
PDF は、プラットフォームやデバイスを問わず一貫したレイアウトを維持できるため、レポート、請求書、電子フォームなどで広く利用されています。しかし、その固定レイアウトの特性上、専用ツールなしで編集するのは容易ではありません。
Python で PDF を編集したい開発者にとって、Spire.PDF for Python は包括的かつ使いやすいソリューションです。この Python 向け PDF 編集ライブラリを使用すると、Adobe Acrobat やその他の外部ソフトウェアに依存することなく、テキストの変更、画像の差し替え、注釈の追加、フォーム処理、セキュリティ設定などをプログラムから実行できます。
この記事では、Spire.PDF for Python を使用して、Python アプリケーション内で PDF を編集する方法を紹介します。
- Python と Spire.PDF で PDF ドキュメントを編集する理由
- Spire.PDF for Python のセットアップ
- Spire.PDF for Python で既存の PDF を編集する方法
- よくある質問
Python と Spire.PDF で PDF ドキュメントを編集する理由
Python は非常に汎用性の高いプログラミング言語であり、PDF ドキュメントの自動化や管理に最適な環境を提供します。PDF 編集を行う際、Spire.PDF for Python はあらゆる PDF 操作を実現できる包括的で使いやすいライブラリとして優れています。
Python で PDF を編集するメリット
- 自動化とバッチ処理:繰り返し行うPDF編集作業を効率的に自動化できます。
- コスト削減:手作業を減らし、時間とリソースを節約できます。
- システム統合:既存の Python ベースのシステムやワークフローに簡単に組み込むことができます。
Spire.PDF for Python のメリット
Spire.PDF for Python は、外部ソフトウェアに依存せずに PDF ファイルの作成、読み取り、編集、変換、保存を行えるスタンドアロンライブラリです。
主な機能は次のとおりです。
- テキストと画像の編集
- 注釈およびブックマークの管理
- PDF フォームの処理
- セキュリティ設定(暗号化・アクセス権限)
- Word、Excel、HTML、画像への変換
詳細については、Spire.PDF for Python のチュートリアルをご覧ください。
直感的な API 設計により、Spire.PDF は Python での PDF 編集をこれまで以上に簡単かつ効率的に実現し、快適な開発体験を提供します。
Spire.PDF for Python のセットアップ
インストール
Spire.PDF for Python は、以下の pip コマンドでインストールできます。
pip install spire.pdf
小規模プロジェクト向けの無料版を使用する場合は、次のコマンドを実行します。
pip install spire.pdf.free
また、公式サイトからライブラリを手動でダウンロードすることもできます。
基本的な使用例
以下のコードは、Spire.PDF for Python を使用してシンプルな PDF を作成する例です。
from spire.pdf import PdfDocument, PdfFont, PdfBrushes, PdfFontFamily, PdfFontStyle
