシートを追加して名前を付ける
worksheet = workbook.Worksheets.Add("Books")
# XML ファイルを読み込む
xml_tree = ET.parse(r"C:\Users\Administrator\Desktop\Books.xml")
xml_root = xml_tree.getroot()
# エクスポートしたい要素を定義する
selected_elements = ["title", "author"]
# 英語と日本語のラベルマッピングを定義する
label_mapping = {
"title": "書名",
"author": "著者",
}
# ヘッダーを書き込む
for col_index, tag in enumerate(selected_elements, start=1):
jp_tag = label_mapping.get(tag, tag)
worksheet.SetValue(1, col_index, jp_tag)
# データを書き込む
row_index = 2
for book in xml_root.iter("book"):
for col_index, tag in enumerate(selected_elements, start=1):
# findtextを使用して欠損値を安全に処理する
worksheet.SetValue(row_index, col_index, book.findtext(tag, ""))
row_index += 1
# CSV として保存
worksheet.SaveToFile("output/XmlToCsv_Selected.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
この方法により、必要な列だけを含む CSV を生成できます。
出力:
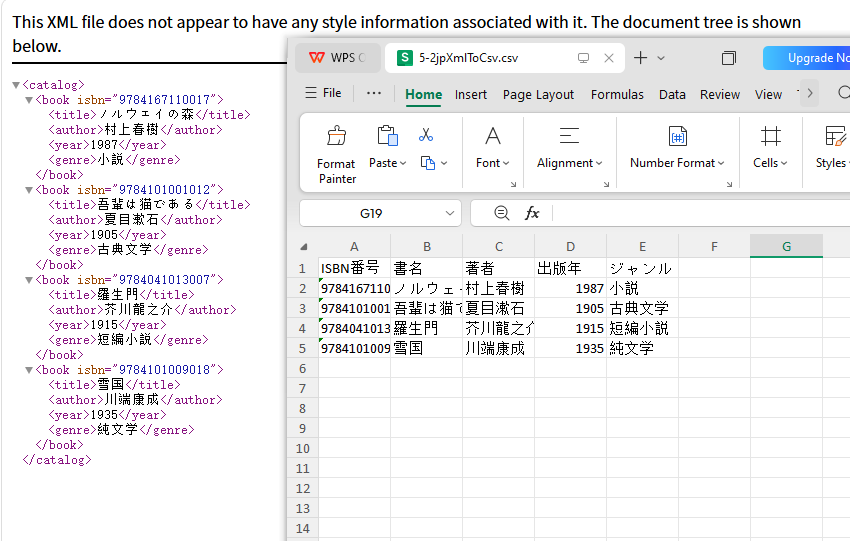
XML 属性を CSV に含める
XML に isbn のような属性として保存された重要なデータが含まれている場合はどうでしょうか? それらを簡単に含めることができます。
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Workbook オブジェクトを作成する
workbook = Workbook()
# デフォルトのワークシートを削除する
workbook.Worksheets.Clear()
# ワークシートを追加して名前を付ける
worksheet = workbook.Worksheets.Add("Books")
# XML ファイルを読み込む
xml_tree = ET.parse(r"C:\Users\Administrator\Desktop\Books.xml")
# XML ツリーのルート要素を取得する
xml_root = xml_tree.getroot()
# 最初の book 要素を取得する
first_book = xml_root.find("book")
# ヘッダー情報(子ノード)を抽出する
header = list(first_book.iter())[1:]
# 英語と日本語のラベルマッピングを定義する
label_mapping = {
"isbn": "ISBN番号",
"title": "書名",
"author": "著者",
"year": "出版年",
"genre": "ジャンル",
}
# ヘッダーを Excel に書き込む
jp_isbn = label_mapping.get("isbn", "isbn")
worksheet.SetValue(1, 1, jp_isbn) # <-- 最初にISBN列を追加
for col_index, header_node in enumerate(header, start=2): # 2から開始する
en_tag = header_node.tag
jp_tag = label_mapping.get(en_tag, en_tag)
worksheet.SetValue(1, col_index, jp_tag)
# データを書き込む
row_index = 2
for book in xml_root.iter("book"):
# isbn をテキストとして書き込む
isbn_value = book.attrib.get("isbn", "")
