JSON は、アプリケーション、API、データベース間で構造化データを交換するための最も一般的な形式の 1 つです。しかし、多くのビジネスシナリオでは、JSON データをレポート、請求書、要約、契約書、またはエクスポートされたレコードなどの人間が読める Word ドキュメントに変換する必要があります。
JSON から Word への変換は単純なファイル形式の変換ではありません。JSON には固有の Word 構造がないため、このプロセスでは JSON データを解析し、その要素を段落、テーブル、見出しなどの適切な Word ドキュメントコンポーネントにマッピングする必要があります。
この記事では、Spire.Doc for Python を使用して Python で JSON データを Word ドキュメントに変換する方法を示します。JSON をフォーマットされたテキストとしてエクスポートする、JSON 配列から Word テーブルを作成する、ネストされた JSON データから構造化レポートを生成するなど、複数のアプローチを取り上げます。
コンテンツ概要
- JSON から Word への変換の理解
- Spire.Doc for Python のインストール
- 方法 1:JSON をフォーマットされたテキストとして Word に変換
- 方法 2:JSON 配列を Word テーブルに変換
- 方法 3:JSON から構造化 Word レポートを生成
- ネストされた JSON オブジェクトの処理
- 欠落しているフィールドまたはオプションフィールドの処理
- JSON ファイルを Word ドキュメントに変換
- JSON から Word への変換に Spire.Doc を使用する理由
- よくある質問
- まとめ
1. JSON から Word への変換の理解
JSON と Word ドキュメントは根本的に異なる目的を果たします。JSON はデータ交換と機械処理のために設計された構造化データ形式であり、Word ドキュメントは豊富なフォーマット、視覚的階層、ページレイアウトを備えた人間向けのものです。
その結果、JSON から Word への変換は直接的な形式変換ではありません。Word ドキュメントを生成する前に、JSON データをまず解析して適切なドキュメント要素にマッピングする必要があります。
変換プロセスは通常、次のワークフローに従います:
JSON データ
↓
JSON の解析 (json.loads)
↓
データ構造のマッピング
↓
Spire.Doc for Python
↓
段落 / テーブル / 見出し
↓
DOCX ドキュメント
Python では、組み込みの json モジュールが JSON データの解析によく使用され、Spire.Doc for Python がドキュメント生成を処理します。JSON 構造が分析およびマッピングされると、Spire.Doc は段落、テーブル、見出し、画像、その他の Word 要素をプログラムで作成し、完全にフォーマットされた DOCX ドキュメントを生成できます。
以下の表は、JSON 構造と Word 要素の一般的なマッピングを示しています:
| JSON 構造 | Word 要素 | 例 |
|---|---|---|
| キー値ペア | 段落 | "名前": "山田" → 名前: 山田 |
| 配列 | テーブル | [{...}, {...}] → 行と列 |
| オブジェクト | セクション | ネストされたオブジェクト → グループ化されたコンテンツ |
| タイトルフィールド | 見出し | "title": "レポート" → 見出し 1 |
| URL/画像パス | 画像 | "logo": "img.png" → 埋め込み画像 |
これらのマッピングを理解することは重要です。同じ JSON データでも、ドキュメントの目的に応じて異なる方法で表現できるからです。例えば、単純なキー値データは段落としてエクスポートできますが、レコードのコレクションはテーブルとしてレンダリングすると読みやすくなります。Spire.Doc for Python を使用すると、これらのマッピングをプログラムで実装して、構造化された JSON データからプロフェッショナルな Word ドキュメントを生成できます。
2. Spire.Doc for Python のインストール
JSON から Word への変換を行う前に、開発環境に Spire.Doc for Python をインストールする必要があります。
pip 経由でインストール(推奨)
pip install spire.doc
または、Spire.Doc for Python をダウンロードして手動で統合することもできます。
インストール後、プロジェクトでライブラリをインポートします:
from spire.doc import *
from spire.doc.common import *
3. 方法 1:JSON をフォーマットされたテキストとして Word に変換
この方法は、JSON から Word へ変換する最もシンプルなアプローチです。API レスポンス、設定ファイル、各キー値ペアが段落にマッピングされる単純な JSON エクスポートに適しています。
サンプル JSON
{
"名前": "山田太郎",
"部署": "営業部",
"国": "日本"
}
Python コード
import json