# 新しいPDFドキュメントを作成
pdf = PdfDocument()
# ページを追加
page = pdf.Pages.Add()
# フォントを作成
font = PdfFont(PdfFontFamily.TimesRoman, 28.0, PdfFontStyle.Bold)
# ブラシを作成
brush = PdfBrushes.get_Black()
# テキストを描画
page.Canvas.DrawString("Hello, World", font, brush, 100.0, 100.0)
# 保存
pdf.SaveToFile("output/NewPDF.pdf")
pdf.Close()
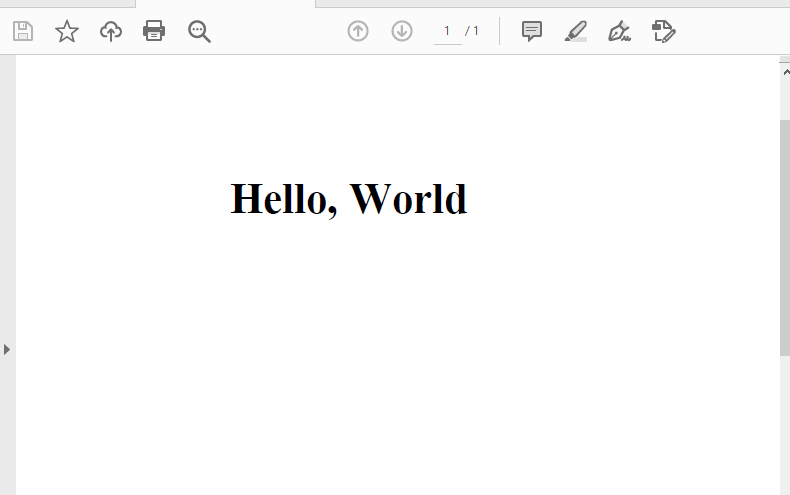
実行結果:
生成された PDF には、Times Roman ボールドで "Hello, World" というテキストが表示されます。
Spire.PDF のインストールが完了したら、Python で PDF を編集する準備は完了です。次のセクションでは、PDF の構造、コンテンツ、セキュリティ、メタデータの編集方法について説明します。
Spire.PDF for Python で既存の PDF を編集する方法
Spire.PDF for Python は、Python を使用して PDF を編集するためのシンプルかつ強力な方法を提供します。直感的な API により、開発者はドキュメント構造、ページコンテンツ、セキュリティ設定、プロパティの変更など、幅広い PDF 編集タスクを自動化できます。以下では、それぞれの編集カテゴリについて紹介します。
Python で PDF のページと構造を編集する
構造編集では、PDF のページ順序の操作、ファイルの結合、ページの挿入/削除が可能で、ドキュメント組み立てワークフローに最適です。
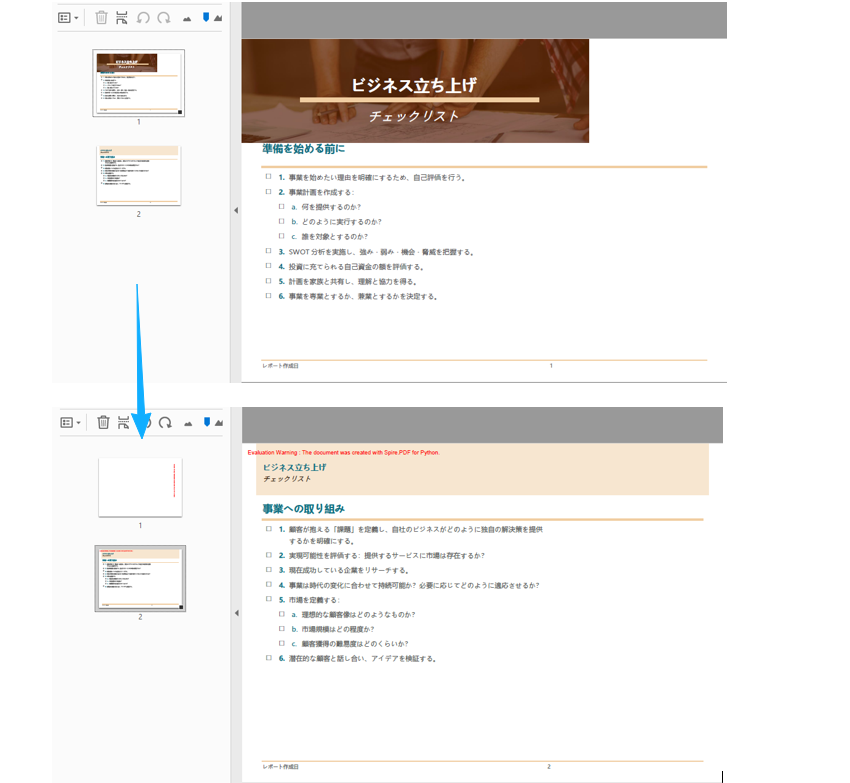
- ページの挿入と削除
PdfDocument クラスの Pages.Insert() メソッドと Pages.RemoveAt() メソッドを使用して、指定位置へページを追加または削除できます。
コード例
from spire.pdf import PdfDocument, PdfPageSize, PdfMargins, PdfPageRotateAngle
# PDFを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# ページを挿入
pdf.Pages.Insert(0, PdfPageSize.A4(), PdfMargins(50.0, 60.0), PdfPageRotateAngle.RotateAngle90)
# 2ページ目を削除
pdf.Pages.RemoveAt(1)
# 保存
pdf.SaveToFile("output/InsertDeletePage.pdf")
pdf.Close()
結果:
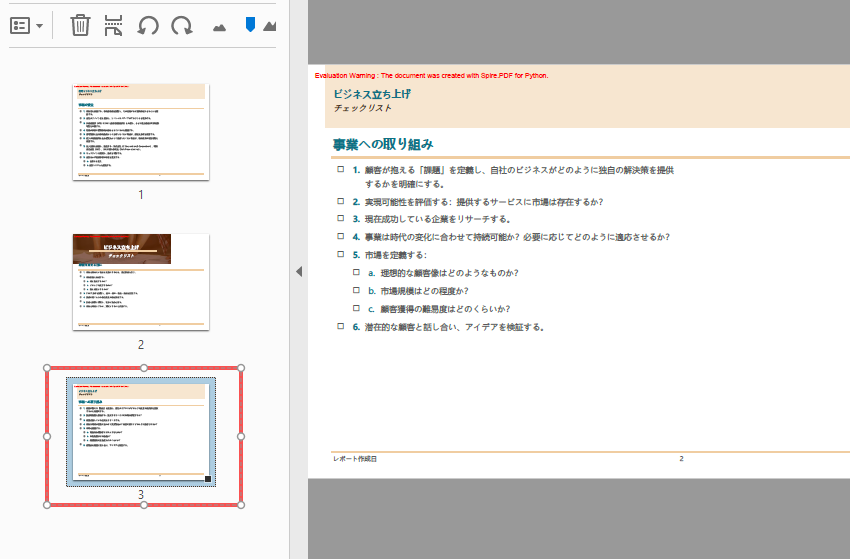
- 複数の PDF を結合する
AppendPage() メソッドを使用すると、複数の PDF を 1 つの PDF にまとめることができます。
コード例
import os
from spire.pdf import PdfDocument
# PDF ファイルのパスを指定
pdfPath = "PDFs/"
