
Word ドキュメントを JSON に変換することは、自動ドキュメント処理パイプラインの構築、AI モデルへのコンテンツ投入、または DOCX ファイルからデータベースや API への構造化データの移行を行う際の一般的な要件です。CSV や XML とは異なり、JSON は柔軟な階層形式を提供し、段落、テーブル、ネストされたドキュメント構造を単一の出力で表現できます。
しかし、Word ファイルにはネイティブな JSON エクスポート形式がありません。.docx ファイルはセクション、段落、スタイル、テーブルで構成されるリッチテキストドキュメントであり、構造化データソースではありません。これを JSON に変換するには、そのコンテンツを意味のあるスキーマにマッピングする方法を決定する必要があります。
このチュートリアルでは、Spire.Doc for Python を使用して Python で Word を JSON に変換する方法を示します。プレーンな段落的テキストの抽出、Word テーブルを JSON 配列に変換する、見出し、段落、テーブルを含む完全なドキュメント構造を階層的 JSON 出力で保持するなど、3 つの progressively advanced な方法を学びます。このチュートリアルの例は、Spire.Doc がサポートする DOCX とレガシー DOC ファイルの両方で動作します。
クイックナビゲーション
- Word はどのように JSON に変換されるか?
- 必要なライブラリのインストール
- 方法 1 – Word テキストを JSON に変換
- 方法 2 – Word テーブルを JSON に変換
- 方法 3 – JSON でドキュメント構造を保持
- Word から JSON への変換を使用する場合
- 制限事項とベストプラクティス
- よくある質問
- まとめ
1. Word はどのように JSON に変換されるか?
Word ドキュメントはセクション、段落、テーブルで構成されるリッチテキスト形式であり、構造化データ形式ではありません。Word を JSON に変換する場合、コンテンツをどのように表現すべきかという単一の標準はありません。適切なスキーマは JSON の使用方法によって異なります:
| 目標 | 推奨スキーマ | 主要な特徴 |
|---|---|---|
| AI 埋め込み / セマンティック検索 | 段落配列 | フラットなテキスト文字列リスト、段落ごとに 1 つ |
| フルテキスト検索インデックス | メタデータ付きテキストブロック | セクションインデックスとスタイル情報を持つ段落 |
| テーブルからのデータベースインポート | テーブル行オブジェクト | ヘッダーキー付き辞書、行ごとに 1 つ |
| RAG パイプライン / ナレッジベース | 階層構造 | 見出し、段落、テーブルを含むネストされたセクション |
| ドキュメントアーカイブ / 交換 | 完全ドキュメントモデル | セクション、スタイル、メタデータ、すべてのコンテンツタイプ |
例えば、見出しと段落を含む Word ドキュメントは、JSON で次のように表現できます:
{
"document": [
{"type": "heading", "level": 1, "text": "プロジェクト概要"},
{"type": "paragraph", "text": "このレポートは四半期の結果を要約しています。"}
]
}
このチュートリアルの 3 つの方法は、これらのスキーマ選択に直接対応しています:
- 方法 1 は段落配列を生成(AI 埋め込み、検索インデックス)
- 方法 2 はテーブル行オブジェクトを生成(データベースインポート、データ抽出)
- 方法 3 は階層構造を生成(RAG、ナレッジベース、ドキュメント理解)
目標に合った方法を選択するか、複数の方法から要素を組み合わせてカスタムスキーマを構築してください。
2. 必要なライブラリのインストール
このチュートリアルでは、DOC/DOCX ファイルを読み取って解析するために Spire.Doc for Python を使用します。pip 経由でインストールします:
pip install spire.doc
または、Spire.Doc for Python をダウンロードして手動で統合することもできます。
インストール後、Python スクリプトでライブラリをインポートします:
from spire.doc import Document, FileFormat
from spire.doc.common import *
Spire.Doc は、Word ドキュメントの読み込み、セクション、段落、テーブルの反復処理、テキストコンテンツの抽出など、Word から JSON へのパイプラインを構築するために必要なすべてを提供します。