from spire.doc import Document, FileFormat, HorizontalAlignment
json_data = '{"名前": "山田太郎", "部署": "営業部", "国": "日本"}'
data = json.loads(json_data)
document = Document()
section = document.AddSection()
for key, value in data.items():
paragraph = section.AddParagraph()
text_range = paragraph.AppendText(f"{key}: {value}")
text_range.CharacterFormat.FontSize = 12
paragraph.Format.AfterSpacing = 6
document.SaveToFile("json_to_text.docx", FileFormat.Docx)
document.Close()
出力
以下の Word ドキュメントは、JSON キー値ペアがフォーマットされた段落に変換される様子を示しています。
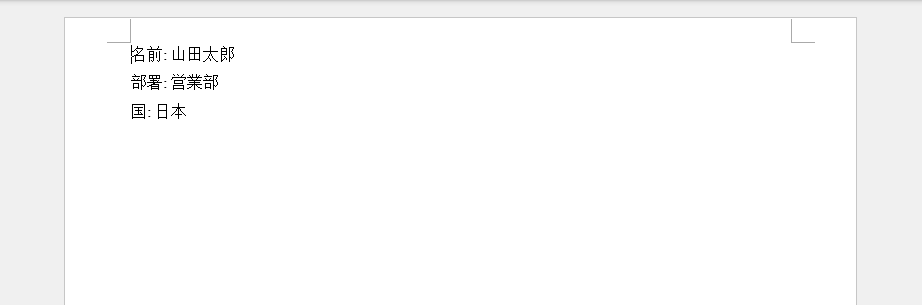
このアプローチを使用する場合
この方法は以下に最適です:
- 単純なキー値 JSON オブジェクト
- API レスポンスのエクスポート
- 設定ファイルのドキュメント化
- クイックデータスナップショット
大規模なデータセットや表形式データには適していません。そのような場合は、方法 2(テーブル)の方が読みやすさが向上します。
構造化された JSON データをスプレッドシートで分析、フィルタリング、または操作する必要がある場合は、Python で JSON を Excel に変換に関するガイドもご覧ください。
4. 方法 2:JSON 配列を Word テーブルに変換
JSON データにオブジェクトの配列が含まれている場合、テーブルは Word ドキュメントでデータを提示する最も効果的な方法です。多くの API やデータベースがデータを JSON 配列として返すため、これは JSON から Word へ変換する最も一般的なシナリオです。
サンプル JSON
[
{"商品": "ノートパソコン", "価格": 150000, "在庫": 45},
{"商品": "マウス", "価格": 3500, "在庫": 200},
{"商品": "キーボード", "価格": 9800, "在庫": 120}
]
Python コード
import json
from spire.doc import (
Document, FileFormat, HorizontalAlignment,
VerticalAlignment, TableRowHeightType, Color
)
json_data = '''[
{"商品": "ノートパソコン", "価格": 150000, "在庫": 45},
{"商品": "マウス", "価格": 3500, "在庫": 200},
{"商品": "キーボード", "価格": 9800, "在庫": 120}
]'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
if data:
headers = list(data[0].keys())
table = section.AddTable(True)
table.ResetCells(len(data) + 1, len(headers))
header_row = table.Rows[0]
header_row.IsHeader = True
header_row.Height = 20
header_row.HeightType = TableRowHeightType.Exactly
for col_index, header in enumerate(headers):
header_row.Cells[col_index].CellFormat.Shading.BackgroundPatternColor = Color.get_Gray()
header_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = header_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(header)
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.FontSize = 12
for row_index, record in enumerate(data):
data_row = table.Rows[row_index + 1]
data_row.Height = 20
data_row.HeightType = TableRowHeightType.Exactly
for col_index, key in enumerate(headers):
data_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = data_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(str(record.get(key, "")))