# パスから PDF ファイル名を読み取りリストに追加
files = [pdfPath + file for file in os.listdir(pdfPath) if file.endswith(".pdf")]
# 最初の PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile(files[0])
# 他の PDF ファイルを反復処理
for i in range(1, len(files)):
# 現在の PDF ファイルを読み込む
pdf2 = PdfDocument()
pdf2.LoadFromFile(files[i])
# 現在の PDF ファイルのページを最初の PDF ファイルに追加
pdf.AppendPage(pdf2)
# 結合した PDF ファイルを保存
pdf.SaveToFile("output/MergePDFs.pdf")
pdf.Close()
結果:
関連トピック:Python で PDF を分割する方法
Python で PDF コンテンツを編集する
Spire.PDF は、テキスト、画像、注釈、フォームなど、さまざまなコンテンツ編集機能を提供します。
- PDF 内のテキストを置換する
PdfTextReplacer クラスを使用すると、ページ内のテキストを検索して置換できます。正確な置換には、大文字小文字やレイアウトを考慮した処理が必要になる場合があることに注意してください。
コード例
from spire.pdf import PdfDocument, PdfTextReplacer, ReplaceActionType, Color
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# 全ページを反復処理
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
# PdfTextReplacer オブジェクトを作成
replacer = PdfTextReplacer(page)
# 置換オプションを設定
replacer.Options.ReplaceType = ReplaceActionType.IgnoreCase
# テキストを置換
replacer.ReplaceAllText("ドローン", "ロボット")
# PDF ファイルを保存
pdf.SaveToFile("output/ReplaceText.pdf")
pdf.Close()
結果:

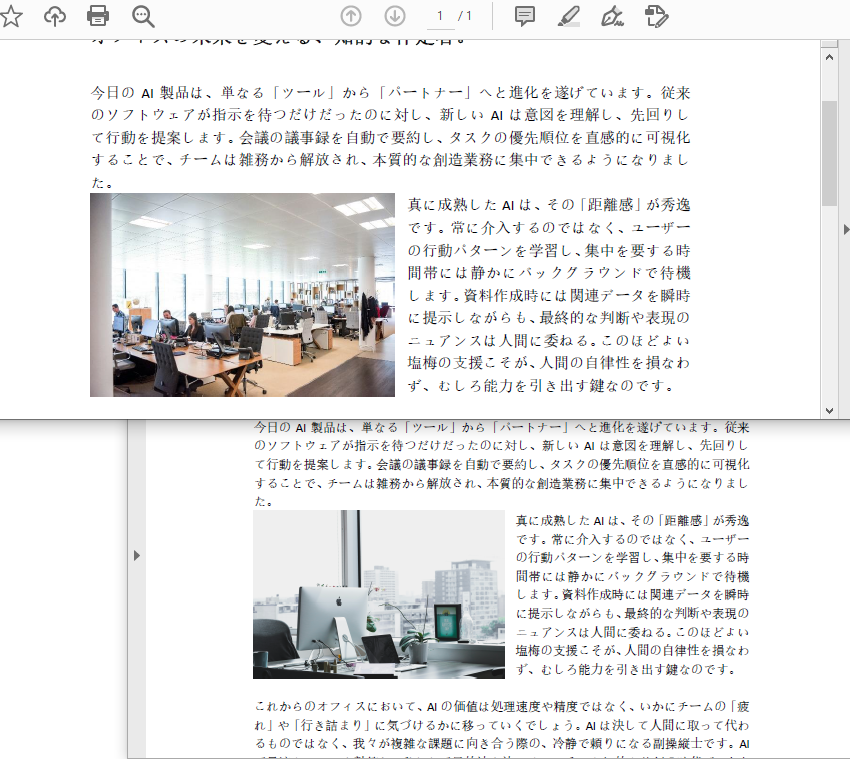
- PDF 内の画像を置換する
PdfImageHelper クラスを利用すると、PDF 内の画像を簡単に差し替えることができます。特定のページから画像情報を取得し、ReplaceImage() メソッドを使用して元の画像を新しい画像に直接置き換えることができます。
コード例
from spire.pdf import PdfDocument, PdfImageHelper, PdfImage
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# ページを取得
page = pdf.Pages.get_Item(0)
# PdfImageHelper インスタンスを作成
imageHelper = PdfImageHelper()
# ページ上の最初の画像の情報を取得
imageInfo = imageHelper.GetImagesInfo(page)[0]