worksheet.Range[row_index, 1].Text = isbn_value
# 次に他のフィールドを書き込む
for col_index, data_node in enumerate(list(book.iter())[1:], start=2):
value = data_node.text
worksheet.SetValue(row_index, col_index, value)
row_index += 1
# 指数表記を防ぐために ISBN 列全体をテキストとして書式設定する
last_row = row_index - 1
isbn_range = f"A2:A{last_row}"
worksheet.Range[isbn_range].NumberFormat = "@"
# CSV として保存
worksheet.SaveToFile("output/XmlToCsv_WithAttributes.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
ここでは、明示的に ISBN 列を作成し、各 <book> の属性からそれを抽出し、Excel が指数表記で表示するのを防ぐためにテキストとして書式設定しています。
出力:
ネストされた XML 構造を処理する
ネストされたノードは一般的です。次のような XML があるとします。
<catalog>
<book>
<title>羅生門</title>
<author>芥川龍之介</author>
<reviews>
<review>人間のエゴイズムを鋭く描いた傑作</review>
<review>短いながらも強烈な印象を残す</review>
</reviews>
</book>
</catalog>
複数の
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Workbook オブジェクトを作成する
workbook = Workbook()
# デフォルトのワークシートを削除する
workbook.Worksheets.Clear()
# ワークシートを追加して名前を付ける
worksheet = workbook.Worksheets.Add("Books")
# XML ファイルを読み込む
xml_tree = ET.parse(r"C:\Users\Administrator\Desktop\Nested.xml")
xml_root = xml_tree.getroot()
# 最初の <book> 要素を取得する
first_book = xml_root.find("book")
# ヘッダーを収集する(自動検出)
header = []
for child in first_book:
if child.tag == "reviews":
header.append("reviews") # ネストされた <review> を 1 つの列にまとめる
else:
header.append(child.tag)
# 英語と日本語のラベルマッピングを定義する
label_mapping = {
"title": "書名",
"author": "著者",
"year": "出版年",
"genre": "ジャンル",
"price": "価格",
"reviews": "レビュー",
}
# ヘッダー行を書き込む
for col_index, header_text in enumerate(header, start=1):
jp_header = label_mapping.get(header_text, header_text)
worksheet.SetValue(1, col_index, jp_header)
# データ行を書き込む
row_index = 2
for book in xml_root.iter("book"):
col_index = 1
for child in book:
if child.tag == "reviews":
# すべての <review> テキストを 1 つのセルに結合する
reviews = [r.text for r in child.findall("review") if r.text]
worksheet.SetValue(row_index, col_index, "; ".join(reviews))
else:
worksheet.SetValue(row_index, col_index, child.text if child.text else "")