text_range.CharacterFormat.FontSize = 11
document.SaveToFile("json_to_table.docx", FileFormat.Docx)
document.Close()
出力
以下のスクリーンショットは、JSON 配列から生成された Word テーブルを示しています。
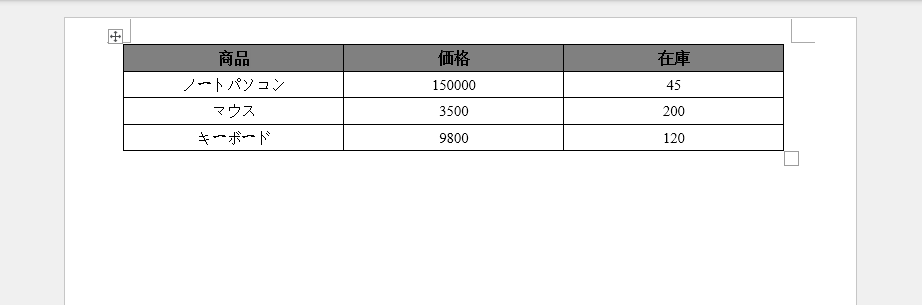
JSON 配列にテーブルを使用する理由
テーブルは JSON 配列データに自然に適合します。理由は次のとおりです:
- 各 JSON オブジェクトがテーブルの行にマッピングされる
- 各キーが列ヘッダーにマッピングされる
- データがスキャンと比較のために整列される
- テーブルはレポート、在庫リスト、エクスポートされたデータベースレコードの標準形式である
フォーマットで JSON テーブルを強化
プレーンテキストエクスポートとは異なり、Spire.Doc を使用すると JSON データをプロフェッショナルにフォーマットされた Word テーブルとしてレンダリングできます。基本的なテーブル作成を超えて、次を適用できます:
- テーブルスタイル – 一貫性のある洗練されたテーブル外観のために
DefaultTableStyleまたはApplyStyleを使用 - 罫線と網掛け – セルの罫線、背景色、交互の行色を制御
- 配置 – セル、行、またはテーブルレベルで水平および垂直配置を設定
- カスタムフォーマット – 個々のセルまたは範囲にフォントサイズ、太字、色を適用
- 自動調整動作 –
AutoFitを使用して列幅をコンテンツまたはウィンドウサイズに合わせて調整
これらのフォーマット機能により、生の JSON データがビジネスドキュメント、クライアント納品物、自動レポートパイプラインに適したプロフェッショナルなレポートレイアウトに変換されます。
結合セル、カスタムテーブルレイアウト、高度なフォーマットなど、より複雑な Word テーブルを作成する必要がある場合は、Python を使用して Word ドキュメントでテーブルを作成およびフォーマットするガイドをご覧ください。
5. 方法 3:JSON から構造化 Word レポートを生成
実際の JSON データには、メタデータ、要約テキスト、表形式データの組み合わせがよく含まれます。この方法は、見出し、段落、テーブルを組み合わせて、JSON から完全な構造化 Word レポートを生成します。
サンプル JSON
{
"title": "月次売上レポート",
"period": "2026年6月",
"summary": "今月の総収益は5,800万円に達し、前期比12%の増加となりました。すべての地域でプラスの成長を示しました。",
"sales": [
{"地域": "北日本", "収益": 15000000, "数量": 320},
{"地域": "南日本", "収益": 12000000, "数量": 280},
{"地域": "東日本", "収益": 18000000, "数量": 410},
{"地域": "西日本", "収益": 13000000, "数量": 290}
]
}
Python コード
import json
from spire.doc import (
Document, FileFormat, HorizontalAlignment,
VerticalAlignment, TableRowHeightType, Color,
BuiltinStyle
)
json_data = '''{
"title": "月次売上レポート",
"period": "2026年6月",
"summary": "今月の総収益は5,800万円に達し、前期比12%の増加となりました。すべての地域でプラスの成長を示しました。",
"sales": [
{"地域": "北日本", "収益": 15000000, "数量": 320},
{"地域": "南日本", "収益": 12000000, "数量": 280},
{"地域": "東日本", "収益": 18000000, "数量": 410},
{"地域": "西日本", "収益": 13000000, "数量": 290}
]
}'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
heading_style = document.AddStyle(BuiltinStyle.Heading1)
subheading_style = document.AddStyle(BuiltinStyle.Heading2)
title_para = section.AddParagraph()
title_para.ApplyStyle(heading_style.Name)
title_para.AppendText(data.get("title", "レポート"))
period_para = section.AddParagraph()
period_para.AppendText(f"期間: {data.get('period', 'N/A')}")
period_para.Format.AfterSpacing = 12
summary_heading = section.AddParagraph()
summary_heading.ApplyStyle(subheading_style.Name)
