API、データ分析、ビジネスレポートを含む多くの Python プロジェクトでは、開発者が Python コードを使用してExcel から JSON へ、またはJSON から Excel へ変換する必要がよくあります。これらの形式は異なるが補完的な役割を果たします:JSON は構造化されたデータ交換と保存に最適であり、Excel はビジネス環境でデータを共有、編集、表示するために広く使用されています。
このチュートリアルでは、Python で JSON と Excel 間の相互変換を行うための、開発者向けの包括的なガイドを提供します。ネストされたデータの処理、Excel フォーマットの適用、一般的な変換やエンコーディングの問題の解決方法を学びます。Python の組み込み json モジュールを使用して JSON データを処理し、Spire.XLS for Python を使用して .xlsx、.xls、.csv 形式の Excel ファイルを読み書きします。これらはすべて、Microsoft Excel や他のサードパーティソフトウェアを必要としません。
カバーするトピック:
- Spire.XLS for Python のインストール
- オープンソースライブラリよりも Spire.XLS を選ぶ理由
- Python で JSON を Excel に変換
- Python で Excel を JSON に変換
- 実例:ネストされた JSON の処理と Excel のフォーマット
- JSON ↔ Excel 変換における一般的なエラーと修正
- よくある質問
- まとめ
Spire.XLS for Python のインストール
このライブラリは、JSON-Excel 変換ワークフローの一部として Excel ファイル(.xlsx、.xls、.csv)を生成および解析するために、このチュートリアルで使用されます。
開始するには、PyPI から Spire.XLS for Python パッケージをインストールします:
pip install spire.xls
小規模なプロジェクトでは、Free Spire.XLS for Python を選択することもできます:
pip install spire.xls.free
Spire.XLS for Python は Windows、Linux、macOS で動作します。Microsoft Excel や COM コンポーネントのインストールは不要です。
オープンソースライブラリよりも Spire.XLS を選ぶ理由
多くのオープンソース Python ライブラリは、単純なデータエクスポートや基本的なフォーマットなど、一般的な Excel タスクに優れています。ユースケースが単純なテーブル出力のみを必要とする場合、これらのツールはすぐに作業を完了できます。
しかし、プロジェクトが豊富な Excel フォーマット、複数シートのレポート、またはMicrosoft Office なしの独立したソリューションを必要とする場合、Spire.XLS for Python は完全な Excel 機能セットを提供することで際立ちます。
| 機能 | オープンソースライブラリ | Spire.XLS for Python |
|---|---|---|
| 高度なExcelフォーマット | 🔸 基本的なスタイリング | ✅ レポート用の完全なスタイリングAPI |
| Office/COM依存なし | ✅ 完全にスタンドアロン | ✅ 完全にスタンドアロン |
| .xls、.xlsx、.csvをサポート | 主に.xlsxと.csv;.xlsには追加パッケージが必要 | ✅ .xls、.xlsx、.csvを完全にサポート |
| チャート、画像、形状 | 🔸 制限ありまたはなし | ✅ 組み込みの完全なサポート |
複雑なレイアウト、ビジュアル、またはビジネス対応のスタイリングを持つ洗練された Excel ファイルを必要とする開発者チームにとって、Spire.XLS は効率的なオールインワンの代替手段です。
Python で JSON を Excel に変換
このセクションでは、Python を使用して構造化された JSON データを Excel ファイルに変換する方法を説明します。これは、API レスポンスや内部データをビジネスユーザーやアナリスト向けの .xlsx レポートにエクスポートする場合に特に便利です。
ステップ1:JSON データの準備
従業員レコードのJSONリストから始めます:
[
{"employee_id": "E001", "name": "田中太郎", "department": "人事部"},
{"employee_id": "E002", "name": "佐藤花子", "department": "IT部"},
{"employee_id": "E003", "name": "鈴木一郎", "department": "財務部"}
]
これは、API によって返されるか、ログファイルに保存される典型的な構造です。より複雑なネスト構造については、実例セクションを参照してください。
ステップ2:Spire.XLS で Python の JSON を Excel に変換
from spire.xls import Workbook, FileFormat
import json
# ファイルからJSONデータを読み込む
with open("employees.json", "r", encoding="utf-8") as f:
data = json.load(f)
# 新しいExcelワークブックを作成し、最初のワークシートにアクセス
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 1行目にヘッダーを書き込む