# 新しい画像を読み込む
newImage = PdfImage.FromFile("Image.png")
# 画像を置換
imageHelper.ReplaceImage(imageInfo, newImage)
# PDF ファイルを保存
pdf.SaveToFile("output/ReplaceImage.pdf")
pdf.Close()
結果:
さらに探る:Python で PDF 画像の透明度を設定する方法
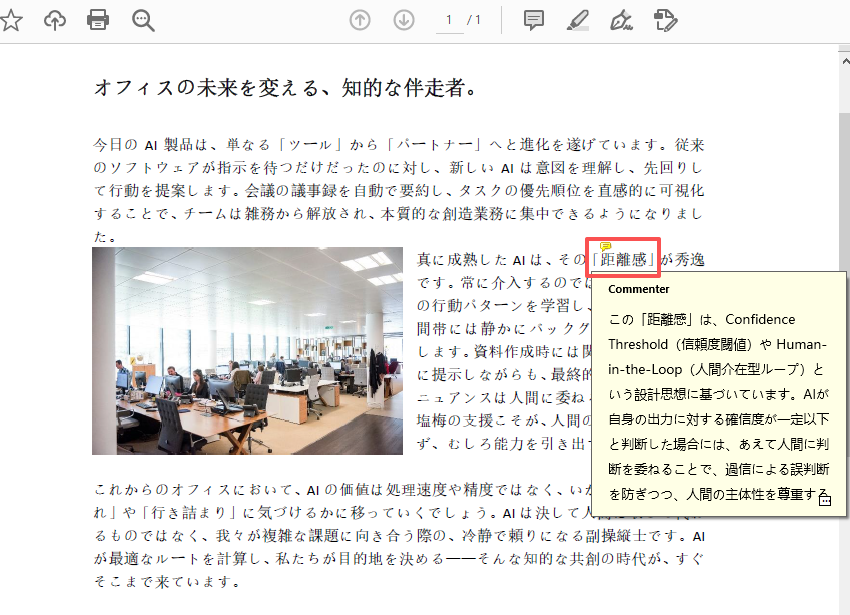
- コメントや注釈を追加する
Python でコメントや注釈を追加するには、PdfTextMarkupAnnotation クラスを使用し、ページの AnnotationsWidget コレクションに追加します。
コード例
from spire.pdf import PdfDocument, PdfTextFinder, PdfTextMarkupAnnotation, PdfRGBColor, Color
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# ページを取得
page = pdf.Pages.get_Item(0)
# PdfTextFinder インスタンスを作成しオプションを設定
finder = PdfTextFinder(page)
finder.Options.Parameter.IgnoreCase = False
finder.Options.Parameter.WholeWord = True
# コメントを付けるテキストを検索
text = finder.Find("距離感")[0]
# テキストの境界を取得
bound = text.Bounds[0]
# コメントを追加
commentText = ("この「距離感」は、Confidence Threshold(信頼度閾値)や "
"Human-in-the-Loop(人間介在型ループ)という設計思想に基づいています。"
"AIが自身の出力に対する確信度が一定以下と判断した場合には、"
"あえて人間に判断を委ねることで、過信による誤判断を防ぎつつ、"
"人間の主体性を尊重する仕組みです。")
comment = PdfTextMarkupAnnotation("Commenter", commentText, bound)
comment.TextMarkupColor = PdfRGBColor(Color.get_Yellow())
page.AnnotationsWidget.Add(comment)
# PDF ファイルを保存
pdf.SaveToFile("output/CommentNote.pdf")
pdf.Close()
結果:
おすすめ記事:Python で PDF ドキュメントにスタンプを追加する方法
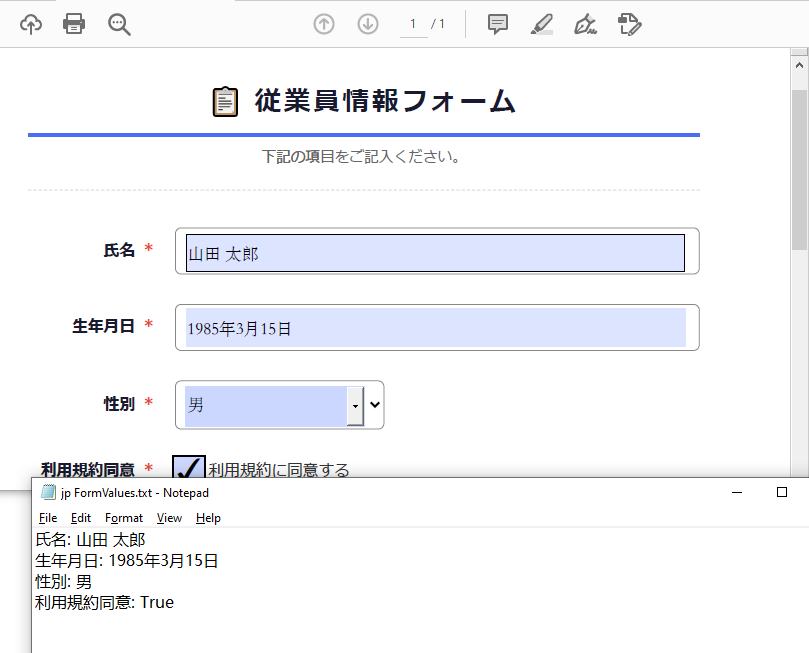
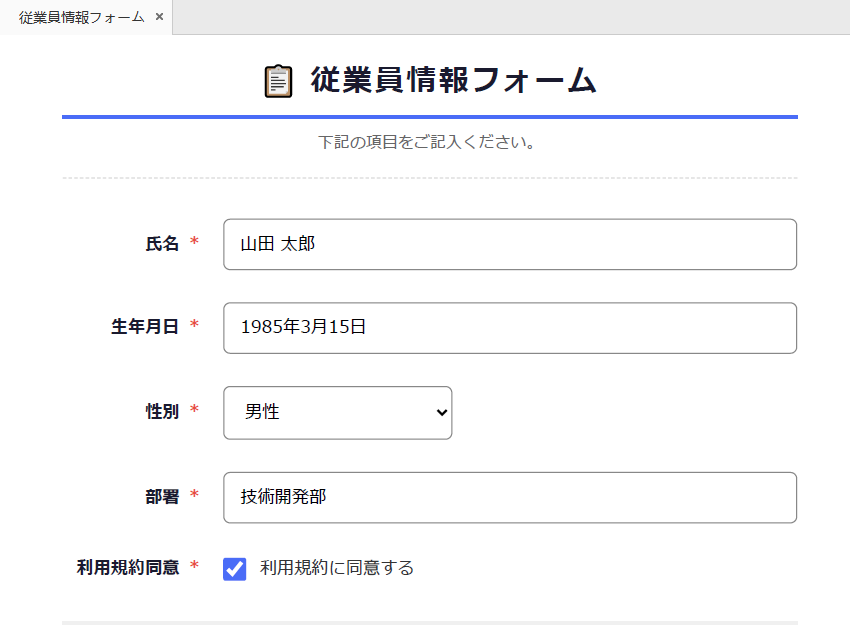
- PDF フォームの読み取りと入力
Spire.PDF では、PDF フォームの入力や値の取得をプログラムから実行できます。PdfFormWidget オブジェクトの FieldsWidget プロパティにアクセスすることで、テキストボックス、コンボボックス、チェックボックスなどのすべてのインタラクティブフォーム要素を反復処理し、その値を更新または抽出できます。