summary_heading.AppendText("エグゼクティブサマリー")
summary_para = section.AddParagraph()
summary_para.AppendText(data.get("summary", ""))
summary_para.Format.AfterSpacing = 12
sales_heading = section.AddParagraph()
sales_heading.ApplyStyle(subheading_style.Name)
sales_heading.AppendText("売上データ")
sales = data.get("sales", [])
if sales:
headers = list(sales[0].keys())
table = section.AddTable(True)
table.ResetCells(len(sales) + 1, len(headers))
header_row = table.Rows[0]
header_row.IsHeader = True
header_row.Height = 20
header_row.HeightType = TableRowHeightType.Exactly
for col_index, header in enumerate(headers):
header_row.Cells[col_index].CellFormat.Shading.BackgroundPatternColor = Color.get_Gray()
header_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = header_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(header)
text_range.CharacterFormat.Bold = True
for row_index, record in enumerate(sales):
data_row = table.Rows[row_index + 1]
data_row.Height = 20
data_row.HeightType = TableRowHeightType.Exactly
for col_index, key in enumerate(headers):
data_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = data_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText(str(record.get(key, "")))
document.SaveToFile("json_report.docx", FileFormat.Docx)
document.Close()
出力
生成された Word ドキュメントは、見出し、説明文、表形式データを構造化レポートに組み合わせ、JSON データを読みやすく共有しやすい形にします。
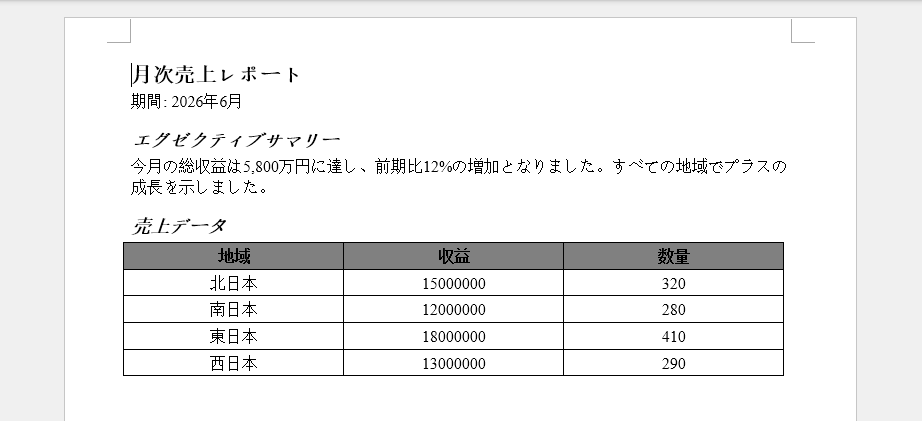
主要な技術
この例では、JSON から Word レポートを生成するためのいくつかの重要な技術を示しています:
- 見出し – ドキュメント構造と目次互換性のために
BuiltinStyle.Heading1およびHeading2を使用 - 段落 – 見出しの間に要約と説明文を追加
- テーブル – JSON 配列をレポート内の表形式データとしてレンダリング
- 組み合わせ – 単一のドキュメントで複数の Word 要素タイプを混合
構造化レポートが重要な理由
ビジネス環境では、JSON データが孤立して存在することはほとんどありません。通常、API、データベース、またはレポートシステムから取得され、意思決定者が読み、共有し、アーカイブできるドキュメントに変換する必要があります。一般的なシナリオには次のものがあります:
- 売上レポート – CRM または ERP システムからの収益、数量、地域別内訳
- 在庫レポート – 在庫レベル、再発注アラート、倉庫要約
- 顧客サマリー – 連絡先詳細、注文履歴、アカウントステータス
- コンプライアンスレポート – 監査ログ、アクセス記録、ポリシーステータス
- 自動レポートシステム – JSON データからドキュメントを生成し、電子メールまたはドキュメント管理システムを介して配布するスケジュールされたジョブ
Spire.Doc を使用すると、構造化された JSON データを自動的に洗練されたビジネスドキュメントに変換でき、単一の出力で見出し、段落、テーブルを組み合わせることができます。
複数セクションのレポート、表紙、目次、ヘッダー、フッター、カスタムドキュメントテンプレートなど、より高度なドキュメントレイアウトを構築する必要がある場合は、Python で構造化 Word ドキュメントを作成するガイドをご覧ください。
6. ネストされた JSON オブジェクトの処理
多くの実際の JSON レスポンスにはネストされたオブジェクトが含まれています。例えば、顧客レコードには独自のフィールドを持つ住所オブジェクトが含まれる場合があります。これらのネストされた構造を処理することは、完全な JSON から Word への変換に不可欠です。