3. 方法 1 – Word テキストを JSON に変換
Word を JSON に変換する最も簡単な方法は、ドキュメントからすべての段落テキストを抽出し、JSON 配列に保存することです。このアプローチは、フルテキスト検索、AI テキスト埋め込み、または単純なコンテンツエクスポートなど、構造化メタデータなしで全文コンテンツが必要な場合に適しています。
3.1 Word ドキュメントから段落を読み取る
Spire.Doc は Word ドキュメントを セクションのコレクションとして表現し、各セクションには 段落が含まれます。すべてのテキストを抽出するには、すべてのセクションとその中のすべての段落を反復処理します。
from spire.doc import Document
from spire.doc.common import *
input_file = "プロジェクトレポート.docx"
document = Document()
document.LoadFromFile(input_file)
paragraphs = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
text = paragraph.Text
if text.strip():
paragraphs.append(text)
document.Close()
各段落の .Text プロパティは、フォーマットを取り除いたプレーンテキストコンテンツを返します。if text.strip() チェックは、Word でスペーシングやレイアウト要素として存在する空の段落をフィルタリングします。
3.2 抽出したテキストを JSON にシリアライズ
前の手順で抽出した段落データが paragraphs リストに格納されていると仮定すると、それを JSON にシリアライズしてファイルに保存できます:
import json
output_file = "paragraphs.json"
result = {
"source": input_file,
"paragraph_count": len(paragraphs),
"paragraphs": paragraphs
}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=2, ensure_ascii=False)
出力例
以下の JSON スニペットは、生成された出力ファイルの構造を示しています:
{
"source": "プロジェクトレポート.docx",
"paragraph_count": 3,
"paragraphs": [
"四半期売上レポート",
"このドキュメントは、すべての地域にわたる売上パフォーマンスの概要を提供します。"
]
}
変換結果
以下の画像は、ソース Word ドキュメントと、段落テキストを抽出した後に生成された JSON ファイルを示しています。
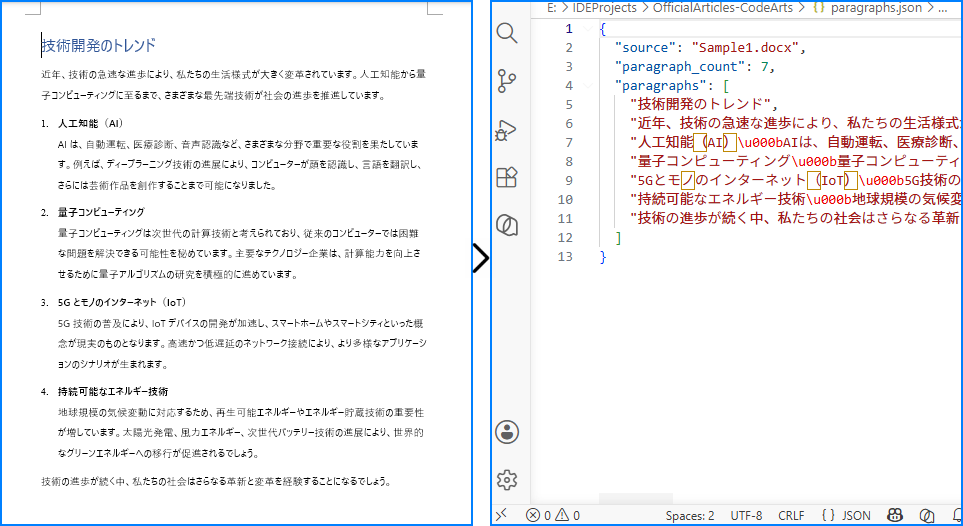
3.3 説明
なぜ一度にすべてのテキストを抽出するのではなく、セクションと段落を反復処理するのでしょうか?Word ドキュメントは階層的に構成されているためです。ドキュメントには 1 つ以上のセクション(それぞれ独自のページレイアウトを持つ)が含まれ、各セクションには段落が含まれます。このレベルで反復処理することで、どのコンテンツを含めるか、またはスキップするかを制御できます。例えば、空の段落をフィルタリングしたり、特定のセクションへの抽出を制限したりできます。
段落を JSON 配列として保存するのは最も単純な構造です。各要素は文字列であるため、下流システムでの消費が容易です。このアプローチは以下に適しています:
- フルテキストインデックス作成 – 段落テキストを Elasticsearch などの検索エンジンに投入
- AI テキスト埋め込み – セマンティック検索のために段落をベクトル表現に変換
- 単純なコンテンツエクスポート – フォーマットなしで Word ファイルから読みやすいテキストを抽出
ただし、この方法は構造化情報を失います。見出し、本文テキスト、リスト項目はすべて同じ方法で扱われます。それらを区別する必要がある場合は、方法 3を参照してください。
JSON に変換せずに Word ドキュメントからテキストコンテンツを抽出するだけの場合は、Python で Word ドキュメントからテキストを抽出するガイドにも興味があるかもしれません。
4. 方法 2 – Word テーブルを JSON に変換