コード例
from spire.pdf import PdfDocument, PdfFormWidget, PdfComboBoxWidgetFieldWidget, PdfCheckBoxWidgetFieldWidget, PdfTextBoxFieldWidget
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
forms = pdf.Form
formWidgets = PdfFormWidget(forms).FieldsWidget
# フォームに入力
for i in range(formWidgets.Count):
formField = formWidgets.get_Item(i)
if formField.Name == "氏名":
textBox = PdfTextBoxFieldWidget(formField)
textBox.Text = "山田 太郎"
elif formField.Name == "生年月日":
textBox = PdfTextBoxFieldWidget(formField)
textBox.Text = "1985年3月15日"
elif formField.Name == "性別":
comboBox = PdfComboBoxWidgetFieldWidget(formField)
comboBox.SelectedIndex = [ 0 ]
elif formField.Name == "利用規約同意":
checkBox = PdfCheckBoxWidgetFieldWidget(formField)
checkBox.Checked = True
# フォーム値を読み取り
formValues = []
for i in range(formWidgets.Count):
formField = formWidgets.get_Item(i)
if isinstance(formField, PdfTextBoxFieldWidget):
formValues.append(formField.Name + ": " + formField.Text)
elif isinstance(formField, PdfComboBoxWidgetFieldWidget):
formValues.append(formField.Name + ": " + formField.SelectedValue)
elif isinstance(formField, PdfCheckBoxWidgetFieldWidget):
formValues.append(formField.Name + ": " + str(formField.Checked))
# フォーム値をファイルに書き込む
with open("output/FormValues.txt", "w") as file:
file.write("\n".join(formValues))
# PDF ファイルを保存
pdf.SaveToFile("output/FilledForm.pdf")
pdf.Close()
結果:
Python で PDF のセキュリティを管理する
機密文書を扱う場合、PDF のセキュリティ管理は非常に重要です。Spire.PDF は、暗号化、パスワード保護、デジタル署名処理、アクセス権限設定をサポートしています。
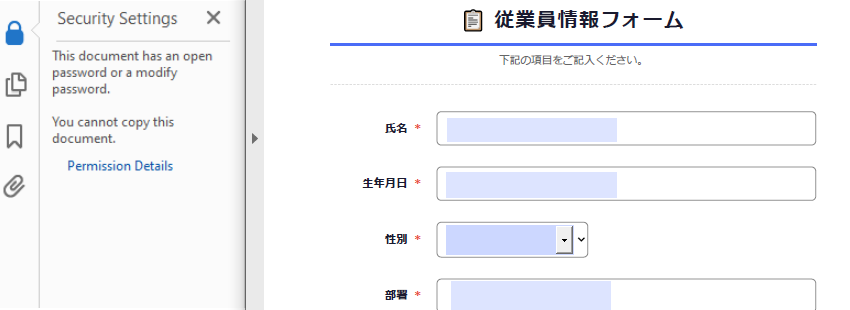