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# 2行目からデータ行を書き込む
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
# 使用されているすべての列の幅を自動調整
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Excelファイルを保存してリソースを解放
workbook.SaveToFile("output/employees.xlsx", FileFormat.Version2016)
workbook.Dispose()
コードの説明:
- Workbook() は 3 つのデフォルトワークシートで Excel ファイルを初期化します。
- workbook.Worksheets[] は指定されたワークシートにアクセスします。
- sheet.Range(row, col).Text は特定のセルに文字列データを書き込みます(1 ベースインデックス)。
- 1 行目には JSON キーに基づいた列ヘッダーが含まれ、各 JSON オブジェクトはその下の新しい行に書き込まれます。
- workbook.SaveToFile() は Excel ワークブックをディスクに保存します。FileFormat 列挙型を使用して形式を指定できます — 例えば、Version97to2003 は .xls として保存し、Version2007 以降は .xlsx として保存し、CSV は .csv として保存します。
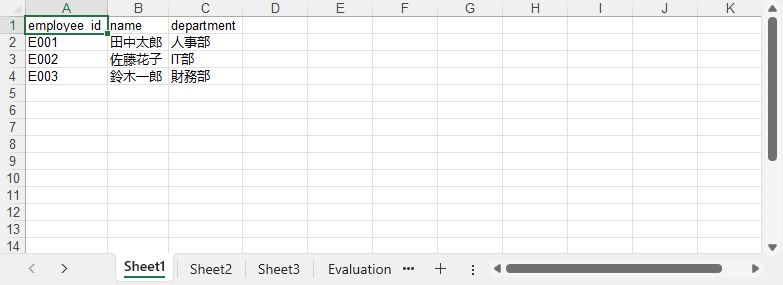
生成された Excel ファイル(employees.xlsx)には、employee_id、name、department の列があります。
Python で Excel を JSON に変換
この部分では、Python を使用して Excel データを構造化された JSON に戻す方法を説明します。これは、JSON 入力を期待する Web アプリ、API、またはデータパイプラインに .xlsx ファイルをインポートする場合の一般的なニーズです。
ステップ1:Excel ファイルの読み込み
まず、Workbook.LoadFromFile() を使用して Excel ファイルを読み込み、workbook.Worksheets[0] を使用してワークシートを選択します。これにより、JSON 形式に変換したいデータにアクセスできます。
from spire.xls import Workbook
# Excelファイルを読み込む
workbook = Workbook()
workbook.LoadFromFile("products.xlsx")
sheet = workbook.Worksheets[0]
ステップ2:Excel データを抽出して JSON に書き込む
import json
# 最後の行と列のインデックスを取得
rows = sheet.LastRow
cols = sheet.LastColumn
# 1行目からヘッダーを抽出
headers = [sheet.Range[1, i + 1].Text for i in range(cols)]
data = []
# ヘッダーを使用して各行を辞書にマッピング
for r in range(2, rows + 1):
row_data = {}
for c in range(cols):
value = sheet.Range[r, c + 1].Text
row_data[headers[c]] = value
data.append(row_data)
# JSON出力を書き込む
with open("products_out.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)
コードの説明:
- sheet.LastRow と sheet.LastColumn は実際に使用されているセル範囲を検出します。
- 1 行目はフィールド名(ヘッダー)の抽出に使用されます。
- 各行は辞書にマッピングされ、JSON オブジェクトのリストを形成します。
- sheet.Range[row, col].Text は、セルの表示テキスト(日付形式や通貨記号などのフォーマットを含む)を返します。生の数値や実際の日付オブジェクトが必要な場合は、代わりに**.Value**、.NumberValue、または**.DateTimeValue**を使用できます。
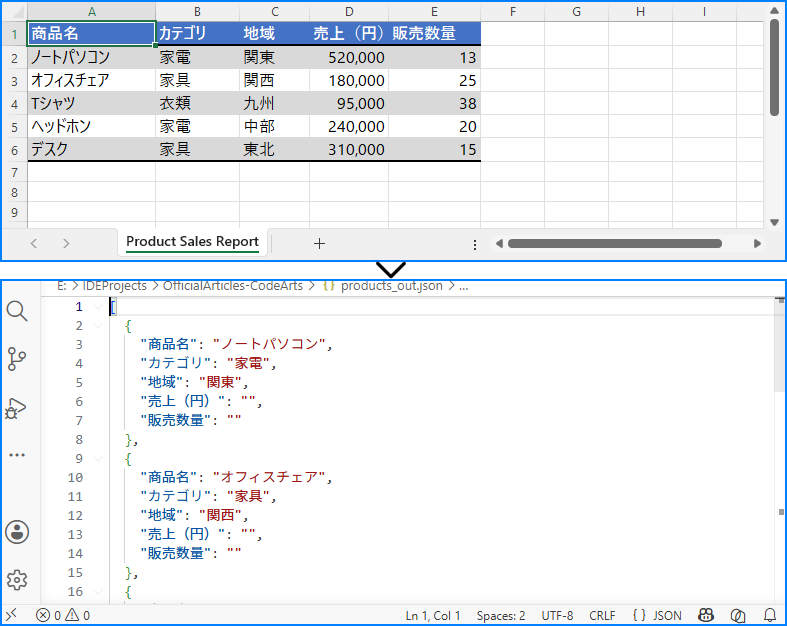
Python を使用して Excel データから生成された JSON ファイル:
Python で Excel ファイルを読み取る方法にまだ慣れていない場合は、完全なガイドを参照してください:Spire.XLS を使用して Python で Excel ファイルを読み取る方法。
実例:ネストされた JSON の処理と Excel のフォーマット
実際の Python アプリケーションでは、JSON データには連絡先詳細、設定グループ、進捗ログなどのネストされた辞書やリストがよく含まれます。同時に、Excel 出力はビジネスや報告目的に適した清潔で読みやすいレイアウトに従うことが期待されます。