多くの Word ドキュメント(レポート、請求書、製品リスト、設定テーブル)では、最も価値のあるコンテンツは段落ではなくテーブル内にあります。Word テーブルを JSON に変換すると、データベース、API、またはデータ分析ツールに直接ロードできる構造化された行列表データを抽出できます。
テーブルに特別な処理が必要な理由
Word のテーブルは行とセルのグリッドとして保存され、各セルには独自の段落が含まれます。段落テキストとは異なり、テーブルデータには JSON オブジェクトに自然にマッピングされる固有の 2 次元構造があります。最初の行には多くの場合列ヘッダーが含まれ、後続の行にはデータレコードが含まれます。
Word ドキュメントからテーブルを抽出
次のコードは、Word ドキュメントからすべてのテーブルを読み取り、最初の行を列ヘッダーとして使用し、後続の各行を JSON オブジェクトに変換します:
import json
from spire.doc import Document
from spire.doc.common import *
input_file = "売上データ.docx"
output_file = "tables.json"
document = Document()
document.LoadFromFile(input_file)
all_tables = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
rows_data = []
if table.Rows.Count < 2:
continue
header_row = table.Rows[0]
headers = []
for c in range(header_row.Cells.Count):
cell_text = header_row.Cells[c].Paragraphs[0].Text.strip()
headers.append(cell_text)
for r in range(1, table.Rows.Count):
row = table.Rows[r]
row_dict = {}
for c in range(row.Cells.Count):
cell_text = row.Cells[c].Paragraphs[0].Text.strip()
row_dict[headers[c] if c < len(headers) else f"Column_{c}"] = cell_text
rows_data.append(row_dict)
all_tables.append({
"table_index": t,
"headers": headers,
"row_count": len(rows_data),
"rows": rows_data
})
document.Close()
result = {
"source": input_file,
"table_count": len(all_tables),
"tables": all_tables
}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=2, ensure_ascii=False)
出力例
以下の JSON スニペットは、ヘッダー行をキーとして使用して各テーブル行が JSON オブジェクトにマッピングされた、生成された出力ファイルの構造を示しています:
{
"source": "売上データ.docx",
"table_count": 1,
"tables": [
{
"table_index": 0,
"headers": ["地域", "商品", "販売数量", "収益"],
"row_count": 3,
"rows": [
{"地域": "北日本", "商品": "ノートパソコン", "販売数量": "120", "収益": "114000"},
{"地域": "南日本", "商品": "ノートパソコン", "販売数量": "80", "収益": "76000"}
]
}
]
}
変換結果
以下の画像は、Word ドキュメントのテーブルデータが構造化された JSON レコードに変換される様子を示しています。
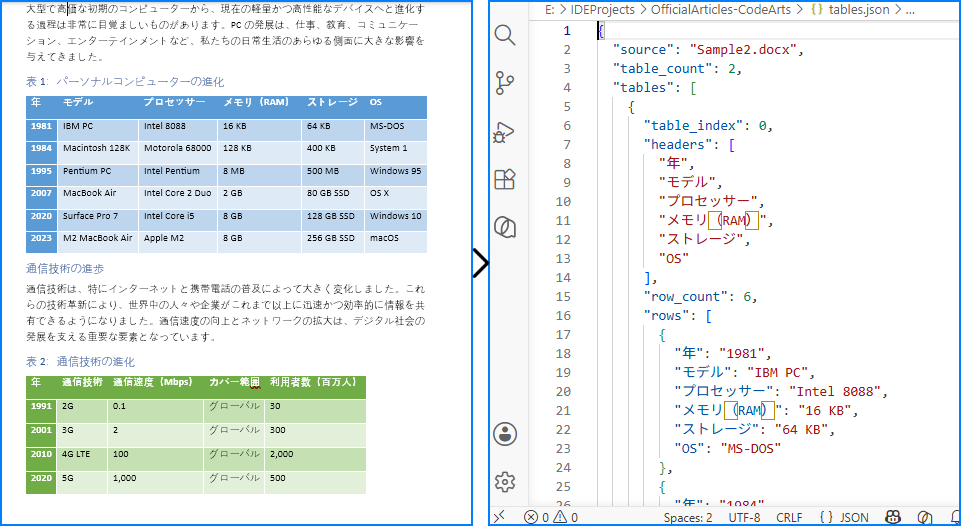
説明
このコードは最初の行をヘッダー行として扱い、後続の行の各セルを対応するヘッダーキーにマッピングします。これにより、表形式データに最も一般的で有用な形式である JSON オブジェクトの配列が生成されます。
主要な考慮事項:
table.Rows.Count < 2は、ヘッダー行のみを持つテーブルまたは空のテーブルをスキップrow.Cells[c].Paragraphs[0].Textは、各セルの最初の段落からテキストを抽出。簡略化のため、この例では最初の段落のみを読み取ります。セルに複数の段落が含まれる場合は、Paragraphsコレクション全体を反復処理して結果を連結します:
cell_text = "\n".join(
row.Cells[c].Paragraphs[p].Text.strip()
for p in range(row.Cells[c].Paragraphs.Count)
if row.Cells[c].Paragraphs[p].Text.strip()
)
headers[c] if c < len(headers) else f"Column_{c}"は、データ行にヘッダー行よりも多くのセルがある場合を処理
この方法は、Word ドキュメントに保存されたレポート、請求書、製品カタログ、設定テーブルから構造化データを抽出するのに最適です。結果の JSON は、データベースに直接ロードしたり、Web API で使用したり、データ分析ツールで処理したりできます。
構造化された JSON データから Word ドキュメントを生成する必要がある場合は、JSON オブジェクトと配列から直接 Word コンテンツとテーブルを作成する方法をカバーする、Python で JSON を Word に変換に関するチュートリアルをご覧ください。
5. 方法 3 – JSON でドキュメント構造を保持
方法 1 と 2 は、段落とテーブルを別々の孤立した要素として扱います。実際には、Word ドキュメントには意味のある階層があります:見出しはセクションを導入し、段落は詳細を提供し、テーブルは特定のコンテキスト内で構造化データを提示します。
この階層を JSON で保持すると、ナレッジベース構築、RAG(Retrieval-Augmented Generation)パイプライン、ドキュメント理解システムにとって遥かに有用な出力が生成されます。フラットなテキストリストではなく、元のドキュメントの論理的フローを維持する構造化表現が得られます。
階層的 JSON 構造で見出し、段落、テーブルを保持する方法
アプローチは、各セクションの本文内のすべての子オブジェクトを反復処理し、各オブジェクトのタイプ(段落またはテーブル)を判断し、それに応じて構造化された JSON 表現を構築することです。段落の場合、StyleName プロパティをチェックして見出しを検出できます。
import json
from spire.doc import Document
from spire.doc.common import *
input_file = "プロジェクトレポート.docx"
output_file = "structured_output.json"
HEADING_STYLES = {
"Heading1": 1,
"Heading2": 2,
"Heading3": 3,
"Heading4": 4,
}
def get_heading_level(style_name):
return HEADING_STYLES.get(style_name, None)
def extract_table_data(table):
rows_data = []
if table.Rows.Count < 1:
return {"headers": [], "rows": []}
header_row = table.Rows[0]
headers = []
for c in range(header_row.Cells.Count):
headers.append(header_row.Cells[c].Paragraphs[0].Text.strip())
for r in range(1, table.Rows.Count):
row = table.Rows[r]
row_dict = {}
for c in range(row.Cells.Count):
cell_text = row.Cells[c].Paragraphs[0].Text.strip()
row_dict[headers[c] if c < len(headers) else f"Column_{c}"] = cell_text
rows_data.append(row_dict)
return {"headers": headers, "rows": rows_data}
document = Document()
document.LoadFromFile(input_file)
sections_data = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
content_items = []