- パスワード保護と権限設定
Encrypt() メソッドを使用すると、ユーザーパスワードとオーナーパスワードを設定し、印刷やコピーなどの許可内容を制御できます。
コード例
from spire.pdf import PdfDocument, PdfEncryptionAlgorithm, PdfDocumentPrivilege, PdfPasswordSecurityPolicy
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
# PdfSecurityPolicy オブジェクトを作成し、パスワードと暗号化アルゴリズムを設定
securityPolicy = PdfPasswordSecurityPolicy("userPSD", "ownerPSD")
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_128
# ドキュメント権限を設定
pdfPrivileges = PdfDocumentPrivilege.ForbidAll()
pdfPrivileges.AllowPrint = True
pdfPrivileges.AllowFillFormFields = True
# ドキュメント権限を適用
securityPolicy.DocumentPrivilege = pdfPrivileges
# セキュリティポリシーで PDF を暗号化
pdf.Encrypt(securityPolicy)
# PDF ファイルを保存
pdf.SaveToFile("output/EncryptedForm.pdf")
pdf.Close()
結果:
- PDF のパスワードを解除する
保護されたファイルを開くには、LoadFromFile() 呼び出し時にユーザーパスワードを指定し、Decrypt() を使用してドキュメントを復号化し、再度保護なしで保存します。
コード例
from spire.pdf import PdfDocument
# オーナーパスワードを使用して暗号化された PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("output/EncryptedForm.pdf", "ownerPSD")
# PDF ファイルを復号化
pdf.Decrypt()
# PDF ファイルを保存
pdf.SaveToFile("output/DecryptedForm.pdf")
pdf.Close()
Python で PDF のプロパティを編集する
Spire.PDF では、PDF のメタデータや表示設定を編集できます。
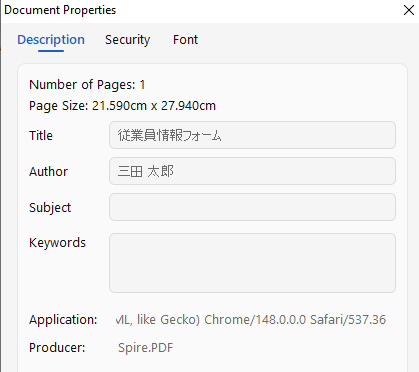
- ドキュメントのメタデータを更新する
DocumentInformation プロパティを使用して、タイトルや作成者情報などを設定できます。
コード例
from spire.pdf import PdfDocument
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
# ドキュメントメタデータを設定
pdf.DocumentInformation.Author = "三田 太郎"
pdf.DocumentInformation.Title = "従業員情報フォーム"
pdf.DocumentInformation.Producer = "Spire.PDF"