例:JSON
{
"customer": {
"name": "佐藤健",
"email": "sato@ example.com",
"address": {
"street": "東京都渋谷区1-2-3",
"city": "東京",
"state": "東京都"
}
}
}
Python コード
import json
from spire.doc import Document, FileFormat, HorizontalAlignment
def add_nested_object(section, obj, indent_level=0):
for key, value in obj.items():
if isinstance(value, dict):
heading_para = section.AddParagraph()
heading_text = " " * indent_level + key.capitalize()
text_range = heading_para.AppendText(heading_text)
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.FontSize = 12 - indent_level
heading_para.Format.AfterSpacing = 4
add_nested_object(section, value, indent_level + 1)
else:
paragraph = section.AddParagraph()
label = " " * indent_level + f"{key}: {value}"
text_range = paragraph.AppendText(label)
text_range.CharacterFormat.FontSize = 11
paragraph.Format.AfterSpacing = 2
json_data = '''{
"customer": {
"name": "佐藤健",
"email": "sato@ example.com",
"address": {
"street": "東京都渋谷区1-2-3",
"city": "東京",
"state": "東京都"
}
}
}'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
add_nested_object(section, data)
document.SaveToFile("json_nested.docx", FileFormat.Docx)
document.Close()
出力
以下のスクリーンショットは、ネストされた JSON 構造から生成された階層的 Word ドキュメントを示しています。
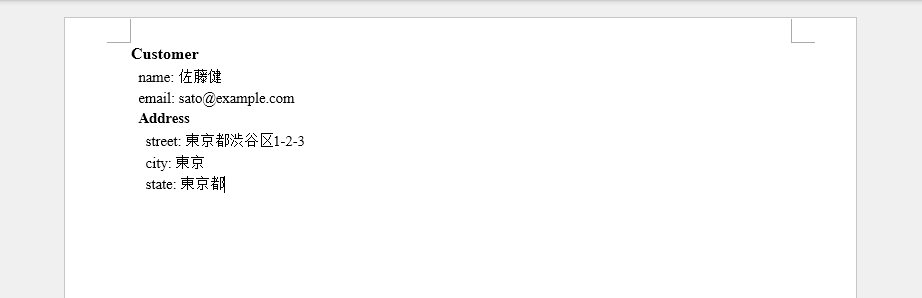
ネストされた JSON オブジェクトは Word ドキュメントの階層的セクションとして表現でき、複雑なデータ構造を読みやすくナビゲートしやすくします。
仕組み
add_nested_object 関数は JSON 構造を再帰的にトラバースします:
- dict 値を検出すると、キーの太字見出しを作成し、ネストされたオブジェクトに再帰
- スカラー値を検出すると、キー値ペアを含む段落を作成
indent_levelパラメータは、視覚的階層を作成するためにインデントとフォントサイズを制御
この再帰的アプローチは任意の深さのネストを処理し、Word ドキュメントで読みやすい階層的レイアウトを生成します。
7. 欠落しているフィールドまたはオプションフィールドの処理
実際のアプリケーションでは、API やデータベースからの JSON データには欠落しているフィールドやオプションフィールドがよく含まれます。レコードに一貫性のないキーがある場合があり、一部のフィールドは完全に欠落している場合があります。これらのケースを適切に処理することでエラーを防ぎ、生成された Word ドキュメントが完全であることを保証します。
欠落フィールドを含む例:JSON
[
{"名前": "佐藤健", "メール": "sato@ example.com", "電話": "03-1234-5678"},
{"名前": "田中美咲", "メール": "tanaka@ example.com"},
{"名前": "鈴木大輔", "電話": "06-9876-5432"}
]
Python コード
import json
from spire.doc import (
Document, FileFormat, HorizontalAlignment,
VerticalAlignment, TableRowHeightType, Color
)
json_data = '''[
{"名前": "佐藤健", "メール": "sato@ example.com", "電話": "03-1234-5678"},
{"名前": "田中美咲", "メール": "tanaka@ example.com"},
{"名前": "鈴木大輔", "電話": "06-9876-5432"}
]'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
if data:
all_keys = []
for record in data:
for key in record.keys():
if key not in all_keys:
all_keys.append(key)
table = section.AddTable(True)
table.ResetCells(len(data) + 1, len(all_keys))
header_row = table.Rows[0]
header_row.IsHeader = True
header_row.Height = 20
header_row.HeightType = TableRowHeightType.Exactly
for col_index, header in enumerate(all_keys):
header_row.Cells[col_index].CellFormat.Shading.BackgroundPatternColor = Color.get_Gray()
header_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = header_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(header)
text_range.CharacterFormat.Bold = True
for row_index, record in enumerate(data):
data_row = table.Rows[row_index + 1]
data_row.Height = 20
data_row.HeightType = TableRowHeightType.Exactly
for col_index, key in enumerate(all_keys):
data_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = data_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText(str(record.get(key, "N/A")))
document.SaveToFile("json_missing_fields.docx", FileFormat.Docx)
document.Close()
出力
以下のスクリーンショットは、欠落しているフィールドがプレースホルダー値で自動的に埋められ、一貫したドキュメント構造を維持する生成された Word テーブルを示しています。
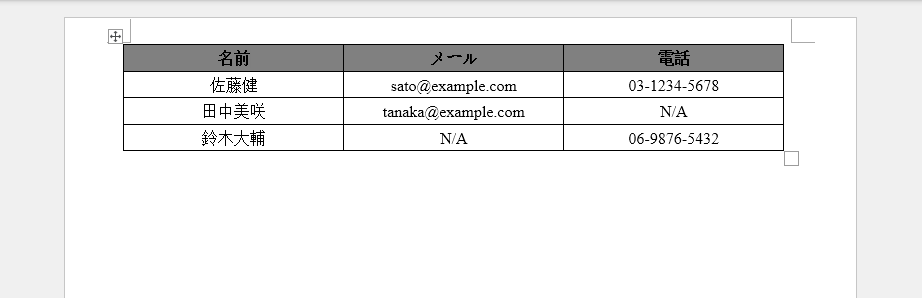
主要な技術
dict.get(key, "N/A")– キーが欠落している場合にデフォルト値を返し、KeyError例外を防ぐ- 動的列収集 – すべてのレコードを反復処理して完全な列ヘッダーセットを構築し、一部のレコードにのみ出現するフィールドも見逃さないようにする
- 一貫したテーブル構造 – 各レコードにどのフィールドが存在するかに関係なく、すべての行が同じ数の列を持つ
このアプローチは、API レスポンスの構造が異なるレコード間や時間経過とともに変化する可能性がある本番ユースケースに不可欠です。
8. JSON ファイルを Word ドキュメントに変換
実際には、JSON データはインライン文字列ではなくファイルから取得されることがよくあります。API エクスポート結果、設定ファイル、データベースダンプ、データ交換ファイル、ログデータはすべて、Word ドキュメントに変換する必要がある .json ファイルとして一般的に保存されます。
JSON ファイルの変換プロセスは次のワークフローに従います:
JSON ファイル (.json)
↓
JSON の読み込み (json.load)
↓
Word ドキュメントの生成 (Spire.Doc)
↓
DOCX ドキュメント
Python コード
import json
from spire.doc import Document, FileFormat
with open("data.json", "r", encoding="utf-8") as f:
data = json.load(f)
document = Document()
section = document.AddSection()
# 読み込まれた JSON データを処理
# 方法 1~3 のいずれかの技術を使用
# (フォーマットされたテキスト、テーブル、または構造化レポート)
document.SaveToFile("data_report.docx", FileFormat.Docx)
document.Close()
要点
json.load()は JSON ファイルを直接読み込んで解析します。文字列を解析するjson.loads()とは異なりますencoding="utf-8"は JSON ファイルの非 ASCII 文字を適切に処理することを保証します- JSON ファイルが Python の辞書またはリストに読み込まれると、Spire.Doc for Python は解析されたデータから段落、テーブル、または構造化レポートを、この記事で前述した任意の方法を使用して生成できます
読み込まれたデータを処理する完全な例については、フォーマットされたテキストの場合は方法 1、テーブルの場合は方法 2、構造化レポートの場合は方法 3を参照してください。