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
if isinstance(obj, Paragraph):
text = obj.Text.strip()
if not text:
continue
heading_level = get_heading_level(obj.StyleName)
if heading_level:
content_items.append({
"type": "heading",
"level": heading_level,
"text": text
})
else:
content_items.append({
"type": "paragraph",
"text": text
})
elif isinstance(obj, Table):
table_data = extract_table_data(obj)
content_items.append({
"type": "table",
"row_count": len(table_data["rows"]),
"data": table_data
})
sections_data.append({
"section_index": i,
"content": content_items
})
document.Close()
result = {
"source": input_file,
"section_count": len(sections_data),
"sections": sections_data
}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=2, ensure_ascii=False)
出力例
以下の JSON スニペットは、見出し、段落、テーブルが階層的出力構造でどのように表現されるかを示しています:
{
"source": "プロジェクトレポート.docx",
"section_count": 1,
"sections": [
{
"section_index": 0,
"content": [
{
"type": "heading",
"level": 1,
"text": "四半期売上レポート"
},
{
"type": "paragraph",
"text": "このレポートは、すべての地域にわたる売上パフォーマンスの概要を提供します。"
},
{
"type": "heading",
"level": 2,
"text": "地域別内訳"
},
{
"type": "table",
"row_count": 3,
"data": {
"headers": ["地域", "商品", "販売数量", "収益"],
"rows": [
{"地域": "北日本", "商品": "ノートパソコン", "販売数量": "120", "収益": "114000"}
]
}
}
]
}
]
}
変換結果
以下の画像は、見出し、段落、テーブルが階層的 JSON 構造で保持される様子を示しています。
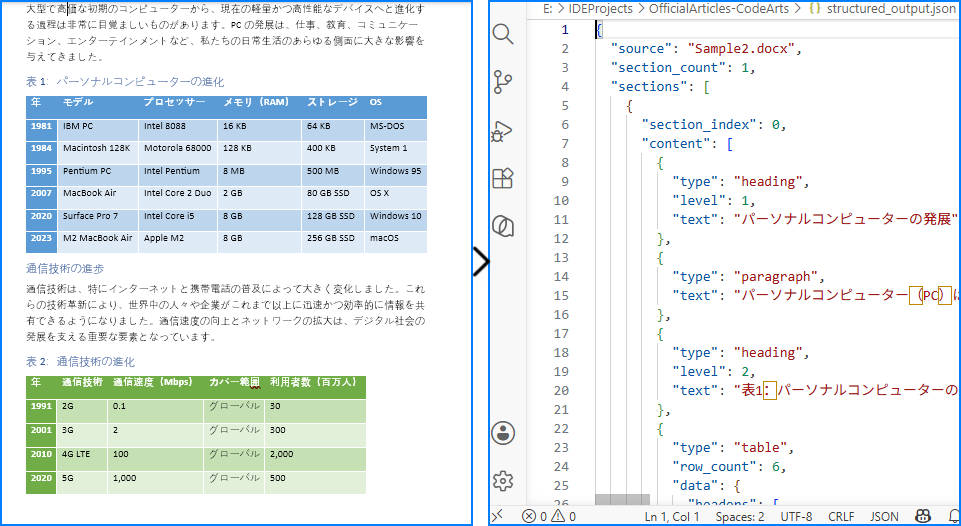
説明
この方法は、以前の 2 つの方法と根本的に異なります:段落とテーブルを個別に反復処理するのではなく、section.Body.ChildObjects を使用してドキュメント順にすべてのコンテンツ要素を反復処理します。これにより、見出し、段落、テーブルの元の順序とインターリーブが保持されます。
主要な設計決定:
StyleNameによる見出し検出 – Word の見出しは「Heading1」、「Heading2」などでスタイル設定された段落です。スタイル名をチェックすることで、見出しを本文テキストから区別し、見出しレベルを記録できます。正確な見出しスタイル名は、Word テンプレートまたは言語設定によって異なる場合があることに注意してください(例:スペース付きの「Heading 1」、または中国語の「标题 1」などのローカライズされた名前)。これらのバリエーションを処理するには、ルックアップ前にスタイル名を正規化します:
def get_heading_level(style_name):
normalized = style_name.lower().replace(" ", "")
heading_map = {"heading1": 1, "heading2": 2, "heading3": 3, "heading4": 4}
return heading_map.get(normalized, None)