# PDF ファイルを保存
pdf.SaveToFile("output/EditProperties.pdf")
pdf.Close()
結果:
- 表示設定を変更する
ViewerPreferences プロパティを使用して、PDF の表示モードをカスタマイズできます。
コード例
from spire.pdf import PdfDocument, PdfPageLayout, PrintScalingMode
# PDF ファイルを読み込む
pdf = PdfDocument()
pdf.LoadFromFile("EmployeeInformationForm.pdf")
# ビューア環境設定を設定
pdf.ViewerPreferences.DisplayTitle = True
pdf.ViewerPreferences.HideToolbar = True
pdf.ViewerPreferences.HideWindowUI = True
pdf.ViewerPreferences.FitWindow = False
pdf.ViewerPreferences.HideMenubar = True
pdf.ViewerPreferences.PrintScaling = PrintScalingMode.AppDefault
pdf.ViewerPreferences.PageLayout = PdfPageLayout.OneColumn
# PDF ファイルを保存
pdf.SaveToFile("output/EditViewerPreference.pdf")
pdf.Close()
結果:
類似トピック:Python で PDF ファイルを読み取る方法
まとめ
Python で PDFを編集するなら、Spire.PDF for Python は実用的かつ効率的な選択肢です。自動化ツールの開発、電子フォームの編集、機密レポートの保護など、さまざまな用途に対応できる包括的な PDF 編集機能を提供します。
コンテンツ編集、フォーム操作、ドキュメント構造の管理、セキュリティ制御まで幅広くサポートしているため、PDF ワークフローを効率化したい開発者や企業にとって非常に有力なソリューションと言えるでしょう。
よくある質問
Q:Python で PDF を編集できますか?
A:はい。Spire.PDF for Python のようなライブラリを利用することで、PDF 内のテキスト、画像、フォーム、注釈、セキュリティ設定などを編集できます。
Q:コードを使って PDF を編集するにはどうすればよいですか?
A:Spire.PDF for Python などのライブラリを使用して既存の PDF を読み込み、内容や構造を変更し、編集後の PDF を保存できます。数行のコードで実現可能です。
Q:Python で利用できる PDF 編集ライブラリは何ですか?
A:Spire.PDF for Python は人気の高い選択肢の一つです。PDF の作成、読み取り、編集、変換、保護を包括的にサポートしており、追加ソフトウェアも必要ありません。
Q:無料で PDF を編集できますか?
A:はい。Spire.PDF for Python の無料版を使用して PDF を編集できます。ただし、無料版には 1 ドキュメントあたり最大 10 ページまでといった制限があります。また、30 日間有効な一時ライセンスを申請することで、機能制限やウォーターマークなしで全機能を評価できます。