9. JSON から Word への変換に Spire.Doc を使用する理由
JSON から Word への変換には、単純なデータ解析を超えるいくつかの実用的な課題が含まれます。適切にフォーマットされたテーブルの生成、一貫したスタイルの適用、見出しと段落を含む構造化レポートの作成、ネストされたデータまたは不完全なデータの処理には、すべて有能なドキュメント生成 API が必要です。
JSON から Word への変換の課題
- テーブル生成 – JSON 配列をヘッダー、行、セルフォーマットを備えた Word テーブルにマッピングする必要がある
- ドキュメントフォーマット – 生データのエクスポートには、Word ドキュメントを読みやすくする視覚的階層が欠けている
- 構造化レポート – 単一のドキュメントで見出し、段落、テーブルを組み合わせるには、複数の要素タイプを調整する必要がある
- ネストされたデータ – 深くネストされた JSON オブジェクトには再帰的トラバースと階層的レイアウトが必要
- 大規模ドキュメント – 大規模な JSON データセットから複数ページのレポートを生成するには効率的なリソース管理が必要
Spire.Doc for Python の利点
Spire.Doc for Python は、わかりやすい API でこれらの課題に対処します:
- Microsoft Word なしで Word ドキュメントを作成 – Office のインストールや Interop 依存関係が不要
- 段落、テーブル、画像、ヘッダー、フッターを生成 – Word ドキュメント要素の完全なカバレッジ
- 組み込みスタイルとカスタムスタイルを適用 –
BuiltinStyleおよびParagraphStyleを使用してドキュメント間で一貫したフォーマット - レポート生成を自動化 – 任意の JSON データソースから構造化レポートをプログラムで構築
- DOCX および他の形式にエクスポート –
FileFormatを使用して DOCX、PDF、HTML、RTF などに保存
Spire.Doc を使用すると、JSON から Word への変換プロセスは、手動の文字列フォーマットやテンプレート操作ではなく、解析されたデータから Word 要素への構造化マッピングになります。
10. よくある質問
Python で JSON を Word に変換するにはどうすればよいですか?
Python の組み込み json モジュールを使用して JSON データを解析し、Spire.Doc for Python を使用して Word ドキュメントを作成します。JSON キー値ペアを段落に、JSON 配列をテーブルにマッピングし、構造に見出しを使用します。基本的な例については方法 1を、完全なレポートについては方法 3を参照してください。
JSON 配列を Word テーブルに変換できますか?
はい。JSON オブジェクトの配列は Word テーブルに自然にマッピングされ、各オブジェクトが行になり、各キーが列になります。JSON 配列からフォーマットされたテーブルを作成する完全なコード例については、方法 2を参照してください。
API JSON レスポンスから DOCX レポートを作成するにはどうすればよいですか?
API レスポンスを JSON として取得し、解析して、Spire.Doc for Python を使用してレポートを生成します。タイトルに見出し、要約に段落、データ配列にテーブルを組み合わせます。構造化レポートの例については、方法 3を参照してください。
ネストされた JSON オブジェクトを Word にエクスポートできますか?
はい。再帰関数を使用してネストされた JSON オブジェクトをトラバースし、オブジェクトキーに見出し、スカラー値に段落を作成します。視覚的階層を備えたネストされた構造を処理する詳細な例については、セクション 6を参照してください。
JSON ファイルを Word ドキュメントに変換するにはどうすればよいですか?
Python の json.load() を使用して JSON ファイルを読み込み、Spire.Doc for Python で解析されたデータを処理します。コード例については、セクション 8を参照してください。
JSON データから Word ドキュメントを生成する最良の方法は何ですか?
最適なアプローチは JSON 構造によって異なります。単純なキー値データの場合は、フォーマットされた段落を使用します。配列の場合は、テーブルを使用します。混合コンテンツを含む複雑なネストデータの場合は、方法 3に示されているように、見出し、段落、テーブルを組み合わせます。
11. まとめ
JSON データから Word ドキュメントを生成することは、レポート作成、ドキュメント自動化、データエクスポートワークフローで一般的な要件です。Spire.Doc for Python を使用すると、JSON から直接段落、テーブル、構造化ドキュメントレイアウトを作成でき、アプリケーションデータからプロフェッショナルな DOCX ファイルを簡単に作成できます。
同じアプローチは、API レスポンス、データベースレコード、設定ファイル、その他の構造化データソースにも拡張でき、小規模プロジェクトからエンタープライズシステムまで、ドキュメント生成の自動化に役立ちます。
大規模ドキュメントやドキュメント変換要件を含むシナリオの場合、ライセンス版が必要です。