ChildObjects反復 –section.Paragraphs(段落のみを返す)やsection.Tables(テーブルのみを返す)とは異なり、ChildObjectsは元の順序ですべての要素を返します。これはドキュメントの論理構造を保持するために不可欠です。- 構造化 JSON 出力 – 各コンテンツアイテムには
typeフィールド(heading、paragraph、またはtable)が含まれ、下流システムが異なるコンテンツタイプを適切に処理しやすくします。
このアプローチは以下に特に価値があります:
- RAG および AI パイプライン – 見出し構造により、セクションごとにドキュメントをチャンキングでき、フラットなテキスト分割よりも優れた検索結果が得られる
- ナレッジベース構築 – 階層的 JSON はツリー構造化ナレッジグラフに直接マッピング
- ドキュメント理解 – 見出しと関連コンテンツ間の関係を保持することで、ドキュメントセクションのセマンティック分析が可能
見出し、段落、テーブルなど、Word ドキュメントから特定のコンテンツタイプを抽出する必要がある場合は、コンテンツ抽出技術をより詳細にカバーする、Python で Word ドキュメントを読み取るに関するチュートリアルをご覧ください。
6. Word から JSON への変換を使用する場合
Word から JSON への変換は、大規模に Word ドキュメントから構造化データを抽出する必要があるあらゆるシナリオで役立ちます。一般的なユースケースには次のものがあります:
- AI および RAG ドキュメント処理 – LLM ベースのアプリケーションでの埋め込みと取得のために、Word ドキュメントを JSON チャンクに変換。方法 3 からの階層構造により、セクションレベルのチャンキングが可能になり、フラットなテキスト分割よりも優れた検索結果が得られる
- ナレッジベース構築 – .docx ファイルとして保存された技術ドキュメント、ポリシー文書、またはマニュアルから構造化ナレッジベースを構築
- バッチデータ抽出 – 数百の Word レポート、請求書、またはフォームからデータを抽出し、結果をデータベースまたはデータウェアハウスにロード
- 契約書および履歴書の解析 – 法的契約書、HR ドキュメント、または履歴書を構造化 JSON に変換し、自動分析と比較を可能にする
- API および Web アプリケーションデータ交換 – Word ドキュメントコンテンツを JSON として REST API を介して提供し、Web およびモバイルアプリケーションが .docx ファイルを直接処理せずにドキュメントデータを消費できるようにする
7. 制限事項とベストプラクティス
制限事項
- Word の標準 JSON スキーマなし – CSV や XML とは異なり、Word コンテンツを JSON で表現するための普遍的に受け入れられた形式はありません。選択する構造は、特定のユースケースに合わせて設計する必要があります。
- 複雑なフォーマットはキャプチャされない – このチュートリアルの方法は、テキストコンテンツと基本的な構造化メタデータ(見出しレベル、テーブルデータ)を抽出します。フォント、色、画像、ページレイアウト、ヘッダー/フッター、脚注はキャプチャしません。これらの要素が必要な場合は、追加の抽出ロジックが必要です。
- 結合セルには特別な処理が必要 – Word テーブルには結合セル(水平および垂直の両方)が含まれる場合があります。方法 2 の単純な行ごとの抽出は、通常のグリッドを想定しています。結合セルを含むドキュメントは予期しない結果を生む可能性があります。
- 大規模ドキュメントにはチャンク処理が必要 – 数百ページまたは数十のテーブルを含むドキュメントの場合、メモリ使用量を管理するためにセクションまたはテーブルを個別に処理することを検討してください。
ベストプラクティス
- コードを書く前に JSON スキーマを設計 – 何が必要か(テキストのみ?見出し?テーブル?完全な構造?)を決定し、適切な抽出方法を選択
- サンプルドキュメントに対して出力を検証 – Word ドキュメントは構造とフォーマットが大きく異なります。実際のドキュメントセットからの代表的なサンプルに対して変換ロジックをテスト
- エンコーディングを明示的に処理 – 非 ASCII テキストの文字エンコーディング問題を避けるために、JSON ファイルを書き込む際に常に
encoding="utf-8"を指定 json.dumpでensure_ascii=Falseを使用 – これにより、出力で Unicode 文字がエスケープされずに保持され、英語以外のテキストを含むドキュメントにとって重要です
8. よくある質問
Python で DOCX を JSON に変換できますか?