col_index += 1
row_index += 1
# CSV に保存する
worksheet.SaveToFile("output/XmlToCsv_WithReviews.csv", ",", Encoding.get_UTF8())
workbook.Dispose()
出力結果:
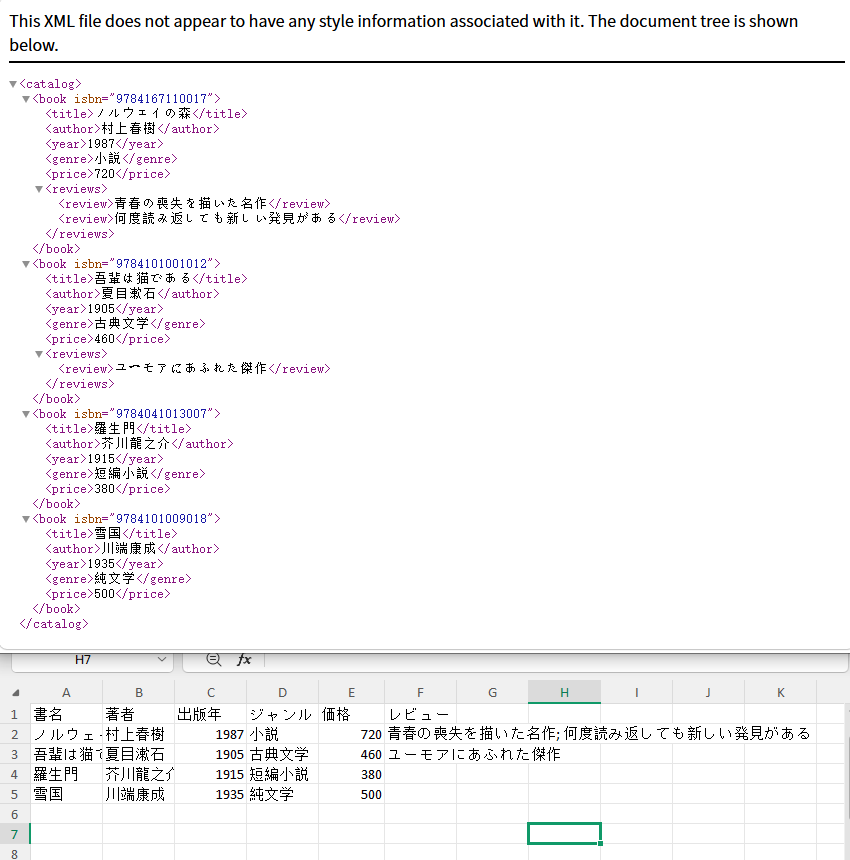
Spire.XLS は、標準の XML ファイルから Excel や CSV へのデータインポートをサポートするだけでなく、Python リストから CSV への変換も可能です。興味があれば、こちらのチュートリアルもご覧ください:Python リストを CSV に変換する方法。
トラブルシューティングとよくある問題
適切に構造化されたスクリプトであっても、XML を CSV に変換する際にいくつかの一般的な問題に遭遇する可能性があります。
Excel で科学表記になる
- 問題:ISBN のような長い数字の文字列が、完全な数値ではなく 9.78045E+12 のように表示される場合があります。
- 解決策:保存する前に、列をテキストとして書式設定します。例:
worksheet.Range["A2:A{last_row}"].NumberFormat = "@"
欠損値によるエラー
- 問題:一部の <book> 要素にオプションフィールド(例:<genre>)がない場合があります。.text に直接アクセスしようとするとエラーが発生する可能性があります。
- 解決策:findtext(tag, "") を使用して、安全にデフォルトの空文字列を提供します。
ヘッダーが不完全になる
- 問題:最初の <book> だけを参照すると、後続の要素に存在するフィールドを見逃す可能性がある。
- 解決策:すべての <book> を走査し、一意のタグを収集してヘッダーを生成する。
文字コードの問題
- 問題:特殊文字(アクセントや記号など)が CSV で正しく表示されない場合があります。
- 解決策:常に UTF-8 エンコーディングで保存します。
worksheet.SaveToFile("output.csv",",", Encoding.get_UTF8())
)
まとめ
Python で XML を CSV に変換する作業は、それほど複雑ではありません。Spire.XLS for Python を使用すると、ヘッダー生成、属性の処理、ネストされたノードのフラット化など、プロセスの多くを自動化できます。少数のフィールドのみをエクスポートする場合でも、複雑な階層を扱う場合でも、乱雑な XML をクリーンアップする場合でも、Spire.XLS はそれに対処する柔軟性を提供します。
少ないコード量で、XML の構造化データを分析しやすい CSV 形式へ変換できるため、データ処理ワークフローを大幅に効率化できます。
FAQs
Q1: CSV ではなく Excel(.xlsx)として保存できますか?
A: はい。単に workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016) を使用してください。
Q2: 非常に大きな XML ファイルを処理するには?
A: xml.etree.ElementTree の iterparse() を使用してストリーミング処理を行うことを推奨します。
Q3: 一部の <book> に追加タグがある場合は?
A:ヘッダー生成時にすべての <book> をスキャンし、一意のタグを動的に収集します。
Q4: CSV の区切り文字を変更できますか?
A: はい。SaveToFile() を呼び出すときに、区切り文字の引数を置き換えます。
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
Q5: 複数の <review> を含むネスト構造はどのように出力しますか?
A: 値を結合して 1 つのセルへ格納します。
reviews = [r.text for r in book.find("reviews").findall("review")]
worksheet.SetValue(row_index, col_index, "; ".join(reviews))
無料ライセンスを取得する
評価版の制限なしで Spire.XLS for Python の機能を試したい場合は、30 日間無料の試用ライセンスを申請できます。