このセクションでは、Python と Spire.XLS を使用してネストされた JSON データをフラット化し、結果の Excel シートをフォーマットする方法を示します。これには、セルの結合、スタイルの適用、列の自動調整が含まれます。これらはすべて、複雑なデータを明確な表形式で提示するのに役立つ機能です。
サンプルファイル projects_nested.json を使用してプロセスを説明します。
ステップ1:ネストされた JSON のフラット化
サンプルJSONファイル(projects_nested.json):
[
{
"project_id": "PRJ001",
"title": "AI研究プロジェクト",
"manager": {
"name": "王恵美博士",
"email": "emily@ lab.org"
},
"phases": [
{"phase": "設計", "status": "完了"},
{"phase": "開発", "status": "進行中"}
]
},
{
"project_id": "PRJ002",
"title": "クラウド移行",
"manager": {
"name": "李ジョン氏",
"email": "john@ infra.net"
},
"phases": [
{"phase": "評価", "status": "完了"}
]
}
]
manager のようなオブジェクトを含むすべてのネスト構造をフラット化し、phases のようなリストを文字列フィールドに要約します。各 JSON レコードは単一のフラット行になり、複雑なネストデータでさえ読みやすい要約を使用して列にコンパクトに表示されます。
import json
# ヘルパー:ネストデータをフラット化し、辞書のリストを文字列に要約
# 例:[{"a":1},{"a":2}] → "a: 1; a: 2"
def flatten(data, parent_key='', sep='.'):
items = {}
for k, v in data.items():
new_key = f"{parent_key}{sep}{k}" if parent_key else k
if isinstance(v, dict):
items.update(flatten(v, new_key, sep=sep))
elif isinstance(v, list):
if all(isinstance(i, dict) for i in v):
items[new_key] = "; ".join(
", ".join(f"{ik}: {iv}" for ik, iv in i.items()) for i in v
)
else:
items[new_key] = ", ".join(map(str, v))
else:
items[new_key] = v
return items
# JSONを読み込んでフラット化
with open("projects_nested.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
flat_data = [flatten(record) for record in raw_data]
# フラット化データからすべての一意のキーをヘッダーとして収集
all_keys = set()
for item in flat_data:
all_keys.update(item.keys())
headers = list(sorted(all_keys)) # 一貫性のあるソートされた列順序
このバージョンのflatten() は、辞書のリストを簡潔な要約文字列(例:"phase: 設計, status: 完了; phase: 開発, status: 進行中")に変換し、複雑な構造を Excel 出力用によりコンパクトにします。
ステップ2:Spire.XLS で Excel をフォーマットしてエクスポート
次に、フラット化されたプロジェクトデータを Excel にエクスポートし、Spire.XLS for Python のフォーマット機能を使用してレイアウトと可読性を向上させます。これには、フォント、色、セルの結合の設定、プロフェッショナルなレポート外観のための列幅の自動調整が含まれます。
from spire.xls import Workbook, Color, FileFormat
# ワークブックとワークシートを作成
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "プロジェクト"
# タイトル行:結合してスタイルを設定
col_count = len(headers)
sheet.Range[1, 1, 1, col_count].Merge()
sheet.Range[1, 1].Text = "プロジェクトレポート(フラット化JSON)"
title_style = sheet.Range["A1"].Style
title_style.Font.IsBold = True
title_style.Font.Size = 14
title_style.Font.Color = Color.get_White()
title_style.Color = Color.get_DarkBlue()
# フラット化キーからのヘッダー行
for col, header in enumerate(headers):
cell = sheet.Range[2, col + 1]
cell.BorderAround() # セルまたはセル範囲に外枠を追加
#cell.BorderInside() # セル範囲に内枠を追加
cell.Text = header
style = cell.Style
style.Font.IsBold = True