はい。Spire.Doc for Python を使用して、任意の .docx ファイルを読み込み、そのセクション、段落、テーブルを反復処理し、Python の組み込み json モジュールを使用して抽出したコンテンツを JSON にシリアライズできます。このチュートリアルでは、単純なテキスト抽出から完全な構造保持まで、これを行うための 3 つの方法を示しています。
開発者向けの最適な Word から JSON へのコンバーターは何ですか?
バッチ処理、自動化、またはカスタム JSON スキーマが必要な開発者にとって、Spire.Doc を使用した Python ベースのアプローチは、オンラインコンバーターよりも柔軟性があります。オンラインツールは一回限りの変換には機能しますが、大規模な処理、カスタム出力形式、または自動パイプラインへの統合は処理できません。
Word テーブルを JSON に変換できますか?
はい。Word ドキュメント内のテーブルを反復処理し、セルテキストを行ごとに抽出することで、テーブルデータを JSON オブジェクトの配列に変換できます。このチュートリアルの方法 2 は、ヘッダーベースのキーマッピングでこれを示しています。
Word にはネイティブな JSON エクスポートオプションがありますか?
いいえ。Microsoft Word には組み込みの JSON エクスポート形式がありません。Word ファイルは DOCX、PDF、HTML、RTF、プレーンテキストとして保存できますが、JSON への変換には、ドキュメント構造を読み取り、JSON スキーマにマッピングするプログラム的アプローチが必要です。
Word を JSON に変換する際に見出しと構造を保持できますか?
はい。各セクションの本文内のすべての子オブジェクトを反復処理し、段落スタイル名をチェックすることで、見出し、本文段落、テーブルを検出し、ドキュメントの論理組織を保持する階層的 JSON 構造を構築できます。このチュートリアルの方法 3 は完全な実装を提供しています。
Word をオンラインで JSON に変換できますか?
はい、一回限りの変換を処理できるオンラインの Word から JSON へのコンバーターがあります。ただし、オンラインツールは単一ファイル処理に限定され、JSON スキーマのカスタマイズを許可しません。バッチ処理、自動パイプライン、またはカスタム出力構造の場合、Spire.Doc を使用した Python ベースのアプローチの方が実用的でスケーラブルです。
9. まとめ
この記事では、Spire.Doc for Python を使用して Python で Word ドキュメントを JSON に変換する方法を示しました。複雑さが増す 3 つの方法を取り上げました:段落テキストをフラットな JSON 配列として抽出、Word テーブルを構造化 JSON オブジェクトに変換、見出し、段落、テーブルを含む完全なドキュメント階層を単一の JSON 出力で保持。
各方法は異なる目的を果たします。プレーンテキスト抽出はインデックス作成と埋め込みに適しています。テーブル抽出はデータ移行とレポート解析に最適です。完全な構造保持はナレッジベース構築と RAG パイプラインを可能にします。要件に合ったアプローチを選択し、特定のユースケースに応じて JSON スキーマを拡張してください。
Spire.Doc for Python は、JSON 変換を超えた包括的な Word ドキュメント処理機能を提供します。ドキュメント作成、フォーマット、メールマージ、形式変換など。30 日間の無料ライセンスを申請して、すべての機能を評価できます。