style.Color = Color.get_LightGray()
# データ行
for row_idx, row in enumerate(flat_data, start=3):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
# 列と行を自動調整
for col in range(len(headers)):
sheet.AutoFitColumn(col + 1)
for row in range(len(flat_data)):
sheet.AutoFitRow(row + 1)
# Excelファイルを保存
workbook.SaveToFile("output/projects_formatted.xlsx", FileFormat.Version2016)
workbook.Dispose()
これにより、ネストされた JSON ファイルから清潔でスタイル設定された Excel シートが生成され、レポート、関係者、またはダッシュボードに適した出力になります。
コードの説明
- sheet.Range[].Merge():セルの範囲を 1 つに結合します。ここではレポートタイトル行(A1:F1)に使用しています。
- .Style.Font / .Style.Color:セルのフォントプロパティ(太字、サイズ、色)と背景塗りつぶしをカスタマイズできます。
- .BorderAround() / .BorderInside():セル範囲に外枠/内枠を追加します。
- AutoFitColumn(n):列
nの幅をその内容に合わせて自動的に調整します。
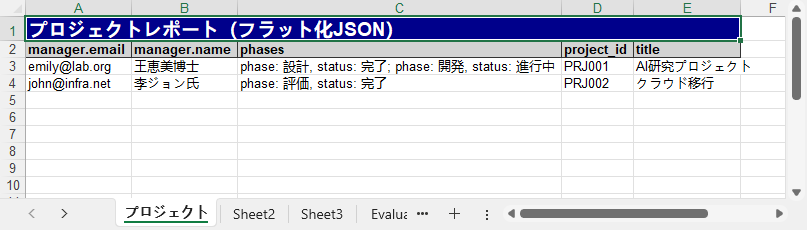
Python を使用して JSON データをフラット化した後に生成された Excel ファイル:
JSON ↔ Excel 変換における一般的なエラーと修正
JSON と Excel 間の相互変換では、フォーマット、エンコーディング、またはデータ構造の問題が発生することがあります。以下は一般的な問題とその修正方法です:
| エラー | 修正方法 |
|---|---|
| JSONDecodeError または不正な入力 | 有効な構文を確認;eval() の使用を避ける;json.load() を使用し、ネストされたオブジェクトをフラット化する。 |
| TypeError: Object of type ... is not JSON serializable | json.dump(data, f, default=str) を使用してシリアライズ不可能な値を変換する。 |
| Excel ファイルが読み込めない、またはクラッシュする | ファイルが Excel で開かれていないことを確認;正しい拡張子(.xlsx または .xls)を使用する。 |
| UnicodeEncodeError または文字化け | json.dump() で encoding="utf-8" と ensure_ascii=False を設定する。 |
まとめ
Spire.XLS for Python を使用すると、JSON と Excel 間の相互変換が効率化され、信頼性の高いプロセスになります。JSON データをヘッダーとスタイル付きの適切にフォーマットされた Excel ファイルに簡単に変換でき、同様に Excel シートを構造化された JSON にスムーズに戻すことができます。このライブラリは、エンコーディングエラー、ネストされたデータの複雑さ、Excel ファイル形式の落とし穴などの一般的な問題を回避するのに役立ちます。
データエクスポートの処理、レポートの生成、API レスポンスの処理のいずれであっても、Spire.XLS は双方向で**.json** と**.xlsx** 形式を扱うための一貫した効率的な方法を提供します。
制限なくすべての機能をアンロックしたいですか?Spire.XLS for Python へのフルアクセスのために無料の一時ライセンスをリクエストしてください。
よくある質問
Q1: PythonでJSONをExcelに変換するにはどうすればよいですか?
Python のjsonモジュールを使用して構造化された JSON データを読み込み、Spire.XLS などのライブラリを使用して.xlsxにエクスポートできます。Spire.XLS では、ヘッダーの書き込み、Excel セルのフォーマット、フラット化によるネストされた JSON の処理が可能です。ステップバイステップの例については、上記のJSON から Excel へセクションを参照してください。
Q2: PythonでJSONデータを解析するにはどうすればよいですか?
Python での JSON 解析は、組み込みのjsonモジュールで簡単に行えます。ファイルから JSON を解析するにはjson.load()を使用し、JSON 文字列を解析するにはjson.loads()を使用します。解析後、結果は通常、辞書のリストになり、反復処理して Excel や他の形式にエクスポートできます。
Q3: PythonでSpire.XLSを使用してExcelをJSONにエクスポートできますか?
はい。Spire.XLS for Python では、Excel ファイルを読み取り、ワークシートデータを辞書のリストに変換し、json.dump()を使用して JSON に書き込むことができます。このプロセスには、ヘッダーの抽出、使用されている行と列の検出、オプションでフォーマットの処理が含まれます。詳細な実装についてはExcel から JSON へを参照してください。





